در این مطلب، ویدئو خط لوله یادگیری ماشین در پایتون | نحوه اجرای خط لوله در یادگیری ماشین پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:11:04
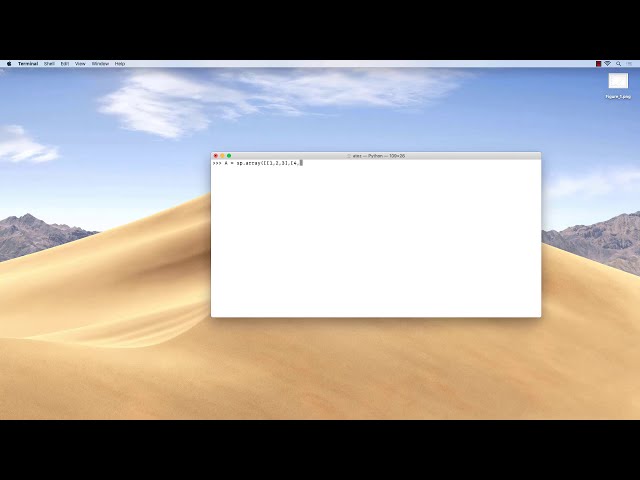
تصاویر این ویدئو:

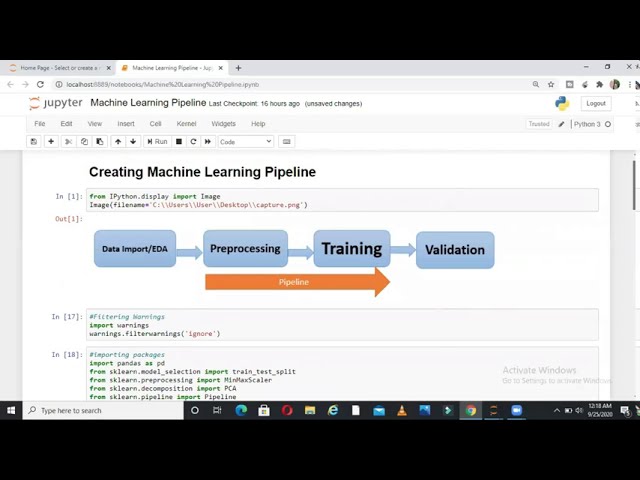
قسمتی از زیرنویس این فیلم:
00:00:00,240 –> 00:00:03,199
همانطور که می توانید یک فرآیند آموزش یادگیری ماشینی ساده
2
00:00:03,199 –> 00:00:06,319
را در اینجا مشاهده کنید که از وارد کردن داده ها شروع می شود
3
00:00:06,319 –> 00:00:07,600
4
00:00:07,600 –> 00:00:10,240
تا پیش پردازش داده ها تا آموزش مدل
5
00:00:10,240 –> 00:00:11,040
6
00:00:11,040 –> 00:00:13,440
و سپس رفتن به اعتبارسنجی مدل، بنابراین
7
00:00:13,440 –> 00:00:15,040
همه این مراحل
8
00:00:15,040 –> 00:00:15,679
9
00:00:15,679 –> 00:00:18,160
برای انجام این کار خاص به کدهای مختلفی
10
00:00:18,160 –> 00:00:19,359
11
00:00:19,359 –> 00:00:20,960
نیاز دارند.
12
00:00:20,960 –> 00:00:22,800
قطعه کد متفاوتی نیاز به کد متفاوتی دارد،
13
00:00:22,800 –> 00:00:24,560
بنابراین آنچه که در آخرین ویدیوی خود بحث کردم
14
00:00:24,560 –> 00:00:27,199
این است که می توانیم خط لوله ای ایجاد
15
00:00:27,199 –> 00:00:29,920
کنیم که در آن می توانیم چندین مرحله را
16
00:00:29,920 –> 00:00:31,760
با هم ترکیب کنیم به گونه ای که
17
00:00:31,760 –> 00:00:34,880
مدیریت کد ما آسان
18
00:00:34,880 –> 00:00:38,079
تر شود و قابل حمل تر شود و ساده به نظر می رسد
19
00:00:38,079 –> 00:00:40,559
ساده برای استفاده ساده برای اشکال زدایی درست،
20
00:00:40,559 –> 00:00:42,960
بنابراین در این ویدیو می
21
00:00:42,960 –> 00:00:44,160
خواهم نمونه
22
00:00:44,160 –> 00:00:46,399
ای از گرفتن داده و ایجاد یک
23
00:00:46,399 –> 00:00:48,000
خط لوله را به شما نشان دهم که در آن
24
00:00:48,000 –> 00:00:51,199
از مقیاس و خط لوله برای وارد کردن
25
00:00:51,199 –> 00:00:53,440
مرحله پیش پردازش و مرحله آموزش
26
00:00:53,440 –> 00:00:54,960
در یک خط لوله استفاده می کنم،
27
00:00:54,960 –> 00:00:57,280
بنابراین چگونه برای انجام این کار با استفاده از یک داده و نحوه
28
00:00:57,280 –> 00:00:58,000
29
00:00:58,000 –> 00:01:00,559
اجرای مدل با خط لوله، میخواهم
30
00:01:00,559 –> 00:01:01,440
31
00:01:01,440 –> 00:01:03,760
گام به گام در این ویدیو
32
00:01:03,760 –> 00:01:05,680
نشان دهم. نام امان است و
33
00:01:05,680 –> 00:01:07,119
من یک دانشمند داده هستم،
34
00:01:07,119 –> 00:01:10,320
بیایید شروع کنیم، بنابراین در اینجا من این را گام به گام اجرا می کنم،
35
00:01:10,320 –> 00:01:12,479
بنابراین کاری که من اینجا انجام می دهم این است
36
00:01:12,479 –> 00:01:14,159
که من فقط برخی از بسته های مورد نیاز را
37
00:01:14,159 –> 00:01:14,960
38
00:01:14,960 –> 00:01:16,880
وارد می کنم، بنابراین بچه ها چه بسته هایی را وارد می کنم،
39
00:01:16,880 –> 00:01:19,680
بگذارید اینجا ببینیم پانداها
40
00:01:19,680 –> 00:01:22,159
مقیاس معمولی است و تقسیم روند انتخاب مدل
41
00:01:22,159 –> 00:01:22,880
42
00:01:22,880 –> 00:01:24,720
از مقیاس و پیش پردازش نقطه معمول است. من
43
00:01:24,720 –> 00:01:26,000
از حداکثر اسکالر میانگین استفاده می کنم،
44
00:01:26,000 –> 00:01:27,840
بنابراین همه شما باید از مفهوم مقیاس بندی آگاه
45
00:01:27,840 –> 00:01:30,479
46
00:01:30,479 –> 00:01:32,240
47
00:01:32,240 –> 00:01:34,079
باشید. من از مقیاس در
48
00:01:34,079 –> 00:01:36,400
تجزیه pca pcs مخفف
49
00:01:36,400 –> 00:01:38,560
اصلی تجزیه و تحلیل مؤلفه است،
50
00:01:38,560 –> 00:01:41,439
بنابراین من می خواهم چندین
51
00:01:41,439 –> 00:01:43,680
مرحله پیش پردازش داده را روی داده های خود اجرا کنم،
52
00:01:43,680 –> 00:01:45,280
بنابراین من برخی از
53
00:01:45,280 –> 00:01:47,439
ماژول های پیش پردازش را وارد می کنم، بنابراین pci یکی از
54
00:01:47,439 –> 00:01:48,799
ماژول های پیش پردازش است.
55
00:01:48,799 –> 00:01:50,960
پس من این را وارد می کنم این یک
56
00:01:50,960 –> 00:01:52,399
بسته مهم است بچه ها
57
00:01:52,399 –> 00:01:54,880
از خط لوله واردات خط لوله sql dot بنابراین فقط
58
00:01:54,880 –> 00:01:56,799
با استفاده از این ماژول
59
00:01:56,799 –> 00:01:58,560
خط لوله من خط لوله خود را ایجاد می کنم به شما نشان خواهم داد که چگونه
60
00:01:58,560 –> 00:02:00,079
این کار را انجام خواهم داد
61
00:02:00,079 –> 00:02:01,920
و سپس سه مدل را که وارد می
62
00:02:01,920 –> 00:02:04,159
کنم تصمیم رگرسیون لجستیک را ببینید
63
00:02:04,159 –> 00:02:05,840
طبقهبندیکننده درختی و طبقهبندیکننده جنگل تصادفی
64
00:02:05,840 –> 00:02:07,360
خوب است،
65
00:02:07,360 –> 00:02:09,758
بنابراین من از این سه مدل استفاده خواهم کرد، حالا
66
00:02:09,758 –> 00:02:11,599
ببینیم در مرحله بعد چه کار میکنم،
67
00:02:11,599 –> 00:02:13,280
بنابراین من به اینجا میروم و
68
00:02:13,280 –> 00:02:15,360
بستهها و دادهها را وارد میکنم، بنابراین بستههایی که
69
00:02:15,360 –> 00:02:16,239
قبلا
70
00:02:16,239 –> 00:02:18,640
وارد کردهام، دادهها را وارد میکنم. من
71
00:02:18,640 –> 00:02:20,480
یک داده اولیه دیابت هندی بسیار ساده را قرار می دهم
72
00:02:20,480 –> 00:02:22,319
من قبلاً چند
73
00:02:22,319 –> 00:02:24,560
فیلم در مورد این داده ها تهیه کرده ام
74
00:02:24,560 –> 00:02:26,239
بنابراین می توانید مشاهده کنید که داده ها به این شکل هستند
75
00:02:26,239 –> 00:02:29,440
76
00:02:29,440 –> 00:02:31,840
77
00:02:31,840 –> 00:02:33,840
.
78
00:02:33,840 –> 00:02:35,840
سطح گلوکز فشار خون ضخامت پوست
79
00:02:35,840 –> 00:02:36,720
80
00:02:36,720 –> 00:02:39,599
و سپس ما یک کلاس متغیر هدف داریم
81
00:02:39,599 –> 00:02:40,400
که می گوید
82
00:02:40,400 –> 00:02:42,480
آیا یک فرد دیابت دارد یا
83
00:02:42,480 –> 00:02:44,160
دیابت ندارد،
84
00:02:44,160 –> 00:02:46,080
بنابراین این داده های ما است که در آن کلاس
85
00:02:46,080 –> 00:02:48,080
متغیر هدف ما است و
86
00:02:48,080 –> 00:02:51,120
کمتر متغیرهای مستقل ما را کاهش می
87
00:02:51,120 –> 00:02:53,120
دهد. در مرحله بعد این کار را انجام می دهم این است
88
00:02:53,120 –> 00:02:55,599
که من فقط قطار را جدا می کنم و خوب تست می کنم،
89
00:02:55,599 –> 00:02:57,200
بنابراین اکثر شما
90
00:02:57,200 –> 00:02:59,200
از هیچ چیز جالبی در اینجا آگاه نخواهید بود،
91
00:02:59,200 –> 00:03:01,680
من فقط هفت یا هشت
92
00:03:01,680 –> 00:03:02,319
ستون اول خود را در
93
00:03:02,319 –> 00:03:04,560
قطار می روم اوه ویژگی های مستقل و آخرین
94
00:03:04,560 –> 00:03:06,239
ستون ویژگی مستقل
95
00:03:06,239 –> 00:03:09,040
و تقسیم شدن به نسبت 80 20 خوب است، بنابراین
96
00:03:09,040 –> 00:03:11,040
آنچه که من خواهم داشت،
97
00:03:11,040 –> 00:03:13,760
آزمایش x و تست y باران سفید شدید خواهم داشت، بیایید به
98
00:03:13,760 –> 00:03:14,400
جلو برویم
99
00:03:14,400 –> 00:03:16,080
تا اینجا، روند بسیار معمولی بود
100
00:03:16,080 –> 00:03:18,080
که بعداً انجام
101
00:03:18,080 –> 00:03:20,480
خواهم داد. من خطوط لوله ایجاد خواهم کرد که منظور من
102
00:03:20,480 –> 00:03:22,239
از خطوط لوله در
103
00:03:22,239 –> 00:03:24,720
اینجا منظور من از خطوط لوله است.
104
00:03:24,720 –> 00:03:26,799
105
00:03:26,799 –> 00:03:28,720
106
00:03:28,720 –> 00:03:29,360
107
00:03:29,360 –> 00:03:31,280
108
00:03:31,280 –> 00:03:32,560
109
00:03:32,560 –> 00:03:34,799
110
00:03:34,799 –> 00:03:35,760
حلقه
111
00:03:35,760 –> 00:03:38,720
خوب است، بنابراین آنچه که همه این مراحل خط لوله
112
00:03:38,720 –> 00:03:39,840
شامل
113
00:03:39,840 –> 00:03:41,920
می شود شامل پیش پردازش داده ها با استفاده از
114
00:03:41,920 –> 00:03:43,519
میانگین حداکثر اسکالر است که من در
115
00:03:43,519 –> 00:03:44,239
آنجا وارد کرده ام
116
00:03:44,239 –> 00:03:46,959
، با استفاده از pca ابعاد را کاهش می دهیم و
117
00:03:46,959 –> 00:03:47,920
سپس از
118
00:03:47,920 –> 00:03:49,920
مدل های آموزشی مربوطه استفاده خواهیم کرد تا همانطور که
119
00:03:49,920 –> 00:03:51,440
در این صفحه می توانید
120
00:03:51,440 –> 00:03:53,120
این بخش از کد درست
121
00:03:53,120 –> 00:03:55,120
است بچه ها، بنابراین کاری که من اینجا انجام می دهم
122
00:03:55,120 –> 00:03:56,720
فقط با دقت ببینید
123
00:03:56,720 –> 00:03:59,360
خط لوله رگرسیون لجستیک برابر با
124
00:03:59,360 –> 00:04:00,080
خط لوله است،
125
00:04:00,080 –> 00:04:02,159
بنابراین این خط لوله چیست که اینجا می بینید p
126
00:04:02,159 –> 00:04:03,840
مقدار سرمایه خوب است،
127
00:04:03,840 –> 00:04:05,680
بنابراین این خط لوله است که من این
128
00:04:05,680 –> 00:04:07,680
ماژول را صدا می زنم خوب شما این ماژول را به یاد دارید که من
129
00:04:07,680 –> 00:04:08,879
وارد کردم،
130
00:04:08,879 –> 00:04:10,720
من وارد می کنم، من این ماژول را
131
00:04:10,720 –> 00:04:12,080
در اینجا فراخوانی می کنم و می
132
00:04:12,080 –> 00:04:16,079
گویم یک خط لوله از چه چیزی ایجاد کنید، بنابراین
133
00:04:16,079 –> 00:04:18,560
ابتدا یک حداقل مقیاس اسکالر را انجام دهید، بنابراین این
134
00:04:18,560 –> 00:04:20,639
اولین چیزی که باید برای
135
00:04:20,639 –> 00:04:23,360
دادههای من بیفتد، فقط کمی توجه کنید، دوستانی که
136
00:04:23,360 –> 00:04:24,800
در این خط لوله هستند
137
00:04:24,800 –> 00:04:26,800
، اولین چیزی که باید برای دادههای من اتفاق بیفتد این
138
00:04:26,800 –> 00:04:28,000
است
139
00:04:28,000 –> 00:04:30,080
که تابع حداکثر میانگین را روی تابع اسکالر حداکثر داده من اجرا کنم،
140
00:04:30,080 –> 00:04:31,360
141
00:04:31,360 –> 00:04:33,680
سپس یک کاما که مرحله بعدی باید باشد.
142
00:04:33,680 –> 00:04:34,560
143
00:04:34,560 –> 00:04:37,440
مرحله بعدی اجرای
144
00:04:37,440 –> 00:04:39,199
تجزیه و تحلیل مؤلفه اصلی بر روی دادههای من با تعداد
145
00:04:39,199 –> 00:04:40,880
مؤلفهها برابر با سه است.
146
00:04:40,880 –> 00:04:43,680
147
00:04:43,680 –> 00:04:45,199
148
00:04:45,199 –> 00:04:48,560
149
00:04:48,560 –> 00:04:50,560
150
00:04:50,560 –> 00:04:51,680
151
00:04:51,680 –> 00:04:54,560
شی رگرسیون لجستیک
152
00:04:54,560 –> 00:04:55,280
153
00:04:55,280 –> 00:04:58,240
درست کنید، بنابراین سه کاری که من انجام میدهم
154
00:04:58,240 –> 00:05:00,320
، پیشپردازش دادهها است
155
00:05:00,320 –> 00:05:02,400
و این فقط ایجاد
156
00:05:02,400 –> 00:05:03,680
شی مدل است،
157
00:05:03,680 –> 00:05:05,600
اکنون فقط باید آن را train meth بنامم. od
158
00:05:05,600 –> 00:05:07,919
و مدل را آموزش میدهد خوب
159
00:05:07,919 –> 00:05:10,400
همان کاری که من انجام میدهم اگر برای
160
00:05:10,400 –> 00:05:11,520
درخت تصمیمگیری ببینید
161
00:05:11,520 –> 00:05:13,600
و همان کاری که من انجام میدهم اگر
162
00:05:13,600 –> 00:05:14,800
چهار جنگل تصادفی را ببینید
163
00:05:14,800 –> 00:05:17,440
خوب است، من آنها را
164
00:05:17,440 –> 00:05:18,639
خطوط لوله مختلف
165
00:05:18,639 –> 00:05:20,800
میگویم رگرسیون لجستیکی خط لوله تصمیمگیری
166
00:05:20,800 –> 00:05:21,919
درخت خط لوله
167
00:05:21,919 –> 00:05:24,320
تصادفی خط لوله جنگل در حال حاضر من سه
168
00:05:24,320 –> 00:05:25,440
خط لوله
169
00:05:25,440 –> 00:05:27,840
دارم، بنابراین کاری که می توانم در اینجا انجام دهم این است که یا می توانم ادامه دهم
170
00:05:27,840 –> 00:05:28,639
171
00:05:28,639 –> 00:05:30,320
و این خط لوله رگرسیون لجستیک را
172
00:05:30,320 –> 00:05:32,000
جداگانه
173
00:05:32,000 –> 00:05:34,960
اجرا کنم یا می توانم هر سه خط لوله را در
174
00:05:34,960 –> 00:05:35,759
یک حلقه اجرا
175
00:05:35,759 –> 00:05:38,479
کنم، بسیار خوب، به شما نشان خواهم داد که چگونه همه
176
00:05:38,479 –> 00:05:40,160
اینها را در ی