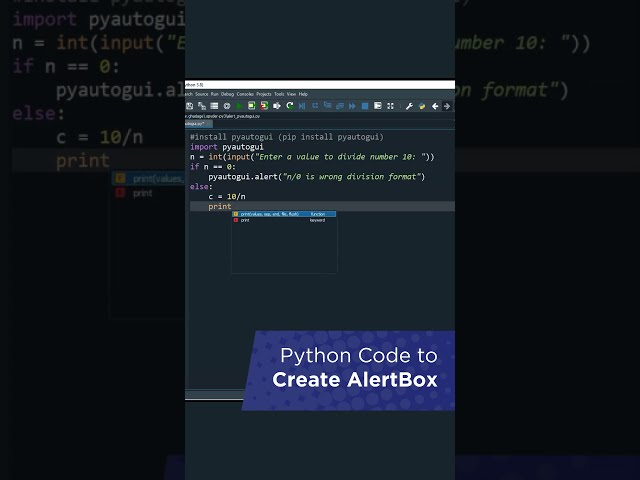
در این مطلب، ویدئو تشخیص گفتار با استفاده از پایتون | نحوه عملکرد تشخیص گفتار در پایتون | Simplile Learn با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:27:12
تصاویر این ویدئو:


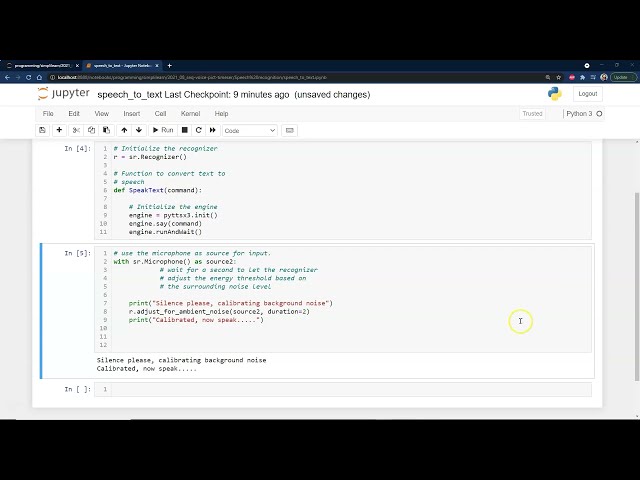

قسمتی از زیرنویس این فیلم:
00:00:08,240 –> 00:00:10,800
خوش آمدید به سادگی یاد بگیرید نام من
2
00:00:10,800 –> 00:00:12,639
ریچارد کیرشنر با تیم یادگیری ساده است
3
00:00:12,639 –> 00:00:13,759
4
00:00:13,759 –> 00:00:16,880
که www.simplylearn
5
00:00:16,880 –> 00:00:20,400
گواهینامه دریافت کنید
6
00:00:20,400 –> 00:00:21,840
در این ویدیو پیش بروید ما قصد داریم نگاهی
7
00:00:21,840 –> 00:00:24,880
به تشخیص
8
00:00:24,880 –> 00:00:26,320
گفتار داشته باشیم برای شما
9
00:00:26,320 –> 00:00:27,840
. تشخیص گفتار
10
00:00:27,840 –> 00:00:29,439
11
00:00:29,439 –> 00:00:32,000
چگونه کار می کند تشخیص گفتار چگونه کار
12
00:00:32,000 –> 00:00:33,440
می کند انتخاب و نصب
13
00:00:33,440 –> 00:00:35,520
بسته تشخیص گفتار
14
00:00:35,520 –> 00:00:37,920
که با فایل های صوتی کار می کند و با میکروفون کار می
15
00:00:37,920 –> 00:00:39,920
کند و سپس ما چند نمونه
16
00:00:39,920 –> 00:00:41,520
نمایشی خواهیم داشت
17
00:00:41,520 –> 00:00:44,239
که تشخیص گفتار چیست.
18
00:00:44,239 –> 00:00:46,480
19
00:00:46,480 –> 00:00:48,480
20
00:00:48,480 –> 00:00:50,480
21
00:00:50,480 –> 00:00:52,559
ارسال پیامک به رایانهها اجازه میدهد تا
22
00:00:52,559 –> 00:00:55,920
زبان انسان را بفهمند
23
00:00:56,079 –> 00:00:58,160
و میتوانید در اینجا یک نمودار ساده را
24
00:00:58,160 –> 00:01:00,320
بشنوید که در آن فرد
25
00:01:00,320 –> 00:01:02,000
با میکروفون خود
26
00:01:02,000 –> 00:01:02,960
27
00:01:02,960 –> 00:01:04,239
در میکروفون صحبت میکند و
28
00:01:04,239 –> 00:01:05,680
آن را به نوعی
29
00:01:05,680 –> 00:01:08,080
متن قابل تشخیص تبدیل میکند یا آن را میخواند
30
00:01:08,080 –> 00:01:09,520
. همه انواع کارهایی که ما می توانیم
31
00:01:09,520 –> 00:01:12,880
انجام دهیم و این یک منطقه در حال انفجار در
32
00:01:12,880 –> 00:01:16,320
علم داده است در حال حاضر
33
00:01:16,640 –> 00:01:19,759
چگونه تشخیص گفتار کار می کند
34
00:01:19,759 –> 00:01:22,240
گفتار ابتدا
35
00:01:22,240 –> 00:01:23,920
با استفاده از میکروفون از صدای فیزیکی به انرژی الکتریکی تبدیل می
36
00:01:23,920 –> 00:01:25,280
شود
37
00:01:25,280 –> 00:01:27,520
و سپس با استفاده از مبدل آنالوگ
38
00:01:27,520 –> 00:01:29,439
به دیجیتال به داده های دیجیتال تبدیل
39
00:01:29,439 –> 00:01:31,439
می
40
00:01:31,439 –> 00:01:33,200
41
00:01:33,200 –> 00:01:37,360
42
00:01:38,159 –> 00:01:40,880
43
00:01:40,880 –> 00:01:42,560
شود. می دانید که امروزه بسیار رایج است،
44
00:01:42,560 –> 00:01:43,680
زمانی که ما در مورد هر یک از
45
00:01:43,680 –> 00:01:45,920
علوم کامپیوتر و داده خود صحبت می
46
00:01:45,920 –> 00:01:48,240
کنیم، ما واقعاً کل این تنظیمات را
47
00:01:48,240 –> 00:01:50,560
داریم که می خواهیم چیزها را به داده های دیجیتال تبدیل
48
00:01:50,560 –> 00:01:53,520
49
00:01:53,520 –> 00:01:55,360
کنیم.
50
00:01:55,360 –> 00:01:57,200
روی این موضوع کار زیادی انجام دهید، خواه
51
00:01:57,200 –> 00:01:58,320
این ویدئو صوتی گفتار باشد،
52
00:01:58,320 –> 00:02:00,399
53
00:02:00,399 –> 00:02:04,159
دادههای دیگری که از وب وارد میشوند،
54
00:02:04,320 –> 00:02:05,759
انتخاب و نصب
55
00:02:05,759 –> 00:02:08,399
بسته تشخیص گفتار
56
00:02:08,399 –> 00:02:10,000
هستند، چندین مدل تشخیص گفتار
57
00:02:10,000 –> 00:02:11,920
در دسترس هستند که همگی
58
00:02:11,920 –> 00:02:14,000
عملکردهای متفاوتی را ارائه میدهند،
59
00:02:14,000 –> 00:02:16,879
برخی از بستههای متداول استفاده شده از این بستهها هستند
60
00:02:16,879 –> 00:02:20,239
. من گفتم که درست
61
00:02:20,239 –> 00:02:22,160
شامل پردازش زبان طبیعی برای
62
00:02:22,160 –> 00:02:25,200
شناسایی سخنرانان است که هدف
63
00:02:25,200 –> 00:02:27,680
گوگل کلام ابری ارائه می دهد c
64
00:02:27,680 –> 00:02:29,520
تبدیل گفتار به متن
65
00:02:29,520 –> 00:02:32,239
تشخیص گفتار پردازش صوتی آسان
66
00:02:32,239 –> 00:02:34,840
و
67
00:02:34,840 –> 00:02:37,200
دسترسی به میکروفون را ارائه می دهد ما با تشخیص گفتار کار خواهیم کرد
68
00:02:37,200 –> 00:02:39,519
به دلیل سهولت استفاده آن را
69
00:02:39,519 –> 00:02:40,879
می توان با اجرای
70
00:02:40,879 –> 00:02:43,120
دستور زیر پیپ نصب تشخیص گفتار نصب کرد
71
00:02:43,120 –> 00:02:45,760
72
00:02:47,440 –> 00:02:49,760
بنابراین اولین کار کار با
73
00:02:49,760 –> 00:02:51,440
فایل های صوتی
74
00:02:51,440 –> 00:02:54,480
و وقتی در مورد فایلهای صوتی صحبت
75
00:02:54,480 –> 00:02:56,319
میکنیم، ذخیره میشوند، این یک چیز خوب است،
76
00:02:56,319 –> 00:02:58,239
بنابراین میتوانید تصویری را ببینید که دارای یک
77
00:02:58,239 –> 00:03:00,640
جدول زمانی است و سپس
78
00:03:00,640 –> 00:03:02,840
مقادیری دارد تا
79
00:03:02,840 –> 00:03:05,360
جایی که صدا در آنجا انجام میدهد و
80
00:03:05,360 –> 00:03:07,040
به کانالهایی که میتوانید ببینید بستگی دارد.
81
00:03:07,040 –> 00:03:09,519
در اینجا نحوه برش فایلهای صوتی که
82
00:03:09,519 –> 00:03:11,040
کانالهای مختلف را با رنگهای مختلف نشان میدهند،
83
00:03:11,040 –> 00:03:12,080
84
00:03:12,080 –> 00:03:13,440
چیزهای زیادی
85
00:03:13,440 –> 00:03:16,159
در یک فایل صوتی خودکار با مقادیر
86
00:03:16,159 –> 00:03:18,959
بسته به تعداد
87
00:03:18,959 –> 00:03:21,360
کانالهای شما وجود دارد، بنابراین اگر 16
88
00:03:21,360 –> 00:03:23,360
کانال داشته باشید این به معنای هر نقطه است. در این
89
00:03:23,360 –> 00:03:26,959
خط مانند یک قاب است که ممکن است
90
00:03:26,959 –> 00:03:28,799
0.1 ثانیه باشد
91
00:03:28,799 –> 00:03:31,040
و سپس شما 16 مقدار خواهید داشت و
92
00:03:31,040 –> 00:03:32,239
ارتفاع کل ارتفاع چیزی
93
00:03:32,239 –> 00:03:34,400
است که در اینجا به آن نگاه می کنید این است که همه آنها با هم تفاوت دارند.
94
00:03:34,400 –> 00:03:35,680
ارزشهای اجاره را میبینید و میتوانید در اینجا ببینید
95
00:03:35,680 –> 00:03:37,519
که آنها به نوعی آن را تقسیم میکنند، مثل
96
00:03:37,519 –> 00:03:39,120
اینکه فکر میکنم این فقط حجم این
97
00:03:39,120 –> 00:03:40,720
تصویر کوچک است، این فقط یک
98
00:03:40,720 –> 00:03:42,879
جستجوی ساده برای فایلهای صوتی است، تصاویر هیچ چیز جالبی نیست
99
00:03:42,879 –> 00:03:44,239
100
00:03:44,239 –> 00:03:45,360
و این چیزی است که اتفاق میافتد این است که شما
101
00:03:45,360 –> 00:03:46,480
این کانالهای مختلف را دارید و
102
00:03:46,480 –> 00:03:50,000
مقادیر مختلف ما واقعاً به طور معمول به
103
00:03:50,000 –> 00:03:52,400
دنبال مقادیر واقعی نمیشویم، مگر
104
00:03:52,400 –> 00:03:55,120
اینکه شما آن را نمایش میدهید،
105
00:03:55,120 –> 00:03:56,799
غیر از گفتن میزان کل
106
00:03:56,799 –> 00:03:58,959
صدای خروجی از میکروفون، ما
107
00:03:58,959 –> 00:04:00,959
واقعاً اهمیتی نمیدهیم زیرا
108
00:04:00,959 –> 00:04:02,319
میخواهیم آن را بشنویم. ما می خواهیم بشنویم که چه اتفاقی می
109
00:04:02,319 –> 00:04:04,720
افتد
110
00:04:04,720 –> 00:04:06,480
و سپس کار با یک
111
00:04:06,480 –> 00:04:08,080
میکروفون وجود دارد
112
00:04:08,080 –> 00:04:09,040
و
113
00:04:09,040 –> 00:04:11,599
شما می دانید که واقعاً دوباره
114
00:04:11,599 –> 00:04:14,159
زمانی که در پایتون کار می
115
00:04:14,159 –> 00:04:16,959
کنید، خیلی سخت است که هم زمان هم ویدیو و هم
116
00:04:16,959 –> 00:04:19,759
ورودی میکروفون را انجام دهید، بنابراین
117
00:04:19,759 –> 00:04:22,079
بسیاری از کارها زمانی که فایل صوتی
118
00:04:22,079 –> 00:04:23,280
و
119
00:04:23,280 –> 00:04:25,199
فایل تصویری را از هم جدا میبینید که دوربین وارد
120
00:04:25,199 –> 00:04:27,360
میشود یا باید جداگانه روی آنها کار کنید
121
00:04:27,360 –> 00:04:29,280
و سپس آنها را دوباره کنار هم قرار دهید و
122
00:04:29,280 –> 00:04:31,280
بنابراین ما در مورد میکروفونی مانند رایانه من صحبت میکنیم،
123
00:04:31,280 –> 00:04:33,120
124
00:04:33,120 –> 00:04:35,040
من تمام فیشهای USB را
125
00:04:35,040 –> 00:04:37,680
دارم که دارم. و دو دوربین وب هر دو دوربین وب
126
00:04:37,680 –> 00:04:39,520
میکروفون خود را دارند
127
00:04:39,520 –> 00:04:41,440
من یکی از مانیتورهای من میکروفون خود را دارد
128
00:04:41,440 –> 00:04:43,919
من سه مانیتور
129
00:04:43,919 –> 00:04:45,600
دارم سپس میکروفون واقعی خود را دارم که
130
00:04:45,600 –> 00:04:47,199
از آن استفاده می کنم که در آن جک است که
131
00:04:47,199 –> 00:04:49,280
کیفیت صدای کمی بهتری دارد
132
00:04:49,280 –> 00:04:51,680
و بنابراین شما واقعاً می خواهید
133
00:04:51,680 –> 00:04:54,720
میکروفون خود را هر طور که پیش فرض دارید تنظیم کنید،
134
00:04:54,720 –> 00:04:56,240
اکثر این برنامه ها در حال حاضر به سراغ
135
00:04:56,240 –> 00:04:58,880
میکروفون پیش فرض بروید، راه هایی برای حل آن وجود دارد،
136
00:04:58,880 –> 00:05:01,360
اما زمانی که به
137
00:05:01,360 –> 00:05:03,280
طور خاص در ویندوز کار می کنید،
138
00:05:03,280 –> 00:05:04,560
139
00:05:04,560 –> 00:05:06,320
تشخیص اینکه کدام میکروفون را به ویندوز انجام می دهید کمی چالش برانگیز است.
140
00:05:06,320 –> 00:05:07,360
استفاده مجدد از
141
00:05:07,360 –> 00:05:09,039
آن بزرگترین چالش نیست، اما
142
00:05:09,039 –> 00:05:11,840
باید از آن آگاه باشید،
143
00:05:12,000 –> 00:05:13,680
بنابراین ما میخواهیم با
144
00:05:13,680 –> 00:05:16,880
نسخهی نمایشی گفتار به متن اصلی خود شروع کنیم
145
00:05:16,880 –> 00:05:18,960
و قبل از اینکه وارد نسخه ی نمایشی شویم، در
146
00:05:18,960 –> 00:05:20,720
واقع سه نسخه نمایشی را انجام
147
00:05:20,720 –> 00:05:22,240
خواهیم داد. دو مورد دوم را مرور خواهیم کرد،
148
00:05:22,240 –> 00:05:24,560
زیرا آنها بر اساس اولین موردی
149
00:05:24,560 –> 00:05:27,039
هستند که ایجاد می کنند، یکی حدس یک کلمه است
150
00:05:27,039 –> 00:05:30,639
و دیگری قرار است یک آدرس اینترنتی باز کند
151
00:05:30,639 –> 00:05:32,240
و ما به صورت
152
00:05:32,240 –> 00:05:35,280
پیش فرض از آناکوندا استفاده می کنیم، مطمئناً
153
00:05:35,280 –> 00:05:37,600
شما می توانید از آن استفاده کنید. pycharm
154
00:05:37,600 –> 00:05:39,280
i در تمام این موارد، باید توجه داشته باشید
155
00:05:39,280 –> 00:05:41,039
که گاهی اوقات محیط بسته
156
00:05:41,039 –> 00:05:42,960
شما یا اگر آن را روی رایانه خود اجرا می کنید،
157
00:05:42,960 –> 00:05:44,560
ممکن است به بسته های اضافی یا
158
00:05:44,560 –> 00:05:46,400
چیزی شبیه به آن نیاز داشته باشد، اکثر این موارد
159
00:05:46,400 –> 00:05:49,440
بسیار ساده هستند
160
00:05:49,440 –> 00:05:50,880
و ما ادامه می دهیم اجازه دهید من ادامه دهم. و
161
00:05:50,880 –> 00:05:53,360
در اینجا نوت بوک مشتری را باز کنید
162
00:05:53,360 –> 00:05:55,360
و در واقع منظورم آناکوندا بود و سپس
163
00:05:55,360 –> 00:06:00,639
نوت بوک مشتری، من در پایتون 3.8 هستم،
164
00:06:00,639 –> 00:06:01,840
این کار خواهد کرد، فکر می کنم برای تشخیص گفتار
165
00:06:01,840 –> 00:06:04,000
به 3.4 برمی گردد
166
00:06:04,000 –> 00:06:06,560
167
00:06:06,560 –> 00:06:08,639
و در حال حاضر مانند 3.9 وجود دارد، فکر می کنم
168
00:06:08,639 –> 00:06:10,720
حتی یک 3.10 بتا
169
00:06:10,720 –> 00:06:12,880
من در نسخه 3.8 هستم زیرا بسیاری از کارهایی که
170
00:06:12,880 –> 00:06:16,960
انجام می دهم روی 3.9 کار نمی کنند
171
00:06:16,960 –> 00:06:18,639
و ما ادامه می دهیم و روی start
172
00:06:18,639 –> 00:06:20,560
on jupiter notebook کلیک می کنیم که نوت بوک مشتری ما را باز می کند
173
00:06:20,560 –> 00:06:23,360
174
00:06:23,360 –> 00:06:25,919
و در اینجا ما یک پایتون جدید
175
00:06:25,919 –> 00:06:28,240
سه
176
00:06:30,240 –> 00:06:31,520
و شروع می کنیم.
177
00:06:31,520 –> 00:06:33,919
گاهی اوقات نمیدانم
178
00:06:33,919 –> 00:06:35,919
تغییر نام چقدر سخت است، اما ما ادامه میدهیم
179
00:06:35,919 –> 00:06:39,520
و نام آن را به متن تغییر میدهیم،
180
00:06:39,520 –> 00:06:41,360
زیرا این همان چیزی
181
00:06:41,360 –> 00:06:43,120
است که روی آن
182
00:06:43,120 –> 00:06:45,840
کار میکنیم، اوه، ادامه میدهیم و نام آن را تغییر میدهیم اگر من
183
00:06:45,840 –> 00:06:47,680
از قبل وجود دارم، اوه، حدس میزنم این
184
00:06:47,680 –> 00:06:48,880
سخنرانی را
185
00:06:48,880 –> 00:06:51,759
th بنامیم به این دلیل است که آنها نسخه نمایشی را برای من ارسال کردند
186
00:06:51,759 –> 00:06:53,199
، مثل هر آشپز خوبی است که می خواهید
187
00:06:53,199 –> 00:06:54,639
قبل از انجام این دموها همه چیز را در پشت آن آماده
188
00:06:54,639 –> 00:06:56,000
کنید و مطمئن شوید که
189
00:06:56,000 –> 00:06:59,039
آنها به درستی اجرا می شوند
190
00:06:59,840 –> 00:07:02,319
و بیایید جلوتر برویم و تشخیص گفتار خود را
191
00:07:02,319 –> 00:07:04,560
به عنوان
192
00:07:04,560 –> 00:07:07,199
sr که معمول است وارد کنیم.
193
00:07:07,199 –> 00:07:09,520
مخفف اگر تا به حال هر کاری انجام می دهید بروید
194
00:07:09,520 –> 00:07:11,919
برای آموزش های تشخیص گفتار
195
00:07:11,919 –> 00:07:13,759
و مثال ها جستجو کنید همیشه ظاهر می
196
00:07:13,759 –> 00:07:15,360
شود آنها از sr استفاده می کنند
197
00:07:15,360 –> 00:07:20,160
و ما همچنین می خواهیم متن
198
00:07:20,160 –> 00:07:24,240
pi 2 متن 3 را وارد
199
00:07:24,240 –> 00:07:26,319
کنیم. این آن را از متن تبدیل می کند.
200
00:07:26,319 –> 00:07:27,599
201
00:07:27,599 –> 00:07:28,960
برای دریافت صدا
202
00:07:28,960 –> 00:07:30,560
از میکروفون خود
203
00:07:30,560 –> 00:07:31,840
و سپس سعی می کنیم آن
204
00:07:31,840 –> 00:07:33,840
را برای خودمان بخوانیم و بنابراین این بخشی از آن
205
00:07:33,840 –> 00:07:35,520
بسته در خواندن آن است زیرا
206
00:07:35,520 –> 00:07:37,360
می خواهیم بتوانیم آن را بشنویم
207
00:07:37,360 –> 00:07:38,960
و شما می توانید اینجا را ببینید
208
00:07:38,960 –> 00:07:40,240
209
00:07:40,240 –> 00:07:42,639
تشخیص گفتار را نصب کنید
210
00:07:42,639 –> 00:07:45,120
و pip install pi
211
00:07:45,120 –> 00:07:48,160
t tsx3
212
00:07:48,160 –> 00:07:49,440
مطمئن شوید که اینها را نصب کردهاید وگرنه
213
00:07:49,440 –> 00:07:50,720
اجرا نمیشوند و ما باید
214
00:07:50,720 –> 00:07:53,199
آن بستهها را وارد کنیم
215
00:07:53,199 –> 00:07:54,479
و اولین کاری که میخواهیم انجام دهیم این است که
216
00:07:54,479 –> 00:07:58,879
جلو برویم و شناسایی um خود را شروع کنیم.
217
00:07:58,879 –> 00:08:01,440
بخشی از س oftware و بنابراین ما یک شناسه
218
00:08:01,440 –> 00:08:04,080
r برابر با sr را خیلی
219
00:08:04,080 –> 00:08:05,919
ساده انجام می دهیم، این همان تنظیمات پایه ای است
220
00:08:05,919 –> 00:08:08,160
که برای این کار می خواهید
221
00:08:08,160 –> 00:08:09,599
و بنابراین r ضبط اصلی ما خواهد بود
222
00:08:09,599 –> 00:08:11,199
و همه
223
00:08:11,199 –> 00:08:14,879
عملکردهای مختلف ما از آنجا وارد می شوند
224
00:08:16,960 –> 00:08:19,520
و ما ادامه می دهیم و
225
00:08:19,520 –> 00:08:22,160
در اینجا یک تابع کوچک ایجاد کنید، متن را بیان کنید،
226
00:08:22,160 –> 00:08:24,400
بنابراین این تابع خود ما است و هر
227
00:08:24,400 –> 00:08:26,400
چیزی را که در اینجا قرار می دهیم، می خواهیم آن را به
228
00:08:26,400 –> 00:08:28,560
خودمان برگردانیم که تمام این کار انجام می شود
229
00:08:28,560 –> 00:08:30,240
و موتور ما در اینجا
230
00:08:30,240 –> 00:08:32,719
برای گفتار خود استفاده می کنیم که
231
00:08:32,719 –> 00:08:37,519
مقداردهی اولیه است. pi ttsx3
232
00:08:37,519 –> 00:08:41,039
و سپس آن را به سادگی میگوییم
233
00:08:41,039 –> 00:08:42,159
دستور
234
00:08:42,159 –> 00:08:43,839
و سپس اجرا میکنیم و منتظر میشویم
235
00:08:43,839 –> 00:08:45,440
تا این کار انجام شود و
236
00:08:45,440 –> 00:08:47,760
هر آنچه را که به صورت متنی برای آن ارسال میکنیم را پس بگوییم
237
00:08:47,760 –> 00:08:48,800
238
00:08:48,800 –> 00:08:50,080
و بیایید ادامه دهیم و اجرا کنیم تا
239
00:08:50,080 –> 00:08:52,000
واقعاً بتوانیم این نوع را آزمایش کنیم. جالب است،
240
00:08:52,000 –> 00:08:53,839
بیایید برویم
241
00:08:53,839 –> 00:08:56,240
242
00:08:56,240 –> 00:08:58,800
متن سلام قدیمی
243
00:08:58,800 –> 00:09:00,720
را بگوییم و اگر این را اجرا کنیم،
244
00:09:00,720 –> 00:09:04,480
امیدوارم از بلندگوهای من بشنوید،
245
00:09:06,080 –> 00:09:08,399
اوه، اشتباهی در آنجا رخ داد،
246
00:09:08,399 –> 00:09:09,920
247
00:09:09,920 –> 00:09:11,600
فراموش کردم مانند هر برنامه نویس خوب، با حروف بزرگ استفاده کنم.
248
00:09:11,600 –> 00:09:13,440
249
00:09:13,440 –> 00:09:15,760
250
00:09:15,760 –> 00:09:17,040
251
00:09:17,040 –> 00:09:18,800
252
00:09:18,800 –> 00:09:21,680
من من در حال توسعه روال های کوچک هستم سلام
253
00:09:21,680 –> 00:09:23,920
دنیا، شما بروید، گفتم سلام
254
00:09:23,920 –> 00:09:25,360
دنیا کار می کند،
255
00:09:25,360 –> 00:09:27,279
تست های سریع کوچک زیادی مانند
256
00:09:27,279 –> 00:09:28,880
این روی هر یک از عملکردهایی
257
00:09:28,880 –> 00:09:31,040
که با آنها کار می کنم انجام می دهم، خیلی آسان است که
258
00:09:31,040 –> 00:09:32,880
از خودتان جلو بیفتید و سپس باید به عقب برگردید
259
00:09:32,880 –> 00:09:35,440
و خطا را
260
00:09:35,440 –> 00:09:38,399
از 15 16 خط قبل پیدا کنید
261
00:09:38,399 –> 00:09:40,640
تا بدانید که فقط یک ترفند سریع
262
00:09:40,640 –> 00:09:44,240
برای آزمایش همه چیز در حین انجام کار
263
00:09:44,640 –> 00:09:47,200
و اولین کاری که
264
00:09:47,200 –> 00:09:48,720
265
00:09:48,720 –> 00:09:50,720
میخواهیم انجام دهیم این است که از میکروفون خود استفاده میکنیم. به عنوان
266
00:09:50,720 –> 00:09:53,279
منبعی برای ورودی، بنابراین با
267
00:09:53,279 –> 00:09:55,279
میکروفون sr در اینجا روی
268
00:09:55,279 –> 00:09:57,760
میکروفون ضربه میزنید که کدام میکروفون است،
269
00:09:57,760 –> 00:10:00,320
هر چیزی که زیر صدای خود تنظیم کردهاید،
270
00:10:00,320 –> 00:10:02,000
است، بنابراین اگر به زیر تنظیمات صدای خود بروم
271
00:10:02,000 –> 00:10:03,760
272
00:10:03,760 –> 00:10:04,959
و شروع به بررسی کنیم، میتوانیم
273
00:10:04,959 –> 00:10:06,320
شروع به جستجو کنیم تا ببینیم کجا
274
00:10:06,320 –> 00:10:08,079
میکروفون زیر تنظیمات سیستم
275
00:10:08,079 –> 00:10:10,320
است،
276
00:10:10,320 –> 00:10:13,200
شما می توانید آن را به هم بزنید و بلافاصله آن را تغییر
277
00:10:13,200 –> 00:10:14,640
دهید، اما خوب
278
00:10:14,640 –> 00:10:16,000
است که آن را به عنوان یک پایه بگذارید اگر
279
00:10:16,000 –> 00:10:18,320
برای اولین بار با آن بازی می کنید و
280
00:10:18,320 –> 00:10:20,640
سپس چیز بعدی و این بسیار مهربان است.
281
00:10:20,640 –> 00:10:23,040
مهم است و می توانید انجام دهید این به صورت دستی
282
00:10:23,040 –> 00:10:25,600
با
283
00:10:26,000 –> 00:10:28,079
تشخیص گفتار روشن
284
00:10:28,079 –> 00:10:30,480
است، میکروفون شما
285
00:10:30,480 –> 00:10:32,640
286
00:10:32,640 –> 00:10:34,880
به طور پیشفرض حذف نویز ندارد، یعنی
287
00:10:34,880 –> 00:10:36,480
اگر کولر گازی من در
288
00:10:36,480 –> 00:10:38,720
پسزمینه کار کند، این صدای پسزمینه بلند را خواهید شنید.
289
00:10:38,720 –> 00:10:40,880
و اگر صحبتم را متوقف
290
00:10:40,880 –> 00:10:42,959
کنم یا هر صفی را در اینجا امتحان کنم
291
00:10:42,959 –> 00:10:44,160
چون اجازه می دهیم این خودکار
292
00:10:44,160 –> 00:10:46,399
خودش متوقف شود، می توانید آن را برای
293
00:10:46,399 –> 00:10:50,079
خود تنظیم کنید، در واقع می توانید مدت زمانی را تعیین کنید
294
00:10:50,640 –> 00:10:52,640
که در اینجا برای انجام نویز محیط انجام دادیم،
295
00:10:52,640 –> 00:10:53,680
296
00:10:53,680 –> 00:10:55,360
این دو ثانیه است
297
00:10:55,360 –> 00:10:58,320
یا می توانید می توانید به آن اطلاع دهید وقتی
298
00:10:58,320 –> 00:11:00,560
صحبت را متوقف می کنید، می توانید به هر یک از
299
00:11:00,560 –> 00:11:01,519
300
00:11:01,519 –> 00:11:05,200
صدای الکسیس گوگل فکر کنید، هر یک از آنهایی
301
00:11:05,200 –> 00:11:07,200
که منتظر مکث در صدا هستند و
302
00:11:07,200 –> 00:11:08,560
این یکی از کارهایی است که می توانند انجام دهند و
303
00:11:08,560 –> 00:11:11,279
سپس مدت زمانی را در آنجا دارند
304
00:11:11,279 –> 00:11:12,640
که این چیزی است که این آیا ما فقط می خواهیم
305
00:11:12,640 –> 00:11:15,760
صدای محیط را ضبط کنیم و بگوییم هی
306
00:11:15,760 –> 00:11:17,920
بیایید چند ثانیه ساکت باشیم و
307
00:11:17,920 –> 00:11:20,079
بعد از اینکه
308
00:11:20,079 –> 00:11:21,839
چند ثانیه ساکت شدیم، جلو می رویم و
309
00:11:21,839 –> 00:11:23,600
چیزها را انتخاب می کنیم و جلوتر می رویم و فقط
310
00:11:23,600 –> 00:11:24,800
این را اجرا کنید مطمئن شوید که هیچ e دریافت نمی کنیم
311
00:11:24,800 –> 00:11:27,800
اشتباهات
312
00:11:28,399 –> 00:11:30,000
و بنابراین شما می توانید درست اینجا را ببینید و
313
00:11:30,000 –> 00:11:32,240
من یک نشانه کوچک در اینجا داشتم اوه سکوت
314
00:11:32,240 –> 00:11:34,640
لطفاً نویز پس زمینه را
315
00:11:34,640 –> 00:11:37,680
کالیبره کنید.
316
00:11:37,680 –> 00:11:39,600
317
00:11:39,600 –> 00:11:43,040
318
00:11:43,040 –> 00:11:44,320
این است که ما می خواهیم جلو برویم
319
00:11:44,320 –> 00:11:46,800
و بلندگو
320
00:11:46,800 –> 00:11:48,399
یا میکروفون
321
00:11:48,399 –> 00:11:50,639
خود را تنظیم کنیم و به دنبال نویز محیط بگردیم تا
322
00:11:50,639 –> 00:11:52,880
نویز محیط را فیلتر کند و سپس می
323
00:11:52,880 –> 00:11:54,720
خواهیم در واقع فقط گوش
324
00:11:54,720 –> 00:11:56,880
کنیم و به ورودی کاربر گوش دهیم و ما می خواهیم
325
00:11:56,880 –> 00:11:58,399
326
00:11:58,399 –> 00:12:00,399
متغیری که ما این
327
00:12:00,399 –> 00:12:03,839
دادهها را بهعنوان audio2 قرار
328
00:12:03,839 –> 00:12:06,000
329
00:12:06,000 –> 00:12:09,000
330
00:12:11,200 –> 00:12:14,480
میدهیم و آن منبع 2 گوش ما خواهد بود و وقتی گوش میدهیم و زمانی
331
00:12:14,480 –> 00:12:16,959
که او به نقطه خاموشی میرسد متوقف میشود،
332
00:12:16,959 –> 00:12:20,160
آه، ادامه میدهیم و متن من را انجام میدهیم.
333
00:12:20,160 –> 00:12:22,320
334
00:12:22,320 –> 00:12:23,839
این مهم است زیرا
335
00:12:23,839 –> 00:12:26,240
استفاده از بسته گوگل یکی از
336
00:12:26,240 –> 00:12:28,800
چیزهای بسیار جالب در مورد علم داده
337
00:12:28,800 –> 00:12:30,160
امروزه است و انجام این پردازش های مختلف این
338
00:12:30,160 –> 00:12:31,360
339
00:12:31,360 –> 00:12:34,800
است که ما اکنون می توانیم از ابزارهای دیگر استفاده کنیم
340
00:12:34,800 –> 00:12:36,639
به جای اینکه مجبور باشیم با
341
00:12:36,639 –> 00:12:38,399
تلاش برای کشف نحوه ترنمنت شروع کنیم.
342
00:12:38,399 –> 00:12:40,000
صدای افراد را
343
00:12:40,000 –> 00:12:43,279
به دادهها برای یک رمزگذار داغ و اصلی تبدیل
344
00:12:43,279 –> 00:12:45,120
کنید، اکنون میتوانید این کار را انجام دهید و فایل صوتی خود را
345
00:12:45,120 –> 00:12:48,480
در آنجا اجرا کنید، در این صورت
346
00:12:48,480 –> 00:12:49,839
باید به فایلهای صوتی واقعی
347
00:12:49,839 –> 00:12:51,120
و آنچه آنها میپذیرند و
348
00:12:51,120 –> 00:12:52,320
همه چیز را نگاه کنید، اما ما فقط
349
00:12:52,320 –> 00:12:54,240
فایل صوتی را در آنجا ریخته و
350
00:12:54,240 –> 00:12:56,639
میخواهیم ببینیم که آیا آن را تشخیص میدهد،
351
00:12:56,639 –> 00:12:58,560
بنابراین بیایید پیش از اجرای این فایل صوتی را
352
00:12:58,560 –> 00:13:00,720
اجرا کنیم، بهتر است
353
00:13:00,720 –> 00:13:02,480
خروجی را چاپ کنم
354
00:13:02,480 –> 00:13:04,000
وگرنه هرگز نخواهیم دید ادامه
355
00:13:04,000 –> 00:13:05,600
356
00:13:05,600 –> 00:13:07,360
دارد، بیایید ادامه دهیم و این را اجرا کنیم و ببینیم
357
00:13:07,360 –> 00:13:10,079
358
00:13:10,880 –> 00:13:15,279
حالا که کالیبره شده چه اتفاقی میافتد، آیا کار میکند
359
00:13:17,360 –> 00:13:18,959
و میتوانید ببینید که آیا شما گفتید
360
00:13:18,959 –> 00:13:21,760
که اکنون کالیبره شده است آیا کار میکند و
361
00:13:21,760 –> 00:13:24,480
بنابراین
362
00:13:24,880 –> 00:13:27,600
ما میکروفون خود را به
363
00:13:27,600 –> 00:13:30,160
رایانه خود به متن منتقل کردهایم
364
00:13:30,160 –> 00:13:32,000
و فقط به این دلیل که سرگرم کننده است،
365
00:13:32,000 –> 00:13:33,920
می خواهیم ادامه دهیم و از ماژول کوچک خود استفاده کنیم،
366
00:13:33,920 –> 00:13:35,360
ما آن را با هم به نام
367
00:13:35,360 –> 00:13:37,360
speak text کنار هم می گذاریم و فقط می خواهیم
368
00:13:37,360 –> 00:13:39,440
متن من را در آن بیاندازیم و بیایید پیش برویم
369
00:13:39,440 –> 00:13:42,079
و این
370
00:13:43,519 –> 00:13:45,360
استقبال را اجرا کنیم تا به سادگی یاد
371
00:13:45,360 –> 00:13:49,720
بگیریم که گواهی نامه دریافت کنیم.
372
00:13:50,079 –> 00:13:51,680
به ساده گواهینامه دریافت کنید
373
00:13:51,680 –> 00:13:54,240
پیش بروید تقریباً آن را در آنجا داشتم که به
374
00:13:54,240 –> 00:13:56,720
نوعی خندهدار است، خوش آمدید به سادهتر،
375
00:13:56,720 –> 00:13:58,320
من



![فیلم آموزشی: نحوه ترسیم [چهار گوشه] [4.2.5 یا 2.12.5] [Python] [CodeHS] [توضیح] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/-dicqaxBpZgimage2.jpg)



![فیلم آموزشی: مطالعه موردی تجزیه و تحلیل داده پایتون | تجزیه و تحلیل داده های نکات رستوران در پایتون | [پاندا] [دریا زاده] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/fJ82678KNCkimage2.jpg)