در این مطلب، ویدئو وبینار زنده: تجزیه و تحلیل مجموعه داده های دیابت با استفاده از پایتون – قسمت 4/4 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:16:59
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:03,030
کسی می خواهد به سرعت بپیوندد با عرض پوزش،
2
00:00:03,030 –> 00:00:06,899
بیایید در قسمت چهارم به سرعت صحبت کنیم
3
00:00:06,899 –> 00:00:09,090
و این در حال حاضر پیش بینی دیابت با
4
00:00:09,090 –> 00:00:10,620
رگرسیون لجستیک است رگرسیون لجستیک
5
00:00:10,620 –> 00:00:14,670
یک تکنیک بسیار مفید و بسیار ترجیح داده شده
6
00:00:14,670 –> 00:00:16,859
در داده کاوی و
7
00:00:16,859 –> 00:00:19,289
یادگیری ماشینی است که درک آن بسیار آسان است و
8
00:00:19,289 –> 00:00:21,090
استفاده از آن آسان است. چیزی که ما آن را
9
00:00:21,090 –> 00:00:22,920
تابع لجستیک در یک تابع سیگموید می نامیم
10
00:00:22,920 –> 00:00:25,560
تا متغیرهای ورودی را تبدیل
11
00:00:25,560 –> 00:00:27,720
به احتمال بله یا خیر بودن نتیجه شما کنیم،
12
00:00:27,720 –> 00:00:30,179
بنابراین معمولاً روی
13
00:00:30,179 –> 00:00:32,820
نتیجه باینری یا بله یا خیر 1 یا 0 مثبت
14
00:00:32,820 –> 00:00:34,200
یا منفی و غیره و غیره کار می کند.
15
00:00:34,200 –> 00:00:35,190
میتوانید دوباره درباره آن بیشتر بخوانید.
16
00:00:35,190 –> 00:00:38,219
17
00:00:38,219 –> 00:00:40,170
18
00:00:40,170 –> 00:00:42,899
19
00:00:42,899 –> 00:00:45,570
20
00:00:45,570 –> 00:00:48,090
21
00:00:48,090 –> 00:00:50,640
من اکنون داده ها را تقسیم کردم تا
22
00:00:50,640 –> 00:00:53,280
بتوانم این متغیرها را اکنون به عنوان ورودی
23
00:00:53,280 –> 00:00:56,100
و این ستون را به عنوان خروجی من در نظر بگیرم. این
24
00:00:56,100 –> 00:00:57,840
کاری است که من در اینجا در این خط
25
00:00:57,840 –> 00:01:00,570
26
00:01:00,570 –> 00:01:02,879
انجام می دهم. Re معمولاً در
27
00:01:02,879 –> 00:01:04,438
حال یادگیری ماشینی است که آن را به دادههای قطار و آزمایش تقسیم میکند.
28
00:01:04,438 –> 00:01:06,840
من درصد بسیار کمی
29
00:01:06,840 –> 00:01:09,210
برای آزمایش دارم فقط برای عملکرد سریع.
30
00:01:09,210 –> 00:01:10,770
من با مدل رگرسیون لجستیک مطابقت دارم
31
00:01:10,770 –> 00:01:13,170
و اکنون سعی میکنم
32
00:01:13,170 –> 00:01:15,540
عملکرد آن را تخمین بزنم خوب است
33
00:01:15,540 –> 00:01:17,549
حدود 83 درصد دقت میدهد که
34
00:01:17,549 –> 00:01:19,470
خوب است. بد نیست آنچه که
35
00:01:19,470 –> 00:01:21,119
ما به آن علاقه مندیم نیست، اکنون
36
00:01:21,119 –> 00:01:24,119
از این مدل برای پیش بینی همان
37
00:01:24,119 –> 00:01:26,659
نقطه آزمایشی استفاده می کنیم که در اینجا همان نقطه
38
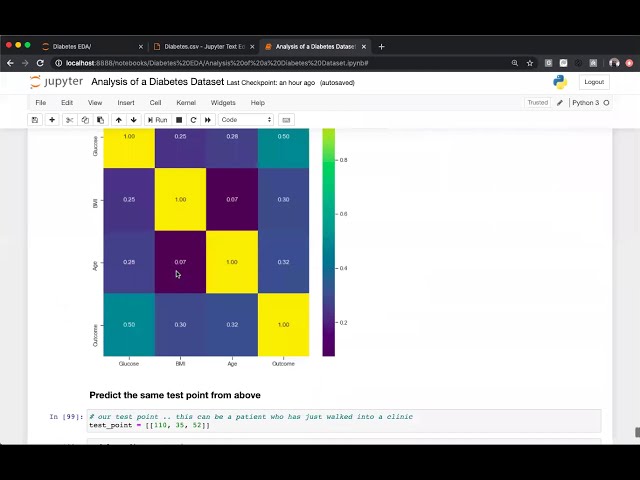
00:01:26,659 –> 00:01:30,090
این نقطه را داشتیم، بنابراین بعد از اینکه
39
00:01:30,090 –> 00:01:32,189
مدل را در همان روی و روی آن آموزش دادیم
40
00:01:32,189 –> 00:01:34,700
دادههایی که اکنون
41
00:01:34,950 –> 00:01:37,799
میتوانم در اینجا انجام دهم این است که میتوانم به
42
00:01:37,799 –> 00:01:39,600
سهم متغیر نگاه کنم و این
43
00:01:39,600 –> 00:01:40,860
بسیار جالب است، بنابراین ما سه
44
00:01:40,860 –> 00:01:44,250
متغیر BMI سن و گلوکز داریم و این
45
00:01:44,250 –> 00:01:47,700
نوار در اینجا به من نشان میدهد که
46
00:01:47,700 –> 00:01:49,770
BMI چقدر سهم دارد و سن هزینه محاسبه چقدر
47
00:01:49,770 –> 00:01:51,780
است. این مدل
48
00:01:51,780 –> 00:01:54,360
اساساً به معنای رگرسیون لجستیک است
49
00:01:54,360 –> 00:01:57,299
که فکر میکند BMI
50
00:01:57,299 –> 00:01:59,549
مهمترین عامل در
51
00:01:59,549 –> 00:02:03,899
پیشبینی دیابت است.
52
00:02:03,899 –> 00:02:05,250
53
00:02:05,250 –> 00:02:07,409
d مهمترین عامل سن است
54
00:02:07,409 –> 00:02:09,630
سومین عامل مهم
55
00:02:09,630 –> 00:02:11,459
گلوکز است در حال حاضر این ممکن است
56
00:02:11,459 –> 00:02:13,739
57
00:02:13,739 –> 00:02:17,430
58
00:02:17,430 –> 00:02:19,200
59
00:02:19,200 –> 00:02:22,049
خلاف واقع
60
00:02:22,049 –> 00:02:23,880
باشد. اکنون به نظر می رسد که شاخص توده بدنی
61
00:02:23,880 –> 00:02:25,680
مهم تر از این است که این مدل
62
00:02:25,680 –> 00:02:28,829
چیزهایی است و احتمالاً به این دلیل که برخی از
63
00:02:28,829 –> 00:02:31,049
داده های دیگر در همبستگی جمع آوری نشده اند
64
00:02:31,049 –> 00:02:33,209
یا ممکن است بین متغیرهای مختلف پراکنده شده
65
00:02:33,209 –> 00:02:34,920
باشند، خوب است، بنابراین این به یک
66
00:02:34,920 –> 00:02:39,120
پیشینه پزشکی نیاز دارد تا بتوان آن را به
67
00:02:39,120 –> 00:02:40,709
سرعت تفسیر کرد، اما مدل ما
68
00:02:40,709 –> 00:02:42,989
این است گفتن BMI مهمتر از
69
00:02:42,989 –> 00:02:45,420
دو مورد دیگر است و برای نگاه کردن به این ویژگی ها
70
00:02:45,420 –> 00:02:48,840
برای گلوکز اهمیت آن نقطه صفر
71
00:02:48,840 –> 00:02:50,819
سه است که تعداد آنها بسیار کم است
72
00:02:50,819 –> 00:02:53,639
زیرا به دلیل نحوه عملکرد
73
00:02:53,639 –> 00:02:55,859
رگرسیون، چیزها را
74
00:02:55,859 –> 00:02:57,480
بین صفر و یک و با استفاده از
75
00:02:57,480 –> 00:02:58,709
تابع لجستیک تبدیل می کند. و به همین ترتیب فرض کنید
76
00:02:58,709 –> 00:03:02,489
به همین دلیل است که مقادیر کاملاً نزدیک به
77
00:03:02,489 –> 00:03:05,040
صفر هستند و می گوید این است که
78
00:03:05,040 –> 00:03:07,170
تأثیر مثبت است پس هیچ چیز هیچ
79
00:03:07,170 –> 00:03:08,850
آنها تأثیر منفی دارند، به این معنی
80
00:03:08,850 –> 00:03:12,239
که وقتی آن مقدار جهت را افزایش می دهد،
81
00:03:12,239 –> 00:03:14,700
همه چیز در جهت مخالف می رود،
82
00:03:14,700 –> 00:03:16,500
بسیار خوب انجام شده است که در اینجا یک خلاصه سریع وجود دارد
83
00:03:16,500 –> 00:03:18,569
که سطح BMI
84
00:03:18,569 –> 00:03:20,849
بیشترین تأثیر را در مدل دارد، آنگاه
85
00:03:20,849 –> 00:03:23,970
گلوکز منطقی است که هر
86
00:03:23,970 –> 00:03:26,099
متخصص پزشکی با آن کار کند. ما امروز اینجا هستیم که
87
00:03:26,099 –> 00:03:28,049
دومین تأثیرگذار بالاتر سن است، سومین
88
00:03:28,049 –> 00:03:30,030
بالاترین سطح گلوکز است که خوشبختانه
89
00:03:30,030 –> 00:03:31,769
به نظر نمی رسد معقول باشد، اما این همان
90
00:03:31,769 –> 00:03:33,720
چیزی است که مدل می گوید این سه
91
00:03:33,720 –> 00:03:35,549
نفر تأثیر مثبتی بر
92
00:03:35,549 –> 00:03:36,500
پیش بینی دارند، یعنی
93
00:03:36,500 –> 00:03:39,120
مقادیر بالاتر آنها با اصلاح می شود.
94
00:03:39,120 –> 00:03:41,370
فرد مبتلا به دیابت B است، بنابراین
95
00:03:41,370 –> 00:03:43,319
در جهت مخالف قرار می گیرد،
96
00:03:43,319 –> 00:03:45,569
همبستگی به ما می گوید که گلوکز
97
00:03:45,569 –> 00:03:48,239
رنگی تر از BMR است – نتیجه ای که گفتم
98
00:03:48,239 –> 00:03:48,740
99
00:03:48,740 –> 00:03:51,260
مانند گلوکز کیفیت بیشتری
100
00:03:51,260 –> 00:03:53,240
دارد تا با نتیجه مرتبط باشد تا BMI،
101
00:03:53,240 –> 00:03:56,330
اما مدل بیشتر بر روی آن متکی است. BMI
102
00:03:56,330 –> 00:03:57,920
منطقی است که این ممکن است به دلایل متعددی اتفاق بیفتد
103
00:03:57,920 –> 00:03:59,720
، شاید
104
00:03:59,720 –> 00:04:01,250
همبستگی ثبت شده توسط علت
105
00:04:01,250 –> 00:04:03,370
آبی توسط برخی متغیرهای دیگر ثبت شود. شاید
106
00:04:03,370 –> 00:04:07,820
این ارزش بررسی بیشتر را دارد اما
107
00:04:07,820 –> 00:04:10,910
حالا نکته مهم خوب است بیایید
108
00:04:10,910 –> 00:04:12,290
نگاهی دیگر به همبستگی بیندازیم که
109
00:04:12,290 –> 00:04:14,360
می بینید گلوکز
110
00:04:14,360 –> 00:04:15,770
با نتیجه بالاتر از BMI همبستگی زیادی دارد
111
00:04:15,770 –> 00:04:20,300
و اما اکنون پس از ایجاد این
112
00:04:20,300 –> 00:04:23,060
مدل رگرسیون می توانیم
113
00:04:23,060 –> 00:04:25,940
احتمالات آن را پیش بینی کنیم. نقطه آزمایش
114
00:04:25,940 –> 00:04:28,670
دیابتی بودن یا نبودن این نقطه سبز در
115
00:04:28,670 –> 00:04:30,470
اینجا همان مقدار است بیایید نگاهی بیندازیم و ببینیم
116
00:04:30,470 –> 00:04:33,410
آیا این دو مدل با مدل آماری
117
00:04:33,410 –> 00:04:36,860
و رگرسیون لجستیک موافق هستند، بنابراین بیایید این
118
00:04:36,860 –> 00:04:38,690
کار را انجام دهیم این نقطه آزمایش من همان
119
00:04:38,690 –> 00:04:42,590
مقادیر 110 برای گلوکز 35 برای BMI 52 است.
120
00:04:42,590 –> 00:04:45,140
برای سن اگر پیش بینی
121
00:04:45,140 –> 00:04:48,650
0 یا 1 را انجام دهم به من می گوید خوب مقدار 0 را می دهد اما
122
00:04:48,650 –> 00:04:50,600
می خواهم بگویم احتمالات را به من بدهید
123
00:04:50,600 –> 00:04:53,470
و اگر اکنون
124
00:04:53,470 –> 00:04:57,140
احتمالات نقطه متعلق به کلاس 1 یعنی 0 یا
125
00:04:57,140 –> 00:05:01,220
نزدیک به صفر یا کلاس را بگیرم. 1 به من می
126
00:05:01,220 –> 00:05:05,300
گوید خوب است، من فکر می کنم 54 54 درصد
127
00:05:05,300 –> 00:05:08,030
احتمال وجود دارد که احتمالاً نقطه صفر 5
128
00:05:08,030 –> 00:05:11,630
4 یا با منفی بودن و 45 درصد
129
00:05:11,630 –> 00:05:14,810
احتمال مثبت بودن آن است و این
130
00:05:14,810 –> 00:05:16,100
واقعاً جالب است زیرا t
131
00:05:16,100 –> 00:05:18,170
همانطور که می بینید، دو مدل موافق هستند، بنابراین
132
00:05:18,170 –> 00:05:23,270
مدل رگرسیون لجستیک من و این
133
00:05:23,270 –> 00:05:25,460
مدل احتمالی هر دو موافق هستند
134
00:05:25,460 –> 00:05:27,690
که
135
00:05:27,690 –> 00:05:31,610
احتمال کمتری وجود دارد که این نقطه
136
00:05:31,610 –> 00:05:34,620
متعلق به یک فرد دیابتی باشد،
137
00:05:34,620 –> 00:05:36,660
خوب مقادیر یا احتمالات
138
00:05:36,660 –> 00:05:41,070
کمی متفاوت است اما
139
00:05:41,070 –> 00:05:44,070
نتیجه یکسان است. اینکه احتمال دیابتی بودن آن کمی کمتر و
140
00:05:44,070 –> 00:05:45,990
141
00:05:45,990 –> 00:05:49,380
احتمال غیر دیابتی بودن آن کمی بیشتر است
142
00:05:49,380 –> 00:05:50,790
و این بسیار جالب است،
143
00:05:50,790 –> 00:05:52,800
به یاد دارم زمانی که یک مدل رگرسیون لجستیک را آموزش
144
00:05:52,800 –> 00:05:54,510
دادم، از
145
00:05:54,510 –> 00:05:57,150
کل کل داده ها استفاده نکردم که بخشی از آن را به کار بردم.
146
00:05:57,150 –> 00:05:59,700
تست من باشد یا آن را تقسیم کنم و
147
00:05:59,700 –> 00:06:01,470
تست ها را برگردانم، اما اگر مدل را آموزش دادم
148
00:06:01,470 –> 00:06:04,470
به طور کامل نخواهد بود، گفتم احتمالاً
149
00:06:04,470 –> 00:06:06,210
مقادیر این احتمالات کمی تغییر می کند،
150
00:06:06,210 –> 00:06:08,490
خوب این مقدار کمی پایین می آید و
151
00:06:08,490 –> 00:06:10,290
کمی بالا می رود. با گفتن این موضوع،
152
00:06:10,290 –> 00:06:12,690
بسیار نزدیکتر از
153
00:06:12,690 –> 00:06:16,680
مدل واقعی بالستیک خواهد بود، بنابراین
154
00:06:16,680 –> 00:06:19,200
همانطور که گفتم، دو مدل موافق هستند
155
00:06:19,200 –> 00:06:21,240
که عالی است که نتیجه واقعاً خوبی از
156
00:06:21,240 –> 00:06:21,990
این آموزش
157
00:06:21,990 –> 00:06:23,850
است. بسیار عالی
158
00:06:23,850 –> 00:06:25,620
از اینکه به ما ملحق شدید بسیار متشکرم
159
00:06:25,620 –> 00:06:28,590
و صحبت من به پایان رسید، بیایید ببینیم
160
00:06:28,590 –> 00:06:33,300
آیا سؤالی دارید، بنابراین در مورد QA
161
00:06:33,300 –> 00:06:39,480
من نمودارها را ترجیح می دهم، اما اگر کسی می خواهد
162
00:06:39,480 –> 00:06:43,650
از میکروفون استفاده کند خوب است بنابراین اجازه دهید
163
00:06:43,650 –> 00:06:46,500
ببینم شما سؤالی دارید سوالات شما می توانید
164
00:06:46,500 –> 00:06:48,360
صفحه نمایش را کوچکتر کنید تا
165
00:06:48,360 –> 00:06:50,250
اطلاعات بیشتری نشان داده شود، بنابراین من به
166
00:06:50,250 –> 00:06:52,950
نمودار نگاه نمی کردم.
167
00:06:52,950 –> 00:06:55,200
168
00:06:55,200 –> 00:06:56,910
169
00:06:56,910 –> 00:06:59,880
170
00:06:59,880 –> 00:07:01,710
171
00:07:01,710 –> 00:07:03,690
میخواهید دادههای خود را مدل کنید
172
00:07:03,690 –> 00:07:05,670
و شاید برای مثال و
173
00:07:05,670 –> 00:07:07,680
پیشبینیهایی برای مثال پیشبینی کنید که
174
00:07:07,680 –> 00:07:10,830
مقداری چقدر محتمل است یا گاهی اوقات
175
00:07:10,830 –> 00:07:13,710
یک مقدار بین محدوده
176
00:07:13,710 –> 00:07:17,730
دو مقدار چقدر محتمل است یا میخواهید دادههایی را
177
00:07:17,730 –> 00:07:20,070
از یک توزیع مشابه بکشید یا دادهای مشابه ایجاد کنید.
178
00:07:20,070 –> 00:07:22,560
تنظیم مدل سازی در اینجا بسیار
179
00:07:22,560 –> 00:07:26,840
مهم است، هر گونه سؤالی،
180
00:07:27,730 –> 00:07:30,010
بله برای آنها برای نتیجه گسسته
181
00:07:30,010 –> 00:07:32,410
، PMF آن در عملکرد جرمی بسیار مهم است. از شما
182
00:07:32,410 –> 00:07:35,140
Idol برای گفتن شما بسیار خوب است،
183
00:07:35,140 –> 00:07:36,640
لطفاً می توانیم سؤالی داشته باشیم.
184
00:07:36,640 –> 00:07:38,970
کد نوت بوک مشتری به عنوان بخشی از سوغات
185
00:07:38,970 –> 00:07:40,570
باشه ممنون
186
00:07:40,570 –> 00:07:42,100
187
00:07:42,100 –> 00:07:43,840
میشم کسی کد رو بدونه باشه من کد رو در github قرار میدم
188
00:07:43,840 –> 00:07:46,030
اگر ایمیلم رو برام ایمیل کنید به عنوان
189
00:07:46,030 –> 00:07:47,110
کد اسمبلی
190
00:07:47,110 –> 00:07:50,350
باشه کد سناتور
191
00:07:50,350 –> 00:07:52,750
حداقل چنده مشاهداتی که
192
00:07:52,750 –> 00:07:55,660
برای N و N و تکنیک مورد نیاز است، کسی در
193
00:07:55,660 –> 00:07:58,210
مورد شبکههای شما میپرسد
194
00:07:58,210 –> 00:08:00,820
شبکههای عصبی به دادهها گرسنه هستند و
195
00:08:00,820 –> 00:08:02,920
من پاسخی برای شما ندارم
196
00:08:02,920 –> 00:08:05,200
میدانید کمترین تعداد
197
00:08:05,200 –> 00:08:08,050
مشاهدات چقدر است، هرچه دادههای بیشتری داشته باشید معمولاً
198
00:08:08,050 –> 00:08:10,060
بهتر است. هیچ پاسخ جادویی برای این وجود ندارد
199
00:08:10,060 –> 00:08:12,910
خوب است که مالک در مورد آن می پرسد
200
00:08:12,910 –> 00:08:14,830
شبکه های منطقه ای متفاوت هستند، شاید یک روز
201
00:08:14,830 –> 00:08:16,930
بتوانیم یک جلسه دیگر روی آنها داشته باشیم، اما
202
00:08:16,930 –> 00:08:19,330
مالک می گوید که
203
00:08:19,330 –> 00:08:21,130
ما معمولاً به چند نمونه نیاز داریم،
204
00:08:21,130 –> 00:08:24,190
صادقانه بگویم پاسخ جادویی ندارم. واقعاً
205
00:08:24,190 –> 00:08:25,930
یک پاسخ مشخص وجود ندارد که
206
00:08:25,930 –> 00:08:28,740
شما معمولاً بهتر است، باشه،
207
00:08:28,740 –> 00:08:33,460
هر سؤال دیگری باشه، حدس میزنم
208
00:08:33,460 –> 00:08:36,280
میتوانم اکنون اشتراکگذاری صفحه را
209
00:08:36,280 –> 00:08:38,650
210
00:08:38,650 –> 00:08:40,090
متوقف کنم. برای این
211
00:08:40,090 –> 00:08:42,789
ارا