در این مطلب، ویدئو آموزش Python Quants 13 – Deep Learning – Financial Time Series Predict | توسعه دهندگان Refinitiv با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:17:21
تصاویر این ویدئو:

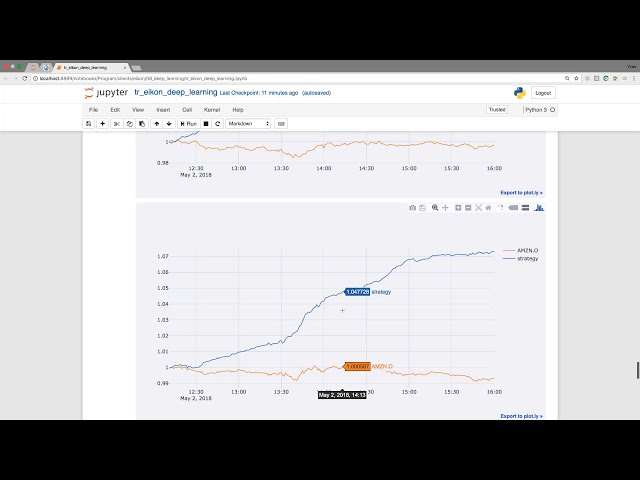
قسمتی از زیرنویس این فیلم:
00:00:03,600 –> 00:00:04,240
2
00:00:04,240 –> 00:00:07,120
سلام و به این آموزش icon data api خوش آمدید.
3
00:00:07,120 –> 00:00:08,639
4
00:00:08,639 –> 00:00:11,120
5
00:00:11,120 –> 00:00:12,559
6
00:00:12,559 –> 00:00:16,079
7
00:00:16,079 –> 00:00:17,840
8
00:00:17,840 –> 00:00:19,439
9
00:00:19,439 –> 00:00:22,720
10
00:00:22,720 –> 00:00:25,599
البته
11
00:00:25,599 –> 00:00:26,080
12
00:00:26,080 –> 00:00:28,400
تا امروز در بسیاری از حوزههای مختلف از شبکههایی استفاده میشود و
13
00:00:28,400 –> 00:00:29,760
ممکن است بخواهیم ببینیم
14
00:00:29,760 –> 00:00:33,360
که آیا چیزی در استفاده از dnns
15
00:00:33,360 –> 00:00:35,680
برای پیشبینی سریهای زمانی مالی وجود دارد
16
00:00:35,680 –> 00:00:36,399
17
00:00:36,399 –> 00:00:38,000
، دستور کار به شرح زیر است، ابتدا
18
00:00:38,000 –> 00:00:40,719
دادههای قیمت روزانه را بازیابی میکنیم و سپس
19
00:00:40,719 –> 00:00:41,680
20
00:00:41,680 –> 00:00:44,239
دادههای کمبود را آماده میکنیم زیرا کل تجزیه و تحلیل
21
00:00:44,239 –> 00:00:45,280
مبتنی
22
00:00:45,280 –> 00:00:48,480
بر دادههای بازده lac خواهد بود که
23
00:00:48,480 –> 00:00:51,600
مدل dnn را برای طبقهبندی پیادهسازی میکنیم و
24
00:00:51,600 –> 00:00:54,160
از نتایج
25
00:00:54,160 –> 00:00:57,920
پیشبینیهای این مدل برای بکآزمایش بردار استفاده
26
00:00:57,920 –> 00:00:58,800
میکنیم و
27
00:00:58,800 –> 00:01:01,520
سپس تحلیل را به سناریوی واقعیتر
28
00:01:01,520 –> 00:01:03,520
منتقل میکنیم که در آن مدل را
29
00:01:03,520 –> 00:01:06,320
بر روی بخشی از مدل آموزش میدهیم. مجموعه دادههایی که در
30
00:01:06,320 –> 00:01:07,200
دسترس داریم و
31
00:01:07,200 –> 00:01:10,159
روی قسمت دیگری آزمایش کردهایم تا ببینیم
32
00:01:10,159 –> 00:01:11,600
مدل ممکن است در
33
00:01:11,600 –> 00:01:14,880
خارج از نمونه چگونه عمل کند، به نوتبوک مشتری میروم
34
00:01:14,880 –> 00:01:16,240
35
00:01:16,240 –> 00:01:20,400
و طبق معمول
36
00:01:20,479 –> 00:01:22,880
آنچه را که باید از این آموزش انتظار داشته باشید
37
00:01:22,880 –> 00:01:23,840
38
00:01:23,840 –> 00:01:26,640
و اولین کدی که پیدا می کنید
39
00:01:26,640 –> 00:01:27,600
مربوط به
40
00:01:27,600 –> 00:01:31,360
واردات بسته های مهم است و به
41
00:01:31,360 –> 00:01:32,159
طور خاص
42
00:01:32,159 –> 00:01:35,040
ما از tensorflow استفاده می کنیم که
43
00:01:35,040 –> 00:01:36,320
توسط گوگل منبع باز بوده
44
00:01:36,320 –> 00:01:38,079
و در بسیاری از
45
00:01:38,079 –> 00:01:39,520
مناطق مختلف به عنوان
46
00:01:39,520 –> 00:01:42,640
بسته ما استفاده می شود. برای
47
00:01:42,640 –> 00:01:46,479
یادگیری عمیق نگاهی سریع به
48
00:01:46,479 –> 00:01:49,680
نسخه های خاص شاید tensorflow
49
00:01:49,680 –> 00:01:51,280
ممکن است در اینجا مورد علاقه باشد
50
00:01:51,280 –> 00:01:54,399
و سپس به api داده آیکون متصل می شوم
51
00:01:54,399 –> 00:01:56,640
که در اینجا در این مثال نیاز است
52
00:01:56,640 –> 00:01:58,560
که پروکسی یا برنامه
53
00:01:58,560 –> 00:02:02,159
در قسمت پشتی اجرا شود، مرحله اول
54
00:02:02,159 –> 00:02:03,200
اکنون بازیابی
55
00:02:03,200 –> 00:02:06,240
روزانه است. دادههای دنیای نسبتاً کوچک
56
00:02:06,240 –> 00:02:06,560
57
00:02:06,560 –> 00:02:08,399
Raks فقط سه ریگ که در
58
00:02:08,399 –> 00:02:10,318
اینجا یک etf و دو استوک استفاده میکنیم
59
00:02:10,318 –> 00:02:15,280
و سپس دادهها را بازیابی میکنیم
60
00:02:18,000 –> 00:02:20,319
صبر کنید تا تمام شود، اکنون
61
00:02:20,319 –> 00:02:23,200
مجموعه دادههای ما در دسترس است، فقط برای یک روز
62
00:02:23,200 –> 00:02:23,760
63
00:02:23,760 –> 00:02:27,520
و فقط برای یک روز چند ساعت اینجا
64
00:02:27,520 –> 00:02:31,440
ساعت 12 بعد از ظهر شروع می شود و بعد از
65
00:02:31,440 –> 00:02:32,480
آن لحظه به
66
00:02:32,480 –> 00:02:34,640
لحظه به انتهای دم نگاه می کنیم و می بینیم که
67
00:02:34,640 –> 00:02:36,800
دقیقاً در ساعت 4 بعدازظهر در این روز به پایان می رسد،
68
00:02:36,800 –> 00:02:41,120
ما برای
69
00:02:41,120 –> 00:02:41,920
اطمینان از اینکه داریم از drop na استفاده می کنیم.
70
00:02:41,920 –> 00:02:45,440
یک مجموعه داده کامل در سرتاسر و
71
00:02:45,440 –> 00:02:47,120
به عنوان یک مرحله میانی
72
00:02:47,120 –> 00:02:49,599
، بازده قفل را نیز محاسبه میکنیم که
73
00:02:49,599 –> 00:02:50,400
74
00:02:50,400 –> 00:02:53,680
بعداً برای
75
00:02:53,680 –> 00:02:56,640
آزمایش پشتی بردار استفاده خواهیم کرد، بنابراین در اینجا اکنون
76
00:02:56,640 –> 00:02:57,599
بازده قفل
77
00:02:57,599 –> 00:03:00,720
برای سه آجر خود را داریم، اجازه دهید
78
00:03:00,720 –> 00:03:01,360
دادهها را
79
00:03:01,360 –> 00:03:03,680
روی یکی رسم کنیم. در اینجا تکامل روزانه عادی شده
80
00:03:03,680 –> 00:03:04,560
81
00:03:04,560 –> 00:03:07,280
از سه دکل در نظر گرفته شده است که
82
00:03:07,280 –> 00:03:08,000
دو
83
00:03:08,000 –> 00:03:11,120
سهام و یک ETF در نظر گرفته شده است
84
00:03:11,120 –> 00:03:14,239
و برای همان مجموعه از دکل ها
85
00:03:14,239 –> 00:03:17,200
نیز توزیع فرکانس
86
00:03:17,200 –> 00:03:18,560
در اینجا آمده است، بنابراین در اینجا کرام
87
00:03:18,560 –> 00:03:21,760
های بازده قفل است اکنون ما می
88
00:03:21,760 –> 00:03:22,480
89
00:03:22,480 –> 00:03:25,519
خواهیم داده های طول را آماده کنیم که از 10 استفاده می کنیم.
90
00:03:25,519 –> 00:03:28,879
legs در مجموع بنابراین در اینجا
91
00:03:28,879 –> 00:03:31,840
تاخیرها تعریف می شوند و این تابع تاخیر تبلیغاتی
92
00:03:31,840 –> 00:03:32,319
93
00:03:32,319 –> 00:03:33,920
یک توابع راحت است که می توانید
94
00:03:33,920 –> 00:03:36,560
آن را برای مجموعه داده های مختلف برای
95
00:03:36,560 –> 00:03:37,040
96
00:03:37,040 –> 00:03:40,640
رنک های مختلف که جمع آوری کرده ایم اعمال کنید، بنابراین در
97
00:03:40,640 –> 00:03:43,200
اینجا تعریف تعداد پاها
98
00:03:43,200 –> 00:03:44,480
و عملکرد
99
00:03:44,480 –> 00:03:48,159
تاخیر تبلیغات و از طریق این حلقه کوچک،
100
00:03:48,159 –> 00:03:51,120
101
00:03:51,120 –> 00:03:52,480
ما به مجموعه دادههای اصلی مورد علاقه
102
00:03:52,480 –> 00:03:55,840
خود تاخیر اضافه میکنیم تا بعداً دادههایی را
103
00:03:55,840 –> 00:03:59,519
داشته باشیم که به دنبال آن هستیم، بنابراین فرقهها
104
00:03:59,519 –> 00:04:02,959
این نامها هستند. um هایی که
105
00:04:02,959 –> 00:04:05,680
داده های کم دارند که در اینجا می بینید، این
106
00:04:05,680 –> 00:04:06,000
107
00:04:06,000 –> 00:04:09,760
یک بازه زمانی تاخیر دارد در مورد
108
00:04:09,760 –> 00:04:11,840
ما یک دقیقه میله است، بسته به داده هایی که با آنها کار می کنیم می تواند یک روز
109
00:04:11,840 –> 00:04:13,360
می تواند پنج دقیقه باشد
110
00:04:13,360 –> 00:04:16,639
111
00:04:16,639 –> 00:04:19,440
و کلیدهای این فرهنگ لغت را می بینید.
112
00:04:19,440 –> 00:04:20,720
و هنگامی که
113
00:04:20,720 –> 00:04:24,720
به سر
114
00:04:24,720 –> 00:04:27,280
قاب داده مربوط به Apple نگاهی بیندازیم، میبینیم که
115
00:04:27,280 –> 00:04:29,759
بازگشتهای اصلی را در اینجا
116
00:04:29,759 –> 00:04:32,320
داریم و سپس دادههای تاخیر را داریم، اما
117
00:04:32,320 –> 00:04:33,440
118
00:04:33,440 –> 00:04:36,639
در اینجا با مقادیر مطلق کار نمیکنیم، کاری که
119
00:04:36,639 –> 00:04:37,360
120
00:04:37,360 –> 00:04:41,120
بعداً انجام خواهیم داد. در سلول بعدی نشان داده شده است که
121
00:04:41,120 –> 00:04:44,479
ما قصد داریم
122
00:04:44,479 –> 00:04:48,400
مقادیر باینری را در اینجا فقط صفر و یک استخراج کنیم
123
00:04:48,400 –> 00:04:51,440
و به ویژه
124
00:04:51,440 –> 00:04:55,120
وقتی بازده مثبت است این یک است
125
00:04:55,120 –> 00:04:58,240
و وقتی
126
00:04:58,240 –> 00:05:00,320
بازده منفی است صفر است، این همان کاری است که
127
00:05:00,320 –> 00:05:02,400
تابع دیجیتالی mp در اینجا با
128
00:05:02,400 –> 00:05:04,000
bin های تعریف شده
129
00:05:04,000 –> 00:05:07,360
فقط یک عدد واحد صفر هستند،
130
00:05:07,360 –> 00:05:09,520
تعداد کل الگوهای در نظر گرفته شده
131
00:05:09,520 –> 00:05:12,000
در اینجا دو به توان تاخیر هستند و
132
00:05:12,000 –> 00:05:14,680
این به 1024 تبدیل می شود و
133
00:05:14,680 –> 00:05:16,720
134
00:05:16,720 –> 00:05:19,520
اکنون به مدل dnn و آنچه در ادامه می آید
135
00:05:19,520 –> 00:05:21,919
ما از یک tensorflow استفاده می کنیم
136
00:05:21,919 –> 00:05:24,080
و به طور خاص از
137
00:05:24,080 –> 00:05:26,120
یک شبکه عصبی عمیق یک طبقهبندیکننده شبکه عصبی عمیق استفاده کنید
138
00:05:26,120 –> 00:05:28,880
و طبقهبندیکننده باید
139
00:05:28,880 –> 00:05:30,720
از الگوهای تاریخی یاد بگیرد تا
140
00:05:30,720 –> 00:05:31,680
پیشبینی
141
00:05:31,680 –> 00:05:33,440
کند که حرکت رو به بالا
142
00:05:33,440 –> 00:05:36,880
محتملتر است یا حرکت رو به پایین
143
00:05:36,880 –> 00:05:39,440
قبل از شروع من، پرحرفی
144
00:05:39,440 –> 00:05:41,680
را روی خطا تنظیم میکنم، فقط برای دیدن خطاها باید تنظیم کنیم.
145
00:05:41,680 –> 00:05:42,160
146
00:05:42,160 –> 00:05:45,120
اگر وجود داشته باشد و ابتدا ویژگیها را تعریف کنیم،
147
00:05:45,120 –> 00:05:45,919
148
00:05:45,919 –> 00:05:48,960
بنابراین برای هر
149
00:05:48,960 –> 00:05:52,320
ستون یک ویژگی تعریف شده در
150
00:05:52,320 –> 00:05:55,120
فرهنگ لغت خواهیم داشت و کاری که من قبلاً
151
00:05:55,120 –> 00:05:55,759
152
00:05:55,759 –> 00:05:58,800
با digitize tensorflow انجام دادهام میتوانم با ستونهای بستهبندی شده در اینجا انجام دهم
153
00:05:58,800 –> 00:06:02,639
تا از
154
00:06:02,639 –> 00:06:05,919
ستونهای با ارزش واقعی خارج شود. m ایجاد اینجا
155
00:06:05,919 –> 00:06:06,880
مرزهایی را که قبلاً گفتم سطل
156
00:06:06,880 –> 00:06:09,280
می کند، بنابراین ما
157
00:06:09,280 –> 00:06:10,720
فقط به
158
00:06:10,720 –> 00:06:13,919
مقادیر مثبت و یا منفی در
159
00:06:13,919 –> 00:06:16,319
این مرحله علاقه مندیم،
160
00:06:16,319 –> 00:06:19,600
اکنون من با مدل مطابقت دارم و
161
00:06:19,600 –> 00:06:23,120
برای شروع این کار به تابعی نیاز دارم که
162
00:06:23,120 –> 00:06:26,800
هم داده های ستون های ویژگی
163
00:06:26,800 –> 00:06:29,120
و هم برچسب ها را برمی گرداند. داده ها و این همان کاری است که
164
00:06:29,120 –> 00:06:31,199
getdata قرار است انجام دهد
165
00:06:31,199 –> 00:06:32,560
بنابراین در اینجا می بینید که ستون های ویژگی به
166
00:06:32,560 –> 00:06:35,520
عنوان فرهنگ لغت ارائه می شوند و برچسب
167
00:06:35,520 –> 00:06:38,960
ها در اینجا فقط یک بردار a s هستند. یک تانسور یکنواخت
168
00:06:38,960 –> 00:06:39,919
169
00:06:39,919 –> 00:06:42,880
در اینجا یک ثابت است و ما یک بار دیگر از digitize استفاده می کنیم
170
00:06:42,880 –> 00:06:43,440
171
00:06:43,440 –> 00:06:45,520
تا به صفرها و یک
172
00:06:45,520 –> 00:06:47,360
هایی که برای
173
00:06:47,360 –> 00:06:51,120
پیش بینی یا مدل سازی خود نیاز داریم برسیم، بنابراین می توان گفت
174
00:06:51,120 –> 00:06:54,240
اکنون dnn را می توان آموزش داد، بنابراین می گوییم
175
00:06:54,240 –> 00:06:55,360
برازش داده ها
176
00:06:55,360 –> 00:06:59,039
و شبکه عصبی و یادگیری عمیق
177
00:06:59,039 –> 00:07:01,360
به طور معمول از یک آموزش به جای برازش صحبت می کنیم
178
00:07:01,360 –> 00:07:02,720
179
00:07:02,720 –> 00:07:06,160
و شی مدل dna با سه لایه مخفی نمونه سازی شده است
180
00:07:06,160 –> 00:07:06,639
که
181
00:07:06,639 –> 00:07:09,759
چیز بزرگی نیست، اما
182
00:07:09,759 –> 00:07:13,120
در حال حاضر نوعی یک شبکه عصبی عمیق انعطاف پذیر
183
00:07:13,120 –> 00:07:15,120
است که ما در اینجا ساختیم،
184
00:07:15,120 –> 00:07:17,599
این در اینجا برای هر ریکی دوباره انجام می شود، در
185
00:07:17,599 –> 00:07:19,599
غیر این صورت مدل
186
00:07:19,599 –> 00:07:22,800
با دادههایی که به آن اضافه میشود یاد میگیریم، بنابراین ما
187
00:07:22,800 –> 00:07:26,720
برای هر مدل جدید مورد نیاز نمونهسازی
188
00:07:26,720 –> 00:07:29,599
میکنیم، دادههای مرتبط را
189
00:07:29,599 –> 00:07:32,000
انتخاب میکنیم و مدل را
190
00:07:32,000 –> 00:07:34,720
با توجه به دادههایی که توسط تابع دریافت داده ارائه میشود مطابقت
191
00:07:34,720 –> 00:07:35,599
192
00:07:35,599 –> 00:07:39,680
میدهیم، از 250 مرحله یادگیری استفاده میکنیم
193
00:07:39,680 –> 00:07:42,000
که تعداد آنها زیاد نیست، اما امیدواریم به اندازه کافی برای به
194
00:07:42,000 –> 00:07:43,039
195
00:07:43,039 –> 00:07:46,319
نتایج مناسبی برسیم، سپس پیشبینی را
196
00:07:46,319 –> 00:07:49,440
بر اساس مجموعه دادههای آموزشی درون نمونه انجام
197
00:07:49,440 –> 00:07:50,319
198
00:07:50,319 –> 00:07:53,440
میدهیم و نتایج را در ستونی
199
00:07:53,440 –> 00:07:54,240
در ریگ مربوطه قرار
200
00:07:54,240 –> 00:07:56,400
میدهیم و سپس نتیجه را ترجمه میکنیم. s از
201
00:07:56,400 –> 00:07:58,400
صفر و یک به
202
00:07:58,400 –> 00:08:02,160
مثبت یک و منهای یک، بنابراین
203
00:08:02,160 –> 00:08:04,400
این همان کاری است که ما در اینجا انجام می دهیم، هر زمان
204
00:08:04,400 –> 00:08:06,720
که یک مقدار مثبت به اضافه یک داشته
205
00:08:06,720 –> 00:08:08,639
باشیم، آن را در مثبت یک رها می کنیم، اگر صفر داشته باشیم،
206
00:08:08,639 –> 00:08:10,000
این
207
00:08:10,000 –> 00:08:12,879
همان طور که در اینجا می توانید ببینید به a ترجمه می شود.
208
00:08:12,879 –> 00:08:15,599
منهای یک
209
00:08:16,080 –> 00:08:18,160
بنابراین وقتی این سلول را اجرا می کنم چند ثانیه طول می
210
00:08:18,160 –> 00:08:19,280
211
00:08:19,280 –> 00:08:21,680
کشد زیرا روی سه ریگ تکرار
212
00:08:21,680 –> 00:08:22,319
می
213
00:08:22,319 –> 00:08:25,360
شود، تمرین را بر اساس 250 مرحله
214
00:08:25,360 –> 00:08:28,000
در هفته پس از 10 ثانیه در دستگاه من انجام
215
00:08:28,000 –> 00:08:29,360
می دهد
216
00:08:29,360 –> 00:08:31,599
و وقتی من به عنوان مثال به
217
00:08:31,599 –> 00:08:33,760
برخی از نتایج نگاه می کنم ببینید که
218
00:08:33,760 –> 00:08:36,240
اکنون ما واقعاً در ستون های موقعیت
219
00:08:36,240 –> 00:08:38,000
220
00:08:38,000 –> 00:08:40,320
فریم های داده مربوطه داریم به علاوه یک و منهای یک
221
00:08:40,320 –> 00:08:42