در این مطلب، ویدئو TF-IDF برای مبتدیان چیست (مدل سازی موضوع در پایتون برای DH 02.01) با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:10:39
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:02,009 –> 00:00:09,809
[موسیقی]
2
00:00:11,519 –> 00:00:13,519
سلام و خوش آمدید به مجموعه
3
00:00:13,519 –> 00:00:15,280
مدل سازی موضوع و
4
00:00:15,280 –> 00:00:17,279
طبقه بندی متن برای اهداف
5
00:00:17,279 –> 00:00:19,199
علوم انسانی دیجیتال
6
00:00:19,199 –> 00:00:21,680
در این قسمت دوم، ما قصد داریم به
7
00:00:21,680 –> 00:00:22,560
بررسی
8
00:00:22,560 –> 00:00:26,000
فرکانس معکوس tf idf یا اصطلاح
9
00:00:26,000 –> 00:00:27,519
فرکانس سند
10
00:00:27,519 –> 00:00:28,880
بپردازیم و یک مورد را دنبال می کنیم. الگوی
11
00:00:28,880 –> 00:00:30,480
در بقیه این مجموعه که
12
00:00:30,480 –> 00:00:32,079
هر قسمت قرار است
13
00:00:32,079 –> 00:00:34,880
سه یا چهار ویدیو داشته باشد، یکی در
14
00:00:34,880 –> 00:00:35,680
15
00:00:35,680 –> 00:00:38,719
مورد مفاهیم پشت این روش است، بنابراین
16
00:00:38,719 –> 00:00:40,239
توضیح کامل روش پیام به
17
00:00:40,239 –> 00:00:42,480
طور کامل ویدیوی دو در
18
00:00:42,480 –> 00:00:44,000
کتابخانه های لازم
19
00:00:44,000 –> 00:00:46,719
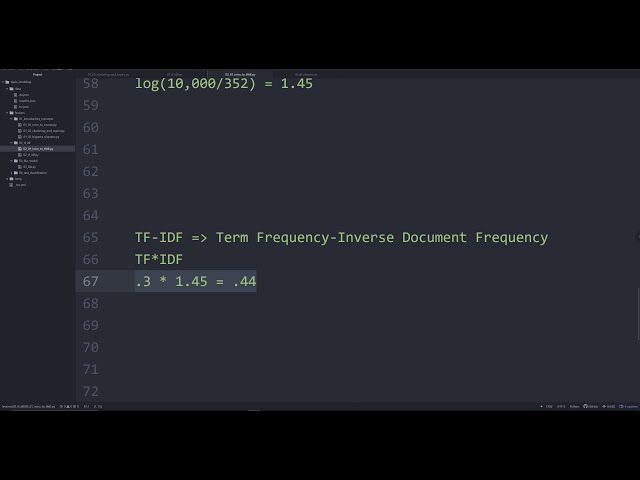
برای پیاده سازی آن روش ها خواهد بود و سپس
20
00:00:46,719 –> 00:00:47,600
ویدیو
21
00:00:47,600 –> 00:00:50,160
3 قرار است کد پایتون برای
22
00:00:50,160 –> 00:00:50,800
23
00:00:50,800 –> 00:00:52,800
استفاده از آن کتابخانهها برای اجرای
24
00:00:52,800 –> 00:00:54,079
متد
25
00:00:54,079 –> 00:00:57,120
ویدیوی 4 در یک سری باشد که روی تجسم دادهها
26
00:00:57,120 –> 00:00:58,239
27
00:00:58,239 –> 00:00:59,680
یا چیزهای کوچک دیگری که ممکن است
28
00:00:59,680 –> 00:01:01,520
لازم باشد
29
00:01:01,520 –> 00:01:03,760
مانند بازگشت به عقب و تنظیم
30
00:01:03,760 –> 00:01:04,879
31
00:01:04,879 –> 00:01:07,119
پارامترهای روشهای مختلفی که ما
32
00:01:07,119 –> 00:01:08,880
انجام میدهیم، این طرح کلی در
33
00:01:08,880 –> 00:01:09,680
آینده است،
34
00:01:09,680 –> 00:01:11,600
زیرا این اولین ویدیویی است
35
00:01:11,600 –> 00:01:13,119
که میخواهیم یک موضوع اساسی بپرسیم.
36
00:01:13,119 –> 00:01:14,400
37
00:01:14,400 –> 00:01:18,159
بپرسید tf idf چیست یا
38
00:01:18,159 –> 00:01:20,400
فرکانس معکوس فرکانس سند چیست
39
00:01:20,400 –> 00:01:21,439
40
00:01:21,439 –> 00:01:23,680
و اگر میخواهید دنبال کنید، من اکنون
41
00:01:23,680 –> 00:01:24,479
شروع به
42
00:01:24,479 –> 00:01:27,200
در دسترس قرار دادن همه مطالبم در قالب
43
00:01:27,200 –> 00:01:28,479
کتابهای درسی کوچکی
44
00:01:28,479 –> 00:01:30,479
میکنم که شما را از صفر
45
00:01:30,479 –> 00:01:32,079
به قهرمان میرساند.
46
00:01:32,079 –> 00:01:33,680
موضوعات مورد بحث در این
47
00:01:33,680 –> 00:01:36,320
کانال یوتیوب، من این کار را برای ner انجام
48
00:01:36,320 –> 00:01:39,680
داده ام، اکنون در ner dot python dot در دسترس است
49
00:01:39,680 –> 00:01:42,640
و اکنون این کار را برای مدل سازی موضوع انجام می دهم،
50
00:01:42,640 –> 00:01:43,280
51
00:01:43,280 –> 00:01:46,720
بنابراین
52
00:01:46,720 –> 00:01:47,119
53
00:01:47,119 –> 00:01:49,920
اگر دوست داشتید، همراه باشید و آنجا را دنبال کنید، می توانم کتاب درسی را به روز
54
00:01:49,920 –> 00:01:52,159
کنم اما نمی توانم این ویدیو را بهروزرسانی کنید، بنابراین اگر
55
00:01:52,159 –> 00:01:53,840
میخواهید به برخی از بهروزرسانیهای جدیدتر نگاه
56
00:01:53,840 –> 00:01:54,560
57
00:01:54,560 –> 00:01:56,960
کنید، topic-modeling.pythonhumanities.com را بررسی کنید،
58
00:01:57,560 –> 00:01:59,920
59
00:01:59,920 –> 00:02:02,560
بنابراین، فرکانس معکوس
60
00:02:02,560 –> 00:02:04,240
سند فرکانس
61
00:02:04,240 –> 00:02:07,119
چیست، اساساً این
62
00:02:07,119 –> 00:02:09,119
الگوریتم ریاضی یا قانون ریاضی است
63
00:02:09,119 –> 00:02:12,319
که در پس بسیاری از موارد اولیه و هنوز وجود دارد.
64
00:02:12,319 –> 00:02:13,440
در برخی از
65
00:02:13,440 –> 00:02:15,680
موتورهای جستجو استفاده می شود، این روشی برای
66
00:02:15,680 –> 00:02:16,720
67
00:02:16,720 –> 00:02:20,319
درک ارزش یک عبارت در یک سند
68
00:02:20,319 –> 00:02:24,239
نسبت به مجموعه بزرگی از اسناد است
69
00:02:24,239 –> 00:02:26,800
و در مواردی استفاده می شود
70
00:02:26,800 –> 00:02:27,280
که
71
00:02:27,280 –> 00:02:28,720
شما فرض کنید شما دارید همانطور که قرار
72
00:02:28,720 –> 00:02:30,000
است در اندکی ده هزار سند ببینیم
73
00:02:30,000 –> 00:02:30,879
74
00:02:30,879 –> 00:02:33,200
و می خواهید بدانید
75
00:02:33,200 –> 00:02:35,440
اسنادی که بیشتر به یک موضوع خاص
76
00:02:35,440 –> 00:02:36,319
77
00:02:36,319 –> 00:02:37,920
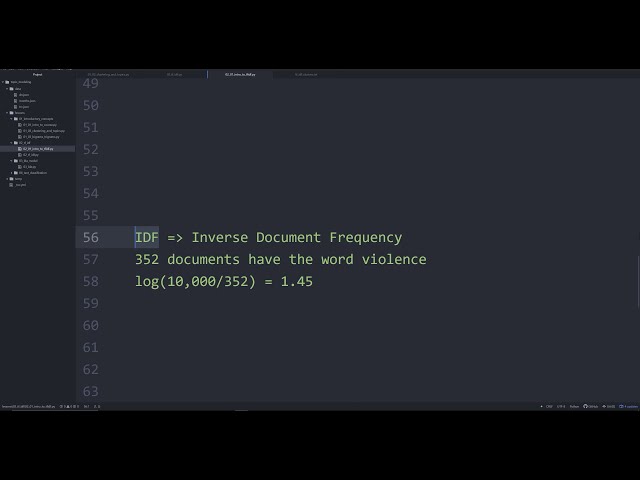
می پردازند، کلمه خشونت را می گویند که ما
78
00:02:37,920 –> 00:02:40,160
در اندکی
79
00:02:40,160 –> 00:02:42,959
tf خواهیم دید. -idf روشی است
80
00:02:42,959 –> 00:02:44,560
81
00:02:44,560 –> 00:02:47,440
که میزان استفاده از یک عبارت در یک
82
00:02:47,440 –> 00:02:48,879
سند را نسبت به
83
00:02:48,879 –> 00:02:49,680
84
00:02:49,680 –> 00:02:52,160
اسناد دیگر محاسبه میکنید، به عبارت دیگر، روشی است برای یافتن
85
00:02:52,160 –> 00:02:53,680
و پی
86
00:02:53,680 –> 00:02:57,120
بردن به ارزش جستجوهای خاص در
87
00:02:57,120 –> 00:02:58,080
یک مجموعه
88
00:02:58,080 –> 00:03:00,800
و چه اسنادی. برای اینکه
89
00:03:00,800 –> 00:03:01,599
از نظر محقق بالاتر قرار
90
00:03:01,599 –> 00:03:04,959
91
00:03:04,959 –> 00:03:07,840
92
00:03:07,840 –> 00:03:08,640
93
00:03:08,640 –> 00:03:10,560
بگیرم، در انجام برخی مدلسازی موضوعات مبتنی بر قواعد نیز مفید خواهد بود، این یک راه سریع برای دریافت حس یک
94
00:03:10,560 –> 00:03:13,120
مجموعه است، اما من از خودم جلوتر میروم،
95
00:03:13,120 –> 00:03:16,720
بنابراین به طور کلی tf idf
96
00:03:16,720 –> 00:03:20,159
همین است. سوال بعدی این است که tf idf چگونه به
97
00:03:20,159 –> 00:03:21,040
98
00:03:21,040 –> 00:03:23,440
خوبی محاسبه می شود، این یک چیز ساده است، فقط tf
99
00:03:23,440 –> 00:03:24,319
ترم فرکانس
100
00:03:24,319 –> 00:03:27,040
ضربدر فرکانس سند معکوس است،
101
00:03:27,040 –> 00:03:29,120
اما برای اینکه بفهمید چگونه به آن پاسخ
102
00:03:29,120 –> 00:03:30,480
دهید، باید بدانید که هر یک از اجزای جداگانه آن چیست.
103
00:03:30,480 –> 00:03:32,480
d چگونه
104
00:03:32,480 –> 00:03:33,760
آنها را محاسبه کنیم
105
00:03:33,760 –> 00:03:35,360
و نگران نباشید که مجبور نیستید
106
00:03:35,360 –> 00:03:37,360
این چیزها را با دست python محاسبه کنید
107
00:03:37,360 –> 00:03:39,840
و scikit-learn همه
108
00:03:39,840 –> 00:03:41,760
فرمول های ریاضی و علمی را دارد
109
00:03:41,760 –> 00:03:42,400
که باید
110
00:03:42,400 –> 00:03:44,959
این کار را به صورت خودکار انجام دهیم، بنابراین اجازه دهید ابتدا به نحوه انجام این کار بپردازیم.
111
00:03:44,959 –> 00:03:46,640
112
00:03:46,640 –> 00:03:49,840
فرکانس عبارت را محاسبه کنید و متوجه شدم که بهتر
113
00:03:49,840 –> 00:03:51,760
است واقعاً این کار را با یک مثال مطالعه موردی انجام دهید،
114
00:03:51,760 –> 00:03:52,640
115
00:03:52,640 –> 00:03:54,959
بنابراین در مثال بازی ما
116
00:03:54,959 –> 00:03:55,920
117
00:03:55,920 –> 00:03:58,080
10000 سند خواهیم داشت و هر یک از آن
118
00:03:58,080 –> 00:03:59,360
اسناد
119
00:03:59,360 –> 00:04:02,000
خوش شانس برای ما صد کلمه هستند، بنابراین
120
00:04:02,000 –> 00:04:04,239
همه آنها کاملاً عالی هستند. 100 کلمه است
121
00:04:04,239 –> 00:04:06,480
و ما می خواهیم بدانیم که
122
00:04:06,480 –> 00:04:07,760
از کلمه جستجو
123
00:04:07,760 –> 00:04:10,480
برای این نوع نمونه آزمایشی
124
00:04:10,480 –> 00:04:11,760
خشونت استفاده خواهیم کرد و این به
125
00:04:11,760 –> 00:04:13,120
ویژه مرتبط خواهد بود
126
00:04:13,120 –> 00:04:14,799
زیرا مجموعه داده هایی که در
127
00:04:14,799 –> 00:04:16,720
طول این
128
00:04:16,720 –> 00:04:20,079
مجموعه با آنها کار خواهیم کرد. خشونت و قربانیان
129
00:04:20,079 –> 00:04:22,160
خشونتی که از آپارتاید
130
00:04:22,160 –> 00:04:23,360
آفریقای جنوبی
131
00:04:23,360 –> 00:04:25,840
و شهادت های شفاهی در هولوکاست می
132
00:04:25,840 –> 00:04:26,639
آیند، اینها
133
00:04:26,639 –> 00:04:28,720
مجموعه داده های واقعی هستند که من با
134
00:04:28,720 –> 00:04:29,919
آنها کار می کنم و فکر می کنم
135
00:04:29,919 –> 00:04:32,800
برای زمان استفاده از مدل موضوعی خاص شایسته یک مطالعه موردی خوب هستند.
136
00:04:32,800 –> 00:04:33,600
137
00:04:33,600 –> 00:04:35,600
الگوریتمها و زمان
138
00:04:35,600 –> 00:04:37,199
استفاده از الگوریتمهای دیگر،
139
00:04:37,199 –> 00:04:39,360
به طوری که کلمه جستجوی ما در اینجا باشد،
140
00:04:39,360 –> 00:04:41,040
فقط یک کلمه خشونت است،
141
00:04:41,040 –> 00:04:42,960
بنابراین این مثال ما خواهد بود حالا
142
00:04:42,960 –> 00:04:44,560
بیایید سعی کنیم بگوییم که در کجا به
143
00:04:44,560 –> 00:04:46,560
یک سند نگاه میکنیم، فقط یک
144
00:04:46,560 –> 00:04:49,680
سند از هر 10 سند را بررسی کنیم. 000
145
00:04:49,680 –> 00:04:52,800
و این سند دارای کلمه خشونت است
146
00:04:52,800 –> 00:04:56,160
و 30 بار رخ می دهد بنابراین
147
00:04:56,160 –> 00:04:59,680
در 100 کلمه 30
148
00:04:59,680 –> 00:05:02,720
کاربرد کلمه خشونت را دارید به
149
00:05:02,720 –> 00:05:04,960
این ترتیب امتیاز tf را محاسبه
150
00:05:04,960 –> 00:05:08,080
می کنید.
151
00:05:08,080 –> 00:05:11,680
152
00:05:11,680 –> 00:05:13,520
کلمات موجود در سند،
153
00:05:13,5







![فیلم آموزشی: مجموعه کاراکترهای پایتون [آموزش Regex] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/lrI5wmZo-mYimage2.jpg)