در این مطلب، ویدئو تجزیه و تحلیل داده های اکتشافی EDA با استفاده از پایتون | آموزش پایتون | ادورکا | DL Rewind – 3 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:31:15
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:10,240 –> 00:00:11,759
سلام به همه این وسیم از
2
00:00:11,759 –> 00:00:13,679
edureka است و من به همه شما خوش آمد می گویم به این
3
00:00:13,679 –> 00:00:15,280
جلسه که در آن من قصد دارم در
4
00:00:15,280 –> 00:00:17,600
مورد تجزیه و تحلیل داده های اکتشافی در
5
00:00:17,600 –> 00:00:19,520
پایتون صحبت کنم، بنابراین بیایید ابتدا به
6
00:00:19,520 –> 00:00:21,760
دستور کار این جلسه نگاهی بیندازیم، من
7
00:00:21,760 –> 00:00:23,439
می خواهم توضیح دهم که دقیقاً چه چیزی
8
00:00:23,439 –> 00:00:26,320
اکتشافی است. تجزیه و تحلیل داده ها است و سپس ما
9
00:00:26,320 –> 00:00:28,480
به سمت کل هدف
10
00:00:28,480 –> 00:00:30,960
انجام eda بر روی هر مجموعه داده
11
00:00:30,960 –> 00:00:32,719
پیش می رویم، تمام
12
00:00:32,719 –> 00:00:34,320
مراحلی را که در کل
13
00:00:34,320 –> 00:00:37,280
فرآیند تجزیه و تحلیل داده های اکتشافی دخیل هستند را مورد بحث قرار
14
00:00:37,280 –> 00:00:39,520
می دهیم و در نهایت eda را بر روی یک
15
00:00:39,520 –> 00:00:40,960
مجموعه داده از
16
00:00:40,960 –> 00:00:42,160
من امیدوارم که اکنون بدون هیچ مقدمه ای
17
00:00:42,160 –> 00:00:43,280
دستور کار را روشن کرده
18
00:00:43,280 –> 00:00:45,440
باشید، بیایید
19
00:00:45,440 –> 00:00:46,559
جلسه خود را شروع کنیم،
20
00:00:46,559 –> 00:00:48,879
بنابراین آنچه دقیقاً
21
00:00:48,879 –> 00:00:50,079
تجزیه و تحلیل
22
00:00:50,079 –> 00:00:52,160
داده های اکتشافی است تجزیه و تحلیل داده های اکتشافی یا به زبان ساده
23
00:00:52,160 –> 00:00:54,640
می توانیم آن را به عنوان eda نیز نام ببریم، چیزی نیست
24
00:00:54,640 –> 00:00:56,719
جز یک تکنیک اکتشاف داده برای
25
00:00:56,719 –> 00:00:59,600
درک جنبه های مختلف
26
00:00:59,600 –> 00:01:01,359
داده شامل چندین تکنیک در یک
27
00:01:01,359 –> 00:01:04,159
توالی است که ما باید آنها را دنبال کنیم و خوب است
28
00:01:04,159 –> 00:01:05,760
که بعداً در جلسه با آن تکنیک ها آشنا خواهیم
29
00:01:05,760 –> 00:01:08,159
شد اما کل
30
00:01:08,159 –> 00:01:09,920
هدف یا کل هدف
31
00:01:09,920 –> 00:01:12,400
درک دادهها است و
32
00:01:12,400 –> 00:01:14,240
درک دادهها میتواند چیزهای زیادی باشد، زمانی که ما
33
00:01:14,240 –> 00:01:16,560
در حال کاوش در دادهها هستیم، بنابراین چیزهای کمی
34
00:01:16,560 –> 00:01:18,000
باید در حین کاوش دادهها در نظر داشته باشیم،
35
00:01:18,000 –> 00:01:20,080
مانند اینکه باید مطمئن شویم که
36
00:01:20,080 –> 00:01:22,320
دادهها درست هستند. تمیز است و هیچ
37
00:01:22,320 –> 00:01:24,400
افزونگی یا مقادیر مفقود یا حتی
38
00:01:24,400 –> 00:01:26,720
مقادیر تهی در مجموعه داده ندارد و
39
00:01:26,720 –> 00:01:28,400
باید مطمئن شویم که
40
00:01:28,400 –> 00:01:30,880
متغیرهای مهم در مجموعه داده را شناسایی کرده و
41
00:01:30,880 –> 00:01:32,799
تمام نویزهای غیر ضروری در
42
00:01:32,799 –> 00:01:34,960
داده ها را که ممکن است در واقع مانع از
43
00:01:34,960 –> 00:01:37,119
صحت نتیجهگیریهای خود را هنگامی که
44
00:01:37,119 –> 00:01:38,479
بر روی ساخت مدل کار
45
00:01:38,479 –> 00:01:40,640
میکنیم و باید رابطه
46
00:01:40,640 –> 00:01:43,280
بین متغیرها را از طریق eda درک کنیم و در
47
00:01:43,280 –> 00:01:44,960
آخر
48
00:01:44,960 –> 00:01:47,119
باید بتوانیم نتیجهگیری کنیم و
49
00:01:47,119 –> 00:01:49,360
بینشهایی درباره دادهها برای
50
00:01:49,360 –> 00:01:51,439
تفسیر قطعی جمعآوری کنیم تا به
51
00:01:51,439 –> 00:01:53,520
فرآیندهای پیچیدهتر برویم. در
52
00:01:53,520 –> 00:01:55,119
چرخه حیات پردازش داده،
53
00:01:55,119 –> 00:01:56,640
اکنون اجازه دهید
54
00:01:56,640 –> 00:01:59,759
هدف eda در اکتشاف داده را درک
55
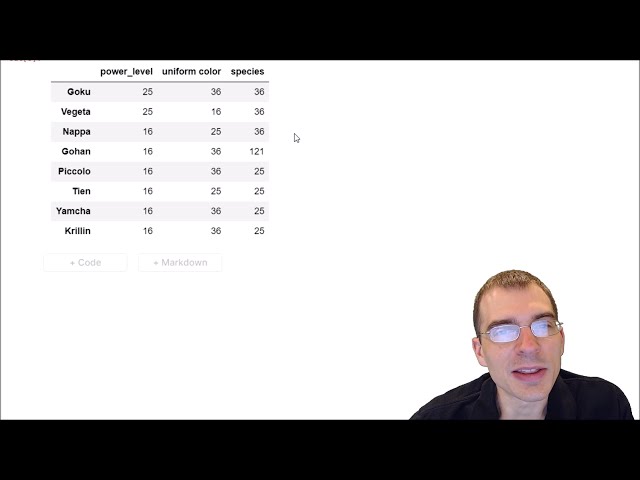
00:01:59,759 –> 00:02:02,399
کنیم، ایده اصلی این است که اطمینان حاصل کنیم
56
00:02:02,399 –> 00:02:04,880
که داده های پس از eda تمیز
57
00:02:04,880 –> 00:02:07,119
و تمیز است منظورم این است که داده ها باید
58
00:02:07,119 –> 00:02:08,878
عاری از همه وابستگی ها از جمله
59
00:02:08,878 –> 00:02:10,878
مقادیر null و همه آن چیزها
60
00:02:10,878 –> 00:02:12,720
باشند، بنابراین می توانیم آن را به دو
61
00:02:12,720 –> 00:02:15,040
هدف اصلی برای اجرای eda محدود کنیم،
62
00:02:15,040 –> 00:02:17,680
بنابراین هدف اول این است که eda به ما در شناسایی نقاط معیوب کمک می کند.
63
00:02:17,680 –> 00:02:19,760
در داده ها
64
00:02:19,760 –> 00:02:21,440
و اگر نقاط معیوب را شناسایی
65
00:02:21,440 –> 00:02:23,440
کرده اید، می توانید به راحتی آنها را حذف کرده
66
00:02:23,440 –> 00:02:25,280
و داده های خود را پاک کنید
67
00:02:25,280 –> 00:02:28,160
و هدف بعدی این است که eda به
68
00:02:28,160 –> 00:02:29,840
ما کمک کند تا رابطه بین متغیرها را درک کنیم
69
00:02:29,840 –> 00:02:32,239
که به ما
70
00:02:32,239 –> 00:02:34,879
دید وسیع تری از داده ها می دهد و
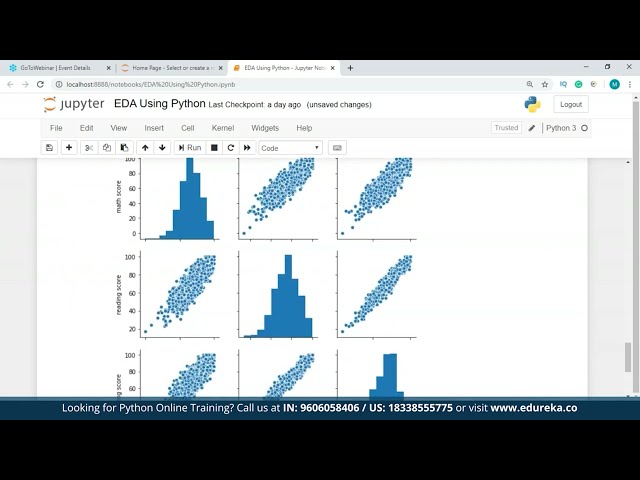
71
00:02:34,879 –> 00:02:36,640
در واقع به ما کمک می کند. با
72
00:02:36,640 –> 00:02:38,480
استفاده از رابطه بین متغیرها بر روی آن بسازید،
73
00:02:38,480 –> 00:02:39,760
74
00:02:39,760 –> 00:02:41,519
بنابراین اینها اهداف اصلی
75
00:02:41,519 –> 00:02:44,239
اجرای eda بر روی هر داده ای هستند،
76
00:02:44,239 –> 00:02:45,840
اکنون اجازه دهید
77
00:02:45,840 –> 00:02:48,160
به مراحل پیش برویم و نگاهی به مراحل مربوط به eda بیندازیم،
78
00:02:48,160 –> 00:02:50,000
بنابراین اینها مراحل اساسی هستند که
79
00:02:50,000 –> 00:02:52,319
درگیر هستند، بنابراین من فقط
80
00:02:52,319 –> 00:02:54,959
چند نکته اصلی را برجسته کنید، اگرچه مانند هر مرحله
81
00:02:54,959 –> 00:02:58,000
چندین ویژگی دیگر نیز وجود دارد، بنابراین
82
00:02:58,000 –> 00:02:59,519
ما
83
00:02:59,519 –> 00:03:01,680
در ابتدای کار روی راههای نمایشی
84
00:03:01,680 –> 00:03:03,840
و اولیه آنها را بررسی خواهیم کرد. مرحله این است
85
00:03:03,840 –> 00:03:06,239
که متغیرهای موجود در مجموعه داده را درک کنید،
86
00:03:06,239 –> 00:03:08,000
بنابراین باید کاملاً مطمئن باشید که
87
00:03:08,000 –> 00:03:09,760
چه نوع دادههایی
88
00:03:09,760 –> 00:03:11,760
روی متغیرهایی مانند تعداد ستونها و
89
00:03:11,760 –> 00:03:14,159
ردیفها کار میکنید و واقعاً چگونه به نظر میرسد، بنابراین
90
00:03:14,159 –> 00:03:15,920
این اولین قدم شما پس از آن است.
91
00:03:15,920 –> 00:03:17,760
بارگذاری داده ها در برنامه خود،
92
00:03:17,760 –> 00:03:19,840
سپس مرحله بعدی پاک کردن داده ها
93
00:03:19,840 –> 00:03:22,159
از افزونگی ها است، حالا افزونگی ها
94
00:03:22,159 –> 00:03:24,640
می توانند بی نظمی در داده ها باشند، می
95
00:03:24,640 –> 00:03:26,720
توانند برخی از متغیرها یا ستون هایی
96
00:03:26,720 –> 00:03:28,799
باشند که برای
97
00:03:28,799 –> 00:03:30,879
نتیجه گیری یا تفسیر ما ضروری نیستند، بنابراین ما می
98
00:03:30,879 –> 00:03:33,120
توانیم آنها را حذف کنیم. یا نقاط پرت وجود دارد
99
00:03:33,120 –> 00:03:36,319
که میتواند باعث ایجاد نویز در دادهها شود یا
100
00:03:36,319 –> 00:03:38,480
میدانید که ممکن است
101
00:03:38,480 –> 00:03:40,080
زمانی که ما روی ساختمان مدل کار میکنیم بیش از حد یا کمتر با مدل مطابقت
102
00:03:40,080 –> 00:03:42,239
داشته باشد، بنابراین این دومین
103
00:03:42,239 –> 00:03:43,920
قدمی است که بچهها باید دادهها را تمیز کنیم
104
00:03:43,920 –> 00:03:46,159
تا به جلو برویم. و در آخر
105
00:03:46,159 –> 00:03:47,920
ما باید رابطه بین متغیرها را تجزیه و تحلیل کنیم
106
00:03:47,920 –> 00:03:50,239
،
107
00:03:50,239 –> 00:03:52,319
بنابراین اجازه دهید به قسمت سرگرم کننده آن برویم،
108
00:03:52,319 –> 00:03:54,799
بنابراین کاری که اکنون انجام خواهم داد،
109
00:03:54,799 –> 00:03:56,480
به سمت نوت بوک مشتری می روم و روی
110
00:03:56,480 –> 00:03:58,720
یک نسخه نمایشی کار می کنیم. من قصد دارم یک مجموعه داده
111
00:03:58,720 –> 00:04:01,280
از kaggle بگیرم و eda را روی آن اجرا کنم، پس
112
00:04:01,280 –> 00:04:02,640
بیایید آن را به نوت بوک jupiter ببریم،
113
00:04:02,640 –> 00:04:03,680
بچه
114
00:04:03,680 –> 00:04:05,360
ها من قبلاً این نوت بوک را باز کرده ام
115
00:04:05,360 –> 00:04:07,680
و اگر قبلاً نمی دانید چگونه
116
00:04:07,680 –> 00:04:09,280
در نوت بوک jupiter کار کنید، ما یک دفترچه یادداشت
117
00:04:09,280 –> 00:04:11,280
کامل داریم. آموزش نحوه کار با
118
00:04:11,280 –> 00:04:12,879
نوت بوک jupyter می توانید آن را در صفحه یوتیوب ما پیدا کنید
119
00:04:12,879 –> 00:04:15,599
بچه ها و اگر هنوز
120
00:04:15,599 –> 00:04:17,600
به دنبال میانبر هستید مانند اگر می خواهید
121
00:04:17,600 –> 00:04:20,079
بفهمید واقعاً چگونه کار
122
00:04:20,079 –> 00:04:21,759
می کند ما یک برگه تقلب نیز داریم که می
123
00:04:21,759 –> 00:04:23,759
توانید به آن مراجعه کنید. کار در
124
00:04:23,759 –> 00:04:25,120
نوت بوک ژوپیتر و اگر به
125
00:04:25,120 –> 00:04:26,400
نصب و هر چیزی که ما داریم
126
00:04:26,400 –> 00:04:28,800
آموزش آناکوندا را نیز نگاه می کنید، بنابراین
127
00:04:28,800 –> 00:04:30,160
اولین کاری که باید انجام دهید این است
128
00:04:30,160 –> 00:04:31,600
که کتابخانه های خاصی را وارد کنید که به آنها
129
00:04:31,600 –> 00:04:34,560
نیاز دارید، بنابراین من پانداها را
130
00:04:34,560 –> 00:04:37,199
با نام مستعار pd من قصد دارم چند
131
00:04:37,199 –> 00:04:40,560
کتابخانه دیگر را وارد کنم که ممکن است به آنها نیاز داشته باشید،
132
00:04:40,560 –> 00:04:42,960
من می خواهم پیوند c را برای نمایش تصویری وارد کنم،
133
00:04:42,960 –> 00:04:44,560
زیرا ما
134
00:04:44,560 –> 00:04:46,000
رابطه
135
00:04:46,000 –> 00:04:47,440
بین متغیرها را تجسم خواهیم کرد، بنابراین برای آن
136
00:04:47,440 –> 00:04:49,040
استفاده خواهم کرد. c باند
137
00:04:49,040 –> 00:04:50,880
بنابراین من این PR را اجرا خواهم کرد ogram
138
00:04:50,880 –> 00:04:53,520
و این سلول در حال حاضر با موفقیت اجرا
139
00:04:53,520 –> 00:04:55,360
می شود، بچه ها مدتی طول می کشد، در
140
00:04:55,360 –> 00:04:56,720
141
00:04:56,720 –> 00:04:58,000
ضمن من فقط می خواهم به شما بگویم که
142
00:04:58,000 –> 00:05:00,000
چگونه می خواهیم به این موضوع نزدیک
143
00:05:00,000 –> 00:05:02,080
شویم.
144
00:05:02,080 –> 00:05:03,759
برای گرفتن این داده متغیر
145
00:05:03,759 –> 00:05:04,639
146
00:05:04,639 –> 00:05:07,280
و من از کتابخانه pandas استفاده می کنم، بنابراین
147
00:05:07,280 –> 00:05:11,720
اول از همه اولین قدم این است که
148
00:05:11,919 –> 00:05:15,360
من باید
149
00:05:15,919 –> 00:05:19,039
مجموعه داده های خود را وارد کنم بچه ها، بنابراین این مکان
150
00:05:19,039 –> 00:05:22,160
مجموعه داده های من است
151
00:05:23,199 –> 00:05:27,120
و نام مجموعه داده Students.csv است.
152
00:05:28,720 –> 00:05:31,720
153
00:05:32,080 –> 00:05:33,919
بسیار خوب، ما یک فایل خطا داریم که به درستی
154
00:05:33,919 –> 00:05:36,160
یافت نشد،
155
00:05:37,600 –> 00:05:39,280
بنابراین
156
00:05:39,280 –> 00:05:42,400
مجموعه داده های خود را با موفقیت وارد برنامه کردیم،
157
00:05:42,400 –> 00:05:44,160
بنابراین اولین قدم بعد از
158
00:05:44,160 –> 00:05:46,880
بارگیری داده ها در برنامه خود این است که باید
159
00:05:46,880 –> 00:05:49,280
با
160
00:05:49,280 –> 00:05:51,360
درک متغیرهای داخل داده، داده ها را درک کنید. من
161
00:05:51,360 –> 00:05:53,199
فقط آن را به عنوان اولین نام می
162
00:05:53,199 –> 00:05:56,560
163
00:05:58,479 –> 00:06:01,600
164
00:06:03,440 –> 00:06:04,639
165
00:06:04,639 –> 00:06:07,039
گذارم، بنابراین اولین قدم درک داده ها است و من می خواهم
166
00:06:07,039 –> 00:06:09,280
پنج ردیف اول داده های خود را بررسی کنم، بنابراین
167
00:06:09,280 –> 00:06:11,520
این داده های من
168
00:06:11,520 –> 00:06:14,240
169
00:06:14,240 –> 00:06:17,120
است. آمادگی آزمون ناهار آموزش و پرورش
170
00:06:17,120 –> 00:06:19,759
n نمره خواندن نمره ریاضی درس
171
00:06:19,759 –> 00:06:22,560
و آخرین نمره رایتینگ داریم،
172
00:06:22,560 –> 00:06:24,000
بنابراین این نمراتی هستند که با نگاه
173
00:06:24,000 –> 00:06:25,759
کردن به آن در مجموعه داده های ما مهم خواهند بود،
174
00:06:25,759 –> 00:06:27,440
می توانم به شما بگویم که
175
00:06:27,440 –> 00:06:29,600
این مقادیر هستند که
176
00:06:29,600 –> 00:06:31,440
هنگام کار بر روی هر یک از آنها بسیار مهم هستند. مدل
177
00:06:31,440 –> 00:06:33,840
یا فرضیات یا
178
00:06:33,840 –> 00:06:35,919
نتیجه گیری مانند جنسیت باید وجود داشته باشد
179
00:06:35,919 –> 00:06:37,919
زیرا تعیین کننده است که باید
180
00:06:37,919 –> 00:06:40,080
مرد یا زن باشد، بنابراین یک
181
00:06:40,080 –> 00:06:41,680
مقدار طبقه بندی است که
182
00:06:41,680 –> 00:06:43,600
ما در مجموعه داده های خود به آن نیاز خواهیم داشت، نژاد و
183
00:06:43,600 –> 00:06:45,759
قومیت ممکن است حذف شود.
184
00:06:45,759 –> 00:06:47,759
لزوماً متغیر بسیار مهمی در
185
00:06:47,759 –> 00:06:49,680
مجموعه دادههای ما و سطح تحصیلات والدین نیست،
186
00:06:49,680 –> 00:06:52,080
اگر
187
00:06:52,080 –> 00:06:53,919
مقادیر منحصربهفرد را بررسی کنیم و تصمیم بگیریم که این همان کاری است که
188
00:06:53,919 –> 00:06:55,520
میخواهیم انجام دهیم.
189
00:06:55,520 –> 00:06:57,919
190
00:06:57,919 –> 00:07:00,400
پنج ردیف آخر را نیز
191
00:07:00,400 –> 00:07:01,759
داریم، بنابراین ما همه این مقادیر را داریم که
192
00:07:01,759 –> 00:07:03,280
قبلاً به آنها نگاه کرده ایم، بنابراین یک چیز می
193
00:07:03,280 –> 00:07:05,199
توانید مطمئن شوید این است که از صفر شروع می شود
194
00:07:05,199 –> 00:07:07,520
و تا 999 ادامه می یابد.
195
00:07:07,520 –> 00:07:09,360
بنابراین فقط می توانیم بگوییم که ما
196
00:07:09,360 –> 00:07:11,840
هزار ورودی در این مجموعه داده داریم.
197
00:07:11,840 –> 00:07:14,160
بنابراین یک مجموعه داده خیلی بزرگ نیست، اما یک
198
00:07:14,160 –> 00:07:16,240
مجموعه داده نسبتاً کوچک
199
00:07:16,240 –> 00:07:17,120
200
00:07:17,120 –> 00:07:19,520
نیست، همچنین برای ما عالی است زیرا در حین
201
00:07:19,520 –> 00:07:21,199
انجام نمایش
202
00:07:21,199 –> 00:07:23,599
برای ما بسیار آسان خواهد بود،
203
00:07:23,599 –> 00:07:25,520
اکنون اجازه دهید شکل
204
00:07:25,520 –> 00:07:27,120
داده ها را نیز بررسی کنیم، بنابراین همه اینها هستند. مراحلی را
205
00:07:27,120 –> 00:07:30,160
که باید در حین کار درست دنبال کنید،
206
00:07:30,160 –> 00:07:31,599
207
00:07:31,599 –> 00:07:33,919
208
00:07:35,039 –> 00:07:37,120
بنابراین ما شکل را بررسی کرده ایم، بنابراین ما
209
00:07:37,120 –> 00:07:40,400
1000 ردیف و هشت ستون داریم،
210
00:07:40,400 –> 00:07:42,880
بگذارید فقط به چند نکته کلیدی دیگر نگاهی بیندازیم
211
00:07:42,880 –> 00:07:45,520
212
00:07:45,520 –> 00:07:48,080
وقتی از توصیف استفاده می کنید
213
00:07:48,080 –> 00:07:49,599
که فقط نمره ریاضی نمره خواندن را نشان می دهد.
214
00:07:49,599 –> 00:07:51,360
و نمره نوشتن
215
00:07:51,360 –> 00:07:53,360
چون همه متغیرهای دیگری که
216
00:07:53,360 –> 00:07:55,919
داریم اشیای رشته ای هستند فقط
217
00:07:55,919 –> 00:07:58,319
اشیاء عدد صحیح در اینجا نشان داده می شوند، بنابراین
218
00:07:58,319 –> 00:08:01,120
ما در اینجا یک تعداد مانند هزار
219
00:08:01,120 –> 00:08:02,800
داریم و یک مقدار متوسط داریم، ح
220
00:08:02,800 –> 00:08:04,800
اقل مقدار انحراف استاندارد و پن
221
00:08:04,800 –> 00:08:06,560
درصد پنجاه است. درصد هفتاد و پنج
222
00:08:06,560 –> 00:08:08,800
درصد و حداکثر مقدار و همچنین
223
00:08:08,800 –> 00:08:11,599
همانطور که می بینید برای همه این مقادیر 100
224
00:08:11,599 –> 00:08:14,560
نمره حداکثر است و حداقل
225
00:08:14,560 –> 00:08:17,520
نمره ریاضی که داریم 0 نمره خواندن 17 است و نمره
226
00:08:17,520 –> 00:08:19,680
نوشتن 17 re برابر 10 است. بنابراین
227
00:08:19,680 –> 00:08:21,599
می توانید تمام این مقادیر را فقط با روش توصیف دریافت کنید و
228
00:08:21,599 –> 00:08:24,560
سپس می توانید
229
00:08:24,560 –> 00:08:27,440
ستون ها و ردیف ها را به طور جداگانه بررسی کنید، بنابراین
230
00:08:27,440 –> 00:08:29,360
برای این کار فقط باید مانند
231
00:08:29,360 –> 00:08:30,319
232
00:08:30,319 –> 00:08:32,080
233
00:08:32,080 –> 00:08:33,360
ستون
234
00:08:33,360 –> 00:08:36,479
های نقطه داده بنویسید کاملاً قابل فراخوانی نیست
235
00:08:36,479 –> 00:08:38,880
بنابراین ما نژاد جنسیتی داریم. قومیت والدین
236
00:08:38,880 –> 00:08:41,120
سطح تحصیلات آزمون ناهار
237
00:08:41,120 –> 00:08:43,360
دوره آمادگی نمره ریاضی نمره خواندن
238
00:08:43,360 –> 00:08:45,200
و نمره نوشتن،
239
00:08:45,200 –> 00:08:47,360
بنابراین ما هیچکدام را کامل
240
00:08:47,360 –> 00:08:49,440
نکردیم بنابراین فقط n
241
00:08:49,440 –> 00:08:51,360
مقدار منحصر به فرد را بررسی می کنیم که چیزی جز
242
00:08:51,360 –> 00:08:53,519
تابعی نیست که یک سری با
243
00:08:53,519 –> 00:08:55,680
تعدادی مشاهدات متمایز را برمی گرداند.
244
00:08:55,680 –> 00:08:57,200
محور درخواستی،
245
00:08:57,200 –> 00:08:58,959
بنابراین اگر مقدار محور را
246
00:08:58,959 –> 00:09:00,480
صفر قرار دهیم، تعداد کل
247
00:09:00,480 –> 00:09:03,120
مشاهدات منحصربهفرد را روی محور شاخص پیدا میکند،
248
00:09:03,120 –> 00:09:05,360
بنابراین بیایید فقط مقادیر یکتا را بررسی
249
00:09:05,360 –> 00:09:06,560
کنیم
250
00:09:06,560 –> 00:09:08,160
، بچهها حالا چه خواهیم کرد،
251
00:09:08,160 –> 00:09:10,480
مقادیر یکتا را بررسی میکنیم. در دادههای ما،
252
00:09:10,480 –> 00:09:12,240
بچهها، من فقط از n منحصربهفرد استفاده میکنم و
253
00:09:12,240 –> 00:09:14,160
قبلاً به شما گفتهام که چه کاری انجام میدهد،
254
00:09:14,160 –> 00:09:15,920
بنابراین برای همه این ستونها
255
00:09:15,920 –> 00:09:17,760
مقادیر منحصربهفرد را به ما نشان میدهد، بنابراین برای جنسیت ما
256
00:09:17,760 –> 00:09:19,200
دو مقدار منحصر به فرد داریم که اساساً
257
00:09:19,200 –> 00:09:21,279
مرد است و زن برای نژاد و قومیت
258
00:09:21,279 –> 00:09:23,120
ما پنج ارزش داریم سطح
259
00:09:23,120 –> 00:09:25,279
تحصیلات والدین ما شش مقدار برای ناهار
260
00:09:25,279 –> 00:09:27,279
داریم دو مقدار برای دوره آمادگی آزمون
261
00:09:27,279 –> 00:09:29,200
داریم دو مقدار
262
00:09:29,200 –> 00:09:31,120
برای نمره ریاضی نمره خواندن و نمره نوشتن
263
00:09:31,120 –> 00:09:34,240
داریم ما چندین مقدار منحصر به فرد
264
00:09:34,240 –> 00:09:36,560
از صفر داریم تا 100، ما دارای
265
00:09:36,560 –> 00:09:39,200
77 مقدار منحصر به فرد برای نوشتن نمره
266
00:09:39,200 –> 00:09:40,800
برای خواندن هستیم که در آن همه موارد
267
00:09:40,800 –> 00:09:42,320
را داریم و اگر می خواهید به
268
00:09:42,320 –> 00:09:44,320
طور جداگانه برای هر ستونی بررسی کنید، فقط می توانید
269
00:09:44,320 –> 00:09:45,600
بنویسید فرض کنید
270
00:09:45,600 –> 00:09:46,640
جنسیت
271
00:09:46,640 –> 00:09:49,680
و ما فقط می توانیم منحصر به فرد بنویسیم و منحصر به فرد
272
00:09:49,680 –> 00:09:51,440
را به ما نشان می دهد. مقادیر
273
00:09:51,440 –> 00:09:53,279
داخل آن ستون بچه ها، بنابراین
274
00:09:53,279 –> 00:09:54,640
275
00:09:54,640 –> 00:09:56,320
اگر می خواهید بررسی کنید که مرد و زن است به طور مشابه اگر می خواهید بررسی کنید، فرض کنید
276
00:09:56,320 –> 00:10:00,000
برای نژاد و قومیت،
277
00:10:01,200 –> 00:10:03,120
می توانیم بررسی کنیم تا گروه b گروه c
278
00:10:03,120 –> 00:10:05,519
گروه a گروه d و گروه a
279
00:10:05,519 –> 00:10:07,760
برای سطح تحصیلات والدین داشته باشیم، همچنین می توانیم
280
00:10:07,760 –> 00:10:10,240
281
00:10:16,480 –> 00:10:18,000
همه را بررسی کنیم درست است، بنابراین ما مدرک کارشناسی داریم،
282
00:10:18,000 –> 00:10:19,680
برخی از کالجها، ما دارای مدرک کارشناسی ارشد، مقطع
283
00:10:19,680 –> 00:10:21,839
دبیرستان و تعدادی
284
00:10:21,839 –> 00:10:23,760
دبیرستان، بنابراین اینها همه ارزشهایی هستند
285
00:10:23,760 –> 00:10:25,760
که میتوانید فقط با نگاه کردن به
286
00:10:25,760 –> 00:10:27,920
دادهها متوجه شوید. o با نگاه کردن به این
287
00:10:27,920 –> 00:10:29,360
مقادیر منحصر به فرد، می توانم به شما بگویم که ما
288
00:10:29,360 –> 00:10:31,279
مقادیر طبقه بندی داریم، مانند
289
00:10:31,279 –> 00:10:33,920
ناهار و دستور کار دوره آماده سازی آزمون
290
00:10:33,920 –> 00:10:35,519
که می تواند به مقادیر ساختگی
291
00:10:35,519 –> 00:10:36,480
292
00:10:36,480 –> 00:10:38,000
از همه این مقادیر تبدیل شود، من
293
00:10:38,000 –> 00:10:39,920
فقط این سه را انتخاب می کنم که مطابقت دارند
294
00:10:39,920 –> 00:10:41,920
نمره خواندن و نمره نوشتن
295
00:10:41,920 –> 00:10:44,880
و آمادگی آزمون ناهار و جنسیت
296
00:10:44,880 –> 00:10:46,959
و موارد دیگر مانند قومیت و
297
00:10:46,959 –> 00:10:48,720
سطح تحصیلات نقاش را می توان
298
00:10:48,720 –> 00:10:50,399
حذف کرد زیرا اینها لزوماً
299
00:10:50,399 –> 00:10:52,640
متغیرهای بسیار مهمی در مجموعه داده ما نیستند و
300
00:10:52,640 –> 00:10:53,360
301
00:10:53,360 –> 00:10:55,120
اکنون به قسمت بعدی می رویم.
302
00:10:55,120 –> 00:10:57,760
eda که اساسا چیزی جز
303
00:10:57,760 –> 00:11:01,640
پاک کردن داده ها نیست،
304
00:11:02,000 –> 00:11:03,519
بنابراین اولین چیزی که
305
00:11:03,519 –> 00:11:05,680
به ذهن شما می رسد این است که مقادیر تهی
306
00:11:05,680 –> 00:11:08,000
داخل هر یک از اینها
307
00:11:08,000 –> 00:11:09,600
را بررسی کنید، زیرا ما فقط می توانیم
308
00:11:09,600 –> 00:11:11,120
309
00:11:11,120 –> 00:11:13,120
مقادیر تهی را بررسی
310
00:11:13,120 –> 00:11:16,240
کنیم و یک مجموع نیز در داخل این داده ها بدست آوریم.
311
00:11:16,240 –> 00:11:18,720
مجموعه ما مقادیر تهی صفر
312
00:11:18,720 –> 00:11:20,480
داریم، بنابراین لازم نیست نگران حذف
313
00:11:20,480 –> 00:11:22,399
هر ستونی صرفاً به دلیل وجود هیچ
314
00:11:22,399 –> 00:11:24,240
مقدار یا جایگزینی آن با مقادیر دیگر
315
00:11:24,240 –> 00:11:27,040
نباشیم، اما در برخی موارد در برخی از
316
00:11:27,040 –> 00:11:29,279
مجموعه های داده که نسبتاً بسیار بزرگ است،
317
00:11:29,279 –> 00:11:32,000
مثلاً اگر 7 000 یا 8 000 مقادیر
318
00:11:32,000 –> 00:11:34,240
دارید و اگر حتی دو درصد مقادیر تهی دارید
319
00:11:34,240 –> 00:11:36,079
یا مقدار از دست رفته در این
320
00:11:36,079 –> 00:11:38,079
مجموعه داده ها دارید، باید مطمئن
321
00:11:38,079 –> 00:11:40,640
باشید که اگر می خواهید آن
322
00:11:40,640 –> 00:11:42,959
مقادیر را دست نخورده بگذارید یا اگر می خواهید فقط
323
00:11:42,959 –> 00:11:45,120
آنها را رها کنیم یا مقادیری را از
324
00:11:45,120 –> 00:11:47,040
آنها جایگزین کنیم، بنابراین از آنجایی که ما هیچ مقدار تهی
325
00:11:47,040 –> 00:11:48,480
در داخل آن نداریم، به قسمت بعدی می رویم
326
00:11:48,480 –> 00:11:50,320
327
00:11:50,320 –> 00:11:52,800
که داده های اضافی را حذف می کند که
328
00:11:52,800 –> 00:11:55,200
لزوماً بر عملکرد ما در جدول تأثیر نمی گذارد.
329
00:11:55,200 –> 00:11:56,560
330
00:11:56,560 –> 00:11:58,399
بنابراین اکنون کاری که ما انجام خواهیم داد این است که
331
00:11:58,399 –> 00:12:00,160
چند ستون را که در واقع به آنها نیازی
332
00:12:00,160 –> 00:12:02,320
نداریم در مجموعه داده های خود حذف می کنیم، بنابراین نژاد، قومیت و سطح تحصیلات والدین را حذف می کنیم،
333
00:12:02,320 –> 00:12:04,160
334
00:12:04,160 –> 00:12:05,360
335
00:12:05,360 –> 00:12:06,880
بنابراین این دو مقدار هستند که من به آنها نیازی ندارم.
336
00:12:06,880 –> 00:12:08,720
در مجموعه روز من چون فکر میکنم اینها
337
00:12:08,720 –> 00:12:10,160
مقادیر مهمی برای هر
338
00:12:10,160 –> 00:12:12,560
ارزیابی نیستند، بنابراین فقط اینها را حذف کنید،
339
00:12:12,560 –> 00:12:14,160
بنابراین یک متغیر را انتخاب میکنم، مثلاً دانشآموز
340
00:12:14,160 –> 00:12:16,639
برابر با
341
00:12:16,639 –> 00:12:20,240
افت نقطه داده است و من
342
00:12:20,240 –> 00:12:22,800
343
00:12:23,200 –> 00:12:27,040
قومیت را افزایش میدهم، نام ستون را
344
00:12:27,040 –> 00:12:28,800
درست ارائه
345
00:12:28,800 –> 00:12:32,480
میکنم و ما سطح والدین را نمی خواهم
346
00:12:32,480 –> 00:12:35,839
آموزش
347
00:12:36,480 –> 00:12:37,519
و
348
00:12:37,519 –> 00:12:39,040
349
00:12:39,040 –> 00:12:41,279
دسترسی به آن برابر با 1 است
350
00:12:41,279 –> 00:12:43,920
در غیر این صورت یک خطا برای ما
351
00:12:43,920 –> 00:12:46,320
درست می کند، بنابراین وقتی
352
00:12:46,320 –> 00:12:48,720
به
353
00:12:50,839 –> 00:12:53,600
دانش آموز نگاه می کنم همه این مقادیر را
354
00:12:53,600 –> 00:12:55,519
داریم، جنسیت امتحان ناهار آماده سازی
355
00:12:55,519 –> 00:12:57,279
نمره مسابقه نمره خواندن و
356
00:12:57,279 –> 00:12:58,639
نمره نوشتن
357
00:12:58,639 –> 00:13:00,880
مرحله بعدی مانند بررسی
358
00:13:00,880 –> 00:13:02,720
اعداد پرت که لزوماً
359
00:13:02,720 –> 00:13:04,639
برای ما مشکلی ایجاد نمیکند، زیرا
360
00:13:04,639 –> 00:13:07,040
مجموعه دادههای کاملاً تمیزی داریم، بنابراین
361
00:13:07,040 –> 00:13:08,639
اگر میخواهید بیشتر در مورد اعداد پرت بدانید، میتوانید به دنبال اعداد پرت نیز باشید،
362
00:13:08,639 –> 00:13:10,720
من به شما خواهم گفت که
363
00:13:10,720 –> 00:13:12,560
اعداد پرت واقعاً چه هستند،
364
00:13:12,560 –> 00:13:14,639
بنابراین مقادیر پرت چیزی نیستند. اما در
365
00:13:14,639 –> 00:13:17,120
آمار، نقطه پرت یک نقطه داده ای است
366
00:13:17,120 –> 00:13:19,200
که به طور قابل توجهی با مشاهدات دیگر متفاوت است
367
00:13:19,200 –> 00:13:20,480
368
00:13:20,480 –> 00:13:22,079
، فرض کنید اگر یک نمره ریاضی دارید
369
00:13:22,079 –> 00:13:25,279
که 72 است، می دانید 69 و ناگهان
370
00:13:25,279 –> 00:13:27,760
فردی صفر و یک دارد، بنابراین ممکن
371
00:13:27,760 –> 00:13:31,200
است یک نقطه پرت و پرت باشد.
372
00:13:31,200 –> 00:13:33,360
به تغییرپذیری در اندازهگیری یا
373
00:13:33,360 –> 00:13:35,360
ممکن است نشاندهنده خطای آزمایشی باشد،
374
00:13:35,360 –> 00:13:37,519
بنابراین موارد دوم گاهی
375
00:13:37,519 –> 00:13:39,600
از مجموعه دادهها حذف میشوند،
376
00:13:39,600 –> 00:13:42,160
زیرا یک نقطه پرت در واقع میتواند
377
00:13:42,160 –> 00:13:44,399
مشکلات جدی در s ایجاد کند. تجزیه و تحلیل آماری،
378
00:13:44,399 –> 00:13:45,519
به همین دلیل است که ما باید به دنبال
379
00:13:45,519 –> 00:13:48,079
نقاط پرت باشیم و در این مجموعه داده ها
380
00:13:48,079 –> 00:13:49,680
لزوماً ما هیچ نقطه پرت
381
00:13:49,680 –> 00:13:51,680
نداریم، بنابراین ما آن را رها می کنیم و به
382
00:13:51,680 –> 00:13:53,199
مرحله سومی می رویم که داریم که
383
00:13:53,199 –> 00:13:55,600
اساسا چیزی نیست جز تجزیه و
384
00:13:55,600 –> 00:13:56,320
385
00:13:56,320 –> 00:13:58,160
تحلیل ما می توانیم آن را به عنوان
386
00:13:58,160 –> 00:13:59,519
تجزیه و تحلیل رابطه بنامیم،
387
00:13:59,519 –> 00:14:02,399
بنابراین من فقط آن را به عنوان سه علامت گذاری می کنم بسیار خوب، من
388
00:14:02,399 –> 00:14:04,360
فقط به عنوان
389
00:14:04,360 –> 00:14:07,519
تجزیه و تحلیل رابطه می نویسم
390
00:14:07,519 –> 00:14:09,279
اکنون کاری که ما انجام خواهیم داد این است که
391
00:14:09,279 –> 00:14:11,680
به چند معیار دیگر نگاهی بیندازیم، بنابراین اول از همه
392
00:14:11,680 –> 00:14:14,079
ما همبستگی داریم ماتریس
393
00:14:14,079 –> 00:14:16,480
و قبل از اینکه به
394
00:14:16,480 –> 00:14:18,880
تجزیه و تحلیل رابطه بپردازیم، امیدوارم همه چیز برای شما روشن باشد،
395
00:14:18,880 –> 00:14:21,279
مثل اینکه ما از
396
00:14:21,279 –> 00:14:22,320
بارگیری داده ها
397
00:14:22,320 –> 00:14:24,