در این مطلب، ویدئو پیش بینی آب و هوا با Neural Prophet و Python با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:23:46
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,080 –> 00:00:01,199
نمیدانم هوا
2
00:00:01,199 –> 00:00:05,440
امروز چگونه خواهد بود گرم، امیدوارم
3
00:00:05,440 –> 00:00:09,599
شاید شما باید پیشبینی را بررسی کنید که
4
00:00:09,599 –> 00:00:11,840
چه اتفاقی میافتد بچهها بیرون فوقالعاده آفتابی است،
5
00:00:11,840 –> 00:00:13,840
اما آیا همیشه
6
00:00:13,840 –> 00:00:15,440
در این ویدیو خواهد بود، ما نگاهی
7
00:00:15,440 –> 00:00:17,680
خواهیم داشت به اینکه چگونه میتوانیم با استفاده از زمان، آب و هوا را پیشبینی
8
00:00:17,680 –> 00:00:19,119
کنیم. بسته سری
9
00:00:19,119 –> 00:00:21,199
به نام سود عصبی، بیایید نگاهی عمیقتر
10
00:00:21,199 –> 00:00:22,480
به آنچه که قرار
11
00:00:22,480 –> 00:00:22,800
12
00:00:22,800 –> 00:00:24,240
است از سر گذرانیم بیاندازیم، بنابراین در این راهنما
13
00:00:24,240 –> 00:00:25,599
چند مورد کلیدی را مرور خواهیم کرد، اما بهطور
14
00:00:25,599 –> 00:00:27,279
خاص تا پایان
15
00:00:27,279 –> 00:00:28,080
این ویدیو
16
00:00:28,080 –> 00:00:30,080
شما باید قادر به پیشبینی
17
00:00:30,080 –> 00:00:31,920
دما با استفاده از بسته سود عصبی هستیم،
18
00:00:31,920 –> 00:00:32,719
19
00:00:32,719 –> 00:00:34,160
بنابراین ابتدا با
20
00:00:34,160 –> 00:00:36,160
پیشپردازش دادههایمان و بارگذاری آنها
21
00:00:36,160 –> 00:00:37,840
شروع میکنیم، بنابراین از مجموعه دادههای kaggle
22
00:00:37,840 –> 00:00:38,480
برای این کار استفاده
23
00:00:38,480 –> 00:00:39,920
میکنیم و سپس یک سری زمانی آموزش میدهیم.
24
00:00:39,920 –> 00:00:42,000
مدل پیشبینی با استفاده از سود عصبی، بنابراین
25
00:00:42,000 –> 00:00:42,320
این
26
00:00:42,320 –> 00:00:44,640
در واقع یک کتابخانه است که
27
00:00:44,640 –> 00:00:45,680
بر روی
28
00:00:45,680 –> 00:00:48,879
بسته سود ar net و فیسبوک ساخته شده است،
29
00:00:48,879 –> 00:00:50,079
سپس کاری که میخواهیم انجام دهیم این است که
30
00:00:50,079 –> 00:00:51,760
31
00:00:51,760 –> 00:00:52,719
32
00:00:52,719 –> 00:00:55,199
با استفاده از مدل آموزشدیده خود دما را در آینده پیشبینی کنیم.
33
00:00:55,199 –> 00:00:56,719
نگاهی عمیق تر به اینکه چگونه همه اینها
34
00:00:56,719 –> 00:00:58,640
با هم تطبیق می دهند بیندازید، بنابراین
35
00:00:58,640 –> 00:01:00,640
ابتدا با خواندن مجموعه داده های خود
36
00:01:00,640 –> 00:01:02,719
در یک نوت بوک jupyter با استفاده از پانداها شروع
37
00:01:02,719 –> 00:01:03,920
می کنیم و سپس کمی
38
00:01:03,920 –> 00:01:05,760
پیش پردازش را انجام می دهیم. به طور خاص خواهید دید
39
00:01:05,760 –> 00:01:07,200
که در دادههایی که قرار است با آنها
40
00:01:07,200 –> 00:01:08,000
کار
41
00:01:08,000 –> 00:01:09,920
کنیم، بخش گمشدهای از دادهها وجود دارد، بنابراین
42
00:01:09,920 –> 00:01:11,360
نگاهی خواهیم داشت که چگونه میتوانیم آن را مدیریت
43
00:01:11,360 –> 00:01:12,000
کنیم،
44
00:01:12,000 –> 00:01:13,680
سپس کاری که انجام میدهیم این است که با سیستم عصبی خود هماهنگ میشویم.
45
00:01:13,680 –> 00:01:15,680
مدل شبکه به طور خاص با استفاده از
46
00:01:15,680 –> 00:01:17,600
سود عصبی و سپس میتوانیم
47
00:01:17,600 –> 00:01:20,159
دورههای آینده را پیشبینی کنیم، بنابراین این
48
00:01:20,159 –> 00:01:21,360
به ما امکان میدهد
49
00:01:21,360 –> 00:01:22,159
دمای
50
00:01:22,159 –> 00:01:25,119
خارج از آینده را پیشبینی کنیم و
51
00:01:25,119 –> 00:01:27,280
آماده انجام آن باشیم.
52
00:01:27,280 –> 00:01:28,560
آب و هوا ما
53
00:01:28,560 –> 00:01:29,360
باید
54
00:01:29,360 –> 00:01:31,840
پنج کار کلیدی انجام دهیم، بنابراین به طور خاص
55
00:01:31,840 –> 00:01:32,640
ابتدا باید
56
00:01:32,640 –> 00:01:34,640
وابستگیهای خود را نصب و وارد کنیم، بنابراین
57
00:01:34,640 –> 00:01:36,320
این تا حد زیادی بسته سود عصبی
58
00:01:36,320 –> 00:01:37,200
است،
59
00:01:37,200 –> 00:01:39,119
سپس باید دادههایمان را بخوانیم و
60
00:01:39,119 –> 00:01:40,799
تاریخهایمان را پردازش کنیم و من به شما نشان خواهم داد
61
00:01:40,799 –> 00:01:42,079
کجا برای به دست آوردن داده ها
62
00:01:42,079 –> 00:01:44,240
، سپس مدل خود را در ابتدا آموزش خواهیم داد ریخته و
63
00:01:44,240 –> 00:01:45,920
سپس مدل خود را ذخیره کنید تا بتوانیم
64
00:01:45,920 –> 00:01:46,799
65
00:01:46,799 –> 00:01:49,040
بعداً دوباره از آن استفاده کنیم.
66
00:01:49,040 –> 00:01:50,560
67
00:01:50,560 –> 00:01:53,439
68
00:01:53,439 –> 00:01:54,880
69
00:01:54,880 –> 00:01:56,880
70
00:01:56,880 –> 00:01:58,799
در اینجا دما در
71
00:01:58,799 –> 00:01:59,520
ساعت 3 بعد از ظهر نامیده
72
00:01:59,520 –> 00:02:00,719
می شود و این ویژگی است که
73
00:02:00,719 –> 00:02:02,880
ما قصد داریم اکنون آن را پیش بینی کنیم. نکته دیگری که باید به آن
74
00:02:02,880 –> 00:02:04,159
توجه کرد این است که می توانید
75
00:02:04,159 –> 00:02:06,560
همه این کدها را از پیش نوشته شده دریافت کنید،
76
00:02:06,560 –> 00:02:08,080
از جمله نوت بوک مشتری و
77
00:02:08,080 –> 00:02:09,038
مجموعه داده ها
78
00:02:09,038 –> 00:02:11,038
از صفحه github من. اگر یک
79
00:02:11,038 –> 00:02:12,560
پیشبینی آب و هوا
80
00:02:12,560 –> 00:02:13,920
با سود عصبی دارید، میتوانید
81
00:02:13,920 –> 00:02:14,640
این را انتخاب کنید
82
00:02:14,640 –> 00:02:16,560
و با آن اجرا کنید، اما در این ویدیو ما
83
00:02:16,560 –> 00:02:18,319
آن را مرحله به مرحله مرور میکنیم،
84
00:02:18,319 –> 00:02:20,480
بنابراین ابتدا بیایید ادامه دهیم و
85
00:02:20,480 –> 00:02:22,000
ما را نصب کنیم. وابستگی اصلی که قطعاً
86
00:02:22,000 –> 00:02:24,720
سود
87
00:02:26,560 –> 00:02:28,800
عصبی خواهد بود و این سود عصبی
88
00:02:28,800 –> 00:02:29,680
نصب شده است،
89
00:02:29,680 –> 00:02:31,120
بنابراین برای انجام این کار
90
00:02:31,120 –> 00:02:33,360
علامت تعجب نوشته ایم پیپ نصب
91
00:02:33,360 –> 00:02:35,840
سود عصبی و می توانید ببینید که
92
00:02:35,840 –> 00:02:36,800
ادامه دارد و
93
00:02:36,800 –> 00:02:38,080
اکنون آن را نصب می کنیم.
94
00:02:38,080 –> 00:02:39,920
انجام این کار در واقع ادامه دادن و
95
00:02:39,920 –> 00:02:42,080
وارد کردن برخی وابستگیهای کلیدی است، بنابراین
96
00:02:42,080 –> 00:02:43,599
وابستگیهای خاصی که به آنها
97
00:02:43,599 –> 00:02:44,879
نیاز خواهیم داشت،
98
00:02:44,879 –> 00:02:46,800
سود عصبی پانداها برای
99
00:02:46,800 –> 00:02:48,480
کمی نقشهبرداری است و همچنین میخواهیم
100
00:02:48,480 –> 00:02:50,080
ترشی را وارد کنیم، زیرا این همان چیزی است که
101
00:02:50,080 –> 00:02:50,640
102
00:02:50,640 –> 00:02:53,040
برای صرفهجویی استفاده میکنیم. مدل ما بعداً روی دیسک پایین میآید،
103
00:02:53,040 –> 00:02:56,560
بنابراین بیایید جلو برویم و همه آنها را وارد
104
00:03:03,519 –> 00:03:05,360
کنیم، بنابراین ما چهار
105
00:03:05,360 –> 00:03:07,040
خط کد را در آنجا نوشتهایم و
106
00:03:07,040 –> 00:03:09,200
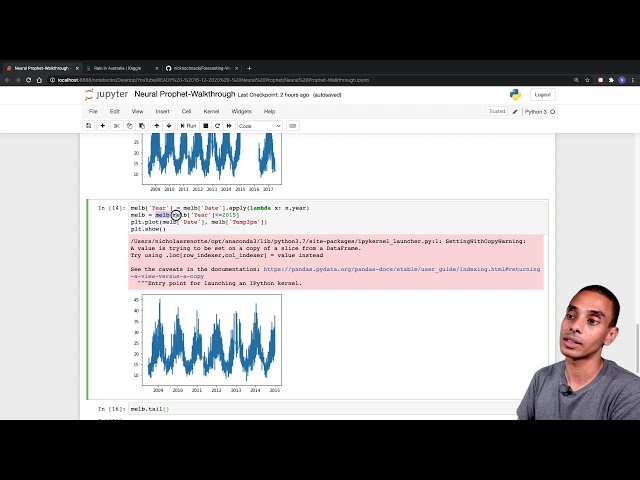
همه وابستگیهایمان را
107
00:03:09,200 –> 00:03:11,040
وارد کردهایم، بنابراین اولین وارداتی که انجام دادیم برای پانداها است.
108
00:03:11,040 –> 00:03:12,000
که ما
109
00:03:12,000 –> 00:03:15,680
پانداهای وارداتی را به صورت pd نوشته ایم سپس سود عصبی را وارد کرده ایم،
110
00:03:15,680 –> 00:03:17,599
بنابراین برای انجام این کار از سود عصبی وارداتی سود عصبی نوشته شده است،
111
00:03:17,599 –> 00:03:20,239
بنابراین
112
00:03:20,239 –> 00:03:21,840
این وارد کردن کلاس سود عصبی است،
113
00:03:21,840 –> 00:03:22,879
114
00:03:22,879 –> 00:03:25,599
سپس ما matplotlib را از
115
00:03:25,599 –> 00:03:26,640
matplotlib
116
00:03:26,640 –> 00:03:29,840
واردات pi نمودار به صورت plt وارد کرده ایم. این بدان معناست که
117
00:03:29,840 –> 00:03:30,799
هر زمان که
118
00:03:30,799 –> 00:03:33,120
به plt مراجعه می کنیم، در واقع به pi
119
00:03:33,120 –> 00:03:34,720
plot و matplotlib اشاره می کنیم
120
00:03:34,720 –> 00:03:36,480
و سپس ترشی را وارد کرده ایم، بنابراین برای انجام
121
00:03:36,480 –> 00:03:38,319
این کار، واردات ترشی را نوشته ایم،
122
00:03:38,319 –> 00:03:39,360
کار بعدی که باید انجام دهیم این است که
123
00:03:39,360 –> 00:03:40,560
در واقع ادامه دهیم و
124
00:03:40,560 –> 00:03:42,720
وارد کنیم. داده ما بنابراین مجموعه داده
125
00:03:42,720 –> 00:03:44,280
ای که قرار است از آن استفاده کنیم این
126
00:03:44,280 –> 00:03:46,080
weatheroz.csv است، بنابراین اگر ما واقعاً
127
00:03:46,080 –> 00:03:48,319
به پیش نمایش نگاهی بیندازیم، می توانید ببینید
128
00:03:48,319 –> 00:03:49,840
که یک دسته کامل
129
00:03:49,840 –> 00:03:51,680
از ستون های مختلف وجود دارد که واقعاً
130
00:03:51,680 –> 00:03:53,680
حول آب و هوا
131
00:03:53,680 –> 00:03:54,799
می چرخند. کمی بیشتر طول می کشد، اجازه دهید در
132
00:03:54,799 –> 00:03:56,959
عوض آن را در قاب داده خود بخوانیم،
133
00:03:56,959 –> 00:03:57,519
پس بیایید ادامه دهیم
134
00:03:57,519 –> 00:04:01,840
و آن را با استفاده از پانداها
135
00:04:03,599 –> 00:04:05,840
بخوانیم و می توانید ببینید که
136
00:04:05,840 –> 00:04:07,280
ما اکنون داده های دمایی خود را داریم،
137
00:04:07,280 –> 00:04:09,680
بنابراین در این مورد خاص، کاری
138
00:04:09,680 –> 00:04:10,319
که انجام داده ایم این
139
00:04:10,319 –> 00:04:13,040
است که ما ‘pd dot read csv نوشتهایم و
140
00:04:13,040 –> 00:04:14,480
سپس
141
00:04:14,480 –> 00:04:16,880
نام مجموعه دادههایمان را عبور دادهایم، بنابراین این مجموعه دادههای ما
142
00:04:16,880 –> 00:04:18,320
در اینجا است، چه نقطه
143
00:04:18,320 –> 00:04:21,199
یا چه oz.csv و سپس
144
00:04:21,199 –> 00:04:22,960
آن دادهها را در یک قاب داده ذخیره کردهایم. df نامیده می شود
145
00:04:22,960 –> 00:04:23,680
146
00:04:23,680 –> 00:04:25,680
و سپس برای تجسم پنج ردیف اول،
147
00:04:25,680 –> 00:04:27,520
ما فقط df.head
148
00:04:27,520 –> 00:04:28,960
برخی از عملکردهای بسیار استاندارد
149
00:04:28,960 –> 00:04:30,400
پاندا را در آنجا نوشتیم، بنابراین اگر
150
00:04:30,400 –> 00:04:32,080
با پانداها خیلی آشنا نیستید، به شدت
151
00:04:32,080 –> 00:04:34,160
توصیه می کنم پانداها را در
152
00:04:34,160 –> 00:04:34,960
ویدیوی 20 دقیقه
153
00:04:34,960 –> 00:04:36,479
ای ببینید. یک لینک در جایی بالا وجود خواهد داشت،
154
00:04:36,479 –> 00:04:38,160
آن را بررسی کنید اکنون که
155
00:04:38,160 –> 00:04:38,560
156
00:04:38,560 –> 00:04:40,080
دادههای خود را وارد کردهایم واقعاً خوب است، احتمالاً خوب است
157
00:04:40,080 –> 00:04:42,000
که کمی
158
00:04:42,000 –> 00:04:43,440
تجزیه و تحلیل دادههای اکتشافی انجام دهیم، بنابراین میتوانید ببینید که ما
159
00:04:43,440 –> 00:04:46,240
یک انبوه مکانهای مختلف در اینجا داریم
160
00:04:46,240 –> 00:04:47,840
و به نظر میرسد که تعدادی از آنها داریم.
161
00:04:47,840 –> 00:04:49,520
بنابراین بیایید ابتدا به آنها نگاهی بیندازیم،
162
00:04:49,520 –> 00:04:51,280
بنابراین بیایید نگاهی به تمام
163
00:04:51,280 –> 00:04:54,560
مکانهای مختلف بیندازیم
164
00:04:55,600 –> 00:04:57,680
تا بتوانیم ببینید که ما
165
00:04:57,680 –> 00:04:58,639
166
00:04:58,639 –> 00:05:00,960
تعداد زیادی مکان مختلف در
167
00:05:00,960 –> 00:05:03,360
مجموعه دادههای خود داریم، بنابراین برای به دست آوردن این منحصر به فرد
168
00:05:03,360 –> 00:05:05,919
آرایه کاری که ما انجام دادهایم اجرای df.location است،
169
00:05:05,919 –> 00:05:07,440
بنابراین به این ستون در اینجا اشاره میکند،
170
00:05:07,440 –> 00:05:09,280
بنابراین اگر یک را رها کنم،
171
00:05:09,280 –> 00:05:10,400
میتوانید ببینید که ما فقط
172
00:05:10,400 –> 00:05:12,240
از آن ستون عبور میکنیم، اما با تایپ کردن عبارت
173
00:05:12,240 –> 00:05:13,280
unique
174
00:05:13,280 –> 00:05:15,199
میتوانیم تمام موارد منحصربهفرد را دریافت کنیم.
175
00:05:15,199 –> 00:05:16,560
176
00:05:16,560 –> 00:05:18,240
اکنون میتوانید ببینید که ما
177
00:05:18,240 –> 00:05:21,039
تعداد کمی از آنها را داریم که فکر میکنم
178
00:05:21,039 –> 00:05:21,600
احتمالاً
179
00:05:21,600 –> 00:05:23,919
ملبورن را انجام خواهیم داد، بنابراین میتوانید ببینید
180
00:05:23,919 –> 00:05:24,960
که ما مجموعهای کامل از مکانهای مختلف داریم،
181
00:05:24,960 –> 00:05:26,720
این مکانهای بدیهی است که
182
00:05:26,720 –> 00:05:28,479
مکانهای استرالیا هستند. ما فقط
183
00:05:28,479 –> 00:05:29,759
یکی را انتخاب می کنیم، بنابراین در انتخاب تفاوت احساس راحتی کنید
184
00:05:29,759 –> 00:05:31,039
185
00:05:31,039 –> 00:05:33,039
اگر بخواهید، این را در یک ثانیه از قبل پردازش میکنیم تا
186
00:05:33,039 –> 00:05:34,560
فیلتر شود، بنابراین
187
00:05:34,560 –> 00:05:36,080
احتمالاً
188
00:05:36,080 –> 00:05:38,000
اکنون ملبورن را انجام خواهیم داد، کار بعدی احتمالاً
189
00:05:38,000 –> 00:05:39,199
نگاهی به تمام ستونهایی است که
190
00:05:39,199 –> 00:05:42,720
داریم، پس بیایید ادامه دهید و این کار را به درستی انجام
191
00:05:42,720 –> 00:05:44,400
دهید تا بتوانیم
192
00:05:44,400 –> 00:05:46,800
فقط با نوشتن df.columns به ستون های خود نگاهی بیندازیم و
193
00:05:46,800 –> 00:05:48,560
می توانید ببینید که ما یک مکان ستون تاریخ داریم
194
00:05:48,560 –> 00:05:49,600
195
00:05:49,600 –> 00:05:51,600
حداقل دما حداکثر دما
196
00:05:51,600 –> 00:05:53,360
تبخیر بارندگی تبخیر
197
00:05:53,360 –> 00:05:55,919
آفتاب وزش باد تند باد سرعت باد
198
00:05:55,919 –> 00:05:56,720
199
00:05:56,720 –> 00:05:58,800
جهت کل دسته ای از جهت ها و همچنین
200
00:05:58,800 –> 00:06:00,479
201
00:06:00,479 –> 00:06:02,720
فشار رطوبت سرعت باد، چه
202
00:06:02,720 –> 00:06:05,120
در ساعت 3 بعدازظهر و چه در ساعت 21:00
203
00:06:05,120 –> 00:06:06,960
دمای هوا داشته باشیم یا
204
00:06:06,960 –> 00:06:09,280
205
00:06:09,280 –> 00:06:10,800
206
00:06:10,800 –> 00:06:12,479
نه در مورد
207
00:06:12,479 –> 00:06:14,240
دما، بنابراین ما میخواهیم
208
00:06:14,240 –> 00:06:15,840
دما را در آینده پیشبینی کنیم
209
00:06:15,840 –> 00:06:17,199
و فکر میکنم کاری که ما انجام خواهیم داد این است
210
00:06:17,199 –> 00:06:18,800
که دما را در ساعت 3 بعد از ظهر پیشبینی میکنیم، بنابراین
211
00:06:18,800 –> 00:06:20,880
تا بعد از ظهر
212
00:06:20,880 –> 00:06:22,560
، اینها فقط مواردی هستند که باید توجه داشته باشیم، بنابراین
213
00:06:22,560 –> 00:06:24,240
ما قصد داریم در ملبورن انجام دهیم.
214
00:06:24,240 –> 00:06:25,759
اینجا و ما می رویم g برای اینکه
215
00:06:25,759 –> 00:06:27,360
دمای خود را در ساعت 3 بعد از ظهر
216
00:06:27,360 –> 00:06:28,720
پیش بینی کنیم، کار بعدی که باید انجام دهیم این است که
217
00:06:28,720 –> 00:06:30,000
در واقع شروع به انجام کمی
218
00:06:30,000 –> 00:06:32,240
پیش پردازش کنیم، بنابراین می خواهیم فیلتر
219
00:06:32,240 –> 00:06:34,479
کنیم و یک مکان خاص را بدست آوریم و سپس
220
00:06:34,479 –> 00:06:36,240
می خواهیم این ستون تاریخ را نیز تبدیل کنیم.
221
00:06:36,240 –> 00:06:37,520
به زمان واقعی تاریخ،
222
00:06:37,520 –> 00:06:39,440
بنابراین اگر ما در حال حاضر به انواع d خود نگاه کنیم،
223
00:06:39,440 –> 00:06:42,240
بنابراین با تایپ انواع df.d
224
00:06:42,240 –> 00:06:43,919
می توانید ببینید که تاریخ ما فقط یک
225
00:06:43,919 –> 00:06:45,680
شی است، بنابراین هیچ ویژگی زمانی ندارد،
226
00:06:45,680 –> 00:06:47,120
اما می خواهیم آن را به تاریخ تبدیل کنیم.
227
00:06:47,120 –> 00:06:48,800
شی زمان، بنابراین ما این کار را
228
00:06:48,800 –> 00:06:50,319
در یک ثانیه نیز
229
00:06:50,319 –> 00:06:52,720
انجام خواهیم داد، پس بیایید ادامه دهیم و
230
00:06:52,720 –> 00:06:54,479
پیش پردازش مجموعه دادههای خود را شروع کنیم،
231
00:06:54,479 –> 00:06:55,840
بنابراین کاری که میخواهیم انجام دهیم این است که
232
00:06:55,840 –> 00:06:57,919
ستون تاریخ خود را به
233
00:06:57,919 –> 00:07:00,960
نوع زمان تاریخ تبدیل کنیم و سپس آنچه را که هستیم همچنین این
234
00:07:00,960 –> 00:07:02,319
کار این است که مجموعه دادههای خود را فیلتر کرده
235
00:07:02,319 –> 00:07:04,479
و ملبورن را انتخاب
236
00:07:04,479 –> 00:07:06,240
میکنیم، بنابراین به یاد داشته باشید که ما فقط یک مکان را پیشبینی میکنیم،
237
00:07:06,240 –> 00:07:07,599
238
00:07:07,599 –> 00:07:17,840
پس بیایید ادامه دهیم و این کار را به خوبی انجام دهیم،
239
00:07:19,919 –> 00:07:23,039
بنابراین اکنون رفتهایم و
240
00:07:23,039 –> 00:07:24,560
دادههای خود را فیلتر کردهایم. تنظیم کنید و ما
241
00:07:24,560 –> 00:07:26,880
آن را به a تبدیل کرده ایم و ستون تاریخ خود
242
00:07:26,880 –> 00:07:28,160
را به زمان تاریخ تبدیل کرده ایم، بنابراین اگر فقط
243
00:07:28,160 –> 00:07:28,880
بررسی کنیم نوع d ما
244
00:07:28,880 –> 00:07:32,240
اوه که به نظر نمی رسد اوه نگه دارید،
245
00:07:32,240 –> 00:07:32,800
ما این
246
00:07:32,800 –> 00:07:34,479
کار را روی قاب داده اشتباه انجام می دهیم،
247
00:07:34,479 –> 00:07:35,919
خیلی خوب است، بنابراین تمام شد،
248
00:07:35,919 –> 00:07:37,360
بنابراین آنچه ما در آنجا نوشتیم این است که ما
249
00:07:37,360 –> 00:07:39,360
سه خط کد نوشته ایم، بنابراین
250
00:07:39,360 –> 00:07:41,520
خط اول آیا ما رفتهایم و
251
00:07:41,520 –> 00:07:43,360
مجموعه دادههای خود را فیلتر کردهایم و
252
00:07:43,360 –> 00:07:45,680
بهطور خاص در مکان ملبورن خود را گرفتهایم،
253
00:07:45,680 –> 00:07:48,000
بنابراین برای انجام این کار،
254
00:07:48,000 –> 00:07:49,520
فریمهای دادهای خود را که df بود
255
00:07:49,520 –> 00:07:50,319
256
00:07:50,319 –> 00:07:51,919
گرفتهایم و سپس رفتهایم و بهطور خاص یک فیلتر
257
00:07:51,919 –> 00:07:53,599
روی آن اعمال کردهایم. کاری که
258
00:07:53,599 –> 00:07:56,000
ما انجام میدهیم این است که ستون مکان
259
00:07:56,000 –> 00:07:57,840
را میگیریم و فقط ردیفهایی را
260
00:07:57,840 –> 00:07:59,680
که مکان ملبورن را دارند برمیگردانیم و سپس
261
00:07:59,680 –> 00:08:00,400
262
00:08:00,400 –> 00:08:02,240
این فریم داده فیلتر شده را در یک
263
00:08:02,240 –> 00:08:03,599
قاب داده جدید به نام melb ذخیره
264
00:08:03,599 –> 00:08:05,199
میکنیم تا هسته اصلی خود را به جلو برسانیم. مجموعه دادهای
265
00:08:05,199 –> 00:08:06,560
که قرار است با آن کار
266
00:08:06,560 –> 00:08:09,039
کنیم، melb نامیده میشود، بنابراین m-e-l-b،
267
00:08:09,039 –> 00:08:10,000
سپس کاری که ما انجام میدهیم این است
268
00:08:10,000 –> 00:08:11,520
که ستون تاریخ خود را تبدیل میکنیم، بنابراین
269
00:08:11,520 –> 00:08:12,960
بهطور خاص کاری که در آنجا انجام
270
00:08:12,960 –> 00:08:14,400
میدهیم این است که تاریخ خود را
271
00:08:14,400 –> 00:08:16,319
تا melb میگیریم. و سپس از
272
00:08:16,319 –> 00:08:18,240
نمایه ساز تاریخ خود عبور می کنیم، بنابراین تاریخ c را به ما می دهد
273
00:08:18,240 –> 00:08:20,000
ستون
274
00:08:20,000 –> 00:08:22,720
و سپس ما از
275
00:08:22,720 –> 00:08:23,360
روش pd.truedatetime استفاده می
276
00:08:23,360 –> 00:08:24,639
کنیم و از آن ستون تاریخ عبور می کنیم،
277
00:08:24,639 –> 00:08:26,400
بنابراین ستون تاریخ ما را
278
00:08:26,400 –> 00:08:27,840
که فقط یک شی است، می گیرد
279
00:08:27,840 –> 00:08:31,280
و آن را به نوع زمان تاریخ تبدیل می کند،
280
00:08:31,280 –> 00:08:33,519
سپس آن را ذخیره می کنیم یا آن را لغو می
281
00:08:33,519 –> 00:08:35,200
کنیم. ستون تاریخ موجود با آن ستون
282
00:08:35,200 –> 00:08:36,159
نوع زمان تاریخ جدید
283
00:08:36,159 –> 00:08:38,320
و سپس پنج ردیف اول خود را
284
00:08:38,320 –> 00:08:40,640
با استفاده از melb.head نشان میدهیم، بنابراین میتوانید ببینید
285
00:08:40,640 –> 00:08:42,640
که اکنون پنج ردیف اول خود را در
286
00:08:42,640 –> 00:08:43,039
آنجا داریم
287
00:08:43,039 –> 00:08:45,040
و اگر انواع melb.d را تایپ کنیم، میتوانید
288
00:08:45,040 –> 00:08:47,279
ببینید که در واقع ما اکنون
289
00:08:47,279 –> 00:08:49,519
زمان تاریخ یا ستون تاریخ خود
290
00:08:49,519 –> 00:08:52,080
را به نوع زمان تاریخ تبدیل کردهایم، بنابراین
291
00:08:52,080 –> 00:08:53,680
هر زمان که واقعاً با
292
00:08:53,680 –> 00:08:55,519
سود عصبی کار میکنید باید از دو ستون عبور کنید،
293
00:08:55,519 –> 00:08:58,160
بنابراین زمان تاریخ یا تاریخ.
294
00:08:58,160 –> 00:08:58,800
ستون
295
00:08:58,800 –> 00:09:00,560
و سپس یک ستون مقدار، اما ما
296
00:09:00,560 –> 00:09:02,160
این را در یک ثانیه خواهیم دید، بنابراین اکنون چیزی
297
00:09:02,160 –> 00:09:03,519
که احتمالاً میخواهیم انجام دهیم،
298
00:09:03,519 –> 00:09:05,360
کمی تجزیه و تحلیل دادههای اکتشافی است، بنابراین
299
00:09:05,360 –> 00:09:06,880
در واقع به دنبال این نبودهایم که ببینیم آیا
300
00:09:06,880 –> 00:09:08,320
یک الگوی واقعی وجود دارد یا خیر.
301
00:09:08,320 –> 00:09:09,519
بر حسب دمای ما،
302
00:09:09,519 –> 00:09:10,959
بنابراین چه چیزی می خواهیم d o اکنون می
303
00:09:10,959 –> 00:09:12,640
خواهیم از matplotlib استفاده کنیم که
304
00:09:12,640 –> 00:09:13,519
305
00:09:13,519 –> 00:09:15,440
در اینجا وارد کرده ایم و در واقع
306
00:09:15,440 –> 00:09:17,360
دمای خود را در طول زمان ترسیم می کنیم، بنابراین بیایید ادامه دهیم
307
00:09:17,360 –> 00:09:17,600
308
00:09:17,600 –> 00:09:23,839
و این کار را به خوبی انجام
309
00:09:26,320 –> 00:09:28,800
دهیم تا بتوانید
310
00:09:28,800 –> 00:09:30,800
به وضوح ببینید که در اینجا مقداری از داده های گم شده
311
00:09:30,800 –> 00:09:33,440
وجود دارد. بنابراین به نظر می رسد از سال 2015
312
00:09:33,440 –> 00:09:35,920
تا شاید اواسط سال 2016، به نظر می رسد که ما
313
00:09:35,920 –> 00:09:37,839
برخی از داده های دما را در آنجا از دست داده
314
00:09:37,839 –> 00:09:40,080
ایم، بنابراین ما در حالت ایده آل می خواهیم مطمئن شویم که
315
00:09:40,080 –> 00:09:41,760
هر زمان که
316
00:09:41,760 –> 00:09:43,600
داده های خود را به سود عصبی منتقل می کنیم، مقادیر از دست رفته را نداشته باشیم تا
317
00:09:43,600 –> 00:09:44,720
بتوانید آن را
318
00:09:44,720 –> 00:09:46,800
نسبت دهید. مقادیر مشخصی از دست رفته است، اما
319
00:09:46,800 –> 00:09:48,480
اگر بخش بزرگی را از دست
320
00:09:48,480 –> 00:09:50,320
داده اید، کار را کمی دشوار می کند،
321
00:09:50,320 –> 00:09:51,839
بنابراین کاری که ما می خواهیم انجام دهیم این است
322
00:09:51,839 –> 00:09:53,519
که مجموعه داده های خود را
323
00:09:53,519 –> 00:09:54,720
از سال 2015 قطع کنیم
324
00:09:54,720 –> 00:09:58,080
و فقط از 2015 به بعد استفاده کنیم یا قبل
325
00:09:58,080 –> 00:09:59,360
از این، اساساً به این معنی است که
326
00:09:59,360 –> 00:10:01,519
همه چیز را پس از سال 2015 قطع کرده ایم، بنابراین
327
00:10:01,519 –> 00:10:03,279
همه چیز از اینجا به
328
00:10:03,279 –> 00:10:05,200
بعد از مجموعه داده های ما حذف می شود، بنابراین بیایید
329
00:10:05,200 –> 00:10:19,839
ادامه دهیم و آن را به درستی انجام دهیم.
330
00:10:22,399 –> 00:10:24,399
331
00:10:24,399 –> 00:10:25,519
332
00:10:25,519 –> 00:10:27,440
می توانید ببینید که ما
333
00:10:27,440 –> 00:10:29,200
اکنون فقط داریم e 2015
334
00:10:29,200 –> 00:10:31,279
و قبل از آن، برای انجام این کار، ما
335
00:10:31,279 –> 00:10:32,880
آن را در دو مرحله انجام دادهایم،
336
00:10:32,880 –> 00:10:34,399
بنابراین ابتدا کاری که انجام دادهایم این است
337
00:10:34,399 –> 00:10:36,320
که یک ستون سال جدید ایجاد کردهایم، بنابراین اگر من فقط
338
00:10:36,320 –> 00:10:36,640
بروم
339
00:10:36,640 –> 00:10:39,040
و melb.head را تایپ کنم، میتوانید ببینید که
340
00:10:39,040 –> 00:10:40,800
ما اکنون رفتهایم و
341
00:10:40,800 –> 00:10:42,320
سال خود را استخراج کردهایم، بنابراین اگر برویم و به قسمت
342
00:10:42,320 –> 00:10:44,560
دم نگاه کنیم، باید بتوانیم پایین آن را ببینیم،
343
00:10:44,560 –> 00:10:45,519
344
00:10:45,519 –> 00:10:47,360
بنابراین اولین کاری که انجام دادهایم این است که
345
00:10:47,360 –> 00:10:49,600
رفتهایم و سال خود را از تاریخ خود گرفتهایم تا
346
00:10:49,600 –> 00:10:51,279
این کار را انجام دهیم. melb نوشتیم و سپس
347
00:10:51,279 –> 00:10:52,800
از فهرست دادههایمان عبور میکنیم، بنابراین این
348
00:10:52,800 –> 00:10:54,160
ستون تاریخ ما را به ما میدهد
349
00:10:54,160 –> 00:10:55,839
و سپس ما رفتهایم و از عملکرد نوعی اعمال لامبدا استفاده کردهایم
350
00:10:55,839 –> 00:10:57,680
تا بتوانیم
351
00:10:57,680 –> 00:10:59,680
برویم و yelp خود را استخراج کنیم، بنابراین
352
00:10:59,680 –> 00:11:02,800
نقطه نوشته شده، lambda x را اعمال میکنیم تا این
353
00:11:02,800 –> 00:11:04,399
از طریق هر مقدار در ستون حلقه می زند
354
00:11:04,399 –> 00:11:06,640
و سپس سال خود را استخراج می کنیم تا
355
00:11:06,640 –> 00:11:07,519
آن x نقطه نوشته شده را انجام دهیم
356
00:11:07,519 –> 00:11:09,200
بله، بنابراین این ستون در اینجا
357
00:11:09,200 –> 00:11:10,959
اساساً از طریق هر
358
00:11:10,959 –> 00:11:11,440
مقدار
359
00:11:11,440 –> 00:11:13,440
در ستون تاریخ ما حلقه می زند و فقط
360
00:11:13,440 –> 00:11:15,600
سال را می گیرد و سپس نتایج را در داخل ذخیره می کنیم.
361
00:11:15,600 –> 00:11:17,360
از یک ستون جدید به نام سال و
362
00:11:17,360 –> 00:11:18,959
می بینید که ما اکنون آن را
363
00:11:18,959 –> 00:11:21,360
در ستونی به نام year ov ذخیره کرده ایم پس در اینجا
364
00:11:21,360 –> 00:11:22,640
آنچه رفته ایم و انجام داده ایم این
365
00:11:22,640 –> 00:11:24,160
است که رفته ایم و فیلتری را اعمال کرده ایم، بنابراین دوباره
366
00:11:24,160 –> 00:11:25,200
مشابه کاری که
367
00:11:25,200 –> 00:11:28,320
برای فیلتر کردن بر اساس مکان ملبورن
368
00:11:28,320 –> 00:11:30,079
انجام دادیم، بنابراین در اینجا بر اساس مکان فیلتر کردیم و
369
00:11:30,079 –> 00:11:31,600
ملبورن را
370
00:11:31,600 –> 00:11:33,120
در اینجا گرفتیم. یک سال فیلتر می
371
00:11:33,120 –> 00:11:35,360
شود، بنابراین آنچه که ما اساساً می گوییم
372
00:11:35,360 –> 00:11:37,279
این است که ما
373
00:11:37,279 –> 00:11:40,000
قبل از پایان سال 2015 چیزی نمی خواهیم.
374
00:11:40,000 –> 00:11:42,240
بنابراین همه چیز قبل از سال
375
00:11:42,240 –> 00:11:44,959
2015 و 2015 را شامل می شود و سپس آن را فیلتر
376
00:11:44,959 –> 00:11:46,720
می کنیم. اساساً
377
00:11:46,720 –> 00:11:47,839
تک تک ستونها را
378
00:11:47,839 –> 00:11:49,839
در چارچوب داده melb خود میگیریم و
379
00:11:49,839 –> 00:11:51,680
فریم دادههای melb موجود خود را
380
00:11:51,680 –> 00:11:53,040
با این قاب فیلتر شده لغو میکنیم، بنابراین اکنون میتوانید ببینید
381
00:11:53,040 –> 00:11:54,639
که در واقع چیزی
382
00:11:54,639 –> 00:11:56,800
از سال 2015 گذشته است.
383
00:11:56,800 –> 00:11:58,240
پس کاری که انجام میدهیم این است که استفاده مجدد از
384
00:11:58,240 –> 00:12:00,160
این کد تجسمی که در اینجا
385
00:12:00,160 –> 00:12:01







![فیلم آموزشی: [#JulhoRedis | محتوای انگلیسی] ساختارهای داده احتمالی با پایتون و ردیس](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/F_YlClC8aF0image2.jpg)