در این مطلب، ویدئو یادگیری ماشین: رگرسیون خطی چندگانه پایتون | پیش بینی قیمت خانه | تجزیه و تحلیل پیش بینی کننده با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:12:04
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,170 –> 00:00:05,779
[موسیقی]
2
00:00:06,160 –> 00:00:09,200
سلام و خوش آمدید و همه امروز
3
00:00:09,200 –> 00:00:11,280
ما با
4
00:00:11,280 –> 00:00:14,000
تجزیه و تحلیل پیشبینیکننده در ویدیوی قبلی که
5
00:00:14,000 –> 00:00:16,640
به رگرسیون خطی ساده نگاه کردیم ادامه خواهیم داد.
6
00:00:16,640 –> 00:00:18,640
مدل رگرسیون خطی ساده
7
00:00:18,640 –> 00:00:21,359
متغیر هدف را با استفاده از یک
8
00:00:21,359 –> 00:00:23,119
متغیر مستقل
9
00:00:23,119 –> 00:00:25,760
پیشبینی
10
00:00:25,760 –> 00:00:28,320
میکند. برای یافتن رابطه
11
00:00:28,320 –> 00:00:30,800
بین هدف و
12
00:00:30,800 –> 00:00:34,000
متغیرهای مستقل استفاده می شود که امروز آن را گسترش می دهیم
13
00:00:34,000 –> 00:00:36,160
و نحوه استفاده از
14
00:00:36,160 –> 00:00:39,040
رگرسیون خطی چندگانه را که به عنوان رگرسیون چندگانه نیز شناخته می شود
15
00:00:39,040 –> 00:00:42,320
استفاده می کنیم،
16
00:00:42,320 –> 00:00:44,960
زمانی که یک متغیر در یک مجموعه داده
17
00:00:44,960 –> 00:00:48,000
برای ایجاد یک مدل خوب کافی نیست از رگرسیون چندگانه استفاده می کنیم.
18
00:00:48,000 –> 00:00:50,640
برای پیشبینی دقیق در این ویدیو
19
00:00:50,640 –> 00:00:53,120
، اگر
20
00:00:53,120 –> 00:00:54,960
اولین ویدیو را ندیدهاید، به رگرسیون چندگانه میپردازیم،
21
00:00:54,960 –> 00:00:57,039
این زمان خوبی برای مکث و بررسی
22
00:00:57,039 –> 00:01:00,160
آن است،
23
00:01:00,160 –> 00:01:02,559
قبل از اینکه بخواهیم یک مدل با استفاده از
24
00:01:02,559 –> 00:01:05,600
پایتون بسازیم، لینک در توضیحات زیر است. نیاز به در نظر گرفتن چند چیز است که
25
00:01:05,600 –> 00:01:07,840
افزودن متغیر بیشتر همیشه
26
00:01:07,840 –> 00:01:10,560
مفید نیست زیرا ممکن است مدل
27
00:01:10,560 –> 00:01:13,520
بیش از حد مناسب باشد و همچنین ممکن است بسیار پیچیده
28
00:01:13,520 –> 00:01:15,680
شود. مدل آموزشدیده شده
29
00:01:15,680 –> 00:01:18,320
با دادههای جدید تعمیم نمییابد و فقط بر
30
00:01:18,320 –> 00:01:21,200
روی دادههای آموزشدیده کار میکند و
31
00:01:21,200 –> 00:01:23,600
انحراف در دادهها ممکن است بر دقت پیشبینیها تأثیر بگذارد،
32
00:01:23,600 –> 00:01:26,400
بنابراین ما
33
00:01:26,400 –> 00:01:28,880
باید قبل از
34
00:01:28,880 –> 00:01:31,439
ساخت یک مدل به این مسائل بپردازیم. سوم باید
35
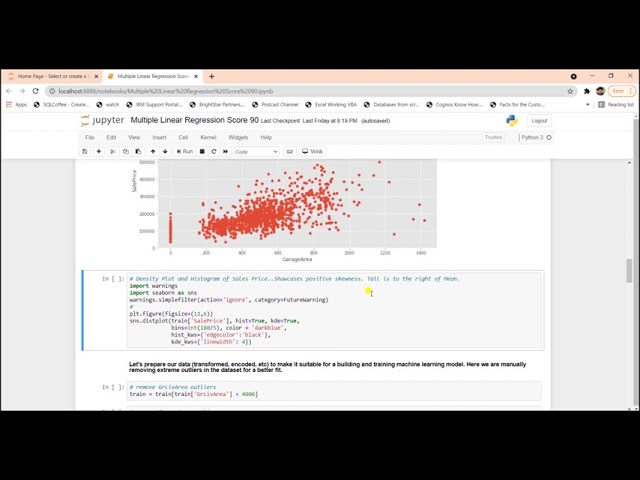
00:01:31,439 –> 00:01:33,439
متغیرهای مناسب را انتخاب کنیم. ساختن
36
00:01:33,439 –> 00:01:35,680
بهترین مدل این فرآیند انتخاب
37
00:01:35,680 –> 00:01:39,040
متغیرها انتخاب ویژگی نامیده می شود که
38
00:01:39,040 –> 00:01:41,280
39
00:01:41,280 –> 00:01:44,000
با مثال های عملی به
40
00:01:44,000 –> 00:01:46,240
این نکات می پردازیم، بیایید به دفترچه یادداشت jupyter شیرجه بزنیم و ببینیم چگونه
41
00:01:46,240 –> 00:01:48,799
یک مدل رگرسیون خطی با
42
00:01:48,799 –> 00:01:50,079
43
00:01:50,079 –> 00:01:52,320
نوت بوک کامل پایتون به همراه مجموعه داده های
44
00:01:52,320 –> 00:01:55,040
موجود در آن می سازیم.
45
00:01:55,040 –> 00:01:57,600
لینک github در توضیحات زیر است، طبق
46
00:01:57,600 –> 00:02:00,399
معمول در بالا، من
47
00:02:00,399 –> 00:02:02,880
کتابخانه های مورد نیاز را وارد می کنم، مطمئن شوید که
48
00:02:02,880 –> 00:02:04,960
این کتابخانه ها را قبل از
49
00:02:04,960 –> 00:02:07,200
اجرای این کد نصب کرده اید، می توانید
50
00:02:07,200 –> 00:02:09,679
کتابخانه ها را در نوت بوک
51
00:02:09,679 –> 00:02:12,560
jupyter با دستور pip نصب کنید یا می توانید
52
00:02:12,560 –> 00:02:14,239
خط فرمان را اجرا کنید.
53
00:02:14,239 –> 00:02:16,480
و یک دستور pip به همراه
54
00:02:16,480 –> 00:02:19,680
کتابخانه صادر کنید تا آن کتابخانه ها را نصب کنید
55
00:02:19,680 –> 00:02:22,239
ابتدا داده ها را می خوانیم و آن را
56
00:02:22,239 –> 00:02:25,200
به یک قاب داده پاندا با
57
00:02:25,200 –> 00:02:27,840
روش pandas read csv تبدیل کنید، من قصد دارم این سلول را
58
00:02:27,840 –> 00:02:29,840
با میانبر صفحه کلید
59
00:02:29,840 –> 00:02:32,560
Shift به اضافه enter اجرا کنم یا می توانید سلول را انتخاب کنید
60
00:02:32,560 –> 00:02:33,519
61
00:02:33,519 –> 00:02:36,080
و روی دکمه run در منوی
62
00:02:36,080 –> 00:02:37,280
بالای
63
00:02:37,280 –> 00:02:40,239
مجموعه داده ما کلیک کنید. به نظر می رسد این است. یک
64
00:02:40,239 –> 00:02:44,000
مجموعه داده کگل شامل تقریباً 1400
65
00:02:44,000 –> 00:02:47,440
ردیف با 81 ویژگی ویژگی است،
66
00:02:47,440 –> 00:02:49,920
متغیر هدف در این مجموعه داده
67
00:02:49,920 –> 00:02:52,640
قیمت فروش است، هدف این است که از
68
00:02:52,640 –> 00:02:56,319
تجزیه و تحلیل داده های اکتشافی یا
69
00:02:56,319 –> 00:02:58,400
eda استفاده کنید، البته اگر با eda آشنایی ندارید،
70
00:02:58,400 –> 00:03:02,640
ویدیوی من را در این مورد بررسی کنید. لینک eda
71
00:03:02,640 –> 00:03:04,480
در توضیحات زیر است
72
00:03:04,480 –> 00:03:06,400
که به ما در فرآیند پاکسازی دادهها
73
00:03:06,400 –> 00:03:09,920
و پیش پردازش دادهها قبل
74
00:03:09,920 –> 00:03:12,640
از شروع ساخت مدل واقعی کمک میکند،
75
00:03:12,640 –> 00:03:15,280
اجازه دهید با فرآیند eda شروع
76
00:03:15,280 –> 00:03:17,840
کنیم و میتوانیم بررسی کنیم که چه تعداد مشاهدات و
77
00:03:17,840 –> 00:03:20,000
ستونها در چارچوب دادههای خود داریم. با
78
00:03:20,000 –> 00:03:22,400
فراخوانی تابع shape
79
00:03:22,400 –> 00:03:26,080
مانند قبل، حدود 1400 سطر و 81
80
00:03:26,080 –> 00:03:27,200
ستون داریم،
81
00:03:27,200 –> 00:03:28,560
بیایید
82
00:03:28,560 –> 00:03:32,000
مقادیر تهی را در مجموعه داده با استفاده از تابع is n بررسی کنیم،
83
00:03:32,000 –> 00:03:34,239
مقادیر زیادی
84
00:03:34,239 –> 00:03:37,200
در مجموعه داده ما وجود ندارد و ما باید
85
00:03:37,200 –> 00:03:39,680
با حذف اینها میتوانیم روش توصیف را
86
00:03:39,680 –> 00:03:42,640
برای نشان دادن میانگین قیمت فروش
87
00:03:42,640 –> 00:03:45,840
خانهای که نزدیک به 180 است و
88
00:03:45,840 –> 00:03:47,840
بیشتر مقادیر در
89
00:03:47,840 –> 00:03:50,560
محدوده سی و چهار هزار تا هفتصد
90
00:03:50,560 –> 00:03:52,480
و پنجاه و پنج هزار قرار میگیرند،
91
00:03:52,480 –> 00:03:54,799
میتوانیم از همبستگی برای انتخاب
92
00:03:54,799 –> 00:03:57,599
مناسب استفاده کنیم. ویژگیهای مدل ما در
93
00:03:57,599 –> 00:03:59,760
مرحله بعدی نشان دادن رابطه
94
00:03:59,760 –> 00:04:02,480
بین ستونها برای بررسی همبستگی
95
00:04:02,480 –> 00:04:05,120
بین ویژگیها و هدف
96
00:04:05,120 –> 00:04:08,080
بالاترین ویژگی مرتبط با قیمت فروش است
97
00:04:08,080 –> 00:04:11,040
که نمره کیفیت کلی به دنبال
98
00:04:11,040 –> 00:04:13,200
آن منطقه نشیمن بالای زمین که
99
00:04:13,200 –> 00:04:15,200
حدود 71 درصد است
100
00:04:15,200 –> 00:04:18,560
و مساحت گاراژ است. 64
101
00:04:18,560 –> 00:04:21,680
و تعداد گاراژ خودرو که 62
102
00:04:21,680 –> 00:04:23,759
درصد است، شما همچنین دارای کمترین
103
00:04:23,759 –> 00:04:26,000
ویژگیهای همبستگی هستید، ما به سادگی میتوانیم
104
00:04:26,000 –> 00:04:27,840
این ویژگیها را از مجموعه دادهها حذف
105
00:04:27,840 –> 00:04:30,479
کنیم، بیایید این متغیرها را به صورت جداگانه
106
00:04:30,479 –> 00:04:32,880
در برابر قیمت فروش در یک نمودار پراکنده رسم کنیم
107
00:04:32,880 –> 00:04:35,199
تا قدرت رابطه
108
00:04:35,199 –> 00:04:38,080
را بررسی کنیم و مقادیر پرت را بررسی کنیم. نقاط پرت می
109
00:04:38,080 –> 00:04:40,320
توانند با
110
00:04:40,320 –> 00:04:42,960
دور کردن خط رگرسیون تخمینی از
111
00:04:42,960 –> 00:04:45,520
موقعیت واقعی آن، ابتدا مدل رگرسیون را تحت تأثیر قرار دهند. از آنجایی
112
00:04:45,520 –> 00:04:47,759
که رابطه بین
113
00:04:47,759 –> 00:04:50,720
مساحت بالای
114
00:04:50,720 –> 00:04:53,520
زمین افزایش مییابد، میتوانیم ببینیم که مساحت بالای زمین افزایش مییابد، قیمت فروش نیز افزایش مییابد،
115
00:04:53,520 –> 00:04:54,960
116
00:04:54,960 –> 00:04:57,680
اما پس از 4000، چند نقطه
117
00:04:57,680 –> 00:05:00,560
پرت در سطح بالای
118
00:05:00,560 –> 00:05:02,720
زمین در سمت راست وجود دارد و
119
00:05:02,720 –> 00:05:05,360
قیمت فروش کاهش مییابد. همچنین
120
00:05:05,360 –> 00:05:08,000
نقاط داده کمی در بالا وجود دارد، بنابراین این
121
00:05:08,000 –> 00:05:10,960
نقاط پرت هستند و ما آنها را حذف خواهیم کرد همچنین
122
00:05:10,960 –> 00:05:13,520
با نگاه کردن به نمودار برای منطقه گاراژ،
123
00:05:13,520 –> 00:05:15,919
میتوانیم ببینیم که پس از آستانه 1200s نقاط پرت وجود دارد،
124
00:05:15,919 –> 00:05:19,520
بنابراین باید
125
00:05:19,520 –> 00:05:22,240
آنها را حذف کنیم. خوب، من
126
00:05:22,240 –> 00:05:24,800
تشخیص و حذف نقاط پرت را
127
00:05:24,800 –> 00:05:27,840
در آموزش ویرایش خود به طور مفصل پوشش دادم، بنابراین اگر به اطلاعات بیشتری نیاز دارید،
128
00:05:27,840 –> 00:05:29,840
آن
129
00:05:29,840 –> 00:05:31,759
ویدیو را بررسی کنید، بیایید توزیع داده ها را
130
00:05:31,759 –> 00:05:34,479
با نمودار چگالی بررسی کنیم، من می
131
00:05:34,479 –> 00:05:37,840
خواهم نمودار چگالی را از seaborn رسم کنم
132
00:05:37,840 –> 00:05:41,039
و به آن می دهم ستون قیمت فروش و
133
00:05:41,039 –> 00:05:43,600
همانطور که می بینید به نظر می رسد که نقطه داده ما
134
00:05:43,600 –> 00:05:46,000
دارای یک انحراف مثبت است زیرا می بینیم
135
00:05:46,000 –> 00:05:48,639
که یک دم بلند در سمت راست وجود دارد و
136
00:05:48,639 –> 00:05:50,560
به نظر می رسد بیشتر توزیع
137
00:05:50,560 –> 00:05:53,120
در سمت چپ میانگین قرار دارد. o
138
00:05:53,120 –> 00:05:55,600
ما باید به این موضوع نیز بپردازیم،
139
00:05:55,600 –> 00:05:57,600
اجازه دهید در مراحل آمادهسازی دادهها
140