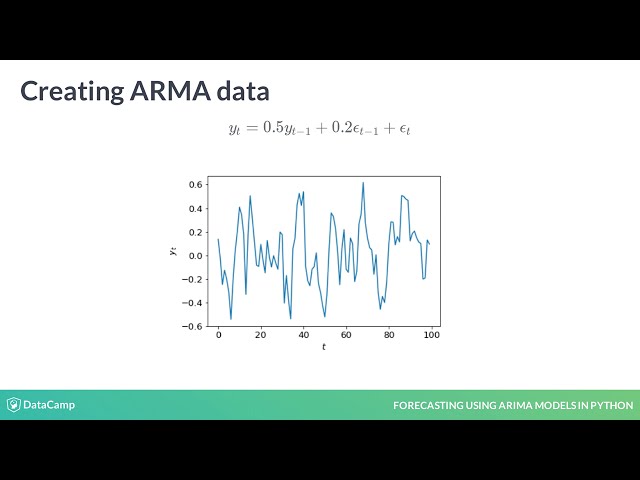
در این مطلب، ویدئو مقدمه ای بر کار با پایگاه های داده در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:53:17
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:05,170 –> 00:00:08,210
خیلی خب، فکر میکنم این بار ما در حال پخش زنده هستیم،
2
00:00:08,210 –> 00:00:10,930
3
00:00:18,220 –> 00:00:21,220
واقعاً ممنون بچهها، بنابراین معلوم شد که
4
00:00:21,220 –> 00:00:23,720
در یوتیوب دکمهای وجود دارد که
5
00:00:23,720 –> 00:00:25,700
برای پخش زنده باید آن را فشار دهید و من فراموش کردم
6
00:00:25,700 –> 00:00:26,660
آن را فشار دهم، بنابراین بله
7
00:00:26,660 –> 00:00:30,250
، ما هستیم، بنابراین این چیزی است که این اتفاق افتاد
8
00:00:30,250 –> 00:00:32,840
و از این رو متشکرم بچه ها برای تنظیم
9
00:00:32,840 –> 00:00:34,040
کردن و ما فقط
10
00:00:34,040 –> 00:00:36,140
چند دقیقه زودتر در آنجا با خودم صحبت
11
00:00:36,140 –> 00:00:38,629
می کنیم، اما از شما برای
12
00:00:38,629 –> 00:00:41,230
پیوستن متشکرم، ممنون که به اینجا آمدید، می دانم که
13
00:00:41,230 –> 00:00:43,760
در اینجا مناطق زمانی مختلفی وجود دارد
14
00:00:43,760 –> 00:00:45,230
که شما بچه ها در آنجا هستند، بنابراین می دانم که
15
00:00:45,230 –> 00:00:47,089
برای شما می تواند زود باشد یا گاهی اوقات برای شما دیر است،
16
00:00:47,089 –> 00:00:49,640
اما من از آن سپاسگزارم، من سعی می کنم
17
00:00:49,640 –> 00:00:52,790
منطقه زمانی را انتخاب کنم که برای افراد زیادی مناسب
18
00:00:52,790 –> 00:00:55,460
19
00:00:55,460 –> 00:00:58,519
20
00:00:58,519 –> 00:01:01,790
باشد. بسیار خوب، پس واقعاً از شما متشکریم که
21
00:01:01,790 –> 00:01:03,350
امروز به آن ملحق شدید، ما قصد داریم
22
00:01:03,350 –> 00:01:07,090
یک برنامه پایتون بسازیم که از یک پایگاه داده استفاده می کند و
23
00:01:07,090 –> 00:01:09,500
24
00:01:09,500 –> 00:01:13,070
از طریق ساختن آن در مورد عاقبت آن یاد می گیریم و سپس
25
00:01:13,070 –> 00:01:14,630
به ساختن چند
26
00:01:14,630 –> 00:01:16,130
نمودار و نمودار نیز می پردازیم. نمودارها با استفاده از matplotlib
27
00:01:16,130 –> 00:01:17,780
که در پایان یک چیز اضافی
28
00:01:17,780 –> 00:01:19,909
خواهد بود و بنابراین به منظور پوشش دادن به این موضوع که
29
00:01:19,909 –> 00:01:21,950
ممکن است از مرز ساعت عبور کنیم، به خصوص
30
00:01:21,950 –> 00:01:23,270
با این مشکلات فنی
31
00:01:23,270 –> 00:01:26,780
که داریم، اما امیدوارم که شما دوستان
32
00:01:26,780 –> 00:01:30,409
از جلسه لذت ببرید، اگر
33
00:01:30,409 –> 00:01:32,180
سؤالی دارید، راحت باشید. برای استفاده از چت وقتی
34
00:01:32,180 –> 00:01:33,229
به این سمت نگاه میکنم، این
35
00:01:33,229 –> 00:01:35,659
من هستم که چت را میخوانم و بنابراین
36
00:01:35,659 –> 00:01:36,979
همه چیز را میخوانم، یکسان است، اما
37
00:01:36,979 –> 00:01:38,659
گاهی اوقات نمیتوانم به همه پاسخ
38
00:01:38,659 –> 00:01:40,729
دهم، اما من واقعاً از شما دوستانی که
39
00:01:40,729 –> 00:01:43,159
آنجا چت میکنید و
40
00:01:43,159 –> 00:01:46,549
سؤالی میپرسید سپاسگزارم. شما
41
00:01:46,549 –> 00:01:48,530
قبل از شروع چند چیز دارید، ما یک
42
00:01:48,530 –> 00:01:50,060
حساب توییتر داریم که در
43
00:01:50,060 –> 00:01:52,759
توضیحات ویدیو پیوند داده شده است، بنابراین اگر می خواهید
44
00:01:52,759 –> 00:01:53,570
من را در توییتر دنبال
45
00:01:53,570 –> 00:01:55,850
کنید عالی خواهند بود و سپس به
46
00:01:55,850 –> 00:01:57,920
روز رسانی های بیشتری دریافت خواهید کرد و شما اطلاعات داخلی
47
00:01:57,920 –> 00:02:00,140
و مواردی از این قبیل را میدانید و
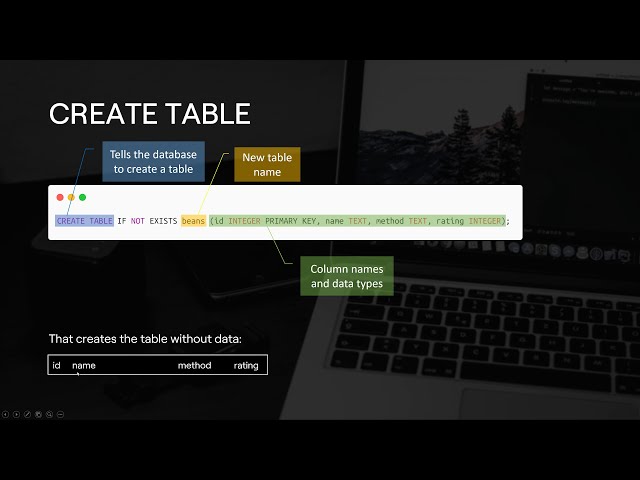
48
00:02:00,140 –> 00:02:01,909
ما همچنین یک دیسک یا کانالی داریم که در آن
49
00:02:01,909 –> 00:02:03,630
50
00:02:03,630 –> 00:02:06,070
[موسیقی]
51
00:02:06,070 –> 00:02:09,508
و این کانال اصلی را داریم
52
00:02:09,508 –> 00:02:12,250
که میدانیم در مورد Python به یکدیگر کمک میکنیم
53
00:02:12,250 –> 00:02:14,980
و غیره صحبت میکنیم تا بتوانید به آنجا بپیوندید.
54
00:02:14,980 –> 00:02:16,150
همچنین لینک آن نیز در
55
00:02:16,150 –> 00:02:22,209
توضیحات موجود است در زیر بسیار خوب، اجازه دهید
56
00:02:22,209 –> 00:02:24,550
شروع کنند، سپس ما
57
00:02:24,550 –> 00:02:28,180
ابتدا یک پرایمر سریع در مورد دنباله انجام می
58
00:02:28,180 –> 00:02:29,860
دهیم، بنابراین من به شما کمی در مورد دنباله چیزهایی
59
00:02:29,860 –> 00:02:31,600
که برای ساختن برنامه ای که
60
00:02:31,600 –> 00:02:33,520
می خواهیم بسازیم به شما آموزش می دهم و سپس ما
61
00:02:33,520 –> 00:02:35,110
همزمان با برنامه و استفاده از
62
00:02:35,110 –> 00:02:39,310
دنباله شروع می کنیم و بنابراین یک
63
00:02:39,310 –> 00:02:41,290
سوال خوب از بارنی که
64
00:02:41,290 –> 00:02:42,820
پس زمینه مورد انتظار شما چیست که باید کمی
65
00:02:42,820 –> 00:02:45,940
در مورد Python برای این جلسه بدانید، بنابراین
66
00:02:45,940 –> 00:02:46,989
اگر کاملا مبتدی هستید این
67
00:02:46,989 –> 00:02:49,570
برای شما نیست و اما اگر کمی در پایتون کدنویسی کرده
68
00:02:49,570 –> 00:02:51,160
اید، شاید
69
00:02:51,160 –> 00:02:52,480
چند بخش از
70
00:02:52,480 –> 00:02:54,220
دوره کامل پایتون ما یا چیزی مشابه را انجام داده باشید،
71
00:02:54,220 –> 00:02:56,020
می دانید که توابع چیست و
72
00:02:56,020 –> 00:02:58,630
می توانید کمی با پایتون کار کنید.
73
00:02:58,630 –> 00:03:00,310
پس همین کافی است
74
00:03:00,310 –> 00:03:01,360
75
00:03:01,360 –> 00:03:02,739
که در این جلسه از برنامه نویسی شی گرا یا هر چیزی شبیه به آن استفاده
76
00:03:02,739 –> 00:03:10,480
نخواهیم کرد، بسیار خوب است، بنابراین اجازه دهید
77
00:03:10,480 –> 00:03:13,530
همینطور که به نوعی به آن نیاز داریم
78
00:03:13,530 –> 00:03:22,480
شروع کنم و اجازه دهید با این شروع کنیم، بنابراین اجازه
79
00:03:22,480 –> 00:03:25,510
دهید فقط این را نشان دهم خیلی سریع من نمی
80
00:03:25,510 –> 00:03:28,950
دانم چرا اینجا آنجاست ما
81
00:03:30,640 –> 00:03:33,410
میرویم امیدوارم شما بچهها بتوانید این را ببینید و
82
00:03:33,410 –> 00:03:35,720
این یک ارائه سریع
83
00:03:35,720 –> 00:03:40,010
در مورد دنبالهها فقط نکات اصلی خواهد بود و به
84
00:03:40,010 –> 00:03:42,470
این ترتیب میتوانید بدانید که
85
00:03:42,470 –> 00:03:46,640
در برنامهنویسی پایتون در دنباله اصلی آن،
86
00:03:46,640 –> 00:03:49,310
زبانی است که برای تعامل با
87
00:03:49,310 –> 00:03:51,200
پایگاههای داده استفاده میشود. بنابراین ما به
88
00:03:51,200 –> 00:03:53,300
پایگاه داده ای نیاز داریم که پایگاه داده ای که
89
00:03:53,300 –> 00:03:55,430
در این پروژه از آن استفاده می کنیم، به نام
90
00:03:55,430 –> 00:03:58,580
Sequel Lite است و
91
00:03:58,580 –> 00:04:01,070
یک پایگاه داده کاملاً کاربردی است، اما
92
00:04:01,070 –> 00:04:04,220
نسخه ای ساده از یک سیستم پایگاه داده
93
00:04:04,220 –> 00:04:06,020
کامل است که برخی از سیستم های پایگاه داده تمام عیار ممکن است
94
00:04:06,020 –> 00:04:07,970
می دانم دنباله من هستند به عنوان مثال یا
95
00:04:07,970 –> 00:04:10,160
دنباله Postgres Lite مانند یک نسخه Lite است
96
00:04:10,160 –> 00:04:13,550
که بسیار سریع قابل استفاده است، اما
97
00:04:13,550 –> 00:04:15,980
دارای چند محدودیت است که
98
00:04:15,980 –> 00:04:19,488
پایگاه داده های اصلی آن از جداول تشکیل شده است،
99
00:04:19,488 –> 00:04:21,709
بنابراین چیزی که ما در این پروژه خواهیم ساخت
100
00:04:21,709 –> 00:04:24,740
برنامه
101
00:04:24,740 –> 00:04:28,430
قهوه ما دانههای قهوه را
102
00:04:28,430 –> 00:04:30,440
پیگیری میکنیم، روشی را که
103
00:04:30,440 –> 00:04:32,150
قهوه را با دستگاه پرکولاتور با
104
00:04:32,150 –> 00:04:34,880
دستگاه اسپرسوساز یا فیلتر و غیره درست
105
00:04:34,880 –> 00:04:36,290
کردهایم پیگیری میکنیم و سپس به آنها رتبهبندی میدهیم و به آنها نشان میدهیم.
106
00:04:36,290 –> 00:04:39,260
می دانید که آیا ما یک
107
00:04:39,260 –> 00:04:41,690
دانه خاص را دوست داشتیم که با روش خاصی تهیه
108
00:04:41,690 –> 00:04:43,730
شده باشد یا خیر، برای مثال در اینجا در این
109
00:04:43,730 –> 00:04:46,700
جدول نمونه، این دانه عربیکای فوق العاده را
110
00:04:46,700 –> 00:04:48,500
داریم که با دستگاه اسپرسوساز درست
111
00:04:48,500 –> 00:04:50,600
کردیم و به آن 90 از 100 دادیم
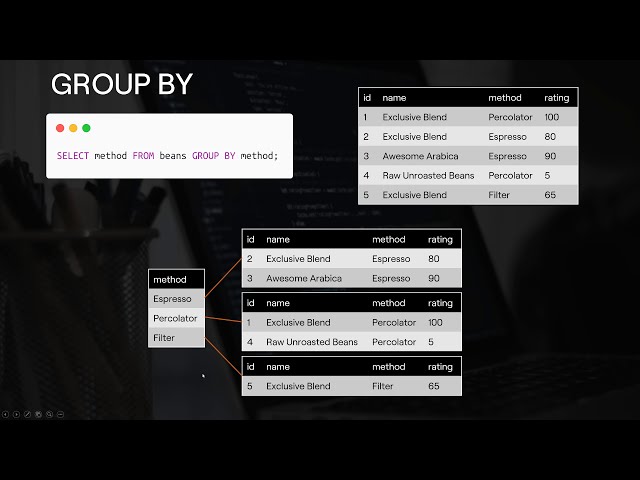
112
00:04:50,600 –> 00:04:54,710
و به همین ترتیب مخلوط انحصاری لوبیا
113
00:04:54,710 –> 00:04:55,940
114
00:04:55,940 –> 00:04:57,860
را با یک فیلتر آماده کردیم و به
115
00:04:57,860 –> 00:05:00,800
آن امتیاز 65 از 100 دادیم، بنابراین آنچه که در اینجا
116
00:05:00,800 –> 00:05:03,170
داریم اساساً لوبیاهایی است که
117
00:05:03,170 –> 00:05:05,210
خریداری کرده ایم و چگونه آنها را آماده می کنیم و
118
00:05:05,210 –> 00:05:06,950
بعداً چقدر آنها را دوست داریم. ما میتوانیم از
119
00:05:06,950 –> 00:05:08,740
این دادهها برای تصمیمگیری آگاهانهتر برای
120
00:05:08,740 –> 00:05:11,570
خرید استفاده کنیم و وقتی در
121
00:05:11,570 –> 00:05:14,180
حال مرور آمازون هستیم و بنابراین آنچه
122
00:05:14,180 –> 00:05:17,210
در جدول داریم اول از همه نام ستونها است،
123
00:05:17,210 –> 00:05:19,400
بنابراین هر ستون در یک جدول یک نام دارد در
124
00:05:19,400 –> 00:05:22,910
این مورد نام نام است. و اما این
125
00:05:22,910 –> 00:05:25,100
نام ستون ها روش است این نام ستون
126
00:05:25,100 –> 00:05:28,180
ها رتبه بندی نام این ستون ها ID است
127
00:05:28,180 –> 00:05:30,790
و جداول از ستون ها و همچنین از ردیف ها تشکیل شده است
128
00:05:30,790 –> 00:05:34,610
بنابراین هر ردیف از داده ها
129
00:05:34,610 –> 00:05:38,090
اساساً یک دانه در این جدول است و
130
00:05:38,090 –> 00:05:39,980
حاوی اطلاعاتی در مورد شناسه دانه ها است.
131
00:05:39,980 –> 00:05:42,860
لوبیاها روش
132
00:05:42,860 –> 00:05:43,760
133
00:05:43,760 –> 00:05:45,590
ترمیم دانهها و رتبهبندی را که به آن دادهایم
134
00:05:45,590 –> 00:05:48,200
و همچنین ردیفها و ستونها را نام ببرید،
135
00:05:48,200 –> 00:05:50,330
ترکیب یا تقاطع هر دو
136
00:05:50,330 –> 00:05:52,700
یک سلول است، بنابراین هیچ چیز جدیدی در اینجا وجود ندارد، شما
137
00:05:52,700 –> 00:05:54,680
احتمالاً میدانید که جدول چیست و اما میدانید که یک جدول چیست.
138
00:05:54,680 –> 00:05:58,010
پس بیایید
139
00:05:58,010 –> 00:05:59,750
نگاهی بیندازیم که چگونه
140
00:05:59,750 –> 00:06:03,290
میتوانیم این جدول را با استفاده از sequel ایجاد کنیم و بنابراین
141
00:06:03,290 –> 00:06:05,960
از یک پرس و جو مانند این برای ایجاد جدول پرتوهای خود استفاده میکنیم
142
00:06:05,960 –> 00:06:09,380
و اگر این کوئری را اجرا کنیم و
143
00:06:09,380 –> 00:06:10,670
من به شما نشان میدهم که کجا آن را اجرا کنید و چگونه
144
00:06:10,670 –> 00:06:12,050
آن را در یک لحظه اجرا کنیم، زمانی که ما
145
00:06:12,050 –> 00:06:13,550
شروع به کدنویسی می کنیم،
146
00:06:13,550 –> 00:06:15,500
جدولی مانند این بدون داده ایجاد می شود، بنابراین
147
00:06:15,500 –> 00:06:18,140
شما ستون ها را در آنجا تعریف کرده اید اما
148
00:06:18,140 –> 00:06:20,240
داده ای در جدول وجود ندارد و اجازه دهید از طریق
149
00:06:20,240 –> 00:06:22,220
این پرس و جو به نحوه ساخت آن
150
00:06:22,220 –> 00:06:24,530
بپردازیم قسمت اول ایجاد جدول
151
00:06:24,530 –> 00:06:25,790
چیزی است که در ابتدا قرار
152
00:06:25,790 –> 00:06:27,200
می دهیم و به پایگاه داده می گوید که می خواهیم
153
00:06:27,200 –> 00:06:30,710
یک جدول بسازیم و سپس
154
00:06:30,710 –> 00:06:33,410
نام جدول را دریافت می کنیم.
155
00:06:33,410 –> 00:06:35,840
برای لحظه ای از روی if not exists رد می شوم زیرا
156
00:06:35,840 –> 00:06:37,550
اختیاری است بنابراین ما داریم یک جدول بسازید و
157
00:06:37,550 –> 00:06:39,260
سپس نام جدول را بسازید و آن gon است
158
00:06:39,260 –> 00:06:41,300
na یک جدول جدید در پایگاه داده خود با
159
00:06:41,300 –> 00:06:42,890
آن نام ایجاد می کنیم و در نهایت در پایان
160
00:06:42,890 –> 00:06:46,310
نام ستون ها و انواع داده ها را داریم، بنابراین
161
00:06:46,310 –> 00:06:47,960
در اینجا می توانید ببینید که ما با کاما از
162
00:06:47,960 –> 00:06:51,050
هم جدا شده ایم و تکه هایی از متن را
163
00:06:51,050 –> 00:06:52,730
وارد می کنم. در یک لحظه هستند
164
00:06:52,730 –> 00:06:54,620
اما اساساً چهار بیت جدا شده با کاما وجود دارد که شناسه روش و رتبهبندی آنها با کاما از هم جدا شدهاند
165
00:06:54,620 –> 00:06:57,410
و
166
00:06:57,410 –> 00:06:59,330
به همین دلیل است که در نهایت به چهار ستون میرسیم که
167
00:06:59,330 –> 00:07:01,760
این بیت در اینجا ضروری است تا
168
00:07:01,760 –> 00:07:04,190
در صورت تلاش برای
169
00:07:04,190 –> 00:07:06,710
ایجاد جدولی که از قبل وجود دارد، پایگاه داده خراب نشود.
170
00:07:06,710 –> 00:07:08,750
ایجاد جدول در صورتی که وجود ندارد برای
171
00:07:08,750 –> 00:07:11,480
جلوگیری از آن خطا استفاده میشود، خوب اجازه دهید
172
00:07:11,480 –> 00:07:14,420
وارد انواع دادهها شویم و ستونها از عدد
173
00:07:14,420 –> 00:07:16,760
صحیح استفاده میکنند تا تعریف کنیم که ستون
174
00:07:16,760 –> 00:07:19,340
فقط حاوی ردیفهایی باشد که سلولها
175
00:07:19,340 –> 00:07:23,300
اعداد کامل هستند و متن اساساً برای
176
00:07:23,300 –> 00:07:24,890
هر چیز دیگری است، بنابراین تعداد کاراکترها
177
00:07:24,890 –> 00:07:28,040
نمادها و غیره هر چیزی که می خواهید
178
00:07:28,040 –> 00:07:30,470
کلید اصلی در اینجا
179
00:07:30,470 –> 00:07:34,130
معنای ویژه ای دارد و ما به این می پردازیم که تمام
180
00:07:34,130 –> 00:07:36,350
این معنی چیست و چگونه در دوره پایتون و Postgres ما استفاده می شود،
181
00:07:36,350 –> 00:07:38,630
اما
182
00:07:38,630 –> 00:07:40,370
اساساً کاری که در دنباله Lite انجام
183
00:07:40,370 –> 00:07:42,170
می دهد این است که w را می سازد تعداد سوراخ به
184
00:07:42,170 –> 00:07:45,080
طور خودکار افزایش می یابد بنابراین هر زمان که یک ردیف جدید
185
00:07:45,080 –> 00:07:48,260
را در این جدول وارد می کنیم، ستون ID
186
00:07:48,260 –> 00:07:50,930
یک ردیف بیشتر از ردیف قبلی دریافت می کند،
187
00:07:50,930 –> 00:07:54,440
بنابراین اگر یک پرتو با شناسه یک
188
00:07:54,440 –> 00:07:56,300
دارید و سعی می کنید یک ردیف جدید وارد کنید،
189
00:07:56,300 –> 00:07:57,420
شناسه دو می شود.
190
00:07:57,420 –> 00:08:00,870
افزایش خودکار به چه معناست، بنابراین این
191
00:08:00,870 –> 00:08:03,510
یک آغازگر سریع در جدول ایجاد است و اکنون
192
00:08:03,510 –> 00:08:05,370
ما در حال بررسی نحوه درج داده ها
193
00:08:05,370 –> 00:08:08,070
در پایگاه داده یا در آن جدول
194
00:08:08,070 –> 00:08:10,650
هستیم که واقعاً می توانیم این کار را مانند این درج
195
00:08:10,650 –> 00:08:13,260
در beans و نام جدول انجام دهیم
196
00:08:13,260 –> 00:08:16,110
و سپس ما مقادیر را ذخیره کنید و در داخل
197
00:08:16,110 –> 00:08:18,300
پرانتز یک مقدار برای هر
198
00:08:18,300 –> 00:08:20,640
ستون قرار می دهیم، بنابراین در اینجا
199
00:08:20,640 –> 00:08:23,370
عدد 1 را در ترکیب انحصاری ستون ID به
200
00:08:23,370 –> 00:08:25,440
عنوان یک رشته با
201
00:08:25,440 –> 00:08:28,170
علامت های نقل قول تکی به عنوان نام پرکولاتور bean
202
00:08:28,170 –> 00:08:29,280
203
00:08:29,280 –> 00:08:31,380
دوباره به عنوان یک رشته با علامت نقل قول وارد
204
00:08:31,380 –> 00:08:34,289
می کنیم. در روش 65 در رتبه بندی، بنابراین
205
00:08:34,289 –> 00:08:35,940
در اینجا ما این دانه ترکیبی منحصر به فرد را می خریدیم
206
00:08:35,940 –> 00:08:37,770
که آن را با آبکش درست
207
00:08:37,770 –> 00:08:39,900
کردیم و به آن نمره 65 یا 100 دادیم زیرا
208
00:08:39,900 –> 00:08:43,200
خیلی خوب نبود اما شناسه به طور خودکار
209
00:08:43,200 –> 00:08:44,820
افزایش می یابد همانطور که فقط یک تعریف کردیم. لحظه
210
00:08:44,820 –> 00:08:46,260
پیش پس ما در واقع نیازی نیست
211
00:08:46,260 –> 00:08:48,390
که مقداری را به این بفرستیم، کاری که میتوانیم انجام دهیم این
212
00:08:48,390 –> 00:08:50,580
است که میتوانیم بگوییم در beans قرار دهید و سپس
213
00:08:50,580 –> 00:08:51,870
در داخل براکتها میتوانیم در
214
00:08:51,870 –> 00:08:54,960
ستونهایی قرار دهیم که میخواهیم دادهها را برای آن اضافه کنیم،
215
00:08:54,960 –> 00:08:57,000
بنابراین ستون نام، ستون روش
216
00:08:57,000 –> 00:08:58,950
و ستون رتبهبندی و سپس بعد از
217
00:08:58,950 –> 00:09:00,780
مقادیر، ما به سادگی مقادیری را برای آنها ارسال
218
00:09:00,780 –> 00:09:03,600
میکنیم و به خاطر میآوریم که این مورد را در اینجا نداریم،
219
00:09:03,600 –> 00:09:04,770
زیرا دیگر لازم نیست
220
00:09:04,770 –> 00:09:06,570
که به طور
221
00:09:06,570 –> 00:09:10,530
خودکار توسط پایگاه داده تولید شود، بنابراین به
222
00:09:10,530 –> 00:09:12,090
سرعت به اینجا میرویم و فقط یک یک ساعت
223
00:09:12,090 –> 00:09:14,370
یا بیشتر اینجا چیز بعدی است که
224
00:09:14,370 –> 00:09:15,870
داده ها را از پایگاه داده انتخاب می کنیم یا آنها را
225
00:09:15,870 –> 00:09:18,510
بازیابی می کنیم یا داده هایی را در هسته آن پیدا
226
00:09:18,510 –> 00:09:20,700
227
00:09:20,700 –> 00:09:24,330
228
00:09:24,330 –> 00:09:26,940
می کنیم.
229
00:09:26,940 –> 00:09:29,310
ستاره به معنای همه ستونها است، بنابراین اگر
230
00:09:29,310 –> 00:09:31,920
ما این را در پایگاه داده آزمایشی خود در اینجا اجرا کنیم،
231
00:09:31,920 –> 00:09:33,840
همه ستونها و
232
00:09:33,840 –> 00:09:36,750
همه ردیفها را برمیگردانیم، اما ستاره در اینجا فقط
233
00:09:36,750 –> 00:09:38,730
به معنای تمام ستونها است، بنابراین
234
00:09:38,730 –> 00:09:41,730
به جای ستاره، روش نام شناسه و رتبهبندی را دریافت میکنیم.
235
00:09:41,730 –> 00:09:43,770
می توانیم پاس کنیم s در نام ستون های خاص
236
00:09:43,770 –> 00:09:45,810
مانند روش نام و رتبه بندی و
237
00:09:45,810 –> 00:09:48,000
سپس اگر ما به آن علاقه مندیم ستون ID را برنمی گردانیم
238
00:09:48,000 –> 00:09:50,760
، همچنین می توانیم
239
00:09:50,760 –> 00:09:52,890
خروجی را مرتب کنیم زیرا در اینجا می توانید ببینید
240
00:09:52,890 –> 00:09:55,470
که این موجودات بر اساس ترتیب مرتب
241
00:09:55,470 –> 00:09:58,350
شده اند. ما آنها را
242
00:09:58,350 –> 00:09:59,700
به پایگاه داده وارد کردیم که خیلی
243
00:09:59,700 –> 00:10:01,410
مفید نیست، بنابراین کاری که میتوانیم انجام دهیم این است
244
00:10:01,410 –> 00:10:03,900
که میتوانیم آنها را بر اساس رتبهبندی مرتب کنیم، بنابراین اکنون
245
00:10:03,900 –> 00:10:04,950
کاری که میخواهم انجام دهم این است که
246
00:10:04,950 –> 00:10:09,000
91 را میگذارم و سپس 85 75 65 را دنبال میکنم و 5
247
00:10:09,000 –> 00:10:10,050
در انتها ما آنها را با
248
00:10:10,050 –> 00:10:11,270
رتبه بندی در
249
00:10:11,270 –> 00:10:13,580
ترتیب ارسال مرتب می کنیم، بنابراین این کاری است که در اینجا انجام می دهیم
250
00:10:13,580 –> 00:10:16,820
، ستون ها را از ترتیب جدول
251
00:10:16,820 –> 00:10:18,890
بر اساس ستونی که می خواهیم مرتب کنیم و
252
00:10:18,890 –> 00:10:22,160
سپس ESC را برای ترتیب نزولی انتخاب می کنیم و
253
00:10:22,160 –> 00:10:23,480
بالاترین را قرار می دهد. آنهایی که
254
00:10:23,480 –> 00:10:26,990
در بالا هستند و سپس ASC پایین می آیند برای
255
00:10:26,990 –> 00:10:29,030
صعود برعکس است و شما می توانید
256
00:10:29,030 –> 00:10:31,180
از آن برای حرکت برعکس استفاده کنید
257
00:10:31,180 –> 00:10:33,590
حالا بیایید یک چیز دیگر را امتحان کنیم که
258
00:10:33,590 –> 00:10:35,780
روش و درجه بندی را انتخاب می کنیم تا
259
00:10:35,780 –> 00:10:37,280
بدون نام پرتو فقط یک
260
00:10:37,280 –> 00:10:39,440
روش و رتبه بندی از جدول تیرها
261
00:10:39,440 –> 00:10:41,030
که ما می خواهیم یک مرتبه بر اساس رتبه بندی به
262
00:10:41,030 –> 00:10:42,890
ترتیب نزولی اما اکنون
263
00:10:42,890 –> 00:10:45,320
محدودیت یک را اضافه می کنیم و اضافه کردن آن در پایان
264
00:10:45,320 –> 00:10:47,740
به این معنی است که فقط یک ردیف به عقب برمی گردیم
265
00:10:47,740 –> 00:10:50,300
و آنچه در اینجا به ما می گوید این است که
266
00:10:50,300 –> 00:10:53,140
روشی که بهترین خروجی را
267
00:10:53,140 –> 00:10:55,880
بدون توجه به
268
00:10:55,880 –> 00:10:58,400
در این مورد beam یک دستگاه اسپرسوساز بود و بنابراین
269
00:10:58,400 –> 00:10:59,840
270
00:10:59,840 –> 00:11:02,350
اگر میخواهید ببینید کدام نوع
271
00:11:02,350 –> 00:11:04,490
روش بهترین خروجی را تولید میکند، این اطلاعات جالبی است و
272
00:11:04,490 –> 00:11:06,320
میتوانید پرس و جوی مانند این را اجرا کنید و به
273
00:11:06,320 –> 00:11:10,040
شما اجازه میدهد ببینید که خوب است.
274
00:11:10,040 –> 00:11:11,930
اطلاعات کمی در مورد سفارش و انتخاب در اینجا وجود دارد،
275
00:11:11,930 –> 00:11:14,090
امیدوارم برای شما خیلی سریع نباشد،
276
00:11:14,090 –> 00:11:15,890
اما ما باید
277
00:11:15,890 –> 00:11:17,420
سریع برویم، این را
278
00:11:17,420 –> 00:11:19,790
پس از بررسی کد پایتون
279
00:11:19,790 –> 00:11:21,770
280
00:11:21,770 –> 00:11:25,190
بازنویسی می کنیم. همه
281
00:11:25,190 –> 00:11:27,500
سطرهای پایگاه داده را می
282
00:11:27,500 –> 00:11:29,780
توانیم با عبارت Where اعمال کنیم، بنابراین در اینجا
283
00:11:29,780 –> 00:11:31,670
ما انتخاب ستاره از beans را انجام
284
00:11:31,670 –> 00:11:33,350
می دهیم که همه چیز را از دانه ها و جدول به ما می دهد،
285
00:11:33,350 –> 00:11:35,960
اما یک بند Where اضافه
286
00:11:35,960 –> 00:11:38,480
می کنیم و می گوییم جایی که نام برابر است و t. سپس
287
00:11:38,480 –> 00:11:41,300
مقدار خاصی را ارسال می کنیم که
288
00:11:41,300 –> 00:11:44,510
سلول های ستون نام باید دقیقاً با آن برابر باشند
289
00:11:44,510 –> 00:11:46,700
و این باعث می شود که bean
290
00:11:46,700 –> 00:11:48,800
با آن نام و همچنین هر
291
00:11:48,800 –> 00:11:50,600
ستون دیگر برگردانده شود زیرا ما ستاره ای را انتخاب
292
00:11:50,600 –> 00:11:53,990
می کنیم که همه ستون ها را به ما می دهد، بنابراین بیایید از
293
00:11:53,990 –> 00:11:55,010
آن استفاده کنیم. از همه چیزهایی که
294
00:11:55,010 –> 00:11:57,470
تا کنون برای ساختن یک
295
00:11:57,470 –> 00:11:59,750
جستجوی جالبتر یاد گرفتهایم، بیایید بگوییم
296
00:11:59,750 –> 00:12:01,880
که این دادههای آزمایشی را دریافت
297
00:12:01,880 –> 00:12:04,280
کردهایم، میتوانید ببینید که ما یک پرتو ترکیب انحصاری را در سه روش مختلف دریافت کردهایم،
298
00:12:04,280 –> 00:12:06,290
بنابراین ترکیب انحصاری
299
00:12:06,290 –> 00:12:07,910
با پرکولاتور با
300
00:12:07,910 –> 00:12:09,920
دستگاه اسپرسوساز و با یک فیلتر و آنها
301
00:12:09,920 –> 00:12:11,630
رتبه بندی های متفاوتی دارند و سپس
302
00:12:11,630 –> 00:12:13,160
ما چند دانه دیگر نیز در اینجا داریم و
303
00:12:13,160 –> 00:12:14,840
کاری که می خواهیم انجام دهیم این است که
304
00:12:14,840 –> 00:12:16,970
همه چیز را از بین دانه ها انتخاب می
305
00:12:16,970 –> 00:12:18,560
کنیم، اما فقط می خواهیم آن را بازیابی کنیم.
306
00:12:18,560 –> 00:12:21,590
ترکیب انحصاری این است که این سه
307
00:12:21,590 –> 00:12:24,520
ردیف یک دو و پنج سپس
308
00:12:24,520 –> 00:12:26,320
آنها را بر اساس رتبه بندی آنها مرتب می
309
00:12:26,320 –> 00:12:29,020
کنیم و خواهیم یافت که کدام روش برای این پرتو بهترین است،
310
00:12:29,020 –> 00:12:31,660
بنابراین کاری که می توانیم انجام دهیم این است که
311
00:12:31,660 –> 00:12:33,250
ستاره را از پرتوها انتخاب کنیم تا همه چیزهایی را
312
00:12:33,250 –> 00:12:35,350
که با آن فیلتر می کنیم به دست آوریم. یک جایی که کلاو
313
00:12:35,350 –> 00:12:37,810
با استفاده از نام تیرها، سپس
314
00:12:37,810 –> 00:12:39,550
بر اساس رتبهبندی به ترتیب نزولی ترتیب
315
00:12:39,550 –> 00:12:41,740
میدهیم و از حد یک استفاده میکنیم
316
00:12:41,740 –> 00:12:43,660
تا بهترین را بدست آوریم و در نهایت
317
00:12:43,660 –> 00:12:46,300
این خروجی را در اینجا برای پرتو ترکیبی انحصاری به ما میدهد
318
00:12:46,300 –> 00:12:49,350
، پرکولاتور بهترین روش
319
00:12:49,350 –> 00:12:52,840
بود. بنابراین در اینجا همه چیزهایی است که
320
00:12:52,840 –> 00:12:54,880
تا به حال یاد گرفته ایم،
321
00:12:54,880 –> 00:12:56,890
در این سخنرانی یک چیز دیگر در مورد عاقبت یاد خواهیم گرفت زیرا ما
322
00:12:56,890 –> 00:12:59,560
به آن نیاز داریم تا نمودارهای خود را بعداً ترسیم کنیم، بنابراین
323
00:12:59,560 –> 00:13:03,190
این گروه به بند است، فرض کنید
324
00:13:03,190 –> 00:13:04,570
که ما دوباره آن داده های آزمایشی را دریافت کرده ایم.
325
00:13:04,570 –> 00:13:07,000
دوباره همان مواد و سه دانه که
326
00:13:07,000 –> 00:13:09,340
یکسان هستند و اسپرسو
327
00:13:09,340 –> 00:13:11,290
و صافی پرکولاتور هستند و همچنین یک
328
00:13:11,290 –> 00:13:13,270
پرتو دیگر با استفاده از اسپرسو و یک پرتو دیگر
329
00:13:13,270 –> 00:13:15,490
با استفاده از دستگاه پرکولاتور داریم و حالا ما این
330
00:13:15,490 –> 00:13:17,770
کار را انجام می دهیم این است که فقط روش را انتخاب
331
00:13:17,770 –> 00:13:20,970
می کنیم. فقط این ستون در اینجا
332
00:13:20,970 –> 00:13:23,470
از استیبل پرتو و ما
333
00:13:23,470 –> 00:13:26,620
یک گروه را به روش اضافه می کنیم.
334
00:13:26,620 –> 00:13:28,720
کاری که قرار است انجام دهد این است که فقط ستون متد را به ما می دهد،
335
00:13:28,720 –> 00:13:30,310
اما
336
00:13:30,310 –> 00:13:32,590
چیزی پنهان در پشت صحنه اضافه می کند، بنابراین
337
00:13:32,590 –> 00:13:36,280
این چیزی است که ما انجام می دهیم. دریافت اما هر ردیف او re
338
00:13:36,280 –> 00:13:40,000
برای همان نوع در این ستون منحصر به فرد است،
339
00:13:40,000 –> 00:13:42,520
بنابراین می توانید ببینید که
340
00:13:42,520 –> 00:13:45,040
ما دو دانه داریم که از اسپرسو استفاده می کنند، اما
341
00:13:45,040 –> 00:13:47,530
به دلیل اینکه ما بر اساس روش گروه بندی کرده ایم، آنها
342
00:13:47,530 –> 00:13:52,300
در یک ردیف از خروجی فشرده می شوند، اما
343
00:13:52,300 –> 00:13:55,900
در پشت صحنه گروه هایی هستند که پنهان هستند.
344
00:13:55,900 –> 00:13:58,450
آن را بسازید یا اساساً چه
345
00:13:58,450 –> 00:14:02,350
چیزهایی از مکانیسم گروهبندی استفاده میکنند
346
00:14:02,350 –> 00:14:04,030
و در پشت صحنه پنهان شده و
347
00:14:04,030 –> 00:14:07,660
در خروجی در دسترس ما نیست، این
348
00:14:07,660 –> 00:14:10,990
مجموعه از گروهها است و برای
349
00:14:10,990 –> 00:14:12,670
پرکولاتور ما همان چیزهایی را داریم که
350
00:14:12,670 –> 00:14:14,440
دو دانه را داریم که از percolator و
351
00:14:14,440 –> 00:14:15,940
برای فیلتر ما یک لوبیا داریم
352
00:14:15,940 –> 00:14:19,810
که از فیلتر استفاده می کند، بنابراین همانطور که گفتم این
353
00:14:19,810 –> 00:14:22,060
موارد در اینجا همه این گروه ها
354
00:14:22,060 –> 00:14:24,550
پنهان هستند و تنها خروجی که
355
00:14:24,550 –> 00:14:27,190
از این پرس و جو به دست می آوریم این جدول در اینجا
356
00:14:27,190 –> 00:14:29,020
پرکولاتور یا فیلتر اسپرسو
357
00:14:29,020 –> 00:14:31,630
خیلی مفید نیست. اما وقتی این
358
00:14:31,630 –> 00:14:33,910
گروهها را در دسترس داریم، میتوانیم از
359
00:14:33,910 –> 00:14:35,400
چیزی به نام تابع تجمیع
360
00:14:35,400 –> 00:14:38,350
برای دسترسی به دادههای
361
00:14:38,350 –> 00:14:41,110
جمعآوری شده از این گروهها استفاده کنیم، بنابراین میتوانیم کاری انجام
362
00:14:41,110 –> 00:14:44,500
دهیم مانند انتخاب روش
363
00:14:44,500 –> 00:14:47,650
AVG برای رتبهبندی، این یک تابع است و کارهای بیشتری انجام میدهیم.
364
00:14:47,650 –> 00:14:49,720
در این دوره در مورد این موضوع، اما فقط
365
00:14:49,720 –> 00:14:52,900
یک اطلاعات سریع و کمی در اینجا
366
00:14:52,900 –> 00:14:54,970
میتوانیم AVG رتبهبندی را انجام دهیم و
367
00:14:54,970 –> 00:14:57,400
میانگین رتبهبندیها را
368
00:14:57,400 –> 00:15:00,370
در هر گروه محاسبه میکنیم و از آنجایی که ما
369
00:15:00,370 –> 00:15:02,620
گروه را با روش در اینجا دریافت کردهایم، بنابراین در پایان
370
00:15:02,620 –> 00:15:03,970
روز چیزی که به دست می آوریم چیزی شبیه به
371
00:15:03,970 –> 00:15:06,010
این روش است و برای هر روش
372
00:15:06,010 –> 00:15:09,580
میانگین امتیاز از تمام ردیف های فرعی
373
00:15:09,580 –> 00:15:12,700
که در گروه داریم، بنابراین اینها
374
00:15:12,700 –> 00:15:15,250
در اینجا AVG دیگری به نام
375
00:15:15,250 –> 00:15:17,290
sum وجود دارد و دیگری به نام count
376
00:15:17,290 –> 00:15:18,850
آنها جمع هستند. توابع و آنها
377
00:15:18,850 –> 00:15:21,190
به ما اجازه می دهند تا روی گروه هایی
378
00:15:21,190 –> 00:15:24,220
که معمولاً پنهان هستند کار کنیم، توجه داشته باشید که
379
00:15:24,220 –> 00:15:27,250
اگر نام کاما روش را برای مثال
380
00:15:27,250 –> 00:15:28,960
و بدون استفاده از یک تابع جمع
381
00:15:28,960 –> 00:15:31,420
از جدول پرتوهای گروه بندی شده بر اساس متد انتخاب
382
00:15:31,420 –> 00:15:33,670
کنید، سعی می کنید روش
383
00:15:33,670 –> 00:15:36,670
و همچنین نام را انتخاب کنید. اما می بینید
384
00:15:36,670 –> 00:15:41,470
که نام اساساً منحصر به فرد نیست
385
00:15:41,470 –> 00:15:44,290
و دو نام مختلف در
386
00:15:44,290 –> 00:15:46,180
زیرگروه وجود دارد، بنابراین اگر می خواهید روش را انتخاب کنید
387
00:15:46,180 –> 00:15:48,670
و دنباله نام نمی داند
388
00:15:48,670 –> 00:15:51,400
چه نامی برای شما بگذارد زیرا این دو
389
00:15:51,400 –> 00:15:54,010
یک در پشت صحنه پنهان می شویم، به
390
00:15:54,010 –> 00:15:55,210
همین دلیل است که ما باید از توابع جمع
391
00:15:55,210 –> 00:15:57,610
برای دسترسی به داده های این گروه ها استفاده
392
00:15:57,610 –> 00:16:00,370
کنیم و نمی توانیم مستقیماً به آنها دسترسی داشته باشیم،
393
00:16:00,370 –> 00:16:01,990
اگر از روش
394
00:16:01,990 –> 00:16:03,850
رتبه بندی رایج استفاده کنید، نمی داند که آیا به
395
00:16:03,850 –> 00:16:06,160
شما 80 می دهد یا خیر. 90 اما اگر
396
00:16:06,160 –> 00:16:07,390
میانگین امتیاز را بخواهید، میداند که
397
00:16:07,390 –> 00:16:09,130
آن را با استفاده از تمام دادههای موجود محاسبه کند،
398
00:16:09,130 –> 00:16:13,420
بنابراین یک آغازگر دنبالهدار سریع بود،
399
00:16:13,420 –> 00:16:15,910
ما به نحوه ایجاد
400
00:16:15,910 –> 00:16:18,220
جداول نگاه کردهایم و نحوه درج دادهها را بررسی کردهایم،
401
00:16:18,220 –> 00:16:21,640
نحوه انتخاب دادهها و به عنوان بخشی
402
00:16:21,640 –> 00:16:23,350
از انتخاب، به ترتیب و
403
00:16:23,350 –> 00:16:25,870
محدود کردن نگاه کردیم و سپس به دنبال
404
00:16:25,870 –> 00:16:29,410
فیلتر و گروه بندی برای
405
00:16:29,410 –> 00:16:32,460
دسترسی به این زیرگروه ها در یک
406
00:16:32,460 –> 00:16:37,200
گروه بندی اصلی بودیم، بنابراین امیدواریم که منطقی باشد
407
00:16:37,200 –> 00:16:42,840
اکنون می توانیم با کدنویسی پایتون شروع کنیم و
408
00:16:45,280 –> 00:16:46,960
آن را به اشتراک بگذاریم. پاورپوینت بعداً بله در
409
00:16:46,960 –> 00:16:50,650
کل این جلسه
410
00:16:50,650 –> 00:16:52,840
بعداً آن را ویرایش می کنیم،
411
00:16:52,840 –> 00:16:54,190
کمی زیباتر می کنیم تا نبینید که دارید
412
00:16:54,190 –> 00:16:55,960
در مورد آن زمزمه می کنید و ما
413
00:16:55,960 –> 00:16:57,550
آن را نیز در دوره قرار می دهیم و
414
00:16:57,550 –> 00:16:59,140
ما پاورپوینت را نیز در آنجا قرار می دهیم o اگر
415
00:16:59,140 –> 00:17:00,880
شما بچه ها علاقه مند به آن هستید، من
416
00:17:00,880 –> 00:17:03,400
لینک دوره را بعداً به اشتراک خواهم گذاشت،
417
00:17:03,400 –> 00:17:05,199
اما بله، قطعاً ما بازی ماشین را با شما به اشتراک می گذاریم
418
00:17:05,199 –> 00:17:06,550
، چند ساعتی را صرف
419
00:17:06,550 –> 00:17:08,619
ساختن آن کنید و خیلی با آن خوشحال شوید.
420
00:17:08,619 –> 00:17:14,290
421
00:17:14,290 –> 00:17:18,640
به خوبی در دسترس باشد، بنابراین بیایید
422
00:17:18,640 –> 00:17:22,060
با برنامه خود شروع کنیم، برنامه ما به
423
00:17:22,060 –> 00:17:26,439
کاربران اجازه می دهد تا پرتوهایی را به جدول لوبیاهای خود اضافه کنند
424
00:17:26,439 –> 00:17:28,750
و همچنین به طرق مختلف با لوبیاها تعامل داشته باشند.
425
00:17:28,750 –> 00:17:31,540
426
00:17:31,540 –> 00:17:33,460
427
00:17:33,460 –> 00:17:35,140
برای یک نوع خاص از
428
00:17:35,140 –> 00:17:37,720
لوبیا و غیره، بنابراین ما با
429
00:17:37,720 –> 00:17:40,270
یک فایل جدید در اینجا شروع می کنیم که من
430
00:17:40,270 –> 00:17:43,840
پایگاه داده را dot py صدا می زنم
431
00:17:43,840 –> 00:17:45,400
و در صورت تمایل صورتم را برمی گردم فقط اگر
432
00:17:45,400 –> 00:17:49,270
بچه ها بخواهید من را ببینید. و بنابراین بله و ما
433
00:17:49,270 –> 00:17:50,860
میتوانیم ببینیم که
434
00:17:50,860 –> 00:17:54,550
جریان برای شما خوب است، یوتیوب به من میگوید که
435
00:17:54,550 –> 00:17:56,410
من با کیفیت بالا پخش میکنم، بنابراین
436
00:17:56,410 –> 00:17:58,000
فقط از خود میپرسم که آیا همه چیز
437
00:17:58,000 –> 00:18:01,330
درست است یا خیر، به من اطلاع دهید که آیا درست است یا خیر.
438
00:18:01,330 –> 00:18:03,940
به من نیز اطلاع دهید و بنابراین ما در
439
00:18:03,940 –> 00:18:05,680
اینجا در پایگاه داده نقطه P از نظر
440
00:18:05,680 –> 00:18:08,220
ما این کار را انجام می دهیم در واقع با
441
00:18:08,220 –> 00:18:11,410
اتصال به پایگاه داده خود شروع می کنیم و من
442
00:18:11,410 –> 00:18:13,180
اشاره کردم که از دنباله Lite استفاده می کنیم
443
00:18:13,180 –> 00:18:15,910
و در پایتون می توانید از دنباله Lite سه استفاده کنید
444
00:18:15,910 –> 00:18:17,740
بنابراین ما دنباله هشت سه را وارد می کنیم
445
00:18:17,740 –> 00:18:19,810
این یک ماژول داخلی در
446
00:18:19,810 –> 00:18:21,310
پایتون است که معمولاً می توانید آن را وارد کنید. باید
447
00:18:21,310 –> 00:18:22,480
هر چیزی یا هر چیزی شبیه به آن را نصب کنید
448
00:18:22,480 –> 00:18:24,520
و این همان چیزی است که برای اتصال به پایگاه داده ما استفاده می شود.
449
00:18:24,520 –> 00:18:27,010
خوب ممنون بچه ها،
450
00:18:27,010 –> 00:18:28,720
خوشحالم که جریان خوب است، نمی دانم
451
00:18:28,720 –> 00:18:32,410
کجای YouTube شاکی است.
452
00:18:32,410 –> 00:18:35,170
‘
453
00:18:35,170 –> 00:18:37,420
i3 secret import شده است
454
00:18:37,420 –> 00:18:40,900
ما پایگاه داده خود را ایجاد می کنیم به یاد داشته باشید که در داخل یک
455
00:18:40,900 –> 00:18:43,330
پایگاه داده جداول داریم و
456
00:18:43,330 –> 00:18:45,160
یاد گرفته ایم که چگونه جداول را با استفاده از
457
00:18:45,160 –> 00:18:47,440
sequel با دستور ایجاد جدول ایجاد
458
00:18:47,440 –> 00:18:49,060
کنیم اکنون ابتدا یک پایگاه داده ایجاد می
459
00:18:49,060 –> 00:18:51,010
کنیم sequel I three هر چند
460
00:18:51,010 –> 00:18:52,870
ساختن یک پایگاه داده واقعاً آسان است تنها کاری که باید
461
00:18:52,870 –> 00:18:54,310
انجام دهیم شما بگویید چیزی شبیه به اتصال
462
00:18:54,310 –> 00:18:56,620
برابر با secret i3 آنها متصل می شوند و سپس
463
00:18:56,620 –> 00:18:58,850
ما در یک فایل مانند
464
00:18:58,850 –> 00:19:02,810
DB دنباله مانند سه کار از
465
00:19:02,810 –> 00:19:05,840
فایل های داده و بنابراین هر زمان که به یک
466
00:19:05,840 –> 00:19:07,910
داده اگر فایل از قبل وجود نداشته باشد،
467
00:19:07,910 –> 00:19:09,470
میتوانید ببینید که من یک فایل DB نقطه داده
468
00:19:09,470 –> 00:19:11,900
ندارم، پس از این که میتوانیم
469
00:19:11,900 –> 00:19:13,340
مطمئن شویم که این
470
00:19:13,340 –> 00:19:16,730
یک پایگاهداده نور دنبالهدار معتبر است، میبینید که من فایل DB نقطهای ندارم
471
00:19:16,730 –> 00:19:19,280
. پیشاپیش و
472
00:19:19,280 –> 00:19:21,890
پرس و جوی خود را برای ایجاد جدول خود اجرا کنید، بنابراین اولین
473
00:19:21,890 –> 00:19:23,150
کاری که باید انجام دهیم این است که با
474
00:19:23,150 –> 00:19:25,490
اتصال بگوییم و چیزی که قرار است
475
00:19:25,490 –> 00:19:28,580
تضمین کند این است که وقتی
476
00:19:28,580 –> 00:19:31,370
کوئری خود را برای ایجاد جدول اجرا کردیم،
477
00:19:31,370 –> 00:19:32,900
در واقع در فایل ذخیره شود.
478
00:19:32,900 –> 00:19:36,800
این مدیر زمینه، Upendra را
479
00:19:36,800 –> 00:19:38,240
انجام می دهد، شما نیازی به نصب sequin light
480
00:19:38,240 –> 00:19:40,820
3 ندارید، آن را با پایتون ارائه می
481
00:19:40,820 –> 00:19:43,610
کنید، بنابراین اکنون که اتصال داریم، چیزی برای نصب در آنجا وجود ندارد،
482
00:19:43,610 –> 00:19:45,170
می توانیم ادامه دهیم و
483
00:19:45,170 –> 00:19:47,540
اتصالاتی را انجام دهیم که من اجرا خواهم کرد و
484
00:19:47,540 –> 00:19:51,740
ما ایجاد خود را در اینجا قرار می دهیم. پرتوهای جدول و سپس
485
00:19:51,740 –> 00:19:54,080
ستونها و انواع دادهها، بنابراین
486
00:19:54,080 –> 00:19:57,410
کلید اصلی id عدد صحیح است که متن نام است
487
00:19:57,410 –> 00:20:00,830
که متن روش است و عدد صحیح رتبهبندی است،
488
00:20:00,830 –> 00:20:03,590
بنابراین
489
00:20:03,590 –> 00:20:05,180
در اینجا کمی طولانی میشود، بنابراین من آن
490
00:20:05,180 –> 00:20:06,860
را به سه تقسیم میکنم. خطوط این
491
00:20:06,860 –> 00:20:08,990
در پایتون کاملاً خوب است و این
492
00:20:08,990 –> 00:20:11,210
اطمینان حاصل می کند که جدول ما ایجاد می شود، بنابراین
493
00:20:11,210 –> 00:20:13,490
اجازه دهید فقط این فایل را در PyCharm اجرا کنیم
494
00:20:13,490 –> 00:20:14,930
که همان چیزی است که من در اینجا استفاده می کنم، می توانید
495
00:20:14,930 –> 00:20:17,660
کلیک راست کرده و آن را اجرا کنید و تمام و
496
00:20:17,660 –> 00:20:19,490
شما نقطه DB داده را اینجا در سمت چپ دریافت می کنید.
497
00:20:19,490 –> 00:20:21,320
سعی کنید این را باز کنید، از شما می پرسد
498
00:20:21,320 –> 00:20:22,670
که می خواهید آن را با چه چیزی باز کنید، زیرا
499
00:20:22,670 –> 00:20:24,260
واقعاً نمی داند چگونه آن را باز کند اگر
500
00:20:24,260 –> 00:20:26,090
این متن را باز کنید،
501
00:20:26,090 –> 00:20:27,860
چیزهای عجیب و غریبی در اینجا خواهید دید، بنابراین این کار
502
00:20:27,860 –> 00:20:30,590
را نکنید. اگر نسخه حرفه ای pycharm دارید فقط می توانید
503
00:20:30,590 –> 00:20:33,920
با استفاده از دستورات دنباله به فایل دیتا دات دسترسی پیدا کنید،
504
00:20:33,920 –> 00:20:36,290
سپس
505
00:20:36,290 –> 00:20:37,940
می توانید از نمایشگر پایگاه داده در
506
00:20:37,940 –> 00:20:39,860
pycharm برای دسترسی به آن استفاده کنید، اما در اینجا من از نسخه رایگان استفاده می کنم
507
00:20:39,860 –> 00:20:41,990
، بنابراین نمی توانیم با آن به آن دسترسی پیدا کنیم.
508
00:20:41,990 –> 00:20:46,100
اکنون که این را در اینجا دریافت کردهایم،
509
00:20:46,100 –> 00:20:47,810
میخواهم
510
00:20:47,810 –> 00:20:50,300
چند تابع برای اجرای این خطوط ایجاد کنم، فقط
511
00:20:50,300 –> 00:20:52,070
برای اینکه استفاده از آنها
512
00:20:52,070 –> 00:20:54,560
از جاهای دیگر در برنامهمان کمی آسانتر باشد، بنابراین
513
00:20:54,560 –> 00:20:57,620
میخواهم یک تابع اتصال برای
514
00:20:57,620 –> 00:21:00,470
این قطعه ایجاد کنم. کد وجود دارد که اتصال را دریافت می
515
00:21:00,470 –> 00:21:01,970
کند و به جای تخصیص آن
516
00:21:01,970 –> 00:21:03,920
به یک متغیر من فقط می خواهم
517
00:21:03,920 –> 00:21:06,260
آن را برگردانم و به این ترتیب هر کسی که این
518
00:21:06,260 –> 00:21:09,170
تابع اتصال را فراخوانی می کند می تواند اتصال را دریافت کند
519
00:21:09,170 –> 00:21:11,690
و سپس بدیهی است که در اینجا ما نمی توانیم
520
00:21:11,690 –> 00:21:12,380
این را فراخوانی کنیم
521
00:21:12,380 –> 00:21:13,760
زیرا یک متغیر اتصال داریم بنابراین
522
00:21:13,760 –> 00:21:14,900
می خواهم این را در یک تابع دیگر
523
00:21:14,900 –> 00:21:18,200
نیز به نام آن قرار دهم. جداول ایجاد کنید و این
524
00:21:18,200 –> 00:21:20,420
قرار است در آنجا وارد شود، ما هنوز
525
00:21:20,420 –> 00:21:22,280
به اتصال دسترسی نداریم، بنابراین این
526
00:21:22,280 –> 00:21:24,890
پارامتری است که هر کسی ایجاد
527
00:21:24,890 –> 00:21:26,360
جداول را فراخوانی میکند، اتصالی را به
528
00:21:26,360 –> 00:21:28,730
آن میدهد که باید
529
00:21:28,730 –> 00:21:33,260
برای اجرای پرس و جو استفاده کند. بنابراین
530
00:21:33,260 –> 00:21:35,330
من را به فایل بعدی میرسانیم
531
00:21:35,330 –> 00:21:38,630
که یک فایل جدید به نام app py ایجاد میکنیم و در
532
00:21:38,630 –> 00:21:40,370
اینجا با دادههای مبتنی بر py تعامل میکنیم،
533
00:21:40,370 –> 00:21:42,650
بنابراین این چیزی است که
534
00:21:42,650 –> 00:21:44,660
در این دوره جدید بسیار انجام میدهیم و سعی میکنیم آن را
535
00:21:44,660 –> 00:21:47,210
متمایز کنیم. بین کد کد رو به رو کاربر
536
00:21:47,210 –> 00:21:49,730
که کاربران با آن تعامل دارند
537
00:21:49,730 –> 00:21:52,090
و برنامه p1 قرار است از آن استفاده کند و
538
00:21:52,090 –> 00:21:55,220
کد تعاملی داده که
539
00:21:55,220 –> 00:21:58,400
فقط با پایگاه داده تعامل دارد، بنابراین
540
00:21:58,400 –> 00:22:00,740
این کد برای برنامه dot py برای
541
00:22:00,740 –> 00:22:02,870
کد کاربر است، بنابراین آنچه ما می خواهیم انجام دهیم. در اینجا انجام دهید این است
542
00:22:02,870 –> 00:22:05,060
که ما می خواهیم ایجاد کنیم یک تابع منو داشته باشید
543
00:22:05,060 –> 00:22:06,830
و در آن با
544
00:22:06,830 –> 00:22:09,590
گرفتن اتصال شروع کنیم، بنابراین
545
00:22:09,590 –> 00:22:12,020
اتصال نقطهای پایگاه داده را انجام میدهیم و البته
546
00:22:12,020 –> 00:22:14,870
باید پایگاه داده را وارد کنیم و سپس اتصال
547
00:22:14,870 –> 00:22:17,110
نقطهای پایگاه داده ایجاد جداول را انجام
548
00:22:17,110 –> 00:22:20,480
میدهیم. منوی
549
00:22:20,480 –> 00:22:22,760
اینجا از کاربر سؤال میپرسد
550
00:22:22,760 –> 00:22:25,100
و ورودیهایش را پس میگیرد، اضافه کردن لوبیاها،
551
00:22:25,100 –> 00:22:27,350
یافتن لوبیاها که اطلاعات را نشان میدهند و
552
00:22:27,350 –> 00:22:34,010
به همین ترتیب، خوب خوب، ما بچهها مطمئن شوید که
553
00:22:34,010 –> 00:22:36,700
اگر شما آن را دوست دارید، این جریان را دوست دارید و
554
00:22:36,700 –> 00:22:39,770
آنها عالی خواهند بود و ما این کار را نمیکنیم.
555
00:22:39,770 –> 00:22:41,360
برای پخشهای زنده زیرنویس
556
00:22:41,360 –> 00:22:44,270
نداشته باشید، ایجاد آنها واقعاً امکانپذیر
557
00:22:44,270 –> 00:22:48,470
نیست، اما اگر در نهایت این
558
00:22:48,470 –> 00:22:50,150
را در دوره آپلود کنیم، زیرنویسهایی خواهیم داشت،
559
00:22:50,150 –> 00:22:54,710
پس خوب است، پس بیایید اکنون به پایگاه داده
560
00:22:54,710 –> 00:22:56,690
برگردیم و سؤالات خود را اضافه کنیم.
561
00:22:56,690 –> 00:23:00,140
برای تعامل با پایگاه داده خود،
562
00:23:00,140 –> 00:23:01,280
بنابراین اولین چیزی که می خواهیم
563
00:23:01,280 –> 00:23:03,770
با آن شروع کنیم، یک تمرین خوب است که عبارت است
564
00:23:03,770 –> 00:23:06,860
از قرار دادن پرس و جوهای خود در جایی که
565
00:23:06,860 –> 00:23:09,710
داخل کد نیست، بنابراین ما این
566
00:23:09,710 –> 00:23:11,480
پرس و جو را در اینجا برای ایجاد دانه های جدولی انتخاب می
567
00:23:11,480 –> 00:23:13,340
کنیم و ما. دوباره آن را قطع می کنیم و ما میخواهم
568
00:23:13,340 –> 00:23:16,040
آن را در اینجا بگذارم جدول لوبیا ایجاد کنید و
569
00:23:16,040 –> 00:23:17,480
ما فقط آن را برابر میکنیم که
570
00:23:17,480 –> 00:23:19,460
میدانم اینجا کمی طولانی است، بنابراین من این چیز را
571
00:23:19,460 –> 00:23:21,740
کوچک میکنم تا شما بچهها بتوانید آن را ببینید،
572
00:23:21,740 –> 00:23:25,760
اما اکنون میتوانیم آن را پایین بیاوریم. در اینجا
573
00:23:25,760 –> 00:23:28,130
و از آن استفاده کنید، آنها همه پرس و جوهای ما
574
00:23:28,130 –> 00:23:29,210
را در بالا دارند، این کار را
575
00:23:29,210 –> 00:23:30,800
برای ما آسان تر می کند که
576
00:23:30,800 –> 00:23:34,550
بعداً در صورت نیاز آنها را تغییر دهیم و بنابراین
577
00:23:34,550 –> 00:23:36,890
چیز بعدی این است که پرتو را وارد کنیم که باید
578
00:23:36,890 –> 00:23:39,020
بتوانیم لوبیا اضافه کنیم. به پایگاه داده با استفاده از
579
00:23:39,020 –> 00:23:42,110
ورودی کاربران، بنابراین درج را در beans انجام می دهیم
580
00:23:42,110 –> 00:23:44,660
و در اینجا می خواهیم داده ها
581
00:23:44,660 –> 00:23:47,750
را در روش نام و ستون های رتبه بندی وارد کنیم،
582
00:23:47,750 –> 00:23:49,670
اما در ستون ID نه، زیرا
583
00:23:49,670 –> 00:23:51,320
به طور خودکار توسط
584
00:23:51,320 –> 00:23:54,080
عملکرد افزایش خودکار در نور Seco ایجاد می شود
585
00:23:54,080 –> 00:23:54,470
.
586
00:23:54,470 –> 00:23:57,770
رتبهبندی متد نام را انجام میدهیم و سپس
587
00:23:57,770 –> 00:24:01,070
مقادیر را انجام میدهیم و میخواهیم کاربر
588
00:24:01,070 –> 00:24:03,680
بتواند اطلاعات یا متغیرهای این پرس و جو را
589
00:24:03,680 –> 00:24:06,320
از کد پایتون بدهد و بنابراین
590
00:24:06,320 –> 00:24:07,910
به جای قرار دادن آنچه میخواهیم
591
00:24:07,910 –> 00:24:09,890
در اینجا وارد کنیم، همانطور که قبل از
592
00:24:09,890 –> 00:24:10,910
گذاشتن علامت سؤال انجام دادیم. علامت
593
00:24:10,910 –> 00:24:13,520
سوال علامت سوال و بعد وقتی اجرا می کنیم با
594
00:24:13,520 –> 00:24:15,830
این پرس و جو، ما مطمئن خواهیم شد که به
595
00:24:15,830 –> 00:24:18,800
پرس و جو سه متغیر علامت سوال
596
00:24:18,800 –> 00:24:25,400
در اینجا می دهیم تا در اینجا جایگزین شود، بسیار خوب و
597
00:24:25,400 –> 00:24:27,580
هیچ چیز در جزئیات یا DB مفید نیست،
598
00:24:27,580 –> 00:24:37,670
بنابراین بله عالی است، بنابراین همه چیزهایی که
599
00:24:37,670 –> 00:24:39,860
برای تعامل با دنباله Lite می نویسیم
600
00:24:39,860 –> 00:24:42,260
به همین ترتیب است. ساختار ما
601
00:24:42,260 –> 00:24:44,330
ابتدا از این مدیریت زمینه استفاده می کنیم تا
602
00:24:44,330 –> 00:24:46,430
مطمئن شویم که هر چیزی که
603
00:24:46,430 –> 00:24:48,890
در پایگاه داده ذخیره می کنیم در واقع
604
00:24:48,890 –> 00:24:50,990
در فایل ذخیره می شود و سپس اتصالی را انجام می
605
00:24:50,990 –> 00:24:52,940
دهیم که اجرا می شود و
606
00:24:52,940 –> 00:24:55,400
پرس و جو را اجرا می کنیم. ما
607
00:24:55,400 –> 00:24:58,220
همین کار را در اینجا انجام می دهیم و bean را اضافه می کنیم
608
00:24:58,220 –> 00:25:00,440
و آن را می نامیم این تابع
609
00:25:00,440 –> 00:25:03,680
سه چیز را از کاربر دریافت می
610
00:25:03,680 –> 00:25:06,530
کند: نام متد و رتبه بندی و
611
00:25:06,530 –> 00:25:08,680
سپس با اتصال
612
00:25:08,680 –> 00:25:12,580
اتصال که insert را اجرا می کند انجام می شود. پرتو
613
00:25:12,580 –> 00:25:15,260
دقیقاً مانند آن البته
614
00:25:15,260 –> 00:25:16,670
اتصالی ندارد زیرا این یک
615
00:25:16,670 –> 00:25:18,500
پارامتر در اینجا بود و
616
00:25:18,500 –> 00:25:20,690
بین همه چیز به اشتراک گذاشته نمی شود بنابراین به
617
00:25:20,690 –> 00:25:24,010
یک اتصال نیز نیاز دارد
618
00:25:26,179 –> 00:25:29,350
بنابراین امیدوارم که همه اینها منطقی باشد
619
00:25:29,350 –> 00:25:31,909
به یاد داشته باشید که ما باید p
620
00:25:31,909 –> 00:25:35,090
سه مقداری را که کاربر میخواهد
621
00:25:35,090 –> 00:25:37,369
در پرس و جو وارد کند تا هر یک
622
00:25:37,369 –> 00:25:39,740
از علامتهای سوال جایگزین شود، بنابراین یک
623
00:25:39,740 –> 00:25:42,019
آرگومان دوم برای اتصال برای اجرا در هنگام
624
00:25:42,019 –> 00:25:43,820
کار با نور بعدی که در
625
00:25:43,820 –> 00:25:46,940
روش نام ارسال میکنیم و رتبهبندی را بهعنوان چند عدد از
626
00:25:46,940 –> 00:25:50,179
مقادیر میدهیم. میخواهید هر کدام را درج کنید
627
00:25:50,179 –> 00:25:51,889
، جایگزین یکی از این علامتهای سوال میشود
628
00:25:51,889 –> 00:25:53,419
و در پایان هر چیزی را که کاربر میخواهد وارد کند، در لوبیا قرار میدهیم،
629
00:25:53,419 –> 00:25:55,960
630
00:25:55,960 –> 00:25:58,909
حالا بیایید روی چند جستار دیگر کار
631
00:25:58,909 –> 00:26:03,200
کنیم که باید بدانیم که لوبیاها
632
00:26:03,200 –> 00:26:06,139
یک لوبیا را پیدا کنند. بهترین
633
00:26:06,139 –> 00:26:08,659
روش آماده سازی یک لوبیا
634
00:26:08,659 –> 00:26:11,929
را نام ببرید یا پیدا کنید، بنابراین من می خواهم همه لوبیاهای جنگی را در
635
00:26:11,929 –> 00:26:13,879
آنجا بیاورم و این
636
00:26:13,879 –> 00:26:17,269
ستاره از بین لوبیاها انتخاب می شود و اتفاقاً من
637
00:26:17,269 –> 00:26:19,909
عادت دا






![فیلم آموزشی: دوره سقوط پایتون [TAGALOG]](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/LQA4WSg011kimage2.jpg)