در این مطلب، ویدئو Power BI و Python Machine Learning A تا Z قسمت 6: آماده سازی و ایجاد مدل با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:23:05
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,880 –> 00:00:03,040
سلام، شما قبلاً
2
00:00:03,040 –> 00:00:07,120
در این دوره کارهای زیادی انجام داده اید، ما در مرحله ای
3
00:00:07,120 –> 00:00:10,080
از دوره هستیم که می
4
00:00:10,080 –> 00:00:12,960
خواهیم داده های خود را برای استفاده
5
00:00:12,960 –> 00:00:16,320
در یک مدل یادگیری ماشین آماده کنیم
6
00:00:16,320 –> 00:00:18,400
و مراحل مختلفی برای اطمینان از دریافت آن مورد نیاز است.
7
00:00:18,400 –> 00:00:21,359
دقیق ترین
8
00:00:21,359 –> 00:00:23,840
نتایج
9
00:00:23,840 –> 00:00:27,599
با تهیه این مجموعه داده است،
10
00:00:27,599 –> 00:00:30,080
بنابراین بیایید آنچه را که قبلاً انجام داده ایم مرور کنیم
11
00:00:30,080 –> 00:00:32,479
،
12
00:00:32,479 –> 00:00:35,360
من از یک نوت بوک جدید مشتری استفاده می کنم،
13
00:00:35,360 –> 00:00:38,879
اما شما خوش آمدید از
14
00:00:38,879 –> 00:00:42,480
نسخه قبلی از ویدیوی خود استفاده کنید،
15
00:00:42,480 –> 00:00:45,520
ما
16
00:00:45,520 –> 00:00:49,039
دوباره مجموعه داده های 50 استارتاپ را بررسی خواهیم کرد.
17
00:00:49,039 –> 00:00:52,480
و با استفاده از آن برای ایجاد یک
18
00:00:52,480 –> 00:00:55,680
مدل یادگیری ماشینی رگرسیون خطی،
19
00:00:55,680 –> 00:01:00,079
بنابراین اجازه دهید آنچه را که تا کنون
20
00:01:00,079 –> 00:01:02,079
در کتابخانه های ضروری
21
00:01:02,079 –> 00:01:03,440
pandas و numpy بارگذاری کرده ام
22
00:01:03,440 –> 00:01:06,960
و ما را به عنوان
23
00:01:06,960 –> 00:01:10,080
متغیرهای pd و mp که در کتابخانه تصویری بارگذاری کرده ام ذخیره کرده ام مرور کنیم.
24
00:01:10,080 –> 00:01:12,720
25
00:01:12,720 –> 00:01:15,759
matplotlib به صورت plt
26
00:01:15,759 –> 00:01:18,080
ذخیره شده و در cborm ذخیره شده است که یک
27
00:01:18,080 –> 00:01:19,680
28
00:01:19,680 –> 00:01:22,720
کتابخانه رسم آماری به عنوان sns است
29
00:01:22,720 –> 00:01:27,360
که من در مجموعه داده خوانده ام
30
00:01:27,360 –> 00:01:31,840
که 50 راه اندازی با استفاده از تابع خواندن csv
31
00:01:31,840 –> 00:01:34,960
است که با استفاده از تابع head به پنج ردیف بالا نگاه کردم.
32
00:01:34,960 –> 00:01:37,119
روی آن
33
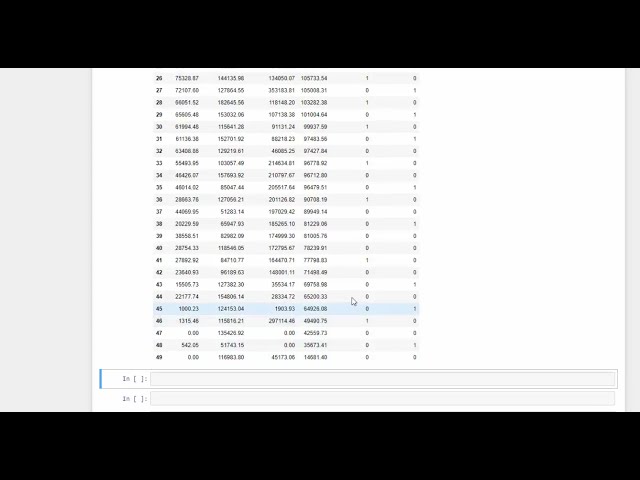
00:01:37,119 –> 00:01:37,759
34
00:01:37,759 –> 00:01:41,040
متغیر مجموعه داده،
35
00:01:41,040 –> 00:01:42,880
36
00:01:42,880 –> 00:01:46,640
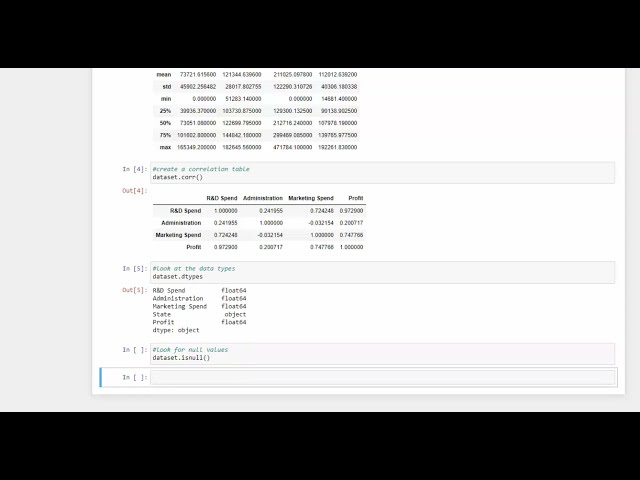
با استفاده از تابع توصیف، یک جدول خلاصه آماری
37
00:01:48,000 –> 00:01:52,079
ایجاد کردهام و با استفاده از تابع corr یک جدول همبستگی ایجاد
38
00:01:52,799 –> 00:01:55,840
کردهام،
39
00:01:55,840 –> 00:01:59,680
حالا چرا به این
40
00:01:59,680 –> 00:02:02,000
مراحل نیاز داریم، باید
41
00:02:02,000 –> 00:02:03,280
سر داده را بررسی کنیم تا بفهمیم
42
00:02:03,280 –> 00:02:06,880
چه چیزی چیست؟
43
00:02:06,880 –> 00:02:10,479
برای پیشبینی ما به ستونهایی نیاز داریم که میخواهیم
44
00:02:10,479 –> 00:02:11,038
45
00:02:11,038 –> 00:02:14,160
به توصیف نگاه کنیم تا ببینیم میانگین
46
00:02:14,160 –> 00:02:15,760
و حداقل و حداکثر
47
00:02:15,760 –> 00:02:18,800
چقدر است تا نشان دهیم مقیاس دادههای ما
48
00:02:18,800 –> 00:02:20,160
چقدر متفاوت
49
00:02:20,160 –> 00:02:25,120
است و میتوانیم ببینیم
50
00:02:25,120 –> 00:02:28,000
که معمولاً همه متغیرهای عددی
51
00:02:28,000 –> 00:02:30,239
52
00:02:30,239 –> 00:02:34,640
یا ستونها
53
00:02:34,640 –> 00:02:38,000
سطح نسبتاً یکسانی از داده ها را داشته باشید و منظور من
54
00:02:38,000 –> 00:02:38,879
از سطح
55
00:02:38,879 –> 00:02:42,560
این است که وقتی ما به آن نگاه می کنیم، فرض
56
00:02:42,560 –> 00:02:46,160
کنید به معنایی که به آن نگاه نمی کنیم،
57
00:02:46,160 –> 00:02:49,280
چیزی را می دانید که
58
00:02:49,280 –> 00:02:51,599
در مقیاس کاملاً متفاوتی است، برای
59
00:02:51,599 –> 00:02:52,560
مثال هزینه های
60
00:02:52,560 –> 00:02:56,800
تحقیق می تواند 15 باشد و سپس
61
00:02:56,800 –> 00:03:00,879
مدیریت 121
62
00:03:00,879 –> 00:03:02,400
000 است. این مقیاس کاملاً متفاوت خواهد بود،
63
00:03:02,400 –> 00:03:04,239
64
00:03:04,239 –> 00:03:06,959
اما ما قرار است داده های خود را مقیاس بندی کنیم
65
00:03:06,959 –> 00:03:07,360
تا
66
00:03:07,360 –> 00:03:11,040
اطمینان حاصل کنیم که بهترین نتایج را دریافت می کنیم.
67
00:03:11,040 –> 00:03:13,440
68
00:03:13,440 –> 00:03:15,760
69
00:03:15,760 –> 00:03:18,800
زیرا این به ما
70
00:03:18,800 –> 00:03:19,040
71
00:03:19,040 –> 00:03:21,280
نشان می دهد که چگونه آن متغیرها
72
00:03:21,280 –> 00:03:22,879
با یکدیگر تعامل دارند
73
00:03:22,879 –> 00:03:25,920
در حال حاضر برای جداول ما در
74
00:03:25,920 –> 00:03:27,920
اینجا فقط با متغیرهای عددی سروکار
75
00:03:27,920 –> 00:03:29,200
داریم،
76
00:03:29,200 –> 00:03:31,920
بنابراین اولین چیزی که می خواهیم به آن نگاه کنیم
77
00:03:31,920 –> 00:03:33,200
تمام انواع داده ها
78
00:03:33,200 –> 00:03:35,120
در مجموعه داده های ما و نحوه کار ما است.
79
00:03:35,120 –> 00:03:36,799
این کار این است که
80
00:03:36,799 –> 00:03:40,000
از انواع تابع d استفاده
81
00:03:40,000 –> 00:03:46,560
میکنم، بنابراین من میخواهم کد
82
00:03:46,560 –> 00:03:49,760
خود را به انواع دادهها مستند کنم و
83
00:03:49,760 –> 00:03:51,680
از
84
00:03:51,680 –> 00:03:55,280
تابع d نوع
85
00:03:55,280 –> 00:03:59,280
استفاده کنم، روش oh من از انواع d برای
86
00:03:59,280 –> 00:04:03,519
ارزیابی انواع دادهها استفاده خواهم کرد. بنابراین مجموعه دادهها را
87
00:04:03,519 –> 00:04:07,280
انواع نقطه d
88
00:04:07,280 –> 00:04:09,920
و سپس من میخواهم تغییر دهم و وارد کنم
89
00:04:09,920 –> 00:04:11,040
و اکنون میتوانیم
90
00:04:11,040 –> 00:04:14,319
تمام انواع دادههایی را که داریم ببینیم،
91
00:04:14,319 –> 00:04:17,759
بنابراین مدلهای یادگیری ماشینی از مقادیر عددی استفاده میکنند
92
00:04:17,759 –> 00:04:19,120
93
00:04:19,120 –> 00:04:21,440
و ما در اینجا یک شی داریم که آن نیز
94
00:04:21,440 –> 00:04:24,080
یک رشته است، بنابراین خواهیم داشت. برای آمادهسازی
95
00:04:24,080 –> 00:04:25,680
مجموعه دادهها
96
00:04:25,680 –> 00:04:29,680
بهگونهای که فقط مقادیر عددی داشته
97
00:04:29,680 –> 00:04:33,040
باشیم، همچنین باید اطمینان حاصل کنیم
98
00:04:33,040 –> 00:04:37,040
که هیچ مقدار از دست رفته نداریم
99
00:04:37,040 –> 00:04:40,639
و چگونه میتوانیم مقادیر گمشده را پیدا
100
00:04:40,639 –> 00:04:43,680
کنیم، میتوانیم به دنبال nullها بگردیم، بنابراین
101
00:04:43,680 –> 00:04:46,720
من میخواهم کد
102
00:04:46,720 –> 00:04:51,520
خود را برای جستجوی null مستند کنم. مقادیر
103
00:04:51,919 –> 00:04:54,000
و من می خواهم دوباره متغیر مجموعه داده را فراخوانی کنم
104
00:04:54,000 –> 00:04:56,639
105
00:04:56,639 –> 00:04:58,880
و سپس من می خواهم از تابع null
106
00:04:58,880 –> 00:05:01,360
استفاده کنم
107
00:05:02,479 –> 00:05:05,360
و اجازه دهید چند فاصله اضافی
108
00:05:05,360 –> 00:05:07,199
در اینجا ایجاد کنم
109
00:05:07,199 –> 00:05:10,080
تا بتوانیم این را کمی بهتر
110
00:05:10,080 –> 00:05:10,639
111
00:05:10,639 –> 00:05:14,320
ببینیم،
112
00:05:14,320 –> 00:05:17,840
بنابراین مقادیر null ما هستند، بنابراین این تابع چه کاری انجام
113
00:05:17,840 –> 00:05:20,639
می دهد و به ما می گوید که آیا وجود دارد یا خیر. یک عدد تهی
114
00:05:20,639 –> 00:05:21,440
115
00:05:21,440 –> 00:05:24,560
یا نه که به ما یک مقدار بولی
116
00:05:24,560 –> 00:05:25,199
117
00:05:25,199 –> 00:05:27,520
درست نادرست می دهد، بنابراین بیایید آن را اجرا کنیم تا
118
00:05:27,520 –> 00:05:31,120
بفهمیم چه اتفاقی می افتد
119
00:05:32,000 –> 00:05:34,320
تا بتوانید ببینید کل مجموعه داده
120
00:05:34,320 –> 00:05:36,080
درست یا نادرست برمی گردد
121
00:05:36,080 –> 00:05:39,840
که برای ما خیلی مفید نیست، بنابراین
122
00:05:39,840 –> 00:05:43,360
اکنون می توانیم یک تابع اضافی دیگر اضافه
123
00:05:43,360 –> 00:05:44,479
کنید
124
00:05:44,479 –> 00:05:48,080
که مجموع است که
125
00:05:48,080 –> 00:05:51,440
مقادیر بولی را در
126
00:05:51,440 –> 00:05:54,800
امتداد ستون ها جمع می کند، بنابراین من می خواهم جمع نقطه را اضافه کنم
127
00:05:54,800 –> 00:05:58,000
و سپس اینتر را بزنید
128
00:05:58,000 –> 00:06:01,280
تا ببینیم هیچ مقداری نداریم، بنابراین در
129
00:06:01,280 –> 00:06:04,639
حال حاضر در وضعیت خوبی هستیم، بنابراین اگر به یاد دارید
130
00:06:04,639 –> 00:06:06,240
از بالای
131
00:06:06,240 –> 00:06:11,680
جدول ما میتوانیم ببینیم
132
00:06:11,680 –> 00:06:15,919
که این رشتهها را
133
00:06:15,919 –> 00:06:17,840
داریم و میخواهیم بتوانیم بدانیم چند
134
00:06:17,840 –> 00:06:19,840
تا از آنها وجود دارد، زیرا شما فقط
135
00:06:19,840 –> 00:06:21,759
به پنج ردیف بالا نگاه میکنید، ما میتوانیم
136
00:06:21,759 –> 00:06:23,520
فلوریدا نیویورک و
137
00:06:23,520 –> 00:06:24,800
کالیفرنیا
138
00:06:24,800 –> 00:06:27,919
را ببینیم. سه متمایز بشمار،
139
00:06:27,919 –> 00:06:30,960
اما بیایید یک l بگیریم خوب
140
00:06:30,960 –> 00:06:34,319
اینها را بشماریم تا بفهمیم
141
00:06:34,319 –> 00:06:37,919
وقتی
142
00:06:37,919 –> 00:06:40,880
اینها را کدگذاری کنیم چند دسته خواهیم داشت چه اتفاقی می افتد،
143
00:06:40,880 –> 00:06:44,240
بنابراین من به پایین بر می گردم
144
00:06:44,240 –> 00:06:49,840
و بیایید
145
00:06:50,000 –> 00:06:53,199
ستون وضعیت خود را
146
00:06:54,400 –> 00:06:58,880
شمارش دسته بندی رشته ها بشماریم،
147
00:06:58,880 –> 00:07:01,599
بنابراین من می خواهم به مجموعه داده ها بروم و سپس
148
00:07:01,599 –> 00:07:02,000
می خواهم برای
149
00:07:02,000 –> 00:07:05,759
ایزوله کردن حالت
150
00:07:08,240 –> 00:07:10,160
اکنون میخواهم بتوانم آن را بشمارم
151
00:07:10,160 –> 00:07:12,960
و میخواهم مقادیر را بشمارم تا بتوانیم از تابع شمارش مقادیر استفاده
152
00:07:12,960 –> 00:07:13,280
153
00:07:13,280 –> 00:07:16,880
154
00:07:16,880 –> 00:07:19,120
کنیم و فقط shift و enter را فشار میدهم
155
00:07:19,120 –> 00:07:21,520
156
00:07:21,520 –> 00:07:24,880
و میتوانیم ببینیم
157
00:07:24,880 –> 00:07:27,199
که تعداد زوج کالیفرنیا داریم. و
158
00:07:27,199 –> 00:07:28,639
159
00:07:28,639 –> 00:07:32,400
برای مقدار فلوریدا کمی متفاوت است،
160
00:07:32,400 –> 00:07:36,000
بنابراین چگونه این
161
00:07:36,000 –> 00:07:39,199
مقادیر رشته را به اعداد تبدیل
162
00:07:39,199 –> 00:07:42,800
کنیم، از این در مرحله ای به نام رمزگذاری استفاده می
163
00:07:42,800 –> 00:07:47,520
کنیم، جایی که می توانیم صفر و یک را اضافه کنیم
164
00:07:47,520 –> 00:07:51,280
تا نشان دهیم که دسته بندی
165
00:07:51,280 –> 00:07:54,319
قرار است چیست و پانداها عملکرد بسیار
166
00:07:54,319 –> 00:07:54,639
خوبی
167
00:07:54,639 –> 00:07:58,080
دارند. برای این میخواهم
168
00:07:58,080 –> 00:08:01,039
بتوانم اینها را رمزگذاری کنم تا دیگر رشتهها نباشند،
169
00:08:01,039 –> 00:08:03,039
اما نمایشهای عددی وجود دارد
170
00:08:03,039 –> 00:08:06,160
171
00:08:06,160 –> 00:08:09,039
و ما میتوانیم این کار را با استفاده از متغیر get dummies انجام دهیم،
172
00:08:09,039 –> 00:08:10,840
بنابراین
173
00:08:10,840 –> 00:08:13,840
ابتدا
174
00:08:13,840 –> 00:08:17,039
یا ستون حالت را
175
00:08:17,039 –> 00:08:19,120
فشار دهید enter را فشار دهید سپس از pd استفاده میکنیم
176
00:08:19,120 –> 00:08:21,680
که یک تغییر دهید میتوانیم
177
00:08:21,680 –> 00:08:22,960
پانداها را در زیر ذخیره کنیم
178
00:08:22,960 –> 00:08:27,840
و سپس عملکرد dummies underscore را وارد
179
00:08:27,919 –> 00:08:31,520
کنیم و سپس من به
180
00:08:31,520 –> 00:08:33,919
آنچه مورد نیاز است نگاه میکنم و میتوانیم
181
00:08:33,919 –> 00:08:35,519
ببینیم که دادهها
182
00:08:35,519 –> 00:08:39,039
مورد نیاز است تا بتوانیم مجموعه دادههای خود را ارسال کنیم
183
00:08:39,039 –> 00:08:40,559
184
00:08:40,559 –> 00:08:43,440
و به آنچه اتفاق میافتد نگاهی بیندازیم و همانطور
185
00:08:43,440 –> 00:08:44,159
که
186
00:08:44,159 –> 00:08:47,920
در اینجا می بینید این کدگذاری شده است
187
00:08:47,920 –> 00:08:51,440
برای مثال اگر بخواهیم ببینیم
188
00:08:51,440 –> 00:08:54,720
که چگونه صفر صفر یک کدگذاری شده است
189
00:08:54,720 –> 00:08:58,720
، نیویورک خواهد بود زیرا
190
00:08:58,720 –> 00:09:02,080
یک دسته انتخابی است
191
00:09:02,080 –> 00:09:06,080
بنابراین کالیفرنیا یک صفر صفر
192
00:09:06,080 –> 00:09:10,000
و فلوریدا 0 1 0 خواهد بود.
193
00:09:10,000 –> 00:09:13,760
اکنون ما داریم سه دسته وجود دارد
194
00:09:13,760 –> 00:09:17,040
اما بهترین تمرین حذف
195
00:09:17,040 –> 00:09:19,920
یکی از این دسته ها است زیرا می دانیم که
196
00:09:19,920 –> 00:09:21,279
197
00:09:21,279 –> 00:09:24,320
آیا نیویورک و فلوریدا است اگر
198
00:09:24,320 –> 00:09:25,200
فقط آن دو
199
00:09:25,200 –> 00:09:28,399
صفر داشته باشیم و یک
200
00:09:28,399 –> 00:09:31,120
برابر با نیویورک است، اما اگر صفر و
201
00:09:31,120 –> 00:09:31,680
صفر داشته
202
00:09:31,680 –> 00:09:34,560
باشیم می دانیم که جایگزین آن کالیفرنیا خواهد بود.
203
00:09:34,560 –> 00:09:35,680
204
00:09:35,680 –> 00:09:38,959
ما در واقع به یکی از این دستهها نیاز نداریم،
205
00:09:38,959 –> 00:09:39,920
206
00:09:39,920 –> 00:09:43,600
بنابراین بهترین کار این است
207
00:09:43,600 –> 00:09:47,360
که دسته اول را حذف کنیم و اگر
208
00:09:47,360 –> 00:09:48,480
به تابع خود برگردم
209
00:09:48,480 –> 00:09:51,839
و تب shift را فشار
210
00:09:51,839 –> 00:09:54,480
دهم، میتوان دید که پارامتری به نام drop وجود دارد،
211
00:09:54,480 –> 00:09:55,040
212
00:09:55,040 –> 00:09:58,320
ابتدا آن را کپی میکنم.
213
00:09:58,320 –> 00:10:02,959
یک d فقط آن را در تابع ما
214
00:10:02,959 –> 00:10:06,560
کپی و پیست کنید و به جای
215
00:10:06,560 –> 00:10:10,720
false من می خواهم این را به درست تغییر دهم،
216
00:10:10,720 –> 00:10:14,240
یک بار که می توانم آن را دوباره اجرا کنم
217
00:10:14,240 –> 00:10:18,720
و اکنون می بینید که ما دو دسته داریم،
218
00:10:18,720 –> 00:10:22,079
بنابراین هر یک از
219
00:10:22,079 –> 00:10:25,600
دسته
220
00:10:25,600 –> 00:10:28,959
ها 0 و 0 هستند. 0
221
00:10:28,959 –> 00:10:32,640
ما می دانیم که نشان دهنده کالیفرنیا است،
222
00:10:32,640 –> 00:10:35,920
بنابراین می خواهیم بتوانیم این مجموعه داده جدید را ذخیره
223
00:10:35,920 –> 00:10:38,959
224
00:10:38,959 –> 00:10:43,200
کنیم تا بتوانیم از
225
00:10:43,200 –> 00:10:45,680
آن در یادگیری ماشین خود استفاده کنیم و روشی
226
00:10:45,680 –> 00:10:46,320
227
00:10:46,320 –> 00:10:50,000
که می توانیم با وارد کردن متغیر
228
00:10:50,000 –> 00:10:50,640
229
00:10:50,640 –> 00:10:54,240
خود و ذخیره مجدد آن
230
00:10:54,240 –> 00:10:58,880
به عنوان داده، آن متغیر را انجام دهیم. تنظیم کنید، بنابراین من میخواهم آن را اجرا کنم
231
00:10:59,120 –> 00:11:01,120
و اکنون اگر به سر دادههایمان نگاه کنم،
232
00:11:01,120 –> 00:11:03,519
233
00:11:04,000 –> 00:11:08,480
میدانیم که آن را بهعنوان
234
00:11:08,600 –> 00:11:11,680
dataset.head دوباره ذخیره کردهایم و اکنون
235
00:11:11,680 –> 00:11:15,279
دستههای رمزگذاریشده
236
00:11:15,279 –> 00:11:18,800
و یک جدول کاملاً عددی را
237
00:11:18,800 –> 00:11:22,640
داریم که باید توسط یک ماشین جذب شود.
238
00:11:22,640 –> 00:11:25,279
مدل یادگیری بنابراین ما به
239
00:11:25,279 –> 00:11:27,040
مراحل خود
240
00:11:27,040 –> 00:11:30,800
در آماده سازی مجموعه داده های خود برای