در این مطلب، ویدئو گفتار ساده به متن | ASR | بررسی پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:10:34
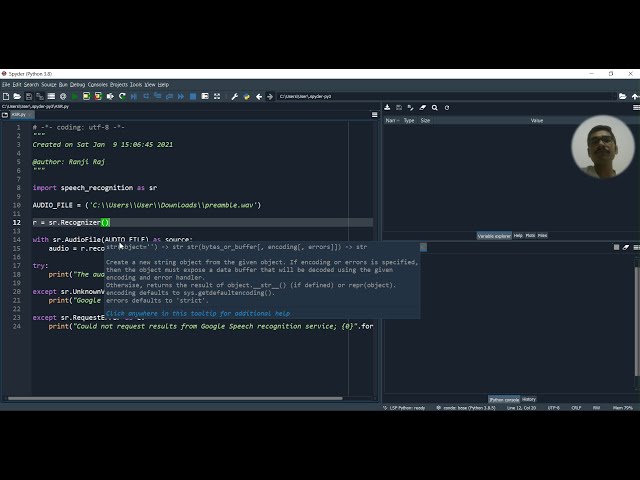
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:01,040 –> 00:00:02,720
سلام مردم، اوه به کانال من خوش آمدید،
2
00:00:02,720 –> 00:00:03,360
3
00:00:03,360 –> 00:00:04,960
بنابراین در ویدیوی امروز
4
00:00:04,960 –> 00:00:06,399
5
00:00:06,399 –> 00:00:09,679
مثال بسیار کوچکی را در پایتون
6
00:00:09,679 –> 00:00:13,040
برای تبدیل گفتار به متن نشان خواهم داد، بنابراین
7
00:00:13,040 –> 00:00:16,079
یک ویدیوی بسیار کوچک و دقیق خواهد بود آه
8
00:00:16,079 –> 00:00:18,080
، رایج ترین مثالی است که
9
00:00:18,080 –> 00:00:19,439
همه
10
00:00:19,439 –> 00:00:22,560
با پایتون انجام می دهند. برای تبدیل از گفتار
11
00:00:22,560 –> 00:00:23,600
به متن،
12
00:00:23,600 –> 00:00:26,720
بنابراین بیایید ببینیم قطعه چیست یا
13
00:00:26,720 –> 00:00:27,519
کد واقعاً چگونه به
14
00:00:27,519 –> 00:00:30,720
نظر می رسد، بنابراین
15
00:00:30,720 –> 00:00:33,680
این صفحه نمایش من است، بنابراین من اساساً این کار را روی spider id انجام می دهم،
16
00:00:33,680 –> 00:00:34,160
17
00:00:34,160 –> 00:00:37,520
بنابراین قبلاً به شما معرفی کرده
18
00:00:37,520 –> 00:00:38,320
19
00:00:38,320 –> 00:00:42,879
ام که spider id چیست. این
20
00:00:42,879 –> 00:00:46,719
برنامه چت بات را روی spider id کدگذاری کردهام،
21
00:00:46,719 –> 00:00:49,840
خب، کتابخانهای که ما از آن استفاده میکنیم
22
00:00:49,840 –> 00:00:53,039
به عنوان تشخیص گفتار نامیده میشود،
23
00:00:53,039 –> 00:00:56,160
بنابراین اگر
24
00:00:56,160 –> 00:00:59,120
این را در سیستم خود
25
00:00:59,120 –> 00:00:59,680
ندارید، به شما پیشنهاد میکنم
26
00:00:59,680 –> 00:01:02,640
آن را از طریق تشخیص گفتار نصب pip نصب کنید.
27
00:01:02,640 –> 00:01:04,479
28
00:01:04,479 –> 00:01:06,960
یا می توانید این کار را روی google collab یا notebook jupyter نیز انجام دهید.
29
00:01:06,960 –> 00:01:09,520
30
00:01:09,520 –> 00:01:13,119
من اساساً از conda استفاده کرده ام
31
00:01:13,119 –> 00:01:15,040
بنابراین عنکبوت اساساً در این محیط conda در حال اجرا
32
00:01:15,040 –> 00:01:17,040
است بنابراین
33
00:01:17,040 –> 00:01:21,360
من اساساً از
34
00:01:21,360 –> 00:01:23,439
خط فرمان conda استفاده می کنم و از این رو من
35
00:01:23,439 –> 00:01:24,479
پایه هستم متحد
36
00:01:24,479 –> 00:01:26,479
این را اجرا میکند یا من کتابخانه تشخیص گفتار را نصب
37
00:01:26,479 –> 00:01:28,080
38
00:01:28,080 –> 00:01:31,280
کردهام و یک elias بهعنوان sr ایجاد میکنم،
39
00:01:31,280 –> 00:01:34,400
بنابراین این شیء
40
00:01:34,400 –> 00:01:40,159
فایل صوتی است، بنابراین
41
00:01:40,159 –> 00:01:43,840
در این مکان فایل صوتی نمونه من است که میتوانم
42
00:01:43,840 –> 00:01:44,399
43
00:01:44,399 –> 00:01:48,640
از آن برای تولید متن استفاده کنم،
44
00:01:48,640 –> 00:01:51,840
بنابراین این در واقع یک فایل صوتی است. برنامه nlp uh
45
00:01:51,840 –> 00:01:54,240
که پردازش زبان طبیعی است
46
00:01:54,240 –> 00:01:57,920
، بنابراین چگونه
47
00:01:57,920 –> 00:02:02,880
wavv مقدمه من به نظر می رسد
48
00:02:03,360 –> 00:02:05,680
، چیزی شبیه به این است، بنابراین این از
49
00:02:05,680 –> 00:02:06,640
50
00:02:06,640 –> 00:02:10,080
مقدمه ما است، بنابراین آنجا
51
00:02:10,080 –> 00:02:12,640
معمولاً این سوگند را در
52
00:02:12,640 –> 00:02:14,319
قانون اساسی می خوانند، بنابراین
53
00:02:14,319 –> 00:02:17,120
من فقط ما مردم را بازی می کنم
54
00:02:17,120 –> 00:02:18,080
ایالات متحده
55
00:02:18,080 –> 00:02:20,239
به منظور تشکیل اتحادیه شرکتی تر،
56
00:02:20,239 –> 00:02:21,599
برقراری عدالت
57
00:02:21,599 –> 00:02:24,080
تضمین می کند که آرامش داخلی برای
58
00:02:24,080 –> 00:02:25,120
دفاع مشترک فراهم شود،
59
00:02:25,120 –> 00:02:27,200
رفاه عمومی را ارتقاء دهد و
60
00:02:27,200 –> 00:02:28,319
نعمت آزادی را
61
00:02:28,319 –> 00:02:30,879
برای خودمان و آیندگان خود تضمین کنیم
62
00:02:30,879 –> 00:02:32,800
تا این قانون اساسی را برای
63
00:02:32,800 –> 00:02:36,720
ایالات متحده آمریکا تعیین و تنظیم کنیم،
64
00:02:36,720 –> 00:02:40,480
پس اوه علاوه بر این، این یک
65
00:02:40,480 –> 00:02:44,160
لهجه بسیار آمریکایی است، بنابراین
66
00:02:44,160 –> 00:02:47,519
بسیاری از کلمات، برخی کلمات جدید،
67
00:02:47,519 –> 00:02:49,840
برخی کلمات قانون اساسی، برخی کلمات سیاسی هستند،
68
00:02:49,840 –> 00:02:50,560
69
00:02:50,560 –> 00:02:52,959
بنابراین ممکن است این امکان وجود داشته باشد که بسیاری از شما
70
00:02:52,959 –> 00:02:54,800
کلمه
71
00:02:54,800 –> 00:02:58,080
واقعی را متوجه نشدید، بنابراین
72
00:02:58,080 –> 00:03:00,560
جادوی پایتون می آید که
73
00:03:00,560 –> 00:03:02,000
74
00:03:02,000 –> 00:03:05,200
این
75
00:03:05,200 –> 00:03:08,159
صدا را به یک قالب متنی تبدیل می کند، به طوری که وقتی
76
00:03:08,159 –> 00:03:09,040
آن را می خوانید
77
00:03:09,040 –> 00:03:12,400
در واقع قابل مشاهده باشد، خوب پس
78
00:03:12,400 –> 00:03:15,280
بلندگو چیست گفته شده در واقع در
79
00:03:15,280 –> 00:03:16,239
آن کلمات
80
00:03:16,239 –> 00:03:19,920
همه به کلمات تبدیل می شوند،
81
00:03:19,920 –> 00:03:23,280
بنابراین بیایید ببینیم چگونه این کار انجام می شود، بنابراین
82
00:03:23,280 –> 00:03:26,319
در تشخیص گفتار ما یک کلاس داریم
83
00:03:26,319 –> 00:03:27,200
که به عنوان شناساگر نامیده می شود
84
00:03:27,200 –> 00:03:30,959
، بنابراین اساساً کاری که این
85
00:03:30,959 –> 00:03:32,159
کلاس انجام می دهد این است
86
00:03:32,159 –> 00:03:35,280
که یک فایل ورودی صوتی را می گیرد.
87
00:03:35,280 –> 00:03:38,400
در داخل این شناساگر روشی وجود دارد
88
00:03:38,400 –> 00:03:40,799
یا عملکرد
89
00:03:40,799 –> 00:03:43,760
این کلاس شناساگر این است که
90
00:03:43,760 –> 00:03:47,360
تمام فایل های صوتی را
91
00:03:47,360 –> 00:03:50,480
که گفته می شود به فرمت متن تبدیل می
92
00:03:50,480 –> 00:03:53,920
کند، بسیار خوب، پس از این کلاس،
93
00:03:53,920 –> 00:03:56,959
ما در حال ایجاد یک شی هستیم که r است،
94
00:03:56,959 –> 00:04:00,159
بنابراین اکنون آنچه انجام می دهیم باز می شود.
95
00:04:00,159 –> 00:04:01,840
با فایل صوتی
96
00:04:01,840 –> 00:04:05,040
پس با فایل صوتی sr dot
97
00:04:05,040 –> 00:04:08,319
و داخل آن در واقع
98
00:04:08,319 –> 00:04:13,120
فایل صوتی را منتقل می کند که این wav خاص
99
00:04:13,120 –> 00:04:16,798
و به خاطر داشته باشید که این برنامه خاص
100
00:04:16,798 –> 00:04:17,839
101
00:04:17,839 –> 00:04:21,759
فقط برای یک wav کار می کند
102
00:04:21,759 –> 00:04:25,600
زیرا اگر مقداری mp3 دارید یا mp4
103
00:04:25,600 –> 00:04:29,520
mp4 برای ویدیو است اما برای mp3
104
00:04:29,520 –> 00:04:32,800
و اگر
105
00:04:32,800 –> 00:04:34,720
پسوندهای دیگری دارید ممکن است کار
106
00:04:34,720 –> 00:04:35,840
نکند زیرا
107
00:04:35,840 –> 00:04:38,000
باید کار دیگری انجام دهید تا
108
00:04:38,000 –> 00:04:41,440
صریحاً آن را
109
00:04:41,440 –> 00:04:44,800
درست کنید، بنابراین با این
110
00:04:44,800 –> 00:04:47,520
فایل صوتی است که اوه اوه دیگری است. متد
111
00:04:47,520 –> 00:04:47,840
112
00:04:47,840 –> 00:04:50,720
یا سازندهای که در
113
00:04:50,720 –> 00:04:52,160
تشخیص گفتار وجود دارد،
114
00:04:52,160 –> 00:04:55,840
بنابراین فایل صوتی را به عنوان منبع ارسال میکنید
115
00:04:55,840 –> 00:04:57,120
،
116
00:04:57,120 –> 00:05:00,400
پس کاری که انجام میدهید این است که سعی کنید متدی را فراخوانی کنید
117
00:05:00,400 –> 00:05:01,360
که
118
00:05:01,360 –> 00:05:04,800
رکورد است و در داخل این رکورد
119
00:05:04,800 –> 00:05:05,759
من منبع خود را ارسال میکنم
120
00:05:05,759 –> 00:05:07,840
تا در واقع من چه چیزی است. منبع منبع
121
00:05:07,840 –> 00:05:09,840
چیزی جز فایل صوتی من نیست، بنابراین به این صورت است
122
00:05:09,840 –> 00:05:11,360
که کدگذاری می شود
123
00:05:11,360 –> 00:05:14,240
یا نوشته می شود و سپس آن را در متغیری به نام audio نگه می دارید،
124
00:05:14,240 –> 00:05:14,479
125
00:05:14,479 –> 00:05:18,400
126
00:05:18,400 –> 00:05:21,280
بنابراین یک استثنا معمولی
127
00:05:21,280 –> 00:05:22,160
128
00:05:22,160 –> 00:05:25,039
وجود دارد که یک بلوک try accept وجود دارد که ما می
129
00:05:25,039 –> 00:05:25,840
نویسیم
130
00:05:25,840 –> 00:05:28,240
تا فقط در صورتی که
131
00:05:28,240 –> 00:05:29,199
متوجه
132
00:05:2






![فیلم آموزشی: آموزش Blender Python: لیست ها - ایجاد، افزودن و حذف [یادگیری پایتون برای مبتدیان] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/5T0sSKH2_0oimage2.jpg)