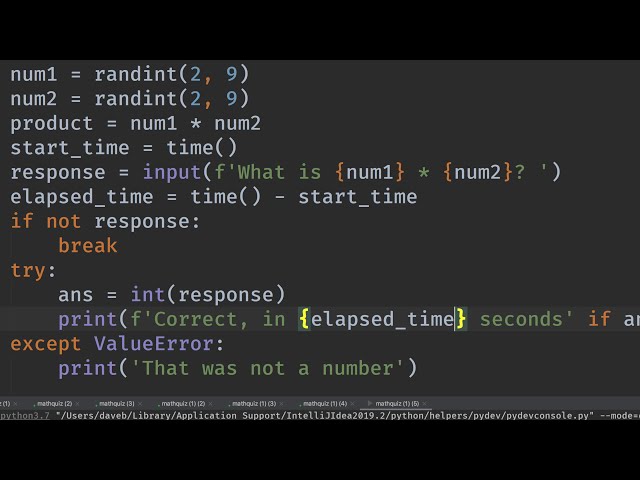
در این مطلب، ویدئو آموزش Python Quants 10 – NLP – تحلیل متن خبری | توسعه دهندگان Refinitiv با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:11:57
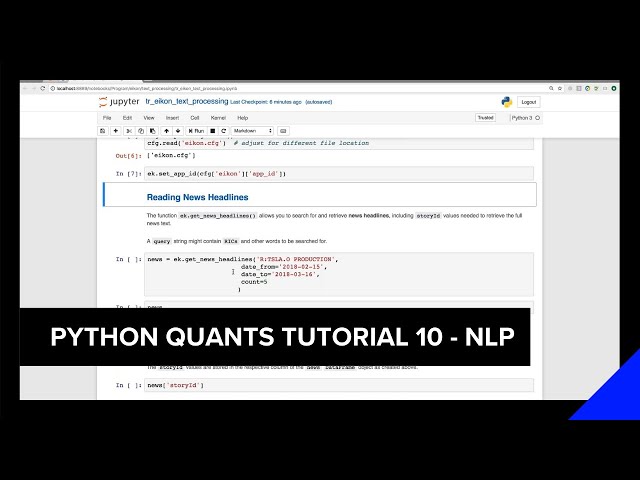
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:02,159 –> 00:00:03,120
سلام و
2
00:00:03,120 –> 00:00:06,720
خوش آمدید به این آموزش icon data api
3
00:00:06,720 –> 00:00:07,680
نام من eve است
4
00:00:07,680 –> 00:00:10,240
من بنیانگذار و شریک مدیریت
5
00:00:10,240 –> 00:00:13,120
python quants
6
00:00:13,440 –> 00:00:15,440
هستم. آموزش امروز در مورد پردازش متن است
7
00:00:15,440 –> 00:00:16,720
به ویژه
8
00:00:16,720 –> 00:00:18,960
ما به
9
00:00:18,960 –> 00:00:20,240
پردازش زبان طبیعی
10
00:00:20,240 –> 00:00:23,600
برای پشته های جدید و با توجه به دستور کار توجه خواهیم کرد.
11
00:00:23,600 –> 00:00:24,880
12
00:00:24,880 –> 00:00:27,119
در اینجا که نحوه
13
00:00:27,119 –> 00:00:28,720
بازیابی عناوین اخبار
14
00:00:28,720 –> 00:00:30,720
و متن کامل داستان را از
15
00:00:30,720 –> 00:00:32,238
icon data api خواهیم دید،
16
00:00:32,238 –> 00:00:34,719
سپس نحوه استخراج متن خام از نسخه
17
00:00:34,719 –> 00:00:36,000
html
18
00:00:36,000 –> 00:00:38,160
ارائه شده را خواهیم
19
00:00:38,160 –> 00:00:39,520
دید،
20
00:00:39,520 –> 00:00:42,559
برای یک تگ خام مقداری نشانه گذاری انجام می دهیم، همچنین چند تگ خام را جمع آوری خواهیم کرد.
21
00:00:42,559 –> 00:00:45,039
کنار هم قرار دادن آنها و
22
00:00:45,039 –> 00:00:46,680
توکن کردن آنها
23
00:00:46,680 –> 00:00:49,840
به طور همزمان و در قسمت پایانی خواهیم
24
00:00:49,840 –> 00:00:50,320
25
00:00:50,320 –> 00:00:53,520
دید که چگونه برای یک مجموعه متن خام واژگان بسازیم،
26
00:00:53,520 –> 00:00:55,199
همه اینها
27
00:00:55,199 –> 00:00:57,520
به نوعی کارهای اساسی هستند که شما در پردازش زبان طبیعی انجام می دهید
28
00:00:57,520 –> 00:00:58,399
29
00:00:58,399 –> 00:01:01,440
و در بسیاری از موارد پایه و اساس را
30
00:01:01,440 –> 00:01:02,559
برای موارد
31
00:01:02,559 –> 00:01:05,199
بیشتر ایجاد می کنند. تجزیه و تحلیل پیچیده مانند یادگیری ماشین
32
00:01:05,199 –> 00:01:06,080
33
00:01:06,080 –> 00:01:09,840
یا تجزیه و تحلیل احساسات برای نام بردن فقط
34
00:01:09,840 –> 00:01:13,360
دو مورد من اکنون مستقیماً
35
00:01:13,360 –> 00:01:16,880
وارد دفترچه یادداشت مشتری می شوم در اینجا
36
00:01:16,880 –> 00:01:20,400
طبق معمول با واردات شروع می شود
37
00:01:20,400 –> 00:01:22,159
و ما همچنین
38
00:01:22,159 –> 00:01:23,759
نگاهی گذرا به نسخههایی خواهیم داشت
39
00:01:23,759 –> 00:01:24,640
40
00:01:24,640 –> 00:01:27,119
که بهویژه برای پردازش زبان طبیعی
41
00:01:27,119 –> 00:01:28,000
42
00:01:28,000 –> 00:01:31,200
استفاده میکنیم، از nltk و bs4 استفاده میکنیم، بنابراین
43
00:01:31,200 –> 00:01:33,200
این جعبه ابزار زبان طبیعی و همچنین
44
00:01:33,200 –> 00:01:34,640
45
00:01:34,640 –> 00:01:37,759
سوپ زیبا است، البته در
46
00:01:37,759 –> 00:01:39,119
47
00:01:39,119 –> 00:01:40,720
زمانی که ما به بستهبندی آیکون نیاز داریم. نگاهی به نسخههای
48
00:01:40,720 –> 00:01:44,000
معمولی پایتون 3.6
49
00:01:44,000 –> 00:01:47,360
، نسخه nltk و سوپ زیبا،
50
00:01:47,360 –> 00:01:49,840
بنابراین ما میخواهیم به
51
00:01:49,840 –> 00:01:52,000
icon data api متصل شویم، بنابراین پروکسی یا
52
00:01:52,000 –> 00:01:54,320
خود نماد باید در پسزمینه اجرا شود
53
00:01:54,320 –> 00:01:55,840
54
00:01:55,840 –> 00:01:59,040
تا بتوانیم به دادههایی که دریافت میکنیم دسترسی داشته
55
00:01:59,040 –> 00:02:02,880
باشیم. در اینجا با تابع um شروع
56
00:02:02,880 –> 00:02:05,920
به دریافت عناوین اخبار می کنیم و
57
00:02:05,920 –> 00:02:08,318
چیزی که می خواهیم بازیابی کنیم برخی از
58
00:02:08,318 –> 00:02:09,199
اخبار مربوط به
59
00:02:09,199 –> 00:02:12,800
تسلا و تولید است و
60
00:02:12,800 –> 00:02:15,920
نوعی دوره زمانی را اصلاح می کنیم و
61
00:02:15,920 –> 00:02:18,160
با کدی که در اینجا ارائه شده است،
62
00:02:18,160 –> 00:02:19,760
فقط
63
00:02:19,760 –> 00:02:22,319
پنج عنوان جدید را در صورت وجود بازیابی خواهیم کرد.
64
00:02:22,319 –> 00:02:22,879
65
00:02:22,879 –> 00:02:24,239
اگر تعداد بیشتری وجود داشته باشد، این حداکثر خواهد بود،
66
00:02:24,239 –> 00:02:26,720
ما
67
00:02:26,720 –> 00:02:29,599
تعداد را همانطور که در اینجا مشخص شده است دریافت خواهیم کرد، بنابراین وقتی
68
00:02:29,599 –> 00:02:31,280
این را اجرا می کنم،
69
00:02:31,280 –> 00:02:34,400
می بینیم که آنچه در اینجا تحویل داده می شود
70
00:02:34,400 –> 00:02:34,720
،
71
00:02:34,720 –> 00:02:37,120
قاب داده است و ما
72
00:02:37,120 –> 00:02:38,160
اطلاعات داده را
73
00:02:38,160 –> 00:02:40,800
نیز نوعی داریم. اولین نگاهی اجمالی به متن
74
00:02:40,800 –> 00:02:41,680
به ویژه
75
00:02:41,680 –> 00:02:43,680
آنچه برای ما مهم است که
76
00:02:43,680 –> 00:02:46,319
بعداً با آن کار کنیم، شناسه داستان است که به ما اجازه می
77
00:02:46,319 –> 00:02:48,879
دهد به عنوان مثال متن کامل را بازیابی کنیم
78
00:02:48,879 –> 00:02:50,480
و می بینید که قبلاً اینجا در ستون متن
79
00:02:50,480 –> 00:02:52,879
تسلا می گوید کم و بیش و
80
00:02:52,879 –> 00:02:53,920
غیره بنابراین
81
00:02:53,920 –> 00:02:56,959
آنچه را که ما در اینجا درخواست می کردیم، ریک
82
00:02:56,959 –> 00:03:00,879
برای تسلا و تولید را اضافه کرده
83
00:03:00,879 –> 00:03:04,319
ایم و اکنون باید پنج
84
00:03:04,319 –> 00:03:06,959
متن خبری در اینجا داشته باشیم، حداقل مانند
85
00:03:06,959 –> 00:03:07,840
86
00:03:07,840 –> 00:03:10,879
دو کلمه اول که تسلا در
87
00:03:10,879 –> 00:03:13,519
آن نقش دارد، اکنون اجازه دهید متن کامل
88
00:03:13,519 –> 00:03:14,800
و به این مجموعه را بازیابی کنیم. ما از
89
00:03:14,800 –> 00:03:17,920
تابع دیگر get news Story در آنجا استفاده می کنیم
90
00:03:17,920 –> 00:03:19,200
و همانطور که قبلا ذکر شد
91
00:03:19,200 –> 00:03:22,239
برای بازیابی متن کامل به شناسه داستان نیاز داریم
92
00:03:22,239 –> 00:03:25,680
و شناسه های داستان
93
00:03:25,680 –> 00:03:27,599
در ستون های مربوطه ذخیره می شوند تا
94
00:03:27,599 –> 00:03:29,040
بتوانیم یکی را
95
00:03:29,040 –> 00:03:32,159
برای مثال در اینجا یا دومی را از
96
00:03:32,159 –> 00:03:33,120
این لیست انتخاب
97
00:03:33,120 –> 00:03:35,840
کنیم. می خواهید با آن کار کنید و استوری جدید می گیرید
98
00:03:35,840 –> 00:03:36,879
با
99
00:03:36,879 –> 00:03:40,000
قرار دادن استوری id متن را به صورت html به ما می دهد
100
00:03:40,000 –> 00:03:41,280
101
00:03:41,280 –> 00:03:43,280
و با استفاده از صفحه نمایش پایتون من تابع
102
00:03:43,280 –> 00:03:44,879
html
103
00:03:44,879 –> 00:03:47,920
متن کامل را نمایش می دهد و
104
00:03:47,920 –> 00:03:49,599
حالا می بینید
105
00:03:49,599 –> 00:03:52,560
که کاملاً متن است و در ادامه مطلب ما
106
00:03:52,560 –> 00:03:53,360
می خواهیم با چنین متنی کار کنیم که
107
00:03:53,360 –> 00:03:55,840
او به عنوان html ارائه کرده است و
108
00:03:55,840 –> 00:03:56,799
109
00:03:56,799 –> 00:04:00,000
قبلاً به عنوان html ما می خواهیم کار کنیم،
110
00:04:00,000 –> 00:04:03,040
اما برای اینکه بتوانیم راحت تر
111
00:04:03,040 –> 00:04:05,280
از درون زمینه پایتون کار
112
00:04:05,280 –> 00:04:07,760
کنیم، ابتدا آن را تجزیه و
113
00:04:07,760 –> 00:04:08,879
به
114
00:04:08,879 –> 00:04:12,840
یک متن خام تبدیل می کنیم. به شکل یک شی strain ساده،
115
00:04:12,840 –> 00:04:15,920
116
00:04:15,920 –> 00:04:20,238
پس استخراج متن خام در مرحله بعد
117
00:04:20,238 –> 00:04:23,440
دوباره متن را در اینجا ابتدا به صورت
118
00:04:23,440 –> 00:04:26,479
html بازیابی می کنیم و می توانیم از لوله زیبا
119
00:04:26,479 –> 00:04:30,240
در اینجا برای تجزیه آن استفاده کنیم تا متن خام را دریافت کنیم
120
00:04:30,240 –> 00:04:33,280
و وقتی اینجا را به عنوان مثال برای اولین بار نگاه می کنم.
121
00:04:33,280 –> 00:04:34,960
وقوع تسلا
122
00:04:34,960 –> 00:04:37,840
و من شروع به چاپ آن می
123
00:04:37,840 –> 00:04:38,240
کنم، اینجا می بینید
124
00:04:38,240 –> 00:04:40,880
که ما اکنون نسخه چاپی را دریافت می کنیم که
125
00:04:40,880 –> 00:04:41,840
126
00:04:41,840 –> 00:04:44,960
دیگر html نیست، این اکنون یک متن ساده است که می توانیم آن
127
00:04:44,960 –> 00:04:46,000
را چاپ
128
00:04:46,000 –> 00:04:49,280
کنیم و می بینیم که متنی که با تسلا شروع می شود،
129
00:04:49,280 –> 00:04:51,600
این همان چیزی است که من دنبالش بودم.
130
00:04:51,600 –> 00:04:52,320
131
00:04:52,320 –> 00:04:54,720
و من از نمایه ای که
132
00:04:54,720 –> 00:04:55,600
از این
133
00:04:55,600 –> 00:04:59,199
عملیات جستجو بازیابی کردم برای چاپ متن استفاده کردم
134
00:04:59,199 –> 00:05:02,479
، اکنون اولین
135
00:05:02,479 –> 00:05:05,759
تحلیل واقعی بر اساس متن است، بنابراین ما
136
00:05:05,759 –> 00:05:06,160
137
00:05:06,160 –> 00:05:08,960
از nltk بسته nltk در اینجا برای نشانه گذاری استفاده می کنیم
138
00:05:08,960 –> 00:05:10,479
139
00:05:10,479 –> 00:05:13,919
تا بدین منظور به یک بسته uh اضافی t نیاز داریم.
140
00:05:13,919 –> 00:05:15,440
در اینجا که باید
141
00:05:15,440 –> 00:05:18,000
دانلود شود، یک بسته برای یک ltk است
142
00:05:18,000 –> 00:05:21,600
که به آن punct میگویند و این فقط برای
143
00:05:21,600 –> 00:05:22,240
اطمینان از
144
00:05:22,240 –> 00:05:24,560
اینکه قبلاً وجود دارد، بله ما آن را داریم
145
00:05:24,560 –> 00:05:25,840
و
146
00:05:25,840 –> 00:05:28,080
توکنسازی به سادگی فراخوانی کلمه
147
00:05:28,080 –> 00:05:29,199
tokenize است که
148
00:05:29,199 –> 00:05:33,360
قبلاً روی متن خام وارد کردم
149
00:05:33,360 –> 00:05:35,600
و زمانی که من اکنون نگاهی میاندازم به عنوان مثال
150
00:05:35,600 –> 00:05:37,199
از
151
00:05:37,199 –> 00:05:40,080
مقدار شاخص بیستم شروع میکنیم، میبینیم که در
152
00:05:40,080 –> 00:05:41,840
اینجا کلماتی مانند گزارشهایی را دریافت میکنیم که
153
00:05:41,840 –> 00:05:44,880
سازنده خودروهای برقی مجبور کرده است
154
00:05:44,880 –> 00:05:48,320
و غیره، بنابراین اساس توکنها
155
00:05:48,320 –> 00:05:49,360
اکنون میتوانیم
156
00:05:49,360 –> 00:05:53,759
به مخاطبین برای توکنهای مختلف دسترسی داشته باشیم
157
00:05:53,759 –> 00:05:56,639
تا بدین منظور. ابتدا باید آن را پردازش کنیم
158
00:05:56,639 –> 00:06:00,240
و سپس میتوانیم از روش تطابق
159
00:





![فیلم آموزشی: [3.1] ایجاد کلاس گره و لیست پیوندی | ساختارهای داده در پایتون با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/PexeeNmPeA4image2.jpg)