در این مطلب، ویدئو وبینار زنده: تجزیه و تحلیل مجموعه داده های دیابت با استفاده از پایتون – قسمت 1/4 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:15:50
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,000 –> 00:00:02,970
احتمالاً میتوانم اکنون اشتراکگذاری صفحه را شروع کنم،
2
00:00:02,970 –> 00:00:04,319
بنابراین اجازه دهید لیست انتظار را بررسی کنم
3
00:00:04,319 –> 00:00:06,569
هیچکس به آن ملحق نمیشود چیزهای خوب، بنابراین
4
00:00:06,569 –> 00:00:09,360
صفحه اشتراکگذاری من کجاست، بیایید بلافاصله شروع کنیم،
5
00:00:09,360 –> 00:00:16,650
بنابراین امیدوارم اکنون بتوانید صفحه من را ببینید،
6
00:00:16,650 –> 00:00:21,600
بنابراین این کد پایتون است
7
00:00:21,600 –> 00:00:23,189
که من آماده کردهام با هم برای شما
8
00:00:23,189 –> 00:00:25,170
و من خوشحالم که اگر و چه چیزی علاقه مند است آن را به اشتراک بگذارم،
9
00:00:25,170 –> 00:00:28,800
بنابراین بحث در مورد
10
00:00:28,800 –> 00:00:31,080
اکتشاف بصری و تجزیه و تحلیل آماری
11
00:00:31,080 –> 00:00:33,480
در مورد مجموعه داده های دیابت با استفاده از پایتون
12
00:00:33,480 –> 00:00:36,210
و طرح حمله یا روشی که من
13
00:00:36,210 –> 00:00:38,700
این سخنرانی را ساختار داده ام در ابتدا است.
14
00:00:38,700 –> 00:00:41,489
ما چند تکنیک اساسی
15
00:00:41,489 –> 00:00:43,980
برای کاوش دادههای شما و پاکسازی
16
00:00:43,980 –> 00:00:46,649
آنها خواهیم داشت و بعد از آن
17
00:00:46,649 –> 00:00:49,800
به ترسیم چند طرح مفید و آموزنده
18
00:00:49,800 –> 00:00:51,989
میپردازیم، با چند طرح اولیه شروع
19
00:00:51,989 –> 00:00:53,600
میکنیم و سعی میکنیم کمی
20
00:00:53,600 –> 00:00:55,559
پیچیده است، اگرچه امروز همه
21
00:00:55,559 –> 00:00:58,140
چیز اساسی نیست، امروز خیلی عمیق نیست، پس از آن،
22
00:00:58,140 –> 00:00:59,969
ما نگاهی به
23
00:00:59,969 –> 00:01:01,949
تحلیل احتمالاتی خواهیم داشت که میتوانیم روی دادهها انجام
24
00:01:01,949 –> 00:01:04,769
دهیم تا شاید پیشبینیهایی
25
00:01:04,769 –> 00:01:08,369
انجام دهیم یا برخی پیشبینیهایی در مورد
26
00:01:08,369 –> 00:01:10,110
رویدادهای آینده یا موارد آینده انجام دهند. زمانی که ما
27
00:01:10,110 –> 00:01:11,640
افرادی را داریم که به کلینیک می آیند و
28
00:01:11,640 –> 00:01:13,530
اندازه گیری می کنند و بعد از
29
00:01:13,530 –> 00:01:17,280
آن نگاهی گذرا به یک
30
00:01:17,280 –> 00:01:20,909
تکنیک یادگیری ماشین اولیه به نام
31
00:01:20,909 –> 00:01:24,060
رگرسیون لجستیک می اندازیم که در آن سعی می کنیم
32
00:01:24,060 –> 00:01:25,950
مدلی برای استخراج داده ها بسازیم و سپس
33
00:01:25,950 –> 00:01:27,720
پیشبینیهای آینده را انجام دهید و سپس بررسی
34
00:01:27,720 –> 00:01:29,189
خواهیم کرد که آیا رویکرد احتمالی
35
00:01:29,189 –> 00:01:31,079
واقعاً با
36
00:01:31,079 –> 00:01:33,570
رگرسیون لجستیک مطابقت دارد یا خیر، بنابراین مشکلی نیست،
37
00:01:33,570 –> 00:01:35,700
بیایید بلافاصله به سراغ کدی برویم که
38
00:01:35,700 –> 00:01:41,430
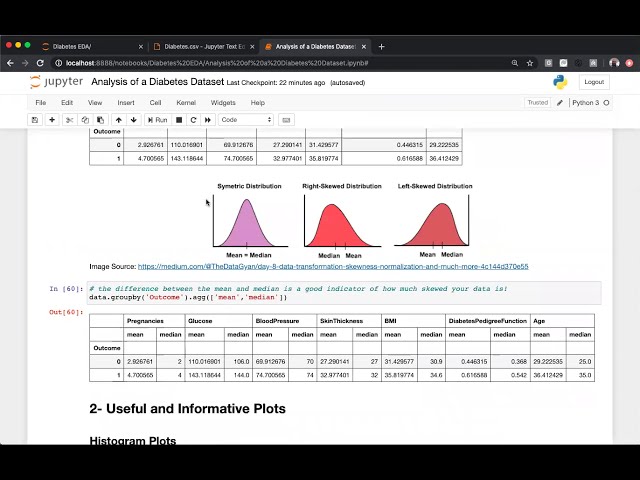
این کد من است و امیدوارم
39
00:01:41,430 –> 00:01:43,590
با پایتون آشنا باشیم. اگر
40
00:01:43,590 –> 00:01:45,119
نه نگران نباشید یادگیری جدایی بسیار آسان است
41
00:01:45,119 –> 00:01:48,210
و چیزی که من امروز میخواهم به آن بپردازم
42
00:01:48,210 –> 00:01:51,119
عمدتاً ایدهها است نه
43
00:01:51,119 –> 00:01:54,570
کد واقعی پایتون، بنابراین این مجموعه
44
00:01:54,570 –> 00:01:57,229
داده بهطور رایگان به صورت آنلاین در
45
00:01:57,229 –> 00:02:00,450
دسترس است و در دسترس است و میتوان آن را از آن دانلود کرد.
46
00:02:00,450 –> 00:02:02,100
منابع مختلف از برخی از Cargill
47
00:02:02,100 –> 00:02:03,570
و منابع مختلف من جزئیات را
48
00:02:03,570 –> 00:02:06,119
در اینجا ارائه کردم اگر می توانید ببینید همانطور که می بینید
49
00:02:06,119 –> 00:02:07,979
و این کد را بعداً در github قرار دادم تا
50
00:02:07,979 –> 00:02:10,139
بتوانید به آن دسترسی داشته باشید اما می خواهم شما
51
00:02:10,139 –> 00:02:12,209
این وضعیت واقعی را تصور کنید. در اینجا
52
00:02:12,209 –> 00:02:13,660
که این کار را انجام
53
00:02:13,660 –> 00:02:17,290
می دهید، سعی می کنید برخی از داده ها را جمع آوری کنید و
54
00:02:17,290 –> 00:02:19,150
سپس می خواهید این داده ها را تجزیه و تحلیل کنید،
55
00:02:19,150 –> 00:02:23,200
بنابراین این وبینار حاوی چندین
56
00:02:23,200 –> 00:02:24,880
تکنیک است که می تواند واقعاً برای
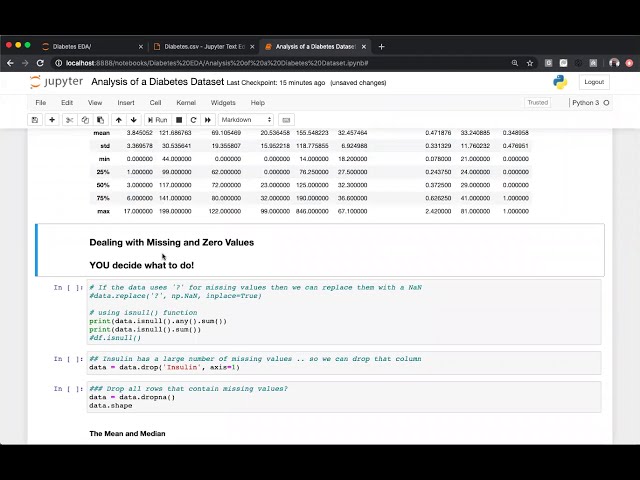
57
00:02:24,880 –> 00:02:28,870
هر نوع داده ای که من بر روی
58
00:02:28,870 –> 00:02:30,490
داده های پزشکی تمرکز می کنم اعمال شود، اما به طور کلی می تواند اینگونه باشد. برای هر چیزی اعمال می شود،
59
00:02:30,490 –> 00:02:32,800
بنابراین با این مجموعه داده، همانطور که
60
00:02:32,800 –> 00:02:35,200
گفتم، به صورت رایگان در دسترس است
61
00:02:35,200 –> 00:02:37,210
و به عنوان مثال در تعداد زیادی
62
00:02:37,210 –> 00:02:38,710
آموزش و ماشین آلات و
63
00:02:38,710 –> 00:02:40,270
تکنیک ها و تجزیه و تحلیل های مختلف در دسترس است، زیرا
64
00:02:40,270 –> 00:02:42,250
برای شما بسیار مهم است که بدانید همیشه
65
00:02:42,250 –> 00:02:44,530
در نظر داشته باشید که هر تکنیکی که ما
66
00:02:44,530 –> 00:02:46,810
توسعه ما همیشه باید آن را به
67
00:02:46,810 –> 00:02:47,290
روشی مفید اعمال کنیم
68
00:02:47,290 –> 00:02:50,770
و این داده ها چندین ستون دارد که یکی از
69
00:02:50,770 –> 00:02:53,740
آنها به عنوان مثال تعداد دفعاتی است
70
00:02:53,740 –> 00:02:56,860
که فرد باردار شده است یا چند بار
71
00:02:56,860 –> 00:02:59,200
بارداری آن فرد صفر یک یا
72
00:02:59,200 –> 00:03:01,180
چند بار داشته
73
00:03:01,180 –> 00:03:04,390
است. گلوکز فشار خون گرفته شده در
74
00:03:04,390 –> 00:03:07,030
آن زمان و اینها واحدهای
75
00:03:07,030 –> 00:03:09,700
ضخامت پوست هستند و این واحدها بر حسب
76
00:03:09,700 –> 00:03:12,940
میلی متر سطح انسولین
77
00:03:12,940 –> 00:03:14,680
BMI شاخص توده بدنی آن
78
00:03:14,680 –> 00:03:17,290
من هستند. چیزی به نام
79
00:03:17,290 –> 00:03:19,900
تابع شجره دیابت که تابعی است
80
00:03:19,900 –> 00:03:21,880
که احتمال ابتلا به دیابت را
81
00:03:21,880 –> 00:03:24,580
بر اساس برخی از سابقههای خانوادگی
82
00:03:24,580 –> 00:03:27,670
R امتیاز میدهد و سپس نتیجه
83
00:03:27,670 –> 00:03:30,100
آن صفر خواهد بود اگر آن فرد غیر دیابتی باشد
84
00:03:30,100 –> 00:03:32,830
و اگر آن فرد دیابتی باشد و
85
00:03:32,830 –> 00:03:35,170
معمولاً شما یک نتیجه میدهد. مجموعه دادهها را مانند این باز
86
00:03:35,170 –> 00:03:39,610
87
00:03:39,610 –> 00:03:42,190
88
00:03:42,190 –> 00:03:44,950
89
00:03:44,950 –> 00:03:46,180
میکنیم، مثلاً در اکسل یا هر جدولی که اساساً پلتفرمی است که به شما تجسم جدولی دادههای شما را میدهد، اما کاری که ما انجام میدهیم این است که سعی میکنیم
90
00:03:46,180 –> 00:03:50,110
فوراً آنها را در پایتون بارگذاری کنیم و
91
00:03:50,110 –> 00:03:52,209
همانطور که گفتم باید نگاهی به چند
92
00:03:52,209 –> 00:03:54,010
تکنیک و تجزیه و تحلیل و پاک کردن آن
93
00:03:54,010 –> 00:03:56,470
، بنابراین در اینجا من چند کتابخانه پایتون را وارد می کنم،
94
00:03:56,470 –> 00:03:57,730
همانطور که گفتم،
95
00:03:57,730 –> 00:03:59,590
نگران کد نباشید اگر پایتون را نمی دانید و
96
00:03:59,590 –> 00:04:01,840
در اینجا کاری که من انجام می دهم این است که داده ها را بارگذاری می کنم.
97
00:04:01,840 –> 00:04:04,150
به نام دیابت نقطه CSV منظورم این است که اگر من به
98
00:04:04,150 –> 00:04:08,650
اینجا بروم و فقط به شما نشان دهم می روم اینجا و
99
00:04:08,650 –> 00:04:11,080
فقط به شما نشان می دهم که چگونه به نظر می رسد بنابراین
100
00:04:11,080 –> 00:04:13,959
همانطور که می بینید این فقط یک داده جدولی است که
101
00:04:13,959 –> 00:04:15,640
توسط ستون فشار خون سطح گلوکز بارداری
102
00:04:15,640 –> 00:04:17,290
و غیره و غیره تنظیم شده است. چهارم
103
00:04:17,290 –> 00:04:19,298
و زمانی که یو شما این را در اکسل باز کنید یا
104
00:04:19,298 –> 00:04:20,529
چیزی شبیه به آن مانند یک
105
00:04:20,529 –> 00:04:23,250
جدول مناسب است حالا
106
00:04:23,250 –> 00:04:25,860
داده ها را بارگیری کنید من فقط آن را به عنوان یک فایل CSV خواندم
107
00:04:25,860 –> 00:04:27,990
که معمولاً فایل های CSV را ترجیح می دهیم
108
00:04:27,990 –> 00:04:29,760
اما با پایتون واقعاً می توانید
109
00:04:29,760 –> 00:04:31,740
هر قالبی را اگر JC باشد و اگر باشد. حتی
110
00:04:31,740 –> 00:04:33,990
در فرمت اکسل هم خوب است،
111
00:04:33,990 –> 00:04:35,910
بنابراین
112
00:04:35,910 –> 00:04:37,320
اگر با CSV آشنایی ندارید، نباید شما را از دیدن CSV ناراحت
113
00:04:37,320 –> 00:04:39,090
کند، خوب است، این فقط یک قالب متنی اولیه
114
00:04:39,090 –> 00:04:41,190
است و این فقط یک نگاه کوتاه یا
115
00:04:41,190 –> 00:04:43,290
نگاهی سریع به چند ردیف بالای آن است.
116
00:04:43,290 –> 00:04:45,720
جدول بنابراین ما سطح گلوکز بارداری
117
00:04:45,720 –> 00:04:47,700
فشار خون ضخامت پوست
118
00:04:47,700 –> 00:04:51,030
انسولین BMI شجره نامه سن و
119
00:04:51,030 –> 00:04:52,650
سپس نتیجه و به یاد داشته باشید یکی به این معنی است
120
00:04:52,650 –> 00:04:56,490
که آن فرد دیابت صفر
121
00:04:56,490 –> 00:05:00,360
دارد یعنی دیابتی نیست و یک
122
00:05:00,360 –> 00:05:04,500
نگاه سریع حتی در چند ردیف به ما می گوید که ما
123
00:05:04,500 –> 00:05:06,720
مقداری داشته باشید که ما آن را به نام Nan یا مقادیر گمشده می نامیم،
124
00:05:06,720 –> 00:05:09,780
بنابراین شاید زمانی که داده ها
125
00:05:09,780 –> 00:05:12,000
اندازه گیری شده اند هنگام اندازه گیری ها
126
00:05:12,000 –> 00:05:15,630
و جمع آوری داده ها، برخی از
127
00:05:15,630 –> 00:05:16,980
اندازه گیری ها به
128
00:05:16,980 –> 00:05:19,020
دلایلی انجام نشده اند، داده ها از دست رفته است که فرد
129
00:05:19,020 –> 00:05:21,000
از انجام اندازه گیری امتناع می کند. r شاید
130
00:05:21,000 –> 00:05:22,800
در حالی که افراد ورودی را دریافت می
131
00:05:22,800 –> 00:05:23,910
کنند، دلایل زیادی وجود دارد که چرا
132
00:05:23,910 –> 00:05:25,890
این اتفاقات رخ می دهد، اما به هر حال متوجه
133
00:05:25,890 –> 00:05:27,150
می شویم که برخی از داده های گم شده در این
134
00:05:27,150 –> 00:05:29,460
ستون به خصوص داریم و سپس این نقطه را نیز حذف
135
00:05:29,460 –> 00:05:31,680
می کنیم که مقداری
136
00:05:31,680 –> 00:05:34,260
داده با مقدار صفر خواهیم داشت. به آن دشمن، بنابراین برای انجام
137
00:05:34,260 –> 00:05:36,330
برخی کاوش و پاکسازی، ما همیشه
138
00:05:36,330 –> 00:05:38,729
سعی میکنیم اطلاعات خود را احساس و نگاه کنیم،
139
00:05:38,729 –> 00:05:40,650
بنابراین
140
00:05:40,650 –> 00:05:41,970
هر زمان که این کار را انجام میدهید، هر زمان که
141
00:05:41,970 –> 00:05:43,650
تجزیه و تحلیل دادهها را انجام میدهید، همیشه به دادههای خود نگاهی بیندازید،
142
00:05:43,650 –> 00:05:46,470
سعی کنید آنها را کشف کنید.
143
00:05:46,470 –> 00:05:48,810
ببینید محتویات چگونه به نظر می رسند شاید
144
00:05:48,810 –> 00:05:50,310
واحدهای اندازه گیری اطمینان حاصل کنند که کل
145
00:05:50,310 –> 00:05:52,710
یکنواخت است به عنوان مثال به مقادیر از دست رفته
146
00:05:52,710 –> 00:05:55,229
نگاه کنید به ورودی های اشتباه نگاه کنید به عنوان مثال
147
00:05:55,229 –> 00:05:56,580
گاهی اوقات شما یک ستون عددی مانند
148
00:05:56,580 –> 00:05:57,870
این دارید که در آن مقادیر قرار است
149
00:05:57,870 –> 00:06:00,690
همیشه اعداد باشند همیشه عددی درست و
150
00:06:00,690 –> 00:06:03,210
ممکن است گاهی اوقات شما بتوانید
151
00:06:03,210 –> 00:06:06,290
متنی را در آنجا داشته باشید که اشتباها وارد شده است
152
00:06:06,290 –> 00:06:08,700
همیشه به این موارد نگاه کنید، بنابراین
153
00:06:08,700 –> 00:06:10,890
مشخص است که داده ها دارای مقادیر گم شده یا صفر
154
00:06:10,890 –> 00:06:13,440
هستند همانطور که می توانیم مشاهده کنیم. به عنوان مثال، اگر
155
00:06:13,440 –> 00:06:15,390
به ضخامت پوست نگاه کنید، منظور من این است که
156
00:06:15,390 –> 00:06:17,220
هیچ کس ضخامت پوست صفر
157
00:06:17,220 –> 00:06:18,960
میلی متر ندارد، بنابراین
158
00:06:18,960 –> 00:06:20,820
منطقی نیست، به این معنی است که برخی از
159
00:06:20,820 –> 00:06:22,860
خطاها در آنجا وجود دارد که مشکل ساز است و
160
00:06:22,860 –> 00:06:25,710
همچنین ما سطح انسولین 9 را داریم، بنابراین
161
00:06:25,710 –> 00:06:28,020
در دسترس نیستیم. nan اساساً به معنای یک
162
00:06:28,020 –> 00:06:29,580
عدد یا چیزی شبیه به آن نیست، بنابراین
163
00:06:29,580 –> 00:06:32,610
در دسترس نیست که همچنین مشکل ساز است،
164
00:06:32,610 –> 00:06:34,919
گاهی اوقات مقادیر گم شده می توانند به
165
00:06:34,919 –> 00:06:36,719
شکل علامت سوال باشند، بنابراین همیشه
166
00:06:36,719 –> 00:06:40,560
به این توجه کنید و از آنجا
167
00:06:40,560 –> 00:06:43,500
اکنون باید تصمیم بگیرید که چه کاری انجام دهید، اما
168
00:06:43,500 –> 00:06:45,180
قبل از اینکه واقعاً انجام دهید. در پردازش این، اجازه دهید
169
00:06:45,180 –> 00:06:47,009
نگاهی به محتویات با
170
00:06:47,009 –> 00:06:48,750
جزئیات بیشتری از دادهها بیندازیم، بنابراین در اینجا ما
171
00:06:48,750 –> 00:06:51,479
یک جدول داریم، فقط یک جدول خلاصه از دادهها
172
00:06:51,479 –> 00:06:53,729
که حدود صد و
173
00:06:53,729 –> 00:06:55,139
شصت و هشت ورودی داریم، بنابراین دادهها شامل
174
00:06:55,139 –> 00:06:57,810
68 ردیف و اینها هستند. ستون هایی هستند که در
175
00:06:57,810 –> 00:06:59,460
هر ستون چند ورودی موجود و
176
00:06:59,460 –> 00:07:01,680
چند ورودی غیر پوچ و
177
00:07:01,680 –> 00:07:04,560
سپس نوع داده عدد صحیح عددی
178
00:07:04,560 –> 00:07:09,229
شناور و غیره و غیره را نشان می دهد و
179
00:07:09,229 –> 00:07:11,310
بنابراین گاهی اوقات آنها پست می کنند زیرا برخی از
180
00:07:11,310 –> 00:07:13,439
افراد در واقع میخواهم به آن بپیوندم، بنابراین اکنون
181
00:07:13,439 –> 00:07:16,110
فشار خون گلوکز بارداری او
182
00:07:16,110 –> 00:07:17,759
متوجه انسولین میشوید، به عنوان مثال به یاد داشته باشید
183
00:07:17,759 –> 00:07:20,909
که دادهها 768 ورودی دارد، اما با
184
00:07:20,909 –> 00:07:24,120
انسولین، مقادیر اسمی کمتر از
185
00:07:24,120 –> 00:07:26,340
400 هستند، به این معنی که ستون دارای
186
00:07:26,340 –> 00:07:28,409
تعداد زیادی مقادیر گم شده است،
187
00:07:28,409 –> 00:07:31,080
احتمالاً تقریباً حدود 50% یا کمی
188
00:07:31,080 –> 00:07:33,360
کمتر از 50% گم شده است، بنابراین در اینجا شما
189
00:07:33,360 –> 00:07:34,590
باید مطمئن باشید که با این کد چه کاری انجام دهید
190
00:07:34,590 –> 00:07:37,259
و آن را رها کنید، فقط آن را حذف کنید چه
191
00:07:37,259 –> 00:07:39,180
کاری انجام دهید واقعاً به شما بستگی دارد، من چند تکنیک را به شما نشان خواهم داد
192
00:07:39,180 –> 00:07:40,469
اما این
193
00:07:40,469 –> 00:07:42,599
واقعاً به شما بستگی دارد، اما این یک راه خوب است
194
00:07:42,599 –> 00:07:44,129
که در واقع میدانید خلاصهای از
195
00:07:44,129 –> 00:07:45,719
چیزهایی که نیاز دارید داشته باشید، چه چیزی در دسترس است، چه چیزی
196
00:07:45,719 –> 00:07:48,750
نیست و سپس در دکمه پایتون، این
197
00:07:48,750 –> 00:07:51,300
بستهای است به نام پاندا در
198
00:07:51,300 –> 00:07:54,810
پایتون این بسته در اینجا ما یک عملکرد دیگر داریم.
199
00:07:54,810 –> 00:07:56,639
به



![فیلم آموزشی: 12. ماژول ها [آموزش برنامه نویسی پایتون 3] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/DdGVBZv46PIimage2.jpg)
![فیلم آموزشی: [EN 84] اسکریپت نویسی عملیات اتوکد با پایتون با استفاده از pyautocad با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/4WKzrUy_bwcimage2.jpg)