در این مطلب، ویدئو راهنمای مصاحبه با Python Science Data Science با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:30:25
تصاویر این ویدئو:


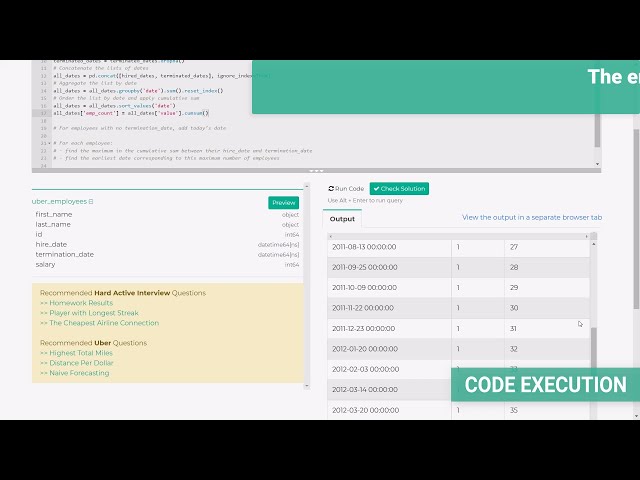
قسمتی از زیرنویس این فیلم:
00:00:03,679 –> 00:00:05,600
سلام من مت هستم من یک رهبر محتوای فنی
2
00:00:05,600 –> 00:00:07,600
در Stratoscratch هستم و امروز
3
00:00:07,600 –> 00:00:09,040
شما را از طریق یک سوال مصاحبه دیگر راهنمایی می کنم که
4
00:00:09,040 –> 00:00:11,120
این سوال در
5
00:00:11,120 –> 00:00:13,120
مصاحبه های علم داده در uber پرسیده شده است.
6
00:00:13,120 –> 00:00:15,040
7
00:00:15,040 –> 00:00:16,560
8
00:00:16,560 –> 00:00:18,480
کارمندان در بازههای زمانی معین،
9
00:00:18,480 –> 00:00:19,520
10
00:00:19,520 –> 00:00:21,279
طبق معمول، این
11
00:00:21,279 –> 00:00:23,439
سوال را با استفاده از پایتون حل میکنم، گویی که در حال
12
00:00:23,439 –> 00:00:25,199
مصاحبه هستیم، به شما نکاتی را در مورد
13
00:00:25,199 –> 00:00:27,199
نحوه نزدیک شدن به آن و نحوه
14
00:00:27,199 –> 00:00:29,199
برقراری ارتباط مؤثر با مصاحبهگر خود ارائه میدهم،
15
00:00:29,199 –> 00:00:31,279
اجازه دهید وارد آن شویم اما قبل از آن، اگر
16
00:00:31,279 –> 00:00:33,120
هنوز این کار را انجام نداده اید، لطفاً در کانال ما مشترک شوید تا
17
00:00:33,120 –> 00:00:34,960
18
00:00:34,960 –> 00:00:37,300
از آخرین سوالات مصاحبه مطلع شوید
19
00:00:37,300 –> 00:00:42,559
[موسیقی
20
00:00:42,559 –> 00:00:44,480
] عنوان این سوال
21
00:00:44,480 –> 00:00:46,800
حداکثر تعداد کارمندان است و از
22
00:00:46,800 –> 00:00:48,559
ما خواسته می شود که درخواستی بنویسیم که
23
00:00:48,559 –> 00:00:50,559
برمی گردد. هر کارمندی که تا به
24
00:00:50,559 –> 00:00:52,960
حال برای شرکت کار کرده است، سپس برای هر
25
00:00:52,960 –> 00:00:54,800
کارمند باید
26
00:00:54,800 –> 00:00:56,879
بیشترین تعداد کارمندانی را که در
27
00:00:56,879 –> 00:00:59,280
طول مدت تصدی آنها برای شرکت کار کرده اند
28
00:00:59,280 –> 00:01:01,440
و همچنین اولین تاریخی که تعداد
29
00:01:01,440 –> 00:01:02,480
رخ
30
00:01:02,480 –> 00:01:04,640
داده تصمیم گرفته می شود که تاریخ پایان کار
31
00:01:04,640 –> 00:01:06,880
یک کارمند نباید به عنوان
32
00:01:06,880 –> 00:01:10,000
یک روز کاری حساب شود و علاوه بر این، خروجی
33
00:01:10,000 –> 00:01:12,400
باید شامل شناسه کارمند
34
00:01:12,400 –> 00:01:14,080
بیشترین تعداد کارمندانی باشد که
35
00:01:14,080 –> 00:01:16,080
در طول مدت تصدی این کارمند در شرکت کار کرده اند
36
00:01:16,080 –> 00:01:17,040
37
00:01:17,040 –> 00:01:19,520
و اولین تاریخی که
38
00:01:19,520 –> 00:01:20,560
39
00:01:20,560 –> 00:01:22,320
این یک سوال سخت است زیرا
40
00:01:22,320 –> 00:01:24,640
شامل دستکاری تاریخ ها و در
41
00:01:24,640 –> 00:01:26,720
اصل بررسی چگونگی تغییر تعداد
42
00:01:26,720 –> 00:01:29,040
کارمندان در زمان
43
00:01:29,040 –> 00:01:30,640
برای تلاش برای حل این
44
00:01:30,640 –> 00:01:32,400
سوال مصاحبه است، من به
45
00:01:32,400 –> 00:01:34,079
چارچوب کلی برای حل
46
00:01:34,079 –> 00:01:35,920
مسائل علم داده که ما می دانیم پایبند می مانم. معمولاً از
47
00:01:35,920 –> 00:01:38,479
این کانال استفاده می کنیم، ایده این است که ابتدا
48
00:01:38,479 –> 00:01:40,880
داده ها را درک کنیم، سپس
49
00:01:40,880 –> 00:01:42,880
با نوشتن چند مرحله کلی
50
00:01:42,880 –> 00:01:44,960
که می تواند ما را به یک راه حل هدایت کند، رویکرد را فرموله کنیم و
51
00:01:44,960 –> 00:01:47,280
در نهایت کد را بر اساس این
52
00:01:47,280 –> 00:01:48,880
رویکرد سطح بالا بنویسیم،
53
00:01:48,880 –> 00:01:50,720
بنابراین بیایید با نگاه کردن به داده ها شروع
54
00:01:50,720 –> 00:01:52,320
کنیم. برای این سوال مصاحبه ارائه شده است که
55
00:01:52,320 –> 00:01:54,320
معمولاً در مصاحبه به شما
56
00:01:54,320 –> 00:01:56,719
سوابق واقعی داده نمی شود، اما در
57
00:01:56,719 –> 00:01:58,960
عوض w را خواهید دید جداول کلاه یا
58
00:01:58,960 –> 00:02:00,640
فریم های داده وجود دارد و
59
00:02:00,640 –> 00:02:03,360
ستون ها و انواع داده ها در این جداول چیست،
60
00:02:03,360 –> 00:02:05,040
در این مورد ما فقط یک جدول
61
00:02:05,040 –> 00:02:07,200
به نام uberemployees داریم و به نظر می رسد
62
00:02:07,200 –> 00:02:09,840
نسبتاً ساده است نام جدول و همچنین
63
00:02:09,840 –> 00:02:11,360
نام ستون نشان می دهد که این یک
64
00:02:11,360 –> 00:02:13,840
لیست است. کارمندان برخی از شرکت ها و
65
00:02:13,840 –> 00:02:16,080
هر ردیف مربوط به یک کارمند است و
66
00:02:16,080 –> 00:02:18,080
برای هر یک از آنها
67
00:02:18,080 –> 00:02:21,040
نام خانوادگی و شناسه داده می شود که همانطور که
68
00:02:21,040 –> 00:02:22,959
می بینید یک عدد صحیح
69
00:02:22,959 –> 00:02:24,879
است همچنین تاریخ استخدام این
70
00:02:24,879 –> 00:02:26,560
کارمند و زمان قرارداد آنها وجود دارد.
71
00:02:26,560 –> 00:02:28,640
فسخ شد هم به دلیل
72
00:02:28,640 –> 00:02:30,800
نوع داده های تاریخ
73
00:02:30,800 –> 00:02:33,599
و هم حقوق کارمند را
74
00:02:33,599 –> 00:02:35,360
داریم یک چیز که ممکن است در
75
00:02:35,360 –> 00:02:36,959
ابتدا مشخص نباشد و در سوال مشخص نشده باشد این
76
00:02:36,959 –> 00:02:38,879
است که ارزش
77
00:02:38,879 –> 00:02:41,280
ستون تاریخ پایان خدمت برای کارکنانی
78
00:02:41,280 –> 00:02:43,280
که هنوز در شرکت کار می کنند چقدر است. خوب ما
79
00:02:43,280 –> 00:02:44,800
می توانیم در این مورد فرضی داشته باشیم به
80
00:02:44,800 –> 00:02:46,800
عنوان مثال در این موارد
81
00:02:46,800 –> 00:02:48,959
تاریخ خاتمه خالی است یا
82
00:02:48,959 –> 00:02:51,040
ارزشی نخواهد داشت و از آنجایی که هیچ توضیحی
83
00:02:51,040 –> 00:02:53,200
در مورد سوال ارائه نشده است، اجازه
84
00:02:53,200 –> 00:02:54,879
داریم چنین مفروضاتی را بسازید
85
00:02:54,879 –> 00:02:57,200
و
86
00:02:57,200 –> 00:02:58,879
تا زمانی که این
87
00:02:58,879 –> 00:03:00,959
مفروضات را به طور واضح به مصاحبه کننده منتقل کنیم
88
00:03:00,959 –> 00:03:02,560
و این اولین گام از تجزیه و تحلیل
89
00:03:02,560 –> 00:03:04,720
داده ها دقیقاً زمانی است که باید
90
00:03:04,720 –> 00:03:07,120
این فرضیات را بسازیم و به آنها انتقال دهیم
91
00:03:07,120 –> 00:03:09,200
، گام بعدی پس از بررسی داده
92
00:03:09,200 –> 00:03:11,200
ها، حل کنید. برای تدوین مراحل سطح بالا برای
93
00:03:11,200 –> 00:03:13,120
حل این سوال مصاحبه
94
00:03:13,120 –> 00:03:15,440
، هدف ما در اینجا این است
95
00:03:15,440 –> 00:03:17,920
که تاریخ های بالاتر و پایان کار را به
96
00:03:17,920 –> 00:03:20,239
لیست تعداد کل کارمندان در
97
00:03:20,239 –> 00:03:22,400
هر تاریخی که این تعداد تغییر می کند تبدیل کنیم و برای
98
00:03:22,400 –> 00:03:24,239
دستیابی به این اولین قدم ممکن است
99
00:03:24,239 –> 00:03:26,319
فهرست کردن تمام تاریخ ها از ستون تاریخ بالاتر
100
00:03:26,319 –> 00:03:28,959
و اضافه کردن یک ستون جدید به آن که در آن
101
00:03:28,959 –> 00:03:31,120
هر سطر دارای مقدار 1
102
00:03:31,120 –> 00:03:32,959
خواهد بود.
103
00:03:32,959 –> 00:03:35,040
104
00:03:35,040 –> 00:03:37,760
105
00:03:37,760 –> 00:03:40,080
می توانید کار مشابهی را برای
106
00:03:40,080 –> 00:03:42,159
ستون تاریخ خاتمه انجام دهید، بیایید
107
00:03:42,159 –> 00:03:43,519
تمام تاریخ های این ستون را فهرست
108
00:03:43,519 –> 00:03:45,840
کنیم و یک ستون جدید پر از مقادیر
109
00:03:45,840 –> 00:03:48,239
-1 و همان مقدار قبلی
110
00:03:48,239 –> 00:03:49,680
1 mea ایجاد کنیم. در صورتی که شرکت یک کارمند جدید دریافت کند،
111
00:03:49,680 –> 00:03:52,080
در این مورد در هر تاریخ
112
00:03:52,080 –> 00:03:54,080
که تاریخ خاتمه کارمندی است،
113
00:03:54,080 –> 00:03:56,879
شرکت در حال از دست دادن یک کارمند بعدی است،
114
00:03:56,879 –> 00:03:59,120
میتوانیم این دو لیست را با هم ادغام
115
00:03:59,120 –> 00:04:00,959
کنیم، به عبارت دیگر، لیست تاریخهای بالاتر را میگیریم و لیستی را
116
00:04:00,959 –> 00:04:02,959
اضافه میکنیم.
117
00:04:02,959 –> 00:04:04,959
تاریخ های پایان کار در پایان
118
00:04:04,959 –> 00:04:07,439
در این تاریخ، فهرست بلندبالایی از تاریخ ها را به دست می آوریم که
119
00:04:07,439 –> 00:04:09,439
هر کدام از آنها ارزش دارد یا
120
00:04:09,439 –> 00:04:11,760
یک کارمند جدید دریافت می کند یا منهای
121
00:04:11,760 –> 00:04:13,599
یک کارمند از دست می دهد و به عنوان چهارمین
122
00:04:13,599 –> 00:04:16,560
مرحله
123
00:04:16,560 –> 00:04:18,880
، لیستی را که به دست آورده ایم را جمع یا گروه بندی می کنیم. تاریخ در حالی که
124
00:04:18,880 –> 00:04:22,320
همه مقادیر یک یا منهای یک را جمع می
125
00:04:22,320 –> 00:04:24,080
کنیم این کار را انجام می دهیم زیرا ممکن
126
00:04:24,080 –> 00:04:26,000
است چندین کارمند در همان تاریخ استخدام شده باشند
127
00:04:26,000 –> 00:04:27,919
یا شاید روزی برخی از
128
00:04:27,919 –> 00:04:29,600
کارمندان استخدام شده باشند و برخی از آنها
129
00:04:29,600 –> 00:04:32,479
قراردادشان فسخ شده است، بنابراین هدف در اینجا این
130
00:04:32,479 –> 00:04:34,479
است که یک تاریخ داشته باشیم. و مقداری را
131
00:04:34,479 –> 00:04:36,000
نشان می دهد که تعداد
132
00:04:36,000 –> 00:04:38,240
کارمندان در روز چقدر تغییر کرده است، بنابراین این
133
00:04:38,240 –> 00:04:40,160
عدد می تواند مثبت باشد اگر کارمندان بیشتری
134
00:04:40,160 –> 00:04:42,560
استخدام شوند در صورت فسخ قراردادهای بیشتر منفی
135
00:04:42,560 –> 00:04:44,560
یا حتی اگر شرکت صفر شود.
136
00:04:44,560 –> 00:04:47,199
همین تعداد کارمند را گرفتیم و از دست
137
00:04:47,199 –> 00:04:49,680
دادیم و با داشتن این لیست، میتوانیم
138
00:04:49,680 –> 00:04:52,000
مجموع جمعی را محاسبه کنیم تا
139
00:04:52,000 –> 00:04:54,320
تعداد کل کارمندان را در هر
140
00:04:54,320 –> 00:04:56,479
نقطه از زمان دقیقاً همان چیزی که به دنبال آن هستیم به دست آوریم،
141
00:04:56,479 –> 00:04:58,080
اما قبل از انجام این کار بسیار مهم است
142
00:04:58,080 –> 00:05:00,400
که ما را مرتب کنیم. فهرستی از قدیمیترین تا
143
00:05:00,400 –> 00:05:03,039
آخرین تاریخها برای اینکه این جامعه از
144
00:05:03,039 –> 00:05:05,120
مجموع واقعاً منطقی باشد و اکنون که
145
00:05:05,120 –> 00:05:06,800
ما این مرور کلی از نحوه تغییر تعداد
146
00:05:06,800 –> 00:05:09,199
کارمندان داریم، تا
147
00:05:09,199 –> 00:05:11,039
حل سؤال مصاحبه چندان دور نیست،
148
00:05:11,039 –> 00:05:12,880
اما قبل از اینکه بتوانیم پاسخ نهایی را ایجاد
149
00:05:12,880 –> 00:05:14,479
کنیم، هنوز یک مشکل کوچک برای
150
00:05:14,479 –> 00:05:15,440
حل
151
00:05:15,440 –> 00:05:17,840
برخی از کارکنان، آنهایی که امروز هنوز
152
00:05:17,840 –> 00:05:19,919
در شرکت کار می کنند، هیچ
153
00:05:19,919 –> 00:05:22,479
ارزشی در ستون تاریخ خاتمه ندارند، بنابراین
154
00:05:22,479 –> 00:05:24,720
برای سهولت در عملیات بعدی
155
00:05:24,720 –> 00:05:27,039
می توانیم این مقدار جدید یا این
156
00:05:27,039 –> 00:05:28,000
فضای خالی را
157
00:05:28,000 –> 00:05:30,160
با تاریخ امروز جایگزین کنیم
158
00:05:30,160 –> 00:05:32,160
و مرحله بعدی جایی است که ما واقعاً
159
00:05:32,160 –> 00:05:34,160
سؤال مصاحبه را حل می کنیم، می توانیم
160
00:05:34,160 –> 00:05:37,440
از لیست تاریخ ها و مجموع تجمعی
161
00:05:37,440 –> 00:05:38,560
که در اختیار داریم استفاده کنیم
162
00:05:38,560 –> 00:05:41,440
و برای هر کارمند می
163
00:05:41,440 –> 00:05:43,199
توانیم بیشترین تعداد کارمندان را پیدا کنیم.
164
00:05:43,199 –> 00:05:44,960
یا بالاترین مقدار در این
165
00:05:44,960 –> 00:05:48,160
مجموع تجمعی بین تاریخ بالاتر
166
00:05:48,160 –> 00:05:50,080
و تاریخ پایان کار
167
00:05:50,080 –> 00:05:53,199
و در همان زمان میتوانیم اولین
168
00:05:53,199 –> 00:05:55,199
تاریخی را پیدا کنیم که این بیشترین تعداد
169
00:05:55,199 –> 00:05:57,440
کارمند رخ داده است و از
170
00:05:57,440 –> 00:05:58,960
آنجایی که ممکن است تعداد کارمندان یکسان
171
00:05:58,960 –> 00:06:00,639
چندین بار در طول یک
172
00:06:00,639 –> 00:06:02,720
کارمند اتفاق افتاده باشد. در زمان تصدی، یافتن اولین تاریخ بسیار مهم است
173
00:06:02,720 –> 00:06:04,560
، زیرا این
174
00:06:04,560 –> 00:06:07,360
همان چیزی است که سؤال میپرسد
175
00:06:07,360 –> 00:06:09,520
و پس از این مرحله، ما از
176
00:06:09,520 –> 00:06:11,520
قبل راهحل تکلیف مصاحبه را داریم،
177
00:06:11,520 –> 00:06:13,919
بنابراین گام نهایی تنظیم
178
00:06:13,919 –> 00:06:16,000
خروجی با آنچه در سؤال مشخص شده است،
179
00:06:16,000 –> 00:06:19,759
خواهد بود. خروجی شناسه کارمند
180
00:06:19,759 –> 00:06:20,400
181
00:06:20,400 –> 00:06:21,840
مربوطه بیشترین تعداد
182
00:06:21,840 –> 00:06:22,960
کارمند
183
00:06:22,960 –> 00:06:24,800
و اولین تاریخی که به این تعداد
184
00:06:24,800 –> 00:06:26,639
رسیده است با تعریف مراحل عمومی و
185
00:06:26,639 –> 00:06:28,639
سطح بالا، اکنون می توانیم از آنها برای
186
00:06:28,639 –> 00:06:30,479
نوشتن کد برای حل این
187
00:06:30,479 –> 00:06:32,479
سوال مصاحبه از uber استفاده کنیم همانطور که می بینید من
188
00:06:32,479 –> 00:06:34,560
قبلاً وارد شده ام. برخی از کتابخانههای پایتون
189
00:06:34,560 –> 00:06:36,160
که من از این کد استفاده خواهم کرد،
190
00:06:36,160 –> 00:06:38,319
مهمترین آنها پاندا نام دارد و
191
00:06:38,319 –> 00:06:40,800
این کتابخانه برای دستکاری da است. ta و
192
00:06:40,800 –> 00:06:42,720
اجازه می دهد تا عملیات مختلفی را بر روی
193
00:06:42,720 –> 00:06:45,840
جداول داده انجام دهیم شبیه به استفاده از sql و
194
00:06:45,840 –> 00:06:48,080
کتابخانه دیگری به نام date time
195
00:06:48,080 –> 00:06:50,400
و زمانی که به تاریخ امروز نیاز داشته باشیم از آن استفاده خواهم کرد
196
00:06:50,400 –> 00:06:52,240
و اولین قدم فهرست کردن تمام
197
00:06:52,240 –> 00:06:54,960
تاریخ های بالاتر و اضافه کردن یک ستون با مقدار است.
198
00:06:54,960 –> 00:06:56,960
یکی از این رو فهرست کردن تاریخ ها به
199
00:06:56,960 –> 00:06:58,639
خصوص دشوار نیست زیرا این تاریخ ها
200
00:06:58,639 –> 00:07:01,680
از قبل در جدول اصلی وجود دارند،
201
00:07:01,680 –> 00:07:03,440
بنابراین ما می توانیم فقط تاریخ ستون بالاتر
202
00:07:03,440 –> 00:07:05,919
را از این جدول اصلی
203
00:07:05,919 –> 00:07:07,039
204
00:07:07,039 –> 00:07:09,199
205
00:07:09,199 –> 00:07:10,080
206
00:07:10,080 –> 00:07:12,720
برداریم.
207
00:07:12,720 –> 00:07:15,840
و سپس اضافه کردن یک ستون جدید
208
00:07:15,840 –> 00:07:17,840
پر از ستونها نیز کاملاً
209
00:07:17,840 –> 00:07:20,080
ساده است، فقط میتوانیم بگوییم که در
210
00:07:20,080 –> 00:07:22,240
این قاب داده جدید با تاریخهای بالاتر
211
00:07:22,240 –> 00:07:24,000
میخواهیم یک ستون جدید ایجاد کنیم، بگذارید آن را
212
00:07:24,000 –> 00:07:26,240
مقدار بنامیم و کافی است بگوییم که این
213
00:07:26,240 –> 00:07:28,800
ستون باید برابر با یک باشد
214
00:07:28,800 –> 00:07:31,440
و اکنون همانطور که پیشنمایش این را
215
00:07:31,440 –> 00:07:33,360
میکنیم، میبینیم که
216
00:07:33,360 –> 00:07:36,400
ما این تاریخهای بالاتر را داریم و هر کدام
217
00:07:36,400 –> 00:07:38,240
با مقدار یک، به این معنی است که در
218
00:07:38,240 –> 00:07:40,160
این تاریخها، این تاریخها چند کارمند
219
00:07:40,160 –> 00:07:43,199
بالاتر هستند، یک کارمند جدید دریافت میکنیم و مشاهده میکنیم.
220
00:07:43,199 –> 00:07:45,520
ممکن است همان تاریخ
221
00:07:45,520 –> 00:07:47,680
در چندین ردیف ظاهر شود، اما میتوانیم
222
00:07:47,680 –> 00:07:49,520
آن را به این شکل رها کنیم، فعلاً
223
00:07:49,520 –> 00:07:50,960
224
00:07:50,960 –> 00:07:53,280
225
00:07:53,280 –> 00:07:55,919
226
00:07:55,919 –> 00:07:58,560
227
00:07:58,560 –> 00:08:00,960
مشکلی نیست و مرحله دوم فهرست کردن تمام تاریخهای خاتمه و اضافه کردن ستون با مقدار -1 است، بنابراین این کار را میتوان در یک in انجام داد.
228
00:08:00,960 –> 00:08:02,560
تقریباً به روش
229
00:08:02,560 –> 00:08:05,680
قبلی، بنابراین با گرفتن ستون این
230
00:08:05,680 –> 00:08:07,599
تاریخ پایان زمان از فریم داده اصلی
231
00:08:07,599 –> 00:08:09,599
ایجاد یک قاب داده جدید، اجازه دهید
232
00:08:09,599 –> 00:08:12,560
آن را تاریخ های پایان یافته بنامیم و سپس با افزودن
233
00:08:12,560 –> 00:08:14,720
یک ستون جدید به نام مقدار، این بار
234
00:08:14,720 –> 00:08:17,120
مقدار -1 خواهد بود،
235
00:08:17,120 –> 00:08:19,680
بنابراین برای پیش نمایش
236
00:08:19,680 –> 00:08:22,000
باز هم نتایج مشابه
237
00:08:22,000 –> 00:08:24,080
مورد قبلی را داریم اما همانطور که می بینید
238
00:08:24,080 –> 00:08:27,520
تعداد زیادی ردیف بدون تاریخ وجود دارد و
239
00:08:27,520 –> 00:08:29,919
این به این دلیل است که همه کارمندان
240
00:08:29,919 –> 00:08:31,520
241
00:08:31,520 –> 00:08:33,760
اگر امروز هنوز برای شرکت کار می کنند تاریخ خاتمه ندارند
242
00:08:33,760 –> 00:08:36,559
بنابراین برای تمیز کردن آن کمی ما می توانید از یک
243
00:08:36,559 –> 00:08:37,679
244
00:08:37,679 –> 00:08:38,880
تابع
245
00:08:38,880 –> 00:08:40,559
pandas استفاده کنید که a
246
00:08:40,559 –> 00:08:42,559
مانند این
247
00:08:42,559 –> 00:08:45,920
و این افت در a و a مخفف مقادیر null است،
248
00:08:45,920 –> 00:08:47,200
249
00:08:47,200 –> 00:08:49,279
بنابراین اساساً از شر تمام
250
00:08:49,279 –> 00:08:53,200
این فضاهای خالی در این جدول خلاص می شود،
251
00:08:53,200 –> 00:08:55,839
بنابراین بسیار بهتر به نظر می رسد و بسیار
252
00:08:55,839 –> 00:08:57,839
شبیه به مورد قبلی است. ه ach
253
00:08:57,839 –> 00:09:00,399
row دوباره به این معنی است که در یک تاریخ مشخص شرکت یک کارمند خود را
254
00:09:00,399 –> 00:09:02,640
از دست می دهد
255
00:09:02,640 –> 00:09:04,880
و دوباره این تاریخ ها ممکن
256
00:09:04,880 –> 00:09:07,920
است تکراری شوند اما فعلاً خوب است
257
00:09:07,920 –> 00:09:10,080
و ما بعداً به آن رسیدگی خواهیم کرد و
258
00:09:10,080 –> 00:09:12,560
فعلاً بیایید به مرحله سوم برویم
259
00:09:12,560 –> 00:09:14,720
که به هم پیوستن است. فهرست
260
00:09:14,720 –> 00:09:17,040
تاریخها، بنابراین آنچه میخواهیم به دست آوریم، یک
261
00:09:17,040 –> 00:09:19,120
لیست واحد با تمام تاریخها در یک
262
00:09:19,120 –> 00:09:22,000
ستون و مقادیر 1 یا -1
263
00:09:22,000 –> 00:09:23,920
در ستون دوم است،
264
00:09:23,920 –> 00:09:26,240
به عبارت دیگر، قاب دادههای تاریخ بالاتر را در نظر بگیریم و
265
00:09:26,240 –> 00:09:28,320
266
00:09:28,320 –> 00:09:30,560
تاریخ پایان یافته را بچسبانیم. قاب داده dates
267
00:09:30,560 –> 00:09:33,200
در پایین آن قرار دارد و برای رسیدن به
268
00:09:33,200 –> 00:09:36,160
این هدف می توانیم از تابع concat pandas به
269
00:09:36,160 –> 00:09:37,920
270
00:09:37,920 –> 00:09:39,760
این صورت استفاده کنیم
271
00:09:39,760 –> 00:09:42,880
و من گفتم که هر چه تاریخ ها
272
00:09:42,880 –> 00:09:43,839
و
273
00:09:43,839 –> 00:09:46,320
تاریخ های خاتمه بالاتر باشد باید به
274
00:09:46,320 –> 00:09:47,600
هم متصل شوند
275
00:09:47,600 –> 00:09:49,839
و پارامتر ignore index
276
00:09:49,839 –> 00:09:51,600
درست است این پارامتر به پانداها می گوید که
277
00:09:51,600 –> 00:09:53,600
دوباره تنظیم شوند. شاخص در قاب داده به دست آمده،
278
00:09:53,600 –> 00:09:54,720
279
00:09:54,720 –> 00:09:56,160
زیرا بدون
280
00:09:56,160 –> 00:09:58,480
آن، اولین سطر از
281
00:09:58,480 –> 00:09:59,360
282
00:09:59,360 –> 00:10:02,000
قاب داده های تاریخ بالاتر، همچنان دارای اندیس صفر خواهد بود،
283
00:10:02,000 –> 00:10:03,920
اما اولین ردیف تاریخ های خاتمه یافته
284
00:10:03,920 –> 00:10:06,880
نیز همان شاخص z را دارند. بنابراین
285
00:10:06,880 –> 00:10:08,720
اگر ایندکس را نادیده بگیریم یا ایندکس را بازنشانی کنیم،
286
00:10:08,720 –> 00:10:09,920
287
00:10:09,920 –> 00:10:12,800
هر سطر دوباره یک نمایه منحصربفرد جدید دریافت میکند،
288
00:10:12,800 –> 00:10:13,920
289
00:10:13,920 –> 00:10:15,920
در این صورت تغییر زیادی نمیکند، اما
290
00:10:15,920 –> 00:10:18,079
تمرین خوب است که این شاخص نادیده گرفته شده
291
00:10:18,079 –> 00:10:21,680
را در چنین شرایطی روی true تنظیم کنیم و
292
00:10:21,680 –> 00:10:24,800
اجازه دهید این فهرست پیوسته جدید را بنامیم.
293
00:10:24,800 –> 00:10:26,320
همه تاریخ ها
294
00:10:26,320 –> 00:10:29,040
و نگاه کردن به این چاه مشکلی وجود دارد
295
00:10:29,040 –> 00:10:30,079
296
00:10:30,079 –> 00:10:32,000
زیرا ما می خواستیم همه تاریخ ها
297
00:10:32,000 –> 00:10:35,000
در یک ستون باشند اما در عوض پانداها
298
00:10:35,000 –> 00:10:38,800
ستون مقدار را برای ما به هم متصل کردند
299
00:10:38,800 –> 00:10:41,360
اما تاریخ ها و تاریخ های بالاتر و
300
00:10:41,360 –> 00:10:43,519
تاریخ های پایان هنوز در دو
301
00:10:43,519 –> 00:10:45,839
ستون جداگانه هستند. و این به این دلیل است که
302
00:10:45,839 –> 00:10:47,680
303
00:10:47,680 –> 00:10:50,560
نام ستون مقدار در هر دو قاب
304
00:10:50,560 –> 00:10:53,279
داده های تاریخ بالاتر و تاریخ پایان یکسان بود،
305
00:10:53,279 –> 00:10:55,440
بنابراین انتخاب واضحی برای
306
00:10:55,440 –> 00:10:58,079
پانداها بود که این ستون را به یک ستون متصل کنند،
307
00:10:58,079 –> 00:10:59,680
اما در همان زمان ستون های دارای
308
00:10:59,680 –> 00:11:03,360
تاریخ نام های مختلفی داشتند تا رفع شود. با این کار
309
00:11:03,360 –> 00:11:05,600
میتوانیم نام این ستونها را
310
00:11:05,600 –> 00:11:07,680
به سادگی به عنوان مثال تاریخ تغییر دهیم، اما باید
311
00:11:07,680 –> 00:11:09,760
این کار را در
312
00:11:09,760 –> 00:11:11,440
هنگام ایجاد قاب داده جدید در اینجا انجام
313
00:11:11,440 –> 00:11:14,480
دهیم، بنابراین بیایید فقط از یک تابع به نام تغییر نام استفاده
314
00:11:14,480 –> 00:11:17,040
کنیم. دوباره یک pa است. تابع ndas برای
315
00:11:17,040 –> 00:11:19,279
تغییر نام اینها به جای گفتن
316
00:11:19,279 –> 00:11:21,519
تاریخ سلسله مراتبی ستون،
317
00:11:21,519 –> 00:11:23,680
نام را به تاریخ تغییر میدهم
318
00:11:23,680 –> 00:11:27,760
و در اینجا یکسان میشود و اکنون قالب این
319
00:11:27,760 –> 00:11:29,760
جدول بسیار بهتر به نظر میرسد و خیلی بیشتر به همان شکلی که
320
00:11:29,760 –> 00:11:30,959
میخواهیم باشد.
321
00:11:30,959 –> 00:11:34,000
یک لیست طولانی داشته باشید
322
00:11:34,000 –> 00:11:36,640
اول همه مقادیر یک بار و سپس
323
00:11:36,640 –> 00:11:39,600
مقادیر منهای یک برای تاریخ های مختلف، بنابراین
324
00:11:39,600 –> 00:11:41,600
وقت آن است که به مرحله بعدی بروید
325
00:11:41,600 –> 00:11:44,079
و مرحله بعدی این است که
326
00:11:44,079 –> 00:11:48,160
لیست را بر اساس تاریخ جمع آوری کنید.
327
00:11:48,160 –> 00:11:51,200
گروه با
328
00:11:51,200 –> 00:11:52,800
تابع
329
00:11:52,800 –> 00:11:54,880
مانند این گروه توسط
330
00:11:54,880 –> 00:11:57,519
و گفتن اینکه باید بر اساس ستون تاریخ گروه بندی
331
00:11:57,519 –> 00:12:00,079
کنیم تا این یک ستونی که
332
00:12:00,079 –> 00:12:01,920
از بین این دو ایجاد
333
00:12:01,920 –> 00:12:03,920
کرده ایم دو مجموعه داده را به هم متصل کنیم
334
00:12:03,920 –> 00:12:06,639
و علاوه بر اینکه فقط جمع می کنیم
335
00:12:06,639 –> 00:12:08,720
باید تابع تجمیع را نیز مشخص کنیم
336
00:12:08,720 –> 00:12:10,959
که باید برای
337
00:12:10,959 –> 00:12:13,200
مقادیر دیگر در این جدول در مورد ما اعمال شود، ما می
338
00:12:13,200 –> 00:12:14,959
خواهیم ببینیم که چگونه تعداد کارمندان
339
00:12:14,959 –> 00:12:17,200
در هر تاریخ تغییر کرده است،
340
00:12:17,200 –> 00:12:18,720
با توجه به اینکه ممکن است تعدادی از
341
00:12:18,720 –> 00:12:21,040
کارمندان استخدام شده باشند و برخی دیگر خاتمه یافته باشند
342
00:12:21,040 –> 00:12:23,040
، بنابراین عملکرد کمک خواهد کرد. ما به
343
00:12:23,040 –> 00:12:26,160
این نتیجه می رسیم که تابع جمع برای
344
00:12:26,160 –> 00:12:27,680
جمع بندی خواهد بود زیرا می
345
00:12:27,680 –> 00:12:30,720
خواهیم تمام مقادیر 1 و 1 را برای
346
00:12:30,720 –> 00:12:33,920
این تاریخ با هم جمع کنیم و اکنون
347
00:12:33,920 –> 00:12:35,839
همانطور که می بینیم
348
00:12:35,839 –> 00:12:38,399
ستون دارای تاریخ ناپدید شده است
349
00:12:38,399 –> 00:12:40,560
زیرا در واقع به یک شاخص از
350
00:12:40,560 –> 00:12:41,360
این
351
00:12:41,360 –> 00:12:42,639
جدول جدید
352
00:12:42,639 –> 00:12:45,040
و این شاخص تبدیل شده است. در حال حاضر به ما نشان داده نمیشود،
353
00:12:45,040 –> 00:12:47,120
بنابراین برای تغییر این مورد و همچنان قادر
354
00:12:47,120 –> 00:12:49,279
به دسترسی آسان به تاریخها،
355
00:12:49,279 –> 00:12:53,760
میتوانیم یک تابع فهرست بازنشانی pandas اضافه
356
00:12:53,760 –> 00:12:55,680
کنیم و به طور مشابه با
357
00:12:55,680 –> 00:12:57,600
پارامتر ignore index که قبلاً در اینجا دیدیم کار میکند،
358
00:12:57,600 –> 00:12:59,360
اکنون استفاده از آن بسیار
359
00:12:59,360 –> 00:13:01,440
مهمتر است. بنابراین به
360
00:13:01,440 –> 00:13:03,920
طور کلی هنگام جمع آوری یا استفاده از این
361
00:13:03,920 –> 00:13:06,399
گروه بر اساس تابع در پانداها، تمرین خوبی
362
00:13:06,399 –> 00:13:08,880
است که همیشه تابع فهرست بازنشانی
363
00:13:08,880 –> 00:13:09,839
364
00:13:09,839 –> 00:13:12,639
را در نتیجه اعمال کنید و با نگاه کردن به نتایج،
365
00:13:12,639 –> 00:13:14,880
می بینیم که دیگر
366
00:13:14,880 –> 00:13:16,399
تکراری
367
00:13:16,399 –> 00:13:17,600
در تاریخ ها وجود ندارد
368
00:13:17,600 –> 00:13:20,160
و در عوض این مقادیر وجود دارد. نشان دهنده
369
00:13:20,160 –> 00:13:23,120
تغییر تعداد کارمندان در هر
370
00:13:23,120 –> 00:13:25,920
تاریخ است، به عنوان مثال در سوم
371
00:13:25,920 –> 00:13:28,800
فوریه 2009، شرکت چهار کارمند دیگر داشت
372
00:13:28,800 –> 00:13:32,240
و در 15 آوریل
373
00:13:32,240 –> 00:13:34,480
یک کارمند بیشتر از یک روز
374
00:13:34,480 –> 00:13:36,959
ب. پیش از این و به عنوان مثال در
375
00:13:36,959 –> 00:13:38,560
20
376
00:13:38,560 –> 00:13:41,519
ژوئیه 2013، این عدد صفر است، زیرا
377
00:13:41,519 –> 00:13:43,440
همان تعداد کارمند استخدام شده و
378
00:13:43,440 –> 00:13:46,079
خاتمه یافته است، بنابراین تغییر صفر است و
379
00:13:46,079 –> 00:13:48,720
گاهی اوقات اگر
380
00:13:48,720 –> 00:13:51,199
قراردادهای بیشتری از کارمندان جدید فسخ شده
381
00:13:51,199 –> 00:13:54,079
382
00:13:54,079 –> 00:13:56,800
و به سمت دیگر حرکت کنند، می تواند منفی باشد. مرحله بعدی
383
00:13:56,800 –> 00:13:59,279
که مرتب کردن لیست بر اساس تاریخ و
384
00:13:59,279 –> 00:14:02,320
اعمال این مجموع تجمعی است، بنابراین ترتیب دادن
385
00:14:02,320 –> 00:14:04,800
نسبتاً ساده است زیرا میتوانیم از تابع
386
00:14:04,800 –> 00:14:06,240
387
00:14:06,240 –> 00:14:08,240
مقادیر مرتبسازی pandas استفاده
388
00:14:08,240 –> 00:14:11,120
کنیم و دوباره ستونی را مشخص کنیم
389
00:14:11,120 –> 00:14:13,360
که مقدار باید بر اساس آن مرتب شود
390
00:14:13,360 –> 00:14:14,880
و جالب اینجاست که این تابع
391
00:14:14,880 –> 00:14:16,720
منبع خواهد شد. مقادیر به
392
00:14:16,720 –> 00:14:18,240
ترتیب صعودی بنابراین از
393
00:14:18,240 –> 00:14:21,680
قدیمی ترین تا آخرین تاریخ ها به طور پیش فرض، بنابراین
394
00:14:21,680 –> 00:14:23,440
نیازی به اضافه کردن هیچ پارامتر دیگری نیست
395
00:14:23,440 –> 00:14:25,839
396
00:14:25,839 –> 00:14:28,480
و این مرتب می شود
397
00:14:28,480 –> 00:14:30,480
و سپس محاسبه مجموع تجمعی
398
00:14:30,480 –> 00:14:32,639
نیز نسبتاً ساده است،
399
00:14:32,639 –> 00:14:35,120
زیرا دوباره یک تابع pandas وجود دارد
400
00:14:35,120 –> 00:14:38,320
که می تواند این کار را انجام دهد. برای
401
00:14:38,320 –> 00:14:40,560
ما فقط باید آن را به
402
00:14:40,560 –> 00:14:43,440
ستون مقدار این قاب داده قدیمی اعمال کنیم
403
00:14:43,440 –> 00:14:46,079
و تابع را c