در این مطلب، ویدئو تقسیم داده ها در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:12:30
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,299 –> 00:00:05,270
سلام بچه ها، در این ویدیو می خواهم
نحوه انجام تقسیم داده ها با استفاده از پایتون را توضیح دهم
2
00:00:05,270 –> 00:00:10,710
و یک تابع بسیار ساده از کتابخانه python scikit-learn وجود
دارد که این کار را انجام می دهد.
3
00:00:10,710 –> 00:00:14,940
من چند کد نمونه
دارم که تقسیم داده ها را در پایتون نشان می دهد که
4
00:00:14,940 –> 00:00:16,570
در این ویدیو به آنها می پردازم.
5
00:00:16,570 –> 00:00:21,659
قبل از اینکه به نمایش کد بپردازیم،
ابتدا میخواهم به سرعت به
6
00:00:21,659 –> 00:00:24,029
مردم یادآوری کنم که تقسیم داده چیست.
7
00:00:24,029 –> 00:00:29,269
وقتی در حال انجام تجزیه و تحلیل دادهها هستید، احتمالاً
میخواهید یک دیتافریم را به پایتون وارد کنید و
8
00:00:29,269 –> 00:00:31,579
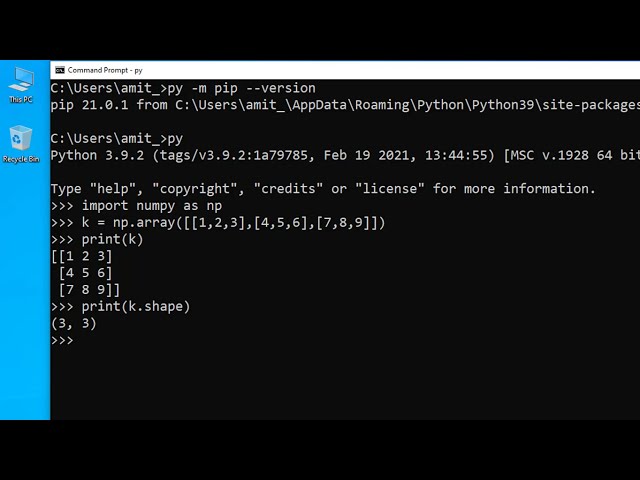
یک دیتافریم چیزی شبیه به این است.
9
00:00:31,579 –> 00:00:33,640
دارای ستون و ردیف است.
10
00:00:33,640 –> 00:00:39,511
ستون ها معمولاً متغیرها یا ویژگی های پیش بینی کننده هستند
و معمولاً
11
00:00:39,511 –> 00:00:40,511
تعدادی ویژگی دارید.
12
00:00:40,511 –> 00:00:43,690
و سپس معمولاً یک متغیر
نتیجه نیز دارید.
13
00:00:43,690 –> 00:00:45,789
این معمولا به عنوان y شما شناخته می شود.
14
00:00:45,789 –> 00:00:48,329
و اینها ستون هایی هستند که دیتافریم را تشکیل می دهند
.
15
00:00:48,329 –> 00:00:53,219
و سپس تعداد مشخصی ردیف دارید
و ردیف ها نمونه شما را نشان می دهند.
16
00:00:53,219 –> 00:00:58,109
فرض کنید مشاهداتی از 100 نفر دارید
و این حجم نمونه شماست.
17
00:00:58,109 –> 00:01:03,239
سپس 100 ردیف داده خواهید داشت
که مشاهداتی از همه ویژگی ها
18
00:01:03,239 –> 00:01:08,050
و متغیر نتیجه شما هستند. و این ستون ها
و سطرها با هم دیتافریم شما را می سازند.
19
00:01:08,050 –> 00:01:13,470
اکنون زمانی که میخواهید تجزیه و تحلیل دادهها را انجام دهید،
میخواهید مدلهای مختلف را با دادههای خود تطبیق دهید
20
00:01:13,470 –> 00:01:17,250
و سپس بهترین مدل را انتخاب کنید که متناسب با
دادههای شما باشد.
21
00:01:17,250 –> 00:01:22,590
وقتی در یادگیری ماشینی مدلها را با دادهها تطبیق
میدهید، ابتدا میخواهید تقسیم دادهها را انجام دهید.
22
00:01:22,590 –> 00:01:29,630
با تقسیم داده، شما به صورت
تصادفی از کل دیتافریم خود زیرمجموعه ای
23
00:01:29,630 –> 00:01:33,520
از این دیتافریم را نمونه برداری می کنید و اساساً آن را به
دو قسمت تقسیم می کنید.
24
00:01:33,520 –> 00:01:39,930
از چارچوب داده یا مجموعه داده اصلی خود، می
خواهید آن را به یک مجموعه آزمایشی و یک مجموعه قطار تقسیم
25
00:01:39,930 –> 00:01:41,510
کنید.
26
00:01:41,510 –> 00:01:47,560
با تقسیم دادهها، شما بهطور
تصادفی زیرمجموعهای از ردیفها و سپس تمام
27
00:01:47,560 –> 00:01:53,310
ستونها را از چارچوب دادهتان انتخاب میکنید و یک
انتخاب تصادفی را در مجموعه آزمایشی قرار میدهید و سپس
28
00:01:53,310 –> 00:01:56,480
بقیه ردیفهای باقیمانده به مجموعه آموزشی شما میروند
.
29
00:01:56,480 –> 00:02:02,020
هنگامی که این تقسیم داده ها را انجام می دهید، معمولاً
می خواهید حدود 80٪ از داده های تقسیم شده شما
30
00:02:02,020 –> 00:02:06,890
به مجموعه آموزشی برود و سپس می خواهید
حدود 20٪ به مجموعه تست بروید.
31
00:02:06,890 –> 00:02:12,440
اساسا اکثریت باید به تمرین بروند
و شما یک تکه برای رفتن به مجموعه تست می خواهید.
32
00:02:12,440 –> 00:02:14,760
گاهی اوقات افراد 75-25 انجام می دهند.
33
00:02:14,760 –> 00:02:20,200
تقسیمی که
میخواهید روی تعداد مشاهدات یا
34
00:02:20,200 –> 00:02:25,000
تعداد ردیفهای مجموعههایتان انجام دهید، بستگی به شما دارد، اما معمولاً
فرض کنید بین 80-20 است.
35
00:02:25,000 –> 00:02:30,990
و دلیل اینکه میخواهید این مرحله تقسیم دادهها را
قبل از انجام تجزیه و تحلیل دادهها انجام دهید این است که میخواهید
36
00:02:30,990 –> 00:02:38,590
مدلهای خود را بر روی مجموعه آموزشی آموزش دهید و
سپس بهترین مدل را بر اساس زیرمجموعهای
37
00:02:38,590 –> 00:02:43,330
از دادهها انتخاب کنید، و بعد از اینکه بهترین
مدل را انتخاب کردید. بیرون، سپس آن را جا میدهید و
38
00:02:43,330 –> 00:02:47,000
آزمایش میکنید که واقعاً چقدر با مجموعه آزمایشی شما مطابقت دارد
.
39
00:02:47,000 –> 00:02:52,160
اکنون زمانی که
قبل از انجام تجزیه و تحلیل داده ها، این تقسیم بندی آزمون-قطار را انجام می دهید،
40
00:02:52,160 –> 00:02:56,740
دلیلی که می خواهید این کار را انجام دهید بسیار مهم است
و اساساً به این دلیل است که می خواهید مدلی
41
00:02:56,740 –> 00:03:01,940
که انتخاب می کنید مطابق با
داده های نمونه شما باشد تا تعمیم یابد. خوب به جمعیت
42
00:03:01,940 –> 00:03:04,930
در آمار، شما هرگز نمی دانید که
جمعیت واقعی چگونه به نظر می رسد.
43
00:03:04,930 –> 00:03:09,311
شما فقط یک نمونه فرعی از جامعه را دریافت می کنید
44
00:03:09,311 –> 00:03:12,477
و فقط می توانید با استفاده از نمونه مشاهده شده خود مدل سازی کنید.
45
00:03:12,477 –> 00:03:16,320
بنابراین زمانی که شما یک مدل را متناسب میکنید، میخواهید آن را به اندازه کافی به
46
00:03:16,320 –> 00:03:21,313
مشاهدات جدید تعمیم دهید. بیایید بگوییم که ما متناسب با یک مدل هستیم. بیایید بگوییم که این مانند یک رگرسیون خطی است.
47
00:03:21,313 –> 00:03:27,230
ما مدلی را با مشاهدات خود متناسب می کنیم. خوب، در جمعیت ممکن است مشاهدات
48
00:03:27,230 –> 00:03:32,623
دیگری داشته باشید که مشاهده نمی کنید و ما همچنان می خواهیم مدل ما به خوبی با آن داده ها مطابقت داشته باشد.
49
00:03:32,767 –> 00:03:38,813
کاری که تقسیم داده انجام می دهد این است که به ما کمک می کند هم از برازش بیش از حد و هم از عدم تناسب مدل خود جلوگیری کنیم.
50
00:03:38,813 –> 00:03:43,554
ایده این است که اگر داده های خود را تقسیم نکنید، ممکن است مدل خود را بیش از حد برازش دهید.
51
00:03:43,554 –> 00:03:47,236
ممکن است مدلی را انتخاب کنید که واقعاً برای نمونه شما
52
00:03:47,236 –> 00:03:51,332
خوب عمل کند، اما ممکن است به خوبی به جمعیت مشاهده نشده تعمیم نکند،
53
00:03:51,332 –> 00:03:52,714
چیزی که ما واقعاً می خواهیم.
54
00:03:52,714 –> 00:03:56,910
یا برعکس، ممکن است از عدم تناسب مدلی اجتناب کنید، مدلی که
55
00:03:56,910 –> 00:04:00,942
پیچیدگی کامل آنچه در سطح جمعیت می گذرد را نشان نمی دهد.
56
00:04:00,942 –> 00:04:05,825
با تقسیم دادههای خود حداقل به دو بخش، یک مجموعه قطار و یک مجموعه آزمایشی،
57
00:04:05,825 –> 00:04:10,309
به جلوگیری از این مشکل کمک میکنید که دادههای خود را بیش از حد
58
00:04:10,309 –> 00:04:16,168
برازش میکند و کمتر برازش میکند، زیرا میخواهید مدل خود را به مجموعهای از دادهها منطبق کنید. داده ها و سپس
59
00:04:16,168 –> 00:04:21,882
وقتی داده ها را روی یک مجموعه آزمایشی آزمایش می کنید، مدل هرگز این مشاهدات جدید را در مجموعه آزمایشی ندیده است.
60
00:04:21,882 –> 00:04:27,085
بنابراین این مانند داده های جدیدی است که گویی از جمعیتی است که قبلاً مشاهده نشده بود.
61
00:04:27,085 –> 00:04:33,067
شما اساساً به خود اجازه میدهید که آزمایش کنید که مدل شما چقدر با مشاهدات مشاهده نشده عمل میکند.
62
00:04:33,067 –> 00:04:41,882
این یک مرحله واقعا رایج در تجزیه و تحلیل داده ها و یادگیری ماشین است. حالا بیایید به نحوه انجام این کار در پایتون بپردازیم.
63
00:04:41,882 –> 00:04:48,862
پایتون یک عملکرد بسیار ساده برای انجام تقسیم داده ها در کتابخانه پایتون scikit-learn دارد.
64
00:04:48,862 –> 00:04:54,315
من قصد دارم نسخه نمایشی کد خود را در Anaconda در یک نوت بوک Jupyter انجام دهم
65
00:04:54,315 –> 00:05:00,236
و محیطی که قرار است انتخاب کنم قبلاً کتابخانه python scikit-learn نصب شده است.
66
00:05:00,236 –> 00:05:06,807
وقتی به محیط خود می روید – هر محیطی که برای اجرای نوت بوک Jupyter خود انتخاب می کنید – فقط می خواهید مطمئن شوید که scikit-learn
67
00:05:06,807 –> 00:05:14,349
قبلاً نصب و بارگذاری شده است. وقتی محیط خود را بررسی می کنم، می بینم که قبلاً آن را دارم. کتابخانه scikit-learn python نصب شده است، به
68
00:05:14,349 –> 00:05:20,948
این معنی که می توانم از توابع آن کتابخانه استفاده کنم. و بعد، من فقط می خواهم یک دفترچه یادداشت Jupyter را باز کنم.
69
00:05:20,948 –> 00:05:29,024
من یک پوشه پایتون دارم و سپس یک پوشه تقسیم داده دارم. و این دفترچه یادداشت Jupyter من را دارد که می خواهم آن را باز
70
00:05:29,024 –> 00:05:34,411
کنم و همچنین داده هایی در همان پوشه دارد. و من قصد دارم از داده هایی که
71
00:05:34,411 –> 00:05:37,499
به صورت آنلاین پیدا کردم به عنوان نسخه آزمایشی خود برای اجرای کد استفاده کنم.
72
00:05:37,499 –> 00:05:41,872
این مثال کوتاه من از نحوه انجام تقسیم داده ها در پایتون است.
73
00:05:41,872 –> 00:05:51,062
من قصد دارم به نحوه تقسیم تصادفی این مجموعه داده ای که در kaggle پیدا کردم، بپردازم. این فقط



![فیلم آموزشی: چگونه یک [کاترپیلار رنگارنگ] [4.3.4 یا 2.13.4] [Python] [CodeHS] [توضیح داده شده] رسم کنیم با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/S58R4xtiCIYimage2.jpg)