در این مطلب، ویدئو نحوه انجام: شبیه سازی مونت کارلو در پایتون (مقدمه) با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:27:23
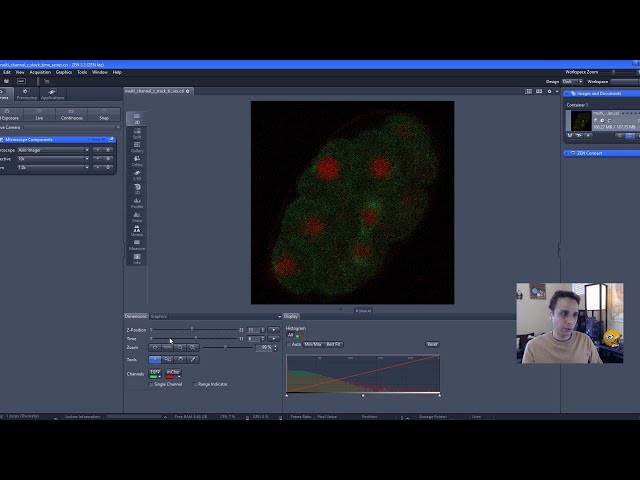
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,320 –> 00:00:02,639
امروز ما شبیه سازی مونت کارلو
2
00:00:02,639 –> 00:00:05,200
در پایتون را بررسی می کنیم و شاید قبلاً این
3
00:00:05,200 –> 00:00:06,720
اصطلاح را نشنیده باشید، اما
4
00:00:06,720 –> 00:00:10,000
معنای مونت کارلو این است که ما می خواهیم
5
00:00:10,000 –> 00:00:13,200
یک آزمایش زندگی واقعی را با استفاده از
6
00:00:13,200 –> 00:00:15,759
متغیرهای تصادفی در رایانه شبیه سازی کنیم و حالا
7
00:00:15,759 –> 00:00:17,199
مزایای آن چاه چیست. البته
8
00:00:17,199 –> 00:00:18,880
زمانی که روی رایانه کار می کنید می توانید
9
00:00:18,880 –> 00:00:21,279
آزمایش های بسیار زیادی را اجرا کنید در حالی که در
10
00:00:21,279 –> 00:00:23,039
زندگی واقعی ممکن است اجرای یک آزمایش زمان زیادی طول بکشد
11
00:00:23,039 –> 00:00:25,439
و بنابراین
12
00:00:25,439 –> 00:00:28,160
در دنیای واقعی به نوعی محدود به زمان هستید، مونت
13
00:00:28,160 –> 00:00:30,240
کارلو نیز می تواند مورد استفاده قرار گیرد. برخی از
14
00:00:30,240 –> 00:00:32,719
نتایج تجربی از قبل تولید کنید تا
15
00:00:32,719 –> 00:00:34,239
مطمئن شوید آزمایشی که
16
00:00:34,239 –> 00:00:36,399
انجام میدهید واقعاً به درستی انجام میشود و
17
00:00:36,399 –> 00:00:38,399
با آنچه شبیهسازی باید به شما بگوید مطابقت دارد.
18
00:00:38,399 –> 00:00:40,800
19
00:00:40,800 –> 00:00:42,800
20
00:00:42,800 –> 00:00:45,280
21
00:00:45,280 –> 00:00:46,960
متغیرهایی که می دانید
22
00:00:46,960 –> 00:00:48,800
گاهی اوقات توزیعی دارید که در پایتون کدگذاری نشده است،
23
00:00:48,800 –> 00:00:51,199
چگونه متغیرهای تصادفی تولید می کنید
24
00:00:51,199 –> 00:00:53,440
و سپس چگونه یک
25
00:00:53,440 –> 00:00:55,760
آزمایش را درست تنظیم کنید، چیزی به شما داده می شود
26
00:00:55,760 –> 00:00:57,760
که g در زندگی واقعی چگونه
27
00:00:57,760 –> 00:00:59,680
از این متغیرهای تصادفی برای
28
00:00:59,680 –> 00:01:01,920
انجام یک آزمایش واقعی استفاده میکنید، حتماً لایک
29
00:01:01,920 –> 00:01:03,680
کنید و مشترک شوید اگر از این
30
00:01:03,680 –> 00:01:05,760
ویدیو لذت میبرید، همه ویدیوهای دیگر من را
31
00:01:05,760 –> 00:01:09,200
نیز بررسی کنید و
32
00:01:10,720 –> 00:01:12,880
مثل همیشه از بستههایی که ما numpy
33
00:01:12,880 –> 00:01:15,040
scipy matplotlib داریم لذت ببرید. senpai و من قصد دارم
34
00:01:15,040 –> 00:01:16,880
از سبک ترسیم بهتری برای
35
00:01:16,880 –> 00:01:18,240
matplotlib استفاده کنیم،
36
00:01:18,240 –> 00:01:20,320
بنابراین قبل از اینکه وارد هر کدنویسی
37
00:01:20,320 –> 00:01:21,759
شویم، مفید است که
38
00:01:21,759 –> 00:01:23,439
مقدمه ای در مورد
39
00:01:23,439 –> 00:01:25,840
اینکه دقیقاً مونت کارلو چیست و
40
00:01:25,840 –> 00:01:27,119
هدف از آن چیست
41
00:01:27,119 –> 00:01:29,200
و بنابراین من می گویم و مفید است.
42
00:01:29,200 –> 00:01:30,560
بسته به جایی که به آن
43
00:01:30,560 –> 00:01:32,560
نگاه می کنید، به روش های کمی متفاوت تعریف می شود، بنابراین فکر می کنم ساده ترین راه برای
44
00:01:32,560 –> 00:01:34,159
بیان آن چیزی است
45
00:01:34,159 –> 00:01:36,560
که برای شبیه سازی یک آزمایش زندگی واقعی نوشته ام
46
00:01:36,560 –> 00:01:38,880
که تا حدودی به تصادفی بودن بستگی دارد،
47
00:01:38,880 –> 00:01:40,640
بنابراین وقتی آزمایش هایی را
48
00:01:40,640 –> 00:01:42,159
در زندگی واقعی انجام می دهید. می دانید
49
00:01:42,159 –> 00:01:43,600
اندازه گیری ذرات در
50
00:01:43,600 –> 00:01:46,399
آشکارساز اطلس یا شمارش رادیواکتیویته از
51
00:01:46,399 –> 00:01:48,240
یک منبع، عناصر
52
00:01:48,240 –> 00:01:51,040
تصادفی وجود دارد که در چنین چیزی اتفاق می افتد،
53
00:01:51,040 –> 00:01:53,040
به عنوان مثال مانند من اینجا می گویم شمارش
54
00:01:53,040 –> 00:01:54,479
تعداد رادیواکتیو از یک منبع رادیو اکتیو تجزیه می شود
55
00:01:54,479 –> 00:01:56,399
و فرض کنید که شما
56
00:01:56,399 –> 00:01:58,640
برای 10 ثانیه حساب می کنید که این یک
57
00:01:58,640 –> 00:02:00,799
متغیر تصادفی سم است و بنابراین
58
00:02:00,799 –> 00:02:03,119
تابع جرم احتمالی دارد که به نظر می
59
00:02:03,119 –> 00:02:05,040
رسد این یک
60
00:02:05,040 –> 00:02:07,040
آمار استاندارد است که می دانید ممکن است
61
00:02:07,040 –> 00:02:09,119
قبلاً این را دیده باشید.
62
00:02:09,119 –> 00:02:11,680
مقدار x را وصل کنم این احتمال تعداد تعداد زیادی را به من می دهد،
63
00:02:11,680 –> 00:02:13,440
بنابراین اگر x
64
00:02:13,440 –> 00:02:15,520
را برابر یک وصل کنم، مقدار x برابر
65
00:02:15,520 –> 00:02:18,319
دو است و لامبدا مقدار متوسط لامبدا نی
66
00:02:18,319 –> 00:02:19,920
ت، لازم نیست یک عدد صحیح باشد، می تواند با
67
00:02:19,920 –> 00:02:22,000
د. مثلاً یک
68
00:02:22,000 –> 00:02:24,480
عدد واقعی را میدانید، اما من x را
69
00:02:24,480 –> 00:02:25,920
که یک عدد صحیح است در اینجا وصل
70
00:02:25,920 –> 00:02:27,360
میکنم و این احتمال را برای من برمیگرداند که این همان چیزی است
71
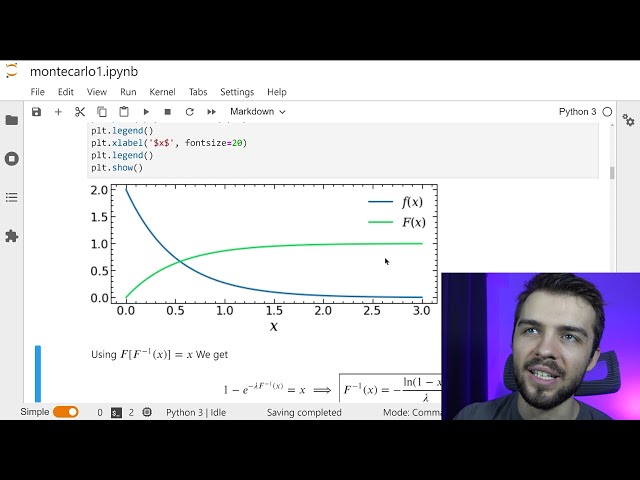
00:02:27,360 –> 00:02:30,000
که تابع جرم احتمال انجام میدهد
72
00:02:30,000 –> 00:02:31,920
آه، آزمایش دیگری میدانید شاید
73
00:02:31,920 –> 00:02:33,680
بخواهید انرژی ذرات شناسایی شده
74
00:02:33,680 –> 00:02:36,400
را در یک تشخیص خاص تعیین کنید. سلول
75
00:02:36,400 –> 00:02:38,080
در اطلس که یک چیز بزرگ در
76
00:02:38,080 –> 00:02:40,319
مورد موضوع پایان نامه کارشناسی ارشد من است و بنابراین
77
00:02:40,319 –> 00:02:42,080
در اینجا متغیر تصادفی چیزی
78
00:02:42,080 –> 00:02:44,319
که تصادفی است دیگر تعداد شمارش ها
79
00:02:44,319 –> 00:02:46,239
مانند توزیع
80
00:02:46,239 –> 00:02:47,840
پواسون نیست، بلکه همان واقعی است. l انرژی که
81
00:02:47,840 –> 00:02:50,480
در سلول رسوب کرده است، بنابراین انرژی
82
00:02:50,480 –> 00:02:52,239
e متغیر تصادفی است و تابع
83
00:02:52,239 –> 00:02:54,239
چگالی احتمال مربوطه
84
00:02:54,239 –> 00:02:56,640
به این شکل است، بنابراین این
85
00:02:56,640 –> 00:02:58,080
با تابع جرم احتمال متفاوت است، تابع احتمال جرم
86
00:02:58,080 –> 00:02:59,120
87
00:02:59,120 –> 00:03:00,480
به من یک
88
00:03:00,480 –> 00:03:02,959
احتمال مستقیم می دهد تابع چگالی احتمال
89
00:03:02,959 –> 00:03:05,680
شش x در اینجا پیوسته است،
90
00:03:05,680 –> 00:03:07,040
دیگر فقط تعداد شمارش ها نیست،
91
00:03:07,040 –> 00:03:08,239
یک دو سه چهار پنج شش، بلکه
92
00:03:08,239 –> 00:03:10,239
یک عدد واقعی پیوسته است.
93
00:03:10,239 –> 00:03:12,239
94
00:03:12,239 –> 00:03:14,480
95
00:03:14,480 –> 00:03:15,920
96
00:03:15,920 –> 00:03:17,920
من
97
00:03:17,920 –> 00:03:20,800
چگالی را در فضایی ادغام میکنم، بنابراین
98
00:03:20,800 –> 00:03:22,640
اگر احتمال را میخواهم،
99
00:03:22,640 –> 00:03:24,640
تابع چگالی احتمال را
100
00:03:24,640 –> 00:03:26,640
روی ناحیه ای از x ادغام میکنم، بنابراین این
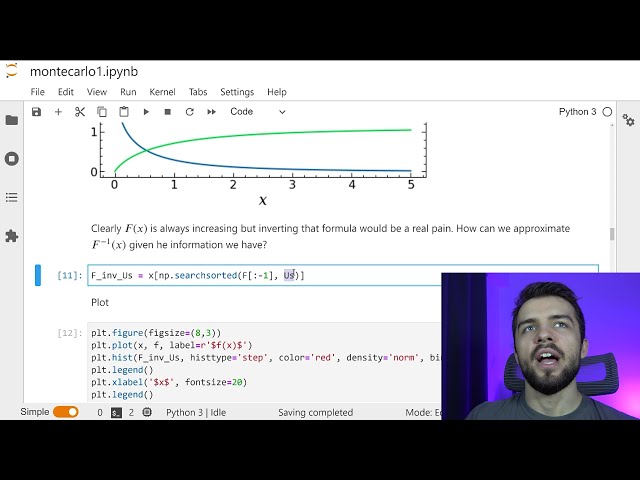
101
00:03:26,640 –> 00:03:28,080
تابع چگالی احتمال من در اینجا است و
102
00:03:28,080 –> 00:03:30,400
ما در ویدیو به آن خواهیم پرداخت، بنابراین این
103
00:03:30,400 –> 00:03:33,599
در واقع یک مدل خوب برای
104
00:03:33,599 –> 00:03:35,440
کالریمتر آرگون مایع اطلس این مدلی است
105
00:03:35,440 –> 00:03:37,360
که من در پایان نامه خود استفاده کردم و
106
00:03:37,360 –> 00:03:38,400
چیزها را به خوبی نشان می دهد و
107
00:03:38,400 –> 00:03:40,560
مقادیر خاصی وجود دارد. f f1 e1 f2
108
00:03:40,560 –> 00:03:42,720
و e2 که میتوانید با برخی از دادههای واقعی که اندازهگیری میکنید مطابقت دهید
109
00:03:42,720 –> 00:03:44,400
110
00:03:44,400 –> 00:03:45,680
، یک مثال دیگر در اینجا وجود دارد که میتوانید به آن
111
00:03:45,680 –> 00:03:47,120
نگاه کنید و البته یک
112
00:03:47,120 –> 00:03:48,879
شبیهسازی مونت کارلو بسیار معروف که
113
00:03:48,879 –> 00:03:50,959
انجام آن در پایتون واقعاً آسان است این است که میتوانید
114
00:03:50,959 –> 00:03:53,360
در واقع مقداری را برای آن تخمین بزنید. pi من
115
00:03:53,360 –> 00:03:55,040
احتمالاً این کار را در این ویدیو انجام نخواهم داد
116
00:03:55,040 –> 00:03:56,879
اما ممکن است یک ویدیوی کوتاه در آینده وجود داشته باشد
117
00:03:56,879 –> 00:03:58,720
که در آن نشان میدهم چگونه پی را
118
00:03:58,720 –> 00:04:00,640
واقعاً به راحتی در پایتون محاسبه کنم
119
00:04:00,640 –> 00:04:01,680
زیرا
120
00:04:01,680 –> 00:04:03,360
میدانید که pi یک عدد جالب به عنوان
121
00:04:03,360 –> 00:04:06,239
یک مفهوم است که برای مدت طولانی وجود داشته است.
122
00:04:06,239 –> 00:04:09,920
به عنوان یک مقدار واقعی، 3.1418 هر چیزی که
123
00:04:09,920 –> 00:04:11,200
پی
124
00:04:11,200 –> 00:04:13,840
است، آنقدرها هم پیش پا افتاده نیست که بتوان به آن دست یافت، بنابراین
125
00:04:13,840 –> 00:04:16,000
برای اکثر موارد، زمانی که آزمایشی را شبیه سازی
126
00:04:16,000 –> 00:04:18,000
می کنید، دو مرحله ضروری وجود دارد که
127
00:04:18,000 –> 00:04:19,759
می خواهید متغیرهای تصادفی را
128
00:04:19,759 –> 00:04:21,680
بر اساس توزیعی تولید
129
00:04:21,680 –> 00:04:23,680
کنید که می دانید شاید یک متغیر پواسون می تواند
130
00:04:23,680 –> 00:04:25,040
متغیری باشید که شبیه این یا
131
00:04:25,040 –> 00:04:26,880
هر چیز دیگری باشد که می دانید
132
00:04:26,880 –> 00:04:28,560
با آزمایش شما مرتبط است
133
00:04:28,560 –> 00:04:30,000
و می خواهید از این
134
00:04:30,000 –> 00:04:31,759
متغیرهای تصادفی برای انجام نوعی
135
00:04:31,759 –> 00:04:33,280
آزمایش استفاده کنید و این به نوعی مبهم است که من چگونه انجام داده
136
00:04:33,280 –> 00:04:35,280
ام. همین الان گفتم اما
137
00:04:35,280 –> 00:04:37,600
من یک و دو را
138
00:04:37,600 –> 00:04:38,880
مرور می کنم و همه چیز را مرور می کنم و به شما نشان می دهم که چگونه
139
00:04:38,880 –> 00:04:41,040
این کار انجام می شود بنابراین اولین قدم
140
00:04:41,040 –> 00:04:42,560
در همه این موارد این است که در واقع
141
00:04:42,560 –> 00:04:44,560
متغیرهای تصادفی را مطابق با یک
142
00:04:44,560 –> 00:04:46,400
توزیع خاص
143
00:04:46,400 –> 00:04:49,120
و آنقدرها هم که همیشه
144
00:04:49,120 –> 00:04:50,560
درست به نظر میرسد آسان نیست، منظور شما این است که میدانید که
145
00:04:50,560 –> 00:04:52,240
رایانهها میتوانند اعداد تصادفی تولید
146
00:04:52,240 –> 00:04:54,479
کنند، آنها میتوانند اعداد یکنواخت تصادفی تولید کنند
147
00:04:54,479 –> 00:04:55,840
و اگر بستهای مانند numpy دارید،
148
00:04:55,840 –> 00:04:57,360
میتواند انواع مختلفی از
149
00:04:57,360 –> 00:04:59,440
اعداد تصادفی تولید کند، اما فرض کنید شما
150
00:04:59,440 –> 00:05:01,840
توزیعی داشته باشید که در حالت ناقص نباشد چگونه
151
00:05:01,840 –> 00:05:03,520
می توانید یک عدد تصادفی را
152
00:05:03,520 –> 00:05:05,680
طبق یک توزیع ایجاد کنید
153
00:05:05,680 –> 00:05:07,440
و یک قضیه واقعا مفید در اینجا وجود دارد و
154
00:05:07,440 –> 00:05:09,600
این مهمترین قضیه ای است
155
00:05:09,600 –> 00:05:11,919
که من برای مونت کارلو فکر می کنم و واقعا
156
00:05:11,919 –> 00:05:14,160
مفید است که بنشینید
157
00:05:14,160 –> 00:05:16,800
آن را بخوانید و واقعاً آن را درک کنید
158
00:05:16,800 –> 00:05:19,440
بنابراین اگر یک متغیر تصادفی x بنابراین
159
00:05:19,440 –> 00:05:21,600
x متغیر تصادفی در اینجا باشد،
160
00:05:21,600 –> 00:05:24,240
تابع چگالی تجمعی f برابر x
161
00:05:24,240 –> 00:05:25,919
داشته باشد که برای دانستن اینکه
162
00:05:25,919 –> 00:05:28,000
cdf چقدر است بنابراین احتمال th مفید است at
163
00:05:28,000 –> 00:05:30,160
انتگرال از بی نهایت منفی تا x
164
00:05:30,160 –> 00:05:32,400
تابع چگالی احتمال در
165
00:05:32,400 –> 00:05:35,039
مورد توزیع های ساده است، بنابراین اگر x
166
00:05:35,039 –> 00:05:37,120
یک cdf از f
167
00:05:37,120 –> 00:05:39,039
داشته باشد، منحصر به فرد است اگر f کمی بدانید،
168
00:05:39,039 –> 00:05:40,400
f بزرگ را می دانید، بنابراین آنها
169
00:05:40,400 –> 00:05:42,240
معادل یکدیگر هستند،
170
00:05:42,240 –> 00:05:44,800
پس متغیر f معکوس بنابراین
171
00:05:44,800 –> 00:05:46,960
تابع معکوس این تابع
172
00:05:46,960 –> 00:05:47,840
u
173
00:05:47,840 –> 00:05:50,080
که در آن u یک متغیر یکنواخت تصادفی
174
00:05:50,080 –> 00:05:54,160
بین 0 و 1 است همچنین دارای cdf f از x است بنابراین
175
00:05:54,160 –> 00:05:55,919
این مقدار زیادی است و من آن را واقعاً
176
00:05:55,919 –> 00:05:58,880
به سادگی اینجا نوشتم بنابراین x این به معنای توزیع
177
00:05:58,880 –> 00:06:00,080
بر اساس
178
00:06:00,080 –> 00:06:01,360
f از است. x به
179
00:06:01,360 –> 00:06:03,680
این معنی است که f معکوس u در جایی که
180
00:06:03,680 –> 00:06:06,160
این یک عدد تصادفی یکنواخت بین
181
00:06:06,160 –> 00:06:07,440
0 و 1 است
182
00:06:07,440 –> 00:06:11,039
نیز دارای این توزیع است، بنابراین این x و
183
00:06:11,039 –> 00:06:13,919
این هر دو توزیع یکسانی دارند،
184
00:06:13,919 –> 00:06:14,720
بنابراین
185
00:06:14,720 –> 00:06:16,880
اگر
186
00:06:16,880 –> 00:06:18,800
بتوانم تعداد زیادی بازدید و تعداد زیادی اعداد ایجاد کنم ابزار بسیار مفیدی است.
187
00:06:18,800 –> 00:06:21,759
بین 0 و 1 و من آنها را به f
188
00:06:21,759 –> 00:06:24,319
معکوس وصل می کنم و اعداد را محاسبه می
189
00:06:24,319 –> 00:06:26,560
کنم آنها مانند x توزیع می شوند، بنابراین
190
00:06:26,560 –> 00:06:29,199
این نتیجه کلیدی است که نوعی از
191
00:06:29,199 –> 00:06:32,240
مونت کارلو تا حدودی بر اساس آن است،
192
00:06:32,240 –> 00:06:33,360
بنابراین برای مثال اجازه دهید به نمایی نگاه کنیم.
193
00:06:33,360 –> 00:06:35,360
توزیع کنید در اینجا
194
00:06:35,360 –> 00:06:37,520
تابع چگالی احتمال برابر است با
195
00:06:37,520 –> 00:06:40,000
لامبدا e به لامبدا منفی x
196
00:06:40,000 –> 00:06:42,000
تابع چگالی تجمعی
197
00:06:42,000 –> 00:06:43,199
که انتگرال آن از
198
00:06:43,199 –> 00:06:45,759
بینهایت منفی تا x 1 منهای e به
199
00:06:45,759 –> 00:06:47,199
لامبدا منفی x است، بنابراین این همان مقداری است که
200
00:06:47,199 –> 00:06:49,680
f بزرگ از x است. فرض کنید من میخواهم
201
00:06:49,680 –> 00:06:51,199
اعداد تصادفی را مطابق با
202
00:06:51,199 –> 00:06:52,639
این توزیع
203
00:06:52,639 –> 00:06:54,319
تولید کنم، ما میتوانیم این کار را انجام دهیم و قبل از انجام
204
00:06:54,319 –> 00:06:56,400
آن، اجازه دهید در واقع به f کوچک
205
00:06:56,400 –> 00:06:58,960
و f بزرگ نگاه کنیم، بنابراین در اینجا چند
206
00:06:58,960 –> 00:07:00,720
متغیر x را از 0 تا 3 100 میسازم. اجازه دهید
207
00:07:00,720 –> 00:07:03,840
بستهها را در اینجا وارد کنیم.
208
00:07:08,319 –> 00:07:10,400
در اینجا من فقط 100 چیز را بین 0
209
00:07:10,400 –> 00:07:12,560
و 3 می سازم و فقط f کوچک
210
00:07:12,560 –> 00:07:15,680
و f بزرگ را وصل می کنم و در اینجا لامبدا برابر با 2 است.
211
00:07:15,680 –> 00:07:18,000
بنابراین بیایید در واقع این توابع را به درستی رسم کنیم
212
00:07:18,000 –> 00:07:20,080
و بنابراین من x و f و x و
213
00:07:20,080 –> 00:07:21,840
f بزرگ را دارم و می توانید ببینید که f کوچک از x
214
00:07:21,840 –> 00:07:23,280
که به این شکل به نظر می رسد، احتمال بیشتری وجود دارد که
215
00:07:23,280 –> 00:07:25,919
شما بدانید هر موجودی
216
00:07:25,919 –> 00:07:28,479
در این ناحیه از x اینجاست و سپس
217
00:07:28,479 –> 00:07:30,400
کمتر از آن اینجا باشد و سپس f بزرگ
218
00:07:30,400 –> 00:07:32,160
از x که تابع چگالی تجمعی
219
00:07:32,160 –> 00:07:34,400
است که بین صفر می رود. و یکی
220
00:07:34,400 –> 00:07:36,720
مثل این صد در صد، بنابراین اگر به
221
00:07:36,720 –> 00:07:38,800
اینجا بروم، این احتمال وجود دارد که می
222
00:07:38,800 –> 00:07:40,560
دانید متغیر تصادفی کمتر یا
223
00:07:40,560 –> 00:07:42,319
مساوی با این مقدار است، بنابراین اگر من از اینجا خارج شوم
224
00:07:42,319 –> 00:07:44,080
و این یکی باشد، اساساً
225
00:07:44,080 –> 00:07:45,680
صد درصد است که در جایی در
226
00:07:45,680 –> 00:07:47,680
این منطقه است. کمتر از آن عدد همان
227
00:07:47,680 –> 00:07:50,000
چیزی است که کلمه تجمعی
228
00:07:50,000 –> 00:07:52,400
تابع چگالی تجمعی راست تجمعی می گوید،
229
00:07:52,400 –> 00:07:53,840
بنابراین این همان چیزی است که این توابع
230
00:07:53,840 –> 00:07:54,879
231
00:07:54,879 –> 00:07:58,240
اکنون به نظر می رسند تا f معکوس u
232
00:07:58,240 –> 00:08:00,319
233
00:08:00,319 –> 00:08:02,800
را محاسبه کنیم که متغیرهای نمایی تصادفی ما را به ما می دهد که باید
234
00:08:02,800 –> 00:08:04,479
f معکوس را محاسبه کنیم. شما می دانید که یک
235
00:08:04,479 –> 00:08:07,120
راه ساده برای انجام آن در ریاضیات وجود دارد که من از f از f
236
00:08:07,120 –> 00:08:08,639
معکوس x برابر x برابر با x است که در
237
00:08:08,639 –> 00:08:10,000
اینجا هویت است،
238
00:08:10,000 –> 00:08:12,160
سپس f معکوس x را به
239
00:08:12,160 –> 00:08:14,319
f بزرگ وصل می کنم، بنابراین 1 منهای e به لامبدا منفی f
240
00:08:14,319 –> 00:08:16,800
معکوس x برابر x برابر است. فقط این
241
00:08:16,800 –> 00:08:19,599
فرمول اینجاست، اما وصل کردن چیزی که من می دانم
242
00:08:19,599 –> 00:08:22,720
f سرمایه برابر است، بنابراین این برای آن مفید است
243
00:08:22,720 –> 00:08:24,879
و سپس من برای
244
00:08:24,879 –> 00:08:26,639
بزرگی f معکوس x را حل می کنم و این فرمول را دریافت می کنم که f
245
00:08:26,639 –> 00:08:28,800
معکوس x برابر است با منهای lon یک منهای
246
00:08:28,800 –> 00:08:30,720
x نسبت به لامبدا، بنابراین این w است
247
00:08:30,720 –> 00:08:32,719
تابع معکوس به نظر می رسد، بنابراین اگر من
248
00:08:32,719 –> 00:08:34,958
یک دسته از u را ایجاد کنم و آنها را
249
00:08:34,958 –> 00:08:36,080
در اینجا وصل
250
00:08:36,080 –> 00:08:37,360
کنم، قضیه می گوید این است که
251
00:08:37,360 –> 00:08:39,679
آنها طبق یک
252
00:08:39,679 –> 00:08:42,080
توزیع نمایی درست توزیع می شوند، بنابراین
253
00:08:42,080 –> 00:08:43,440
من یک دسته از نماها ایجاد می کنم. من
254
00:08:43,440 –> 00:08:45,040
آنها را به این تابع وصل می کنم به این
255
00:08:45,040 –> 00:08:46,880
تابع ظاهر عجیب اینجا و
256
00:08:46,880 –> 00:08:48,800
دقیقاً همانطور که من می خواهم توزیع
257
00:08:48,800 –> 00:08:50,800
می شوند بنابراین این کاری است که من اینجا انجام می دهم بنابراین در اینجا
258
00:08:50,800 –> 00:08:55,120
من 10000
259
00:08:55,120 –> 00:08:56,720
متغیر یکنواخت تصادفی بین صفر و یک تولید می
260
00:08:56,720 –> 00:08:58,080
کنم و من می توانید یک هیستوگرام از آنها درست کنید
261
00:08:58,080 –> 00:09:00,959
تا این را به شما ثابت کند
262
00:09:01,360 –> 00:09:03,920
و بیایید این را در اینجا نشان دهیم.
263
00:09:03,920 –> 00:09:05,200
می توانید ببینید که این موارد استفاده شده این
264
00:09:05,200 –> 00:09:06,959
یکنواخت تصادفی هستند که من این را در
265
00:09:06,959 –> 00:09:08,959
numpy می نامم و تقریباً یکنواخت بین
266
00:09:08,959 –> 00:09:10,240
صفر و یک است و می توانید ببینید که آنها
267
00:09:10,240 –> 00:09:12,240
توزیع شده اند. مانند این است، بنابراین
268
00:09:12,240 –> 00:09:14,000
دقیقاً همان چیزی است که ما میخواهیم و ما
269
00:09:14,000 –> 00:09:16,480
از آنها برای تولید این سرمایه f
270
00:09:16,480 –> 00:09:19,279
معکوس استفاده برای به دست آوردن متغیرهای توزیع نمایی استفاده میکنیم،
271
00:09:19,279 –> 00:09:21,440
بنابراین من این را
272
00:09:21,440 –> 00:09:23,760
استفاده معکوس f مینامم که تو را به
273
00:09:23,760 –> 00:09:25,600
این تابع وصل میکند و من فقط پلاگین در تمام
274
00:09:25,600 –> 00:09:27,760
این مقادیر u در این تابع
275
00:09:27,760 –> 00:09:28,720
در اینجا وجود دارد،
276
00:09:28,720 –> 00:09:30,320
بنابراین من آنها را ارزیابی می کنم و اکنون می
277
00:09:30,320 –> 00:09:32,240
خواهم یک هیستوگرام از این f معکوس
278
00:09:32,240 –> 00:09:33,200
استفاده کنم،
279
00:09:33,200 –> 00:09:35,680
بنابراین کاری که در اینجا انجام می دهم این است که به
280
00:09:35,680 –> 00:09:38,480
دو چیز اول نگاه می کنم،
281
00:09:38,480 –> 00:09:41,440
تابع چگالی احتمال است. در اینجا f blue من
282
00:09:41,440 –> 00:09:43,120
آن را در اینجا نیز در بالا نشان دادم
283
00:09:43,120 –> 00:09:44,959
و می توانید ببینید که من یک هیستوگرام
284
00:09:44,959 –> 00:09:46,640
از این متغیرهای تصادفی دارم و
285
00:09:46,640 –> 00:09:49,600
چگالی هیستوگرام را برابر نرمال قرار داده ام به
286
00:09:49,600 –> 00:09:51,680
طوری که مساحت زیر
287
00:09:51,680 –> 00:09:53,600
هیستوگرام برابر با یک است
288
00:09:53,600 –> 00:09:55,360
دقیقاً مانند مساحت زیر f از x
289
00:09:55,360 –> 00:09:56,959
برابر با یک است اگر من این را در اینجا نداشتم،
290
00:09:56,959 –> 00:09:58,800
به عنوان مثال، اگر من این را حذف کردم
291
00:09:58,800 –> 00:10:00,800
که در اینجا زیاد اتفاق می افتد،
292
00:10:00,800 –> 00:10:02,000
می توانید ببینید که این واقعاً
293
00:10:02,000 –> 00:10:03,440
کوچک است و تعداد وقوع ها را شمارش می کند،
294
00:10:03,440 –> 00:10:04,959
بنابراین می خواهم مطمئن شوم که
295
00:10:04,959 –> 00:10:07,760
هیستوگرام من به خودی خود عادی شده است. بنابراین من
296
00:10:07,760 –> 00:10:08,880
به این صورت می روم
297
00:10:08,880 –> 00:10:10,399
و بنابراین شما می توانید f من از x را ببینید
298
00:10:10,399 –> 00:10:11,760
که توزیعی است که می خواهم
299
00:10:11,760 –> 00:10:13,760
بر اساس آن توزیع شود و f
300
00:10:13,760 –> 00:10:16,320
معکوس استفاده از درست است که قضیه
301
00:10:16,320 –> 00:10:19,040
می گوید باید بر اساس
302
00:10:19,040 –> 00:10:21,920
f از x راست توزیع شود و یک سی دی اف بزرگ داشته باشد. f از
303
00:10:21,920 –> 00:10:24,480
x می توانید ببینید که دقیقاً از آن پیروی می کند،
304
00:10:24,480 –> 00:10:26,720
بنابراین من اکنون یک روش واقعاً خوب برای
305
00:10:26,720 –> 00:10:28,880
تولید متغیرهای تصادفی دارم، بنابراین
306
00:10:28,880 –> 00:10:30,560
کمی مگس در پماد وجود دارد و
307
00:10:30,560 –> 00:10:32,160
من مطمئن هستم که شما ممکن است در مورد این فکر کرده باشید
308
00:10:32,160 –> 00:10:33,279
زمانی که من مرحله قبل را به
309
00:10:33,279 –> 00:10:34,160
310
00:10:34,160 –> 00:10:36,399
خوبی طی می کردم. اگر بزرگ f از x در
311
00:10:36,399 –> 00:10:38,079
واقع معکوس نیست چه می شود اگر
312
00:10:38,079 –> 00:10:39,760
f معکوس x وجود نداشته باشد،
313
00:10:39,760 –> 00:10:40,720
314
00:10:40,720 –> 00:10:42,160
یک ثانیه در مورد آن فکر کنیم زیرا
315
00:10:42,160 –> 00:10:44,160
می دانیم که سرمایه f از x همیشه
316
00:10:44,160 –> 00:10:46,240
با x افزایش می یابد اگر به
317
00:10:46,240 –> 00:10:47,440
این نمودار در اینجا نگاه کنم، می دانم. که
318
00:10:47,440 –> 00:10:48,959
احتمال کمتر یا مساوی بودن
319
00:10:48,959 –> 00:10:50,000
با این
320
00:10:50,000 –> 00:10:51,120
بیشتر از
321
00:10:51,120 –> 00:10:52,480
احتمال کمتر یا مساوی با
322
00:10:52,480 –> 00:10:54,079
این خواهد بود، فقط به این دلیل که من چیزهای درستی بیشتری دارم،
323
00:10:54,079 –> 00:10:56,320
بنابراین سرمایه f از x همیشه در
324
00:10:56,320 –> 00:10:58,480
حال افزایش است، این برای هر
325
00:10:58,480 –> 00:11:01,600
حق توزیع درست است
326
00:11:01,600 –> 00:11:05,519
و بنابراین اگر سرمایه f همیشه در حال
327
00:11:05,519 –> 00:11:08,000
افزایش است، لزوماً یک معکوس وجود دارد، به این
328
00:11:08,000 –> 00:11:09,839
معنی نیست که یک
329
00:11:09,839 –> 00:11:11,440
معکوس تحلیلی مانند فرمولی وجود دارد که ما
330
00:11:11,440 –> 00:11:14,399
واقعاً میتوانیم آن را حل کنیم، اما لزوماً
331
00:11:14,399 –> 00:11:16,959
معکوسپذیر است، مگر اینکه
332
00:11:16,959 –> 00:11:18,160
ثابت باشد و شاید شما h یک
333
00:11:18,160 –> 00:11:20,399
ناپیوستگی وجود دارد، اما اساساً
334
00:11:20,399 –> 00:11:22,320
معکوس است، چیزی است که می توانم بگویم یک
335
00:11:22,320 –> 00:11:23,839
ریاضیدان ممکن است به خاطر گفتن آن از من عصبانی شود،
336
00:11:23,839 –> 00:11:25,760
اما شما می دانید که اساساً
337
00:11:25,760 –> 00:11:26,800
معکوس است
338
00:11:26,800 –> 00:11:28,399
و به عنوان مثال به این فرمول
339
00:11:28,399 –> 00:11:29,680
در اینجا نگاه کنید، این
340
00:11:29,680 –> 00:11:31,839
توزیع
341
00:11:31,839 –> 00:11:34,320
انرژی در یک سلول گرماسنج اطلس بود.
342
00:11:34,320 –> 00:11:36,000
به عنوان مثال، به
343
00:11:36,000 –> 00:11:37,360
نظر می رسد این است، بنابراین اجازه دهید
344
00:11:37,360 –> 00:11:39,360
قبل از اینکه وارد مثال و توزیع تجمعی شویم، این توزیع را رسم کنیم،
345
00:11:39,360 –> 00:11:41,360
346
00:11:41,360 –> 00:11:43,279
بنابراین در اینجا من از senpai استفاده می
347
00:11:43,279 –> 00:11:44,560
کنم تا واقعاً به
348
00:11:44,560 –> 00:11:47,279
فرمول من می خواهم cdf
349
00:11:47,279 –> 00:11:48,480
را پیدا کنم، یعنی باید پیدا کنم. انتگرال
350
00:11:48,480 –> 00:11:50,720
این کار و به جای اینکه آن را با دست انجام دهم یا
351
00:11:50,720 –> 00:11:52,240
352
00:11:52,240 –> 00:11:53,519
یکسری مراحل ریاضی را به شما نشان دهم، فقط می خواهم آن را در simpai انجام دهم و قدرت senpai را به
353
00:11:53,519 –> 00:11:55,600
شما نشان می دهم همانطور که همیشه
354
00:11:55,600 –> 00:11:56,399
انجام
355
00:11:56,399 –> 00:11:58,720
می دهم، در اینجا x و y را تعریف می کنم و سپس
356
00:11:58,720 –> 00:12:02,160
چهار متغیر در اینجا f1 f2 e1 و e2
357
00:12:02,160 –> 00:12:03,760
آنها هر دو واقعی و مثبت برای این
358
00:12:03,760 –> 00:12:05,120
توزیع در اینجا هستند
359
00:12:05,120 –> 00:12:07,920
و من f و s من را مخفف نمادین تعریف می کنم،
360
00:12:07,920 –> 00:12:10,240
بنابراین اگر یک s را بعد از یک متغیر می بینید به
361
00:12:10,240 –> 00:12:11,519
این معنی است که من با یک
362
00:12:11,519 –> 00:12:14,240
چیز نمادین سروکار دارم پس sy من تابع
363
00:12:14,240 –> 00:12:16,480
mbolic شبیه این است f1 بار simp of
364
00:12:16,480 –> 00:12:18,720
this فقط این فرمول به صورت ساده است و من
365
00:12:18,720 –> 00:12:20,800
می توانم به آن نگاه کنم و واقعاً این فرمول را دریافت می کنم
366
00:12:20,800 –> 00:12:23,519
و اگر من تابع
367
00:12:23,519 –> 00:12:25,200
توزیع تجمعی را خوب بخواهم چه کاری
368
00:12:25,200 –> 00:12:26,800
باید انجام دهم باید این تابع را یکپارچه کنم
369
00:12:26,800 –> 00:12:29,279
در اینجا که f نمادین است و من
370
00:12:29,279 –> 00:12:32,160
میخواهم x را از 0 به y ادغام کنم،
371
00:12:32,160 –> 00:12:34,240
ممکن است تعجب کنید که چرا من 0 را به
372
00:12:34,240 –> 00:12:37,120
y میبرم، نمیتوانم از x دو بار درست استفاده کنم، بنابراین
373
00:12:37,120 –> 00:12:38,720
از صفر به متغیر دیگری میروم
374
00:12:38,720 –> 00:12:40,880
که من می خواهم y
375
00:12:40,880 –> 00:12:43,120
را صدا بزنم بنابراین تابع چگالی احتمال نمادین خود را
376
00:12:43,120 –> 00:12:44,800
برای بدست آوردن تابع تجمعی
377
00:12:44,800 –> 00:12:47,760
با استفاده از
378
00:12:47,760 –> 00:12:50,000
simp ادغام می کنم
379
00:12:50,000 –> 00:12:51,920
380
00:12:51,920 –> 00:12:53,760
.
381
00:12:53,760 –> 00:12:56,240
متغیری که در اینجا جالب است،
382
00:12:56,240 –> 00:12:58,079
بنابراین یک تابع طولانی بزرگ است،
383
00:12:58,079 –> 00:13:00,000
اکنون مسئله درست است، ما میخواهیم
384
00:13:00,000 –> 00:13:02,320
محاسبه f را معکوس کنیم،
385
00:13:02,320 –> 00:13:04,079
اما من واقعاً تمایلی به گرفتن
386
00:13:04,079 –> 00:13:05,600
معکوس این تابع ندارم، نمیدانم آیا
387
00:13:05,600 –> 00:13:07,440
واقعاً در آنجا معکوس وجود دارد یا خیر شاید
388
00:13:07,440 –> 00:13:08,720
389
00:13:08,720 –> 00:13:10,560
تا آنجایی که من می دانم نباشد
390
00:13:10,560 –> 00:13:12,079
به این تابع در اینجا
391
00:13:12,079 –> 00:13:14,320
و بنابراین کاری که میخواهیم انجام دهیم این است که
392
00:13:14,320 –> 00:13:16,240
میخواهیم راه دیگری برای گرفتن معکوس
393
00:13:16,240 –> 00:13:19,040
این تابع با استفاده از رایانه پیدا کنیم
394
00:13:19,040 –> 00:13:21,200
و من این ترفند را در اینجا به شما نشان خواهم داد،
395
00:13:21,200 –> 00:13:22,560
بنابراین اولین کاری که انجام میدهیم این است. ما
396
00:13:22,560 –> 00:13:24,800
این تابع را در اینجا به یک
397
00:13:24,800 –> 00:13:27,120
تابع پایتون عددی تبدیل می کنیم، بنابراین
398
00:13:27,120 –> 00:13:28,880
هر زمان که یک n را می بینید که به معنای یک
399
00:13:28,880 –> 00:13:30,560
تابع عددی است، به این معنی است که من به آن
400
00:13:30,560 –> 00:13:32,320
اعداد می دهم و یک عدد را در پایتون برمی گرداند،
401
00:13:32,320 –> 00:13:34,480
این یک تابع عادی است که انجام آن یک تابع عادی است
402
00:13:34,480 –> 00:13:36,720
که باید آن را lamdify کنم. تابع نمادینی
403
00:13:36,720 –> 00:13:38,480
که در ویدیوهای دیگر من دیده اید،
404
00:13:38,480 –> 00:13:40,959
اینها آرگومان های ورودی هستند، این
405
00:13:40,959 –> 00:13:43,680
عبارت نمادین در اینجا است و
406
00:13:43,680 –> 00:13: