

در این مطلب، ویدئو TechBytes: استفاده از پایتون با Vantage | 1. مقدمه و ارتباطات با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:10:52
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:04,890 –> 00:00:08,280
[موسیقی]
2
00:00:10,960 –> 00:00:11,360
سلام
3
00:00:11,360 –> 00:00:13,200
این الکساندر کولووس است با
4
00:00:13,200 –> 00:00:15,120
مهندسی محصول داده سوم
5
00:00:15,120 –> 00:00:16,800
شما در حال تماشای نسخه سوم
6
00:00:16,800 –> 00:00:18,240
بایت های فناوری داده هستید
7
00:00:18,240 –> 00:00:20,960
این قسمت اول از سری استفاده از
8
00:00:20,960 –> 00:00:24,240
پایتون با teradata vantage
9
00:00:24,240 –> 00:00:26,160
r است و پایتون نقش برجسته ای در
10
00:00:26,160 –> 00:00:27,680
موقعیت سوم داده دارد. اکوسیستم زبان،
11
00:00:27,680 –> 00:00:28,960
12
00:00:28,960 –> 00:00:30,800
معماری موازی
13
00:00:30,800 –> 00:00:32,479
14
00:00:32,479 –> 00:00:34,800
برتر برای عملکرد مقیاسپذیری و عملیاتیسازی زمانی
15
00:00:34,800 –> 00:00:37,280
که از rn python در
16
00:00:37,280 –> 00:00:38,559
گرههای موتور پیشرفته sql استفاده میکنید،
17
00:00:38,559 –> 00:00:40,559
بهویژه Vantage یک
18
00:00:40,559 –> 00:00:42,640
مسیر مقیاسبندی معماری را
19
00:00:42,640 –> 00:00:44,399
برای زبانهای عمدتاً رشتهای و
20
00:00:44,399 –> 00:00:46,239
محدود به حافظه فراهم میکند و
21
00:00:46,239 –> 00:00:48,480
اجرای
22
00:00:48,480 –> 00:00:50,320
مجموعه دادههای بزرگ در تجزیه و تحلیلهای پیچیده را آزاد میکند.
23
00:00:50,320 –> 00:00:52,399
24
00:00:52,399 –> 00:00:54,559
سربار زبان تفسیری را کاهش میدهد
25
00:00:54,559 –> 00:00:57,280
و تولید گردشهای کاری پایتون ما را تسهیل میکند.
26
00:00:57,280 –> 00:01:00,320
27
00:01:00,320 –> 00:01:03,039
این سری تکبایت بر مزیت بین دادهای پایتون تمرکز دارد،
28
00:01:03,039 –> 00:01:04,559
29
00:01:04,559 –> 00:01:06,960
ما بهطور خاص بر روی بسته سوم داده
30
00:01:06,960 –> 00:01:09,439
برای پایتون teradata ml
31
00:01:09,439 –> 00:01:11,200
در چند سال اخیر تمرکز کردهایم، این
32
00:01:11,200 –> 00:01:13,680
کتابخانه الحاقی به یک کلید اصلی تبدیل شده است.
33
00:01:13,680 –> 00:01:15,759
python analytics advanta ge
34
00:01:15,759 –> 00:01:17,360
third data ml دارای
35
00:01:17,360 –> 00:01:18,799
ویژگیهای جذاب متنوعی است و
36
00:01:18,799 –> 00:01:21,200
مهمتر از همه
37
00:01:21,200 –> 00:01:23,119
از طریق
38
00:01:23,119 –> 00:01:25,040
پایگاه داده پیشرفته موتور دنبالهای، اتصال برتر مشتریان را امکانپذیر
39
00:01:25,040 –> 00:01:27,040
میسازد. سومین شی قاب داده ml data را معرفی کرد
40
00:01:27,040 –> 00:01:29,600
که از
41
00:01:29,600 –> 00:01:32,159
قاب داده پانداها برای مدیریت کارآمد
42
00:01:32,159 –> 00:01:33,920
دادهها ارائه میکند.
43
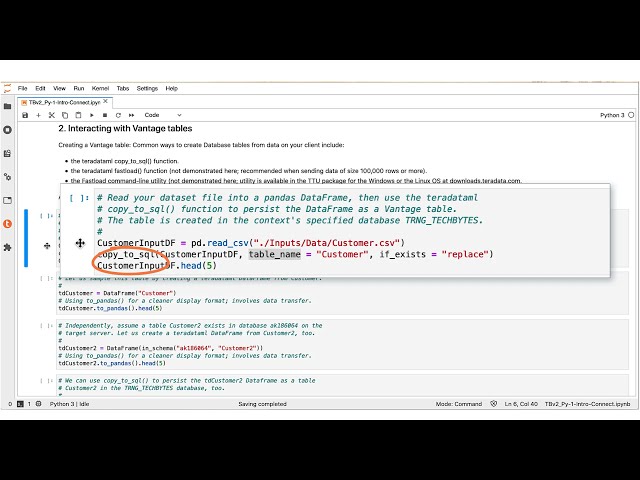
00:01:33,920 –> 00:01:36,240
کتابخانه محبوب کیمیاگری sql برای
44
00:01:36,240 –> 00:01:38,159
پایگاههای داده رابطهای
45
00:01:38,159 –> 00:01:40,479
و دارای مجموعه گستردهای از
46
00:01:40,479 –> 00:01:42,240
ابزارهای پایتون و توابع مدیریت پایگاه داده
47
00:01:42,240 –> 00:01:44,640
برای تعامل با
48
00:01:44,640 –> 00:01:46,159
ویژگیهای اضافی برتر شامل
49
00:01:46,159 –> 00:01:48,479
دستکاری دادهها با sql مانند دستور زبان از طریق
50
00:01:48,479 –> 00:01:51,200
روشهای پایتون و عملگرها
51
00:01:51,200 –> 00:01:53,280
توابع python wrapper برای تعداد زیادی از
52
00:01:53,280 –> 00:01:55,280
توابع تحلیلی جدیدتر. و ابزارهایی
53
00:01:55,280 –> 00:01:56,560
که با
54
00:01:56,560 –> 00:01:58,719
امکانات فهرستنویسی مدل وانتاژ ارائه میشوند، به طوری که
55
00:01:58,719 –> 00:02:00,880
میتوانید مدلهایی را که بر روی آنها میسازید، ذخیره کنید و دوباره از آنها استفاده کنید و
56
00:02:00,880 –> 00:02:02,399
57
00:02:02,399 –> 00:02:03,840
یک رابط را برای
58
00:02:03,840 –> 00:02:06,159
شی پایگاه داده عملگر جدول اسکریپت ذخیره کنید تا بتوانید
59
00:02:06,159 –> 00:02:06,640
60
00:02:06,640 –> 00:02:08,639
اسکریپتهای پایتون را بهصورت بومی در
61
00:02:08,639 –> 00:02:10,800
پایگاه داده و همچنین یک داکر اجرا کنید.
62
00:02:10,800 –> 00:02:12,800
محیط sandbox مبتنی بر به طوری که شما ج آزمایش
63
00:02:12,800 –> 00:02:14,640
این اسکریپتها از
64
00:02:14,640 –> 00:02:17,040
قبل، آخرین نسخه ml دادههای آنها را
65
00:02:17,040 –> 00:02:18,480
همیشه میتوانید در مخزن خط لوله پیدا
66
00:02:18,480 –> 00:02:19,680
کنید،
67
00:02:19,680 –> 00:02:21,599
در حالی که میتوانید
68
00:02:21,599 –> 00:02:23,520
مستندات و نمونههای گستردهای را در
69
00:02:23,520 –> 00:02:25,120
سایت سوم اسناد دادهها
70
00:02:25,120 –> 00:02:28,800
در docs.thirddata.com بیابید
71
00:02:28,800 –> 00:02:30,720
تا به راحتی این سری techbyte را دنبال کنید.
72
00:02:30,720 –> 00:02:33,040
73
00:02:33,040 –> 00:02:34,400
درک خوبی از زبان پایتون
74
00:02:34,400 –> 00:02:35,040
75
00:02:35,040 –> 00:02:36,879
و همچنین درک کلی از
76
00:02:36,879 –> 00:02:39,200
پلتفرم teradata Vantage
77
00:02:39,200 –> 00:02:41,360
در این سری نکات کلیدی این است
78
00:02:41,360 –> 00:02:43,360
که کار با پایتون را در
79
00:02:43,360 –> 00:02:45,440
پلتفرم Vantage از مشتری خود
80
00:02:45,440 –> 00:02:47,280
با بسته teradata برای پایتون
81
00:02:47,280 –> 00:02:49,360
teradata ml به تصویر بکشید
82
00:02:49,360 –> 00:02:50,879
که چهار بخش دارد. در
83
00:02:50,879 –> 00:02:52,720
سری techbyte فعلی
84
00:02:52,720 –> 00:02:56,319
این قسمت اول است که در آن یک مقدمه کلی انجام
85
00:02:56,319 –> 00:02:58,720
میدهیم، نحوه اتصال به
86
00:02:58,720 –> 00:03:00,480
پایگاه داده موتور پیشرفته پیشرفته پیشرفته
87
00:03:00,480 –> 00:03:01,760
با دادههای ml سوم را
88
00:03:01,760 –> 00:03:03,519
نشان میدهیم و برخی از عملیاتهای اساسی را
89
00:03:03,519 –> 00:03:06,080
با کتابخانه نشان
90
00:03:06,080 –> 00:03:07,440
میدهیم، سپس به
91
00:03:07,440 –> 00:03:09,360
نمایش در این مطلب ادامه میدهیم. قسمت 1
92
00:03:09,360 –> 00:03:11,519
استفاده از پایتون با سومین
93
00:03:11,519 –> 00:03:14,080
سری بایت های فناوری برتر داده
94
00:03:14,080 –> 00:03:15,760
در حال حاضر ویدیویی که از
95
00:03:15,760 –> 00:03:17,680
این نوت بوک jupyter برای نشان دادن
96
00:03:17,680 –> 00:03:19,280
ویژگی های زیر استفاده
97
00:03:19,280 –> 00:03:21,120
خواهیم کرد، نحوه اتصال از یک
98
00:03:21,120 –> 00:03:23,120
ماشین کلاینت به یک
99
00:03:23,120 –> 00:03:25,519
پایگاه داده موتور پیشرفته پیشرفته را خواهیم دید، نحوه
100
00:03:25,519 –> 00:03:27,440
ایجاد جداول پایگاه داده از داده های خود
101
00:03:27,440 –> 00:03:28,879
و ایجاد
102
00:03:28,879 –> 00:03:32,000
قاب های داده میلی لیتری مانند پانداها را مشاهده خواهیم کرد. از جداول و
103
00:03:32,000 –> 00:03:33,680
همچنین نحوه فهرست کردن
104
00:03:33,680 –> 00:03:35,599
جداول و رها کردن جداول را در یک اتصال برتر خواهیم دید،
105
00:03:35,599 –> 00:03:37,760
106
00:03:37,760 –> 00:03:39,760
بیایید ابتدا با بارگیری
107
00:03:39,760 –> 00:03:46,159
کتابخانههایی که از آنها
108
00:03:46,159 –> 00:03:48,480
استفاده خواهیم کرد، شروع کنیم.
109
00:03:48,480 –> 00:03:50,959
110
00:03:50,959 –> 00:03:52,480
111
00:03:52,480 –> 00:03:54,720
کتابخانههای معروفی مانند پانداها در
112
00:03:54,720 –> 00:03:56,959
مرحله بعدی ما میخواهیم یک اتصال برتر
113
00:03:56,959 –> 00:03:58,000
114
00:03:58,000 –> 00:04:01,680
به پایگاه داده موتور پیشرفته sql هدف برقرار
115
00:04:01,680 –> 00:04:04,000
کنیم، بهویژه از تابع ایجاد زمینه
116
00:04:04,000 –> 00:04:06,000
برای دادههای ml خود استفاده میکنیم تا
117
00:04:06,000 –> 00:04:07,040
میزبان هدف
118
00:04:07,040 –> 00:04:11,040
و اعتبارنامهها را برای اتصال خود مشخص کنیم،
119
00:04:11,200 –> 00:04:13,680
اکنون میبینیم که متصل هستیم. و
120
00:04:13,680 –> 00:04:15,519
میتوانیم به بخش زیر ادامه دهیم تا در
121
00:04:15,519 –> 00:04:17,519
مورد تعامل با آسیاب داده خود
122
00:04:17,519 –> 00:04:19,519
با جداول در پایگاه داده پیشرفته موتور sql
123
00:04:19,519 –> 00:04:21,279
124
00:04:21,279 –> 00:04:23,600
برای ایجاد موقعیت برتر بحث کنیم. جدول از داده های شما
125
00:04:23,600 –> 00:04:25,840
ساده ترین راه استفاده از
126
00:04:25,840 –> 00:04:29,120
تابع copy to sql teradataml
127
00:04:29,120 –> 00:04:31,280
در این مثال اول است. من با یک
128
00:04:31,280 –> 00:04:32,240
فایل داده
129
00:04:32,240 –> 00:04:35,759
به نام مشتری csv شروع می کنم و آن را
130
00:04:35,759 –> 00:04:38,560
از کلاینت خود به پایتون وارد می کنم و با ایجاد یک
131
00:04:38,560 –> 00:04:40,479
قاب داده پاندا
132
00:04:40,479 –> 00:04:43,840
همانطور که در اینجا می بینید ورودی مشتری df
133
00:04:43,840 –> 00:04:45,919
و کپی در تابع sql که در
134
00:04:45,919 –> 00:04:48,000
مرحله بعد از آن استفاده می کنم می تواند یک شی قاب داده
135
00:04:48,000 –> 00:04:50,960
مانند ورودی مشتری df را بگیرد و
136
00:04:50,960 –> 00:04:52,800
یک جدول در پایگاه داده با
137
00:04:52,800 –> 00:04:54,400
نام جدول مشخص شده توسط کاربر بسازد
138
00:04:54,400 –> 00:04:58,400
که در اینجا مشتری است.
139
00:04:58,400 –> 00:05:02,080
من عبارات این بلوک را
140
00:05:02,080 –> 00:05:05,120
با درخواست یک چند ردیف نمونه از
141
00:05:05,120 –> 00:05:06,320
قاب داده پانداها
142
00:05:06,320 –> 00:05:11,840
به طوری که بتوانیم داده های
143
00:05:12,880 –> 00:05:15,600
بعدی را بررسی کنیم تا محتویات جدول را
144
00:05:15,600 –>







![فیلم آموزشی: نحوه نصب پایتون 3.10.1 در ویندوز 10/11 [ به روز رسانی 2022 ] راهنمای کامل با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/0xwezKlB9Aoimage2.jpg)


