در این مطلب، ویدئو ساختارهای داده در پایتون | ساختار داده ها و الگوریتم ها در پایتون | ادورکا | پایتون لایو – 5 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:34:30
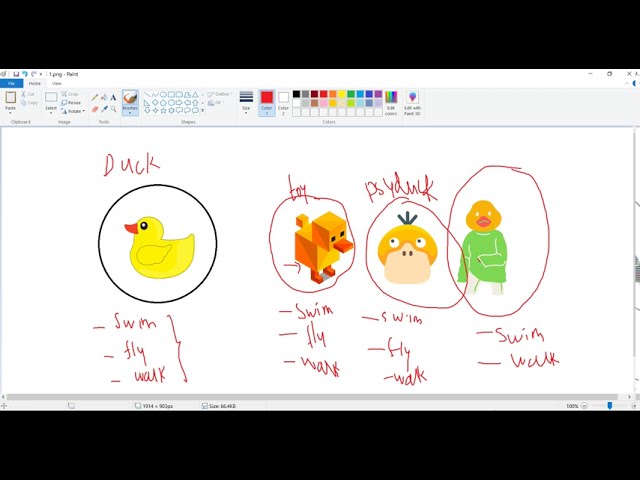
تصاویر این ویدئو:




قسمتی از زیرنویس این فیلم:
00:00:00,160 –> 00:00:02,800
بچه ها قبل از شروع
2
00:00:02,800 –> 00:00:04,720
جلسه می توانید لطفاً یک تأیید سریع به من بدهید
3
00:00:04,720 –> 00:00:06,960
اگر همه می توانید صفحه من را ببینید و من را
4
00:00:06,960 –> 00:00:10,880
بشنوید که در حال یادگیری k و همچنین
5
00:00:13,920 –> 00:00:15,440
کامل است. خیلی ممنون از
6
00:00:15,440 –> 00:00:17,359
تأیید همه،
7
00:00:17,359 –> 00:00:19,359
بنابراین نام من neeraj kedia است و من دارم
8
00:00:19,359 –> 00:00:21,520
اکنون بیش از 13 سال است که در صنعت سایت
9
00:00:21,520 –> 00:00:23,920
10
00:00:23,920 –> 00:00:25,920
کار می کنم، بنابراین دستور جلسه امروز اول
11
00:00:25,920 –> 00:00:27,599
از همه در مورد
12
00:00:27,599 –> 00:00:30,640
ساختارهای داده در پایتون بحث خواهیم کرد و دوباره
13
00:00:30,640 –> 00:00:32,399
ساختار داده این است که چگونه می توانیم با
14
00:00:32,399 –> 00:00:33,360
15
00:00:33,360 –> 00:00:35,760
ساختارهای داده داخلی کار کنیم و چگونه می توانیم می تواند با
16
00:00:35,760 –> 00:00:37,840
ساختارهای داده تعریف شده توسط کاربر کار کند
17
00:00:37,840 –> 00:00:39,760
و سپس در مورد
18
00:00:39,760 –> 00:00:41,440
الگوریتم ها در پایتون بحث می کنیم
19
00:00:41,440 –> 00:00:44,320
که دقیقاً چه الگوریتم هایی
20
00:00:44,320 –> 00:00:46,480
عناصر یک الگوریتم الگوریتم خوب هستند،
21
00:00:46,480 –> 00:00:50,000
الگوریتم های پیمایش درختی
22
00:00:50,000 –> 00:00:52,559
را طبقه بندی می کند، مرتب سازی همه الگوریتم ها
23
00:00:52,559 –> 00:00:54,719
و الگوریتم های جستجو را انجام می دهیم و سپس این
24
00:00:54,719 –> 00:00:57,760
کار را انجام می دهیم. تجزیه و تحلیل الگوریتم
25
00:00:57,760 –> 00:01:00,719
بسیار خوب است، بنابراین دانش ساختارهای داده
26
00:01:00,719 –> 00:01:02,239
و الگوریتم ها
27
00:01:02,239 –> 00:01:06,320
پایه ای را برای شناسایی برنامه نویسان تشکیل می
28
00:01:06,320 –> 00:01:08,799
دهد که دلیل دیگری برای دوباره
29
00:01:08,799 –> 00:01:09,360
شناختن
30
00:01:09,360 –> 00:01:12,000
پایتون به عنوان یک زبان و در حالی که
31
00:01:12,000 –> 00:01:13,119
ساختارهای داده به شرکت ها کمک می کند
32
00:01:13,119 –> 00:01:16,159
تا مطمئن شوند که می
33
00:01:16,159 –> 00:01:18,240
توانند الگوریتم های داده را بهتر سازماندهی کنند،
34
00:01:18,240 –> 00:01:20,400
به یافتن راه حل برای
35
00:01:20,400 –> 00:01:21,280
36
00:01:21,280 –> 00:01:24,240
مشکلات تجزیه و تحلیل داده ها کمک می کند، بنابراین اگر در
37
00:01:24,240 –> 00:01:26,159
مورد ساختارهای داده در پایتون صحبت
38
00:01:26,159 –> 00:01:28,159
کنیم، اول از همه آنها چندین
39
00:01:28,159 –> 00:01:30,320
نوع هستند. دادهها، انواع دادههای داخلی را
40
00:01:30,320 –> 00:01:31,119
41
00:01:31,119 –> 00:01:33,200
داریم و سپس انواع دادههای تعریفشده توسط کاربر را داریم،
42
00:01:33,200 –> 00:01:35,520
اکنون از نظر انواع دادههای داخلی
43
00:01:35,520 –> 00:01:37,520
،
44
00:01:37,520 –> 00:01:40,960
لغتنامهها و مجموعههای تاپل لیست داریم،
45
00:01:40,960 –> 00:01:43,600
بنابراین فهرستها برای ذخیره
46
00:01:43,600 –> 00:01:44,720
عناصر فهرستی استفاده میشوند
47
00:01:44,720 –> 00:01:46,799
که قابل تغییر هستند و میتوانند. شامل
48
00:01:46,799 –> 00:01:48,000
عبارتهای تکراری است،
49
00:01:48,000 –> 00:01:49,920
بنابراین در یک لیست داده شده میتوانیم چندین
50
00:01:49,920 –> 00:01:51,759
مورد تکراری داشته باشیم و به علاوه
51
00:01:51,759 –> 00:01:54,560
میتوانیم موارد فهرست را
52
00:01:54,560 –> 00:01:55,360
هر زمان
53
00:01:55,360 –> 00:01:57,840
که بخواهیم بهروزرسانی کنیم، سپس فرهنگهای لغتنامههایی داریم تا
54
00:01:57,840 –> 00:01:59,840
فرهنگهای لغت مانند
55
00:01:59,840 –> 00:02:01,840
جفتهای مقادیر کلیدی باشند که قابل تغییر هستند، به این
56
00:02:01,840 –> 00:02:03,600
معنی که میتوانیم آنها را در هر نقطه از آن تغییر دهیم.
57
00:02:03,600 –> 00:02:04,399
58
00:02:04,399 –> 00:02:07,439
پس از آن ما تاپل ها داریم، بنابراین تاپل ها غیرقابل تغییر هستند، به
59
00:02:07,439 –> 00:02:08,878
این معنی که ما غیرقابل تغییر در نظر گرفته می شویم،
60
00:02:08,878 –> 00:02:11,440
آنها نمی توانند
61
00:02:11,440 –> 00:02:12,000
62
00:02:12,000 –> 00:02:14,720
پس از اعلام آن تغییر کنند و
63
00:02:14,720 –> 00:02:16,720
حتی نمی توانند آن را داشته باشند. کپیهای تکراری
64
00:02:16,720 –> 00:02:19,760
و سپس مجموعههایی داریم، بنابراین مجموعهها مانند عناصر پیوسته هستند،
65
00:02:19,760 –> 00:02:20,879
66
00:02:20,879 –> 00:02:23,280
مانند عناصر منحصربهفرد نامرتب که
67
00:02:23,280 –> 00:02:25,200
تغییرناپذیر هستند، یعنی
68
00:02:25,200 –> 00:02:27,120
در اینجا باید همه عناصر
69
00:02:27,120 –> 00:02:28,560
منحصربهفرد باشند و نمیتوان آنها را
70
00:02:28,560 –> 00:02:29,520
تکرار کرد
71
00:02:29,520 –> 00:02:31,599
و میتوان آنها را در زمان بعدی تغییر داد.
72
00:02:31,599 –> 00:02:32,800
73
00:02:32,800 –> 00:02:35,280
و سپس اگر در مورد
74
00:02:35,280 –> 00:02:36,879
ساختار داده تعریف شده توسط کاربر صحبت کنیم،
75
00:02:36,879 –> 00:02:39,920
76
00:02:39,920 –> 00:02:43,440
نمودار فهرست پیوندی درخت صف پشته و نقشه هش داریم، بنابراین
77
00:02:43,440 –> 00:02:46,480
برای شروع، ما پشته داریم، بنابراین
78
00:02:46,480 –> 00:02:49,599
پشته ها مانند آخرین ساختار داده خطی هستند،
79
00:02:49,599 –> 00:02:52,720
بنابراین اساساً
80
00:02:52,720 –> 00:02:53,200
81
00:02:53,200 –> 00:02:54,720
اگر عناصر به آخرین به روز رسانی شده
82
00:02:54,720 –> 00:02:56,640
است، قرار است به
83
00:02:56,640 –> 00:02:57,360
84
00:02:57,360 –> 00:02:59,519
عنوان یک معماری برگ، ابتدا به عنوان یک آخرین در ابتدا به بیرون فشار داده شود،
85
00:02:59,519 –> 00:03:00,640
86
00:03:00,640 –> 00:03:03,360
سپس صف داریم، سپس در اینجا صف داریم،
87
00:03:03,360 –> 00:03:04,720
بنابراین صف ها
88
00:03:04,720 –> 00:03:07,760
مانند اول خطی در خانه اول یا عنصر داده هستند
89
00:03:07,760 –> 00:03:10,000
که ابتدا معرفی شد
90
00:03:10,000 –> 00:03:12,080
که برای اولین بار
91
00:03:12,080 –> 00:03:14,239
دوباره زمانی که اکسل اتفاق میافتد از آن خارج میشود و به این صورت است
92
00:03:14,239 –> 00:03:16,159
که در قسمت fifa ابتدا در
93
00:03:16,159 –> 00:03:16,560
ابتدا کار
94
00:03:16,560 –> 00:03:20,080
میکند، سپس درختهایی داریم، بنابراین درختها مانند
95
00:03:20,080 –> 00:03:22,640
ساختار داده غیرخطی هستند. یک ریشه
96
00:03:22,640 –> 00:03:24,239
و یک no تعریف شده است،
97
00:03:24,239 –> 00:03:26,560
پس ما لیست پیوندی داریم، بنابراین
98
00:03:26,560 –> 00:03:28,480
لیست های پیشرو در اصطلاح عناصر ساده هستند، آنها
99
00:03:28,480 –> 00:03:28,879
100
00:03:28,879 –> 00:03:30,840
ساختارهای داده ای هستند که با اشاره گرها پیوند دارند،
101
00:03:30,840 –> 00:03:32,000
102
00:03:32,000 –> 00:03:34,640
سپس ما گراف داریم، بنابراین نمودارها شامل
103
00:03:34,640 –> 00:03:35,840
مجموعه ای از نقاط
104
00:03:35,840 –> 00:03:39,200
یا گره ها به همراه یال ها هستند و سپس
105
00:03:39,200 –> 00:03:40,640
نقشه های هش داریم.
106
00:03:40,640 –> 00:03:43,519
بنابراین اساساً آنها مانند
107
00:03:43,519 –> 00:03:45,680
دیکشنری ها هستند، اگر سناریوی پایتون را درست در نظر بگیرید،
108
00:03:45,680 –> 00:03:47,680
109
00:03:47,680 –> 00:03:50,879
بنابراین اکنون باید در
110
00:03:50,879 –> 00:03:54,239
مورد مفهوم ساختارهای داده داخلی بحث کنیم
111
00:03:54,239 –> 00:03:57,200
که چگونه آنها پیکربندی می شوند، بنابراین در اینجا ما
112
00:03:57,200 –> 00:03:59,519
دیکشنری داریم، مجموعه هایی داریم که تاپل ها داریم
113
00:03:59,519 –> 00:04:00,879
و سپس ما لیستی
114
00:04:00,879 –> 00:04:03,439
داریم، بنابراین دوباره درباره این لیست بحث کردیم،
115
00:04:03,439 –> 00:04:05,439
آنها می توانند حاوی داده های هندریجین باشند و
116
00:04:05,439 –> 00:04:07,040
قابل تغییر هستند، به این معنی
117
00:04:07,040 –> 00:04:09,280
که می توان آنها را تغییر
118
00:04:09,280 –> 00:04:11,200
داد.
119
00:04:11,200 –> 00:04:13,680
120
00:04:13,680 –> 00:04:15,599
121
00:04:15,599 –> 00:04:17,759
همانطور که این، اما دوباره آنها
122
00:04:17,759 –> 00:04:19,680
قابل تغییر نیستند، یعنی ما نمی توانیم
123
00:04:19,680 –> 00:04:20,880
آن را تغییر دهیم
124
00:04:20,880 –> 00:04:23,520
و سپس مجموعه هایی داریم و آنها
125
00:04:23,520 –> 00:04:25,040
مجموعه ای نامرتب از
126
00:04:25,040 –> 00:04:27,759
عناصر منحصر به فرد هستند و آنها قابل تغییر هستند،
127
00:04:27,759 –> 00:04:30,639
یعنی ما c آنها را تغییر دهید،
128
00:04:30,639 –> 00:04:33,840
سپس ساختار داده تعریف شده توسط کاربر داریم، ساختارهای داده تعریف شده توسط کاربر
129
00:04:33,840 –> 00:04:36,080
داریم،
130
00:04:36,080 –> 00:04:38,639
مانند لیست های پیوندی، نمودارها،
131
00:04:38,639 –> 00:04:39,440
نقشه های
132
00:04:39,440 –> 00:04:42,479
درختان، صف ها و پشته هایی که در
133
00:04:42,479 –> 00:04:43,600
مورد این مؤلفه ها
134
00:04:43,600 –> 00:04:47,199
به طور مفصل بحث می کنیم، بنابراین اکنون اجازه دهید در مورد
135
00:04:47,199 –> 00:04:50,960
الگوریتم ها در پایتون بحث کنیم، بنابراین الگوریتم ها چیست.
136
00:04:50,960 –> 00:04:53,040
الگوریتمها اساساً یک
137
00:04:53,040 –> 00:04:54,160
قانون یا
138
00:04:54,160 –> 00:04:56,240
مجموعهای از دستورالعملها هستند که
139
00:04:56,240 –> 00:04:58,880
برای تکمیل یک کار معین باید دنبال شوند، به
140
00:04:58,880 –> 00:05:00,479
عنوان مثال اگر راههای متعددی برای تکمیل یک کار وجود دارد،
141
00:05:00,479 –> 00:05:01,840
142
00:05:01,840 –> 00:05:04,160
بهترین مسیر باید کدام باشد، در
143
00:05:04,160 –> 00:05:04,880
144
00:05:04,880 –> 00:05:07,360
مقابل اگر یک شرط هستند، آن شرایط چگونه
145
00:05:07,360 –> 00:05:09,199
است.
146
00:05:09,199 –> 00:05:11,680
باید دوباره اعمال شود، این همه چیز
147
00:05:11,680 –> 00:05:13,840
به عنوان بخشی از الگوریتم به خوبی تعریف شده
148
00:05:13,840 –> 00:05:17,120
است، بنابراین برای یافتن
149
00:05:17,120 –> 00:05:19,280
کد مطمئن برای هر مسئله ای استفاده می شود، به
150
00:05:19,280 –> 00:05:21,280
عنوان مثال اگر در حال نوشتن یک مسئله هستیم، به
151
00:05:21,280 –> 00:05:23,759
عنوان مثال همان مفهومی که ممکن است
152
00:05:23,759 –> 00:05:25,520
در گذشته یاد گرفته باشید. روزهای مدرسه که
153
00:05:25,520 –> 00:05:27,360
در مورد فلوچارت نیز یاد میگرفتیم،
154
00:05:27,360 –> 00:05:28,080
155
00:05:28,080 –> 00:05:30,240
بنابراین اگر در مورد ایجاد
156
00:05:30,240 –> 00:05:31,919
نمودار جریان برای مثلاً تهیه چای صحبت کنیم،
157
00:05:31,919 –> 00:05:33,280
باید آن را بجوشانیم.
158
00:05:33,280 –> 00:05:35,520
اگر آب شروع به جوشیدن کرد، اگر آب شروع به
159
00:05:35,520 –> 00:05:36,960
جوشیدن کرد، باید برگ های چای را اضافه کنیم
160
00:05:36,960 –> 00:05:37,360
،
161
00:05:37,360 –> 00:05:39,520
اگر اینطور نیست، باید چند ثانیه به جوشیدن ادامه دهیم،
162
00:05:39,520 –> 00:05:41,360
163
00:05:41,360 –> 00:05:44,720
بنابراین منطقی است که
164
00:05:44,720 –> 00:05:47,039
بر اساس انتخاب های داده شده در چه مقطع زمانی باید اعمال شود.
165
00:05:47,039 –> 00:05:48,400
166
00:05:48,400 –> 00:05:51,440
پس این همان چیزی است که ما در اینجا به عنوان الگوریتم از
167
00:05:51,440 –> 00:05:53,520
آن یاد می کنیم، همان چیزی است که به عنوان الگوریتم معرفی می
168
00:05:53,520 –> 00:05:56,240
شود و به کدام قسمت
169
00:05:56,240 –> 00:05:57,199
اشاره می کنیم
170
00:05:57,199 –> 00:06:00,639
و اگر دوباره در مورد
171
00:06:00,639 –> 00:06:02,400
ساختار الگوریتم صحبت کنیم،
172
00:06:02,400 –> 00:06:03,840
باید کارآمدترین
173
00:06:03,840 –> 00:06:06,240
منطق باشد و اساساً کد شبه
174
00:06:06,240 –> 00:06:09,039
مشکلات را می دهند و سپس می توان آن ها را
175
00:06:09,039 –> 00:06:12,000
در چندین زبان پیاده سازی کرد زیرا
176
00:06:12,000 –> 00:06:12,479
177
00:06:12,479 –> 00:06:15,360
زبان خاصی نیستند، بنابراین در اینجا باید
178
00:06:15,360 –> 00:06:16,880
179
00:06:16,880 –> 00:06:18,960
ابتدا مشکل را مشخص کنیم که دقیقاً
180
00:06:18,960 –> 00:06:20,000
مشکل ما چیست، بنابراین
181
00:06:20,000 –> 00:06:22,319
الگوریتم ها معمولاً به عنوان
182
00:06:22,319 –> 00:06:24,000
ترکیبی از
183
00:06:24,000 –> 00:06:27,360
زبان قابل فهم توسط کاربر و برخی از
184
00:06:27,360 –> 00:06:28,800
زبان های برنامه نویسی رایج
185
00:06:28,800 –> 00:06:30,720
در حال حاضر معمولاً نوشته می شوند.
186
00:06:30,720 –> 00:06:32,240
با این حال
187
00:06:32,240 –> 00:06:35,120
، همیشه لازم نیست این کار را انجام دهید، بنابراین
188
00:06:35,120 –> 00:06:37,440
قوانین مشخصی برای فرمولبندی
189
00:06:37,440 –> 00:06:39,520
الگوریتمها وجود ندارد، اما باید موارد زیر را حفظ کنیم.
190
00:06:39,520 –> 00:06:40,240
191
00:06:40,240 –> 00:06:42,000
نشانگرهایی را در ذهن داشته باشیم که می توانیم روی
192
00:06:42,000 –> 00:06:44,160
صفحه نمایش ببینیم، بنابراین ابتدا باید
193
00:06:44,160 –> 00:06:44,560
194
00:06:44,560 –> 00:06:47,199
بفهمیم که دقیقاً چه مشکلی وجود دارد،
195
00:06:47,199 –> 00:06:49,039
سپس باید مشخص می
196
00:06:49,039 –> 00:06:50,000
کردیم که آیا
197
00:06:50,000 –> 00:06:52,720
دقیقاً باید از کجا شروع کنیم یا خیر و سپس
198
00:06:52,720 –> 00:06:54,080
باید
199
00:06:54,080 –> 00:06:56,400
در مورد آن فکر کنیم. جایی که باید متوقف شویم زیرا
200
00:06:56,400 –> 00:06:57,199
201
00:06:57,199 –> 00:06:59,680
شروع و توقف هر دو مورد نیاز است
202
00:06:59,680 –> 00:07:01,280
و سپس باید
203
00:07:01,280 –> 00:07:03,440
مراحلی را که قرار است
204
00:07:03,440 –> 00:07:04,639
205
00:07:04,639 –> 00:07:06,880
در آینده نزدیک انجام شود به عنوان بخشی از پاسخ فرموله
206
00:07:06,880 –> 00:07:08,479
میکردیم و سپس باید
207
00:07:08,479 –> 00:07:10,800
مراحل خود را نیز مرور کنیم.
208
00:07:10,800 –> 00:07:12,560
فرض کنید ما یک
209
00:07:12,560 –> 00:07:15,840
الگوریتم ساده و پاپ فرمولنویس داشتیم تا بررسی کنیم
210
00:07:15,840 –> 00:07:17,840
دانشآموز امتحان را قبول کرده است یا خیر،
211
00:07:17,840 –> 00:07:20,160
بنابراین در اینجا میتوانیم
212
00:07:20,160 –> 00:07:22,000
الگوریتم چند مرحلهای ایجاد کنیم، بنابراین در اینجا میتوانیم شروع کنیم،
213
00:07:22,000 –> 00:07:23,599
میتوانیم دو متغیر را اعلام کنیم
214
00:07:23,599 –> 00:07:25,199
و سپس میتوانیم نمرات را ذخیره کنیم و به
215
00:07:25,199 –> 00:07:26,960
دست آوریم. توسط x
216
00:07:26,960 –> 00:07:28,400
و سپس میتوانیم حداقل
217
00:07:28,400 –> 00:07:30,080
نمره قبولی را در y ذخیره کنیم
218
00:07:30,080 –> 00:07:32,639
و سپس میتوانیم بررسی کنیم که آیا x بزرگتر از y است یا خیر،
219
00:07:32,639 –> 00:07:33,599
220
00:07:33,599 –> 00:07:35,919
دانشآموز قبول کرده است، در غیر این
221
00:07:35,919 –> 00:07:37,840
صورت توزیع به سادگی شکست خورده است
222
00:07:37,840 –> 00:07:40,560
و اکنون باید اجرا را نیز متوقف کنیم،
223
00:07:40,560 –> 00:07:41,520
224
00:07:41,520 –> 00:07:43,599
بنابراین اگر میخواهید ما میتوانیم این مثال را نیز دستکاری کنیم،
225
00:07:43,599 –> 00:07:44,720
226
00:07:44,720 –> 00:07:46,319
مثلاً فرض کنید میخواهیم
227
00:07:46,319 –> 00:07:48,000
مقادیر را به متغیرها
228
00:07:48,000 –> 00:07:49,919
در مرحله دو اختصاص دهیم، برای مثال فرض کنید
229
00:07:49,919 –> 00:07:52,160
در اینجا باید چندین متغیر را
230
00:07:52,160 –> 00:07:54,160
برای تجزیه و شکست پیدا کنیم، بنابراین شما میتوانید
231
00:07:54,160 –> 00:07:56,080
چندین متغیر را تعریف کنید
232
00:07:56,080 –> 00:07:58,240
و سپس میتوانیم همچنین با استفاده از منطق
233
00:07:58,240 –> 00:08:01,360
خودمان،
234
00:08:01,360 –> 00:08:04,639
بسته به نیاز میتوانیم درصد و غیره را پیدا کنیم،
235
00:08:04,639 –> 00:08:07,360
بنابراین اگر در مورد الگوریتمهای خوب
236
00:08:07,360 –> 00:08:08,960
صحبت میکنیم، بنابراین اگر در مورد عناصر یک الگوریتم خوب صحبت میکنیم، قبل از هر
237
00:08:08,960 –> 00:08:10,080
چیز
238
00:08:10,080 –> 00:08:13,199
چندین مرحله وجود دارد که
239
00:08:13,199 –> 00:08:16,080
باید متناهی و واضح باشد.
240
00:08:16,080 –> 00:08:17,680
قابل درک است که به این معنی است که
241
00:08:17,680 –> 00:08:19,599
نباید هیچ نوع مغایرتی
242
00:08:19,599 –> 00:08:20,879
وجود داشته باشد به علاوه نباید هیچ نوع سردرگمی وجود داشته باشد،
243
00:08:20,879 –> 00:08:22,080
244
00:08:22,080 –> 00:08:24,400
اما آنچه باید انجام شود و همچنین
245
00:08:24,400 –> 00:08:25,680
به چه روشی
246
00:08:25,680 –> 00:08:27,599
بنابراین کل ساختار الگوریتم باید
247
00:08:27,599 –> 00:08:28,720
248
00:08:28,720 –> 00:08:31,039
واضح باشد، نباید هیچ نوع
249
00:08:31,039 –> 00:08:31,759
سردرگمی در
250
00:08:31,759 –> 00:08:34,159
مورد آنچه انجام شود وجود داشته باشد. باید انجام شود و آنچه باید
251
00:08:34,159 –> 00:08:35,679
از آن اجتناب شود باید برای همه کاملاً
252
00:08:35,679 –> 00:08:36,080
روشن باشد
253
00:08:36,080 –> 00:08:38,719
سپس باید
254
00:08:38,719 –> 00:08:40,799
توصیفی واضح و دقیق از
255
00:08:40,799 –> 00:08:43,519
ورودی و خروجی وجود داشته باشد تا در باید
256
00:08:43,519 –> 00:08:46,000
ورودی از کاربران نهایی باشد و ما
257
00:08:46,000 –> 00:08:48,560
چه چیزی خروجی داریم که انتظار داریم و
258
00:08:48,560 –> 00:08:50,560
هر مرحله باید خروجی تعریف شده ای داشته باشد
259
00:08:50,560 –> 00:08:52,560
که فقط به ورودی بستگی دارد
260
00:08:52,560 –> 00:08:57,279
و در آن مرحله مراحل قبل هستند
261
00:08:57,279 –> 00:08:58,880
و سپس الگوریتم باید به
262
00:08:58,880 –> 00:09:00,959
اندازه کافی انعطاف پذیر باشد تا
263
00:09:00,959 –> 00:09:02,880
آن را به منظور اجازه دادن به تعدادی
264
00:09:02,880 –> 00:09:04,800
راه حل قالب کنید و
265
00:09:04,800 –> 00:09:06,240
این مراحل باید از
266
00:09:06,240 –> 00:09:08,000
اصول کلی برنامه نویسی باشد
267
00:09:08,000 –> 00:09:10,080
و نباید به زبان خاصی اختصاص داشته باشد،
268
00:09:10,080 –> 00:09:11,839
269
00:09:11,839 –> 00:09:13,519
بنابراین اگر در مورد کلاس های الگوریتم صحبت کنیم،
270
00:09:13,519 –> 00:09:16,560
اول از همه تقسیم کنید
271
00:09:16,560 –> 00:09:18,959
و غلبه کنید سپس پویا خواهیم داشت.
272
00:09:18,959 –> 00:09:20,399
برنامه نویسی
273
00:09:20,399 –> 00:09:23,120
سپس الگوریتم های حریصانه داریم، بنابراین
274
00:09:23,120 –> 00:09:24,880
همه اینها انواع مختلفی از
275
00:09:24,880 –> 00:09:27,440
کلاس های الگوریتم هستند، بنابراین اول از همه
276
00:09:27,440 –> 00:09:29,519
تقسیم و غلبه کنید بنابراین
277
00:09:29,519 –> 00:09:31,279
به سادگی
278
00:09:31,279 –> 00:09:32,959
مسئله را به عبارات فرعی تقسیم می کنیم، به
279
00:09:32,959 –> 00:09:34,640
عنوان مثال ما یک مشکل بزرگ
280
00:09:34,640 –> 00:09:36,800
داریم، بنابراین می توانیم آن را
281
00:09:36,800 –> 00:09:38,800
به فرض تقسیم کنیم. کامپوننت کوچکتر و سپس
282
00:09:38,800 –> 00:09:40,320
ما می توانیم آن
283
00:09:40,320 –> 00:09:41,920
اجزای کوچکتر را یکی یکی حل کنیم
284
00:09:41,920 –> 00:09:43,360
و اگر قرار است همه اجزای
285
00:09:43,360 –> 00:09:45,600
کوچکتر حل شوند، کل مشکل من
286
00:09:45,600 –> 00:09:48,399
درست نیز حل خواهد شد،
287
00:09:48,399 –> 00:09:51,040
بنابراین در اینجا میتوانیم کل
288
00:09:51,040 –> 00:09:51,920
مشکل بزرگ را به
289
00:09:51,920 –> 00:09:53,600
عبارات کوچکتر بدهیم و سپس میتوانیم
290
00:09:53,600 –> 00:09:54,959
روی آن کار کنیم
291
00:09:54,959 –> 00:09:57,120
و سپس برنامهنویسی پویا را داریم،
292
00:09:57,120 –> 00:09:58,959
بنابراین در اینجا میتوانیم مسئله را
293
00:09:58,959 –> 00:10:00,080
294
00:10:00,080 –> 00:10:03,120
به بخشهای فرعی تقسیم کنیم و نتیجه را به خاطر بسپاریم. بخش های فرعی و
295
00:10:03,120 –> 00:10:05,360
ما قصد داریم آن را روی موارد مشابه اعمال کنیم،
296
00:10:05,360 –> 00:10:06,959
بنابراین در اینجا می توانیم سعی کنیم یک
297
00:10:06,959 –> 00:10:08,399
الگو را نیز پیدا کنیم
298
00:10:08,399 –> 00:10:11,040
و سپس الگوریتم حریص را داریم، بنابراین
299
00:10:11,040 –> 00:10:11,839
300
00:10:11,839 –> 00:10:14,720
آسان ترین مراحل را در حین
301
00:10:14,720 –> 00:10:15,920
حل یک مسئله
302
00:10:15,920 –> 00:10:18,079
بدون نگرانی از پیچیدگی
303
00:10:18,079 –> 00:10:19,360
مراحل بعدی فراخوانی می کند.
304
00:10:19,360 –> 00:10:22,640
بنابراین در اینجا هدف ما این است که کل
305
00:10:22,640 –> 00:10:25,279
عبارت را آماده و اجرا کنیم و سپس میتوانیم
306
00:10:25,279 –> 00:10:27,920
روی اصلاح مسائل یا
307
00:10:27,920 –> 00:10:29,200
کار بیشتر روی
308
00:10:29,200 –> 00:10:30,720
هدایت دادههای فعلی که
309
00:10:30,720 –> 00:10:33,839
قبلاً به آنها دسترسی داریم کار کنیم
310
00:10:34,079 –> 00:10:36,720
تا با این ساختار داده
311
00:10:36,720 –> 00:10:38,800
و الگوریتمهای موجود در پایتون پیش برویم.
312
00:10:38,800 –> 00:10:41,600
اکنون می خواهیم در مورد پیمایش آزاد
313
00:10:41,600 –> 00:10:42,480
314
00:10:42,480 –> 00:10:45,279
در الگوریتم های جستجو و همچنین
315
00:10:45,279 –> 00:10:46,720
الگوریتم های مرتب سازی
316
00:10:46,720 –> 00:10:51,519
مورد استفاده بحث کنیم، بنابراین اکنون می خواهیم در
317
00:10:51,519 –> 00:10:53,839
مورد الگوریتم سلول سفر درختی بحث کنیم.
318
00:10:53,839 –> 00:10:56,560
اساساً درختها در پایتون
319
00:10:56,560 –> 00:10:58,959
ساختارهای داده غیرخطی دارند
320
00:10:58,959 –> 00:11:02,720
که دارای ریشه و گرهها هستند، همانطور
321
00:11:02,720 –> 00:11:05,680
که در
322
00:11:05,680 –> 00:11:06,320
این
323
00:11:06,320 –> 00:11:10,320
نمودار فعلی مشاهده کردیم، بنابراین اساساً بر اساس
324
00:11:10,320 –> 00:11:10,959
325
00:11:10,959 –> 00:11:13,440
ترتیب بازدید از گرهها میتوانند
326
00:11:13,440 –> 00:11:14,160
سه
327
00:11:14,160 –> 00:11:17,760
نوع پیمایش درختی باشند، بنابراین اساساً ما در
328
00:11:17,760 –> 00:11:19,120
اینجا سه نوع داشته باشید همانطور که می بینید ما سه
329
00:11:19,120 –> 00:11:20,959
وع داریم که به ترتیب پیش سفارش و س
330
00:11:20,959 –> 00:11:22,399
ارش پست داریم پس اول از همه بیایید یک کار را ان
331
00:11:22,399 –> 00:11:24,480
ام دهیم بیایید با ترتیب شروع کنیم پی
332
00:11:24,480 –> 00:11:27,680
ایش بسیار نامفهوم به پی
333
00:11:27,680 –> 00:11:30,160
ایش درخت به گونه ای اشاره دارد که ما
334
00:11:30,160 –> 00:11:30,959
ب
335
00:11:30,959 –> 00:11:33,200
دا از گره های چپ به دنبال
336
00:11:33,200 –> 00:11:35,600
ریشه و سپس گره های راست بازدید کنید،
337
00:11:35,600 –> 00:11:37,839
بنابراین پیمایش خود را به شکل
338
00:11:37,839 –> 00:11:39,279
از تمام گره های ساختار سمت چپ
339
00:11:39,279 –> 00:11:40,320
340
00:11:40,320 –> 00:11:42,959
شروع می کنیم و سپس به سمت ریشه و
341
00:11:42,959 –> 00:11:45,519
سپس در نهایت به سمت درخت حرکت
342
00:11:45,519 –> 00:11:47,279
می کنیم.
343
00:11:47,279 –> 00:11:49,680
پیمایش سفارش اول از همه در اینجا کار میکند، ما
344
00:11:49,680 –> 00:11:52,399
345
00:11:52,399 –> 00:11:54,240
دوباره با گرههای چپ شروع میکنیم و سپس با
346
00:11:54,240 –> 00:11:56,320
ریشه در گرههای راست دنبال میکنیم و سپس
347
00:11:56,320 –> 00:11:56,959
348
00:11:56,959 –> 00:11:58,880
میخواهیم دو راهاندازی خود را از گرههای
349
00:11:58,880 –> 00:12:00,399
موجود در le بیاوریم. ft sub tree و سپس به سمت ریشه حرکت می کنیم
350
00:12:00,399 –> 00:12:01,440
351
00:12:01,440 –> 00:12:03,680
و در نهایت زیردرخت سمت راست به
352
00:12:03,680 –> 00:12:06,560
طور کلی به همین ترتیب کار می کند
353
00:12:06,560 –> 00:12:09,839
و اکنون در اینجا می توانیم اکنون در this now را ببینیم
354
00:12:09,839 –> 00:12:10,160
355
00:12:10,160 –> 00:12:12,000
تا آن را به عنوان بخشی از مرجع داشته باشیم،
356
00:12:12,000 –> 00:12:14,000
از این نمودار داده شده می توانیم ببینیم
357
00:12:14,000 –> 00:12:16,959
که چهار سمت چپ است. همانطور که می
358
00:12:16,959 –> 00:12:17,360
بینید
359
00:12:17,360 –> 00:12:19,760
چهار چهار وجود ندارد در اینجا چهار حالت
360
00:12:19,760 –> 00:12:20,720
361
00:12:20,720 –> 00:12:23,600
سمت چپ است که بیشتر گره باقی مانده است و از این
362
00:12:23,600 –> 00:12:25,440
رو که این اولین گره ای است که قرار است بعداً
363
00:12:25,440 –> 00:12:26,639
بازدید شود،
364
00:12:26,639 –> 00:12:28,320
ما به سمت ریشه ها حرکت خواهیم کرد، به این
365
00:12:28,320 –> 00:12:30,160
معنی
366
00:12:30,160 –> 00:12:31,920
که اکنون وقتی ما در اینجا به سمت ریشه حرکت می کنیم،
367
00:12:31,920 –> 00:12:34,160
بنابراین ریشه برای know for
368
00:12:34,160 –> 00:12:37,200
four چیست که ریشه گره
369
00:12:37,200 –> 00:12:38,079
چهار در اینجا چیست، بچه ها
370
00:12:38,079 –> 00:12:40,800
اجازه دهید فقط این را برجسته کنم که سمت چپ ترین
371
00:12:40,800 –> 00:12:42,720
گره در حال حاضر دو چهار سمت راست است،
372
00:12:42,720 –> 00:12:46,000
بنابراین ریشه گره چهار چیست، آن
373
00:12:46,000 –> 00:12:47,040
دو سمت راست است.
374
00:12:47,040 –> 00:12:49,360
بنابراین ابتدا به سمت گره ریشه به
375
00:12:49,360 –> 00:12:50,399
سمت راست
376
00:12:50,399 –> 00:12:52,560
حرکت می کند، بنابراین به سمت دو حرکت می کند و
377
00:12:52,560 –> 00:12:54,639
سپس به دنبال آن باید بررسی کنیم
378
00:12:54,639 –> 00:12:56,639
که آیا گرهی به سمت راست داریم
379
00:12:56,639 –> 00:12:58,240
و درخت نشان می دهد که ما یک
380
00:12:58,240 –> 00:13:00,399
گره به عنوان ریشه پنج
381
00:13:00,399 –> 00:13:02,639
داریم، پس آن را قرار است به آقا تقدیم کند در
382
00:13:02,639 –> 00:13:03,519
بازدید خنثی
383
00:13:03,519 –> 00:13:05,920
پنج و هنگامی که این کار انجام شد، زیردرخت سمت چپ
384
00:13:05,920 –> 00:13:07,360
کامل شد
385
00:13:07,360 –> 00:13:09,279
و سپس ما دوباره همان
386
00:13:09,279 –> 00:13:10,399
قانون را
387
00:13:10,399 –> 00:13:14,000
از ریشه سمت چپ به راست دنبال می کنیم
388
00:13:14,000 –> 00:13:17,839
تا کل پیمایش
389
00:13:17,839 –> 00:13:19,680
را کامل کنیم تا دوباره به
390
00:13:19,680 –> 00:13:22,079
عقب برگردد. به سمت چپ که چهارمین است و
391
00:13:22,079 –> 00:13:24,000
سپس به ترتیب به
392
00:13:24,000 –> 00:13:27,600
سمت راست در دسترس است،
393
00:13:27,600 –> 00:13:29,279
بنابراین اکنون در اینجا میتوانیم با
394
00:13:29,279 –> 00:13:31,120
پیمایش پیشسفارش نیز کار کنیم، بنابراین
395
00:13:31,120 –> 00:13:32,320
از نظر پیشسفارش،
396
00:13:32,320 –> 00:13:34,560
گره ریشه اول بازدید شد و
397
00:13:34,560 –> 00:13:36,320
سپس زیر درخت سمت چپ
398
00:13:36,320 –> 00:13:38,800
و سپس زیردرخت سمت راست، بنابراین در این
399
00:13:38,800 –> 00:13:40,320
مثال میتوانیم ببینیم اولین
400
00:13:40,320 –> 00:13:43,680
گره بازدید شده یک است، بنابراین در اینجا میتوانیم
401
00:13:43,680 –> 00:13:44,720
ببینیم اولین گرهای که میخواهیم
402
00:13:44,720 –> 00:13:46,720
بازدید کنیم یک است
403
00:13:46,720 –> 00:13:49,839
و سپس گره را دنبال میکنیم. دو
404
00:13:49,839 –> 00:13:51,839
که به سمت چپ گره
405
00:13:51,839 –> 00:13:53,680
یک است بنابراین سمت چپ
406
00:13:53,680 –> 00:13:55,760
گره دو است و آن به قسمت دوم می رود
407
00:13:55,760 –> 00:13:58,000
و
408
00:13:58,000 –> 00:14:00,240
دوباره به سمت چپ حرکت می کند
409
00:14:00,240 –> 00:14:03,120
چهارم می شود و اکنون هیچ سمت چپی وجود ندارد بنابراین
410
00:14:03,120 –> 00:14:04,639
اکنون به سمت راست تراورس می کنیم
411
00:14:04,639 –> 00:14:06,720
ection و دوباره از سمت راست
412
00:14:06,720 –> 00:14:08,800
دوباره به سمت بالا می رویم و
413
00:14:08,800 –> 00:14:10,000
سه فرض کنید
414
00:14:10,000 –> 00:14:12,399
عنصر دیگری در دسترس بود،
415
00:14:12,399 –> 00:14:14,000
سپس به آن
416
00:14:14,000 –> 00:14:15,600
عنصر خاص و
417
00:14:15,600 –> 00:14:18,959
همچنین بخشی از پیمایش پیش سفارش می رفت
418
00:14:18,959 –> 00:14:20,480
و سپس اگر در مورد پست صحبت می کنید
419
00:14:20,480 –> 00:14:22,720
سفارش پس مرتب سازی ترتیب
420
00:14:22,720 –> 00:14:23,760
از سمت چپ شروع می شود
421
00:14:23,760 –> 00:14:26,320
سپس به راست و سپس در نهایت
422
00:14:26,320 –> 00:14:27,199
به ریشه
423
00:14:27,199 –> 00:14:29,600
بنابراین در اینجا از چپ شروع می شود و سپس
424
00:14:29,600 –> 00:14:31,360
425
00:14:31,360 –> 00:14:34,240
دوباره به سمت راست به سمت چپ می رود دوباره به سمت راست
426
00:14:34,240 –> 00:14:35,519
دوباره به سمت چپ
427
00:14:35,519 –> 00:14:38,320
و به همین ترتیب به همین ترتیب است. یک مسیر زیگزاگی کامل
428
00:14:38,320 –> 00:14:40,399
که با استفاده از
429
00:14:40,399 –> 00:14:42,720
پیمایش سفارش پست که از
430
00:14:42,720 –> 00:14:44,000
چپ به راست از چپ به راست میرفت دنبال
431
00:14:44,000 –> 00:14:47,600
میشود، بنابراین مرتبسازی دادهها
432
00:14:47,600 –> 00:14:50,480
در زمان واقعی میتوانیم بگوییم چه زمانی
433
00:14:50,480 –> 00:14:52,480
روی آن کار میکنیم و هر داده را مرتب میکنیم،
434
00:14:52,480 –> 00:14:54,079
پس باید در زمان واقعی انجام شود
435
00:14:54,079 –> 00:14:54,800
436
00:14:54,800 –> 00:14:57,920
و باید چندین
437
00:14:57,920 –> 00:14:59,360
الگوریتم مرتبسازی
438
00:14:59,360 –> 00:15:02,800
حل شود، بنابراین
439
00:15:02,800 –> 00:15:04,959
با مفاهیم ساختار داده و
440
00:15:04,959 –> 00:15:06,079
الگوریتمها
441
00:15:06,079 –> 00:15:08,000
در پایتون بهعنوان بخشی از بحث خود،
442
00:15:08,000 –> 00:15:09,839
بیایید شروع کنیم. بحث در مورد
443
00:15:09,839 –> 00:15:12,880
الگوریتمهای مرتبسازی ابتدا در پایتون،
444
00:15:12,880 –> 00:15:16,000
اجازه دهید ابتدا با آن شروع کنیم و اکنون
445
00:15:16,000 –> 00:15:18,560
از نظر الگوریتمهای مرتبسازی، از
446
00:15:18,560 –> 00:15:19,920
الگوریتمهای مرتبسازی
447
00:15:19,920 –> 00:15:23,760
برای مرتبسازی دادهها به ترتیب معین استفاده میشود
448
00:15:23,760 –> 00:15:26,079
و الگوریتمهای مرتبسازی را میتوان
449
00:15:26,079 –> 00:15:27,839
به پنج نوع طبقهبندی کرد.
450
00:15:27,839 –> 00:15:30,720
مرتبسازی پیام داریم مرتبسازی ادغامی
451
00:15:30,720 –> 00:15:31,519
سپس
452
00:15:31,519 –> 00:15:34,399
مرتبسازی حبابی و مرتبسازی انتخابی درج
453
00:15:34,399 –> 00:15:37,040
و سپس مرتبسازی پوستهای داریم،
454
00:15:37,040 –> 00:15:40,160
بنابراین همه الگوریتمها دوباره اینجا
455
00:15:40,160 —