در این مطلب، ویدئو آموزش PySpark در 60 دقیقه | مقدمه ای بر آپاچی اسپارک با پایتون | Edureka Live با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:22:42
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:10,240 –> 00:00:11,519
سلام به همه متشکرم برای پیوستن به
2
00:00:11,519 –> 00:00:12,480
جلسه
3
00:00:12,480 –> 00:00:14,400
که در آن سعی خواهیم کرد در مورد
4
00:00:14,400 –> 00:00:17,039
پارک ادویه چیست صحبت کنیم که مزایای
5
00:00:17,039 –> 00:00:18,640
یادگیری pi spot
6
00:00:18,640 –> 00:00:20,480
چیست و
7
00:00:20,480 –> 00:00:22,800
اگر کسی بخواهد
8
00:00:22,800 –> 00:00:25,039
تمرین کند و عملی انجام دهد چگونه نصب pi spark را انجام دهیم.
9
00:00:25,039 –> 00:00:26,880
و اصول اولیه اسپارک پی
10
00:00:26,880 –> 00:00:28,560
11
00:00:28,560 –> 00:00:30,320
چیست و ما به یک دمو کوچک عملی
12
00:00:30,320 –> 00:00:32,159
از نحوه برخورد با جرقه و
13
00:00:32,159 –> 00:00:34,160
نحوه پردازش دستگاه نگاهی خواهیم انداخت که این همان چیزی است که
14
00:00:34,160 –> 00:00:35,840
ما در 60 دقیقه در مورد آن صحبت خواهیم کرد،
15
00:00:35,840 –> 00:00:37,200
16
00:00:37,200 –> 00:00:41,040
بنابراین اکنون اجازه دهید همینطور که
17
00:00:41,040 –> 00:00:43,600
همه شما میدانید که ما
18
00:00:43,600 –> 00:00:45,920
وارد دنیای دیجیتالیسازی شدهایم،
19
00:00:45,920 –> 00:00:47,440
بنابراین آنچه که به خاطر این دیجیتالیسازی اتفاق افتاد،
20
00:00:47,440 –> 00:00:50,079
هر فردی شروع به
21
00:00:50,079 –> 00:00:52,160
تعامل با چیزی به نام
22
00:00:52,160 –> 00:00:53,840
دستگاههای دیجیتال کرد
23
00:00:53,840 –> 00:00:56,640
که باعث میشود دادههای دیجیتالی
24
00:00:56,640 –> 00:00:59,359
زیادی ایجاد شود یا به
25
00:00:59,359 –> 00:01:01,760
خصوص هر کاری
26
00:01:01,760 –> 00:01:03,120
که شما در شبکه های اجتماعی انجام می دهید،
27
00:01:03,120 –> 00:01:05,040
هر کاری که در صفحات وب انجام می دهید، تولید می شود
28
00:01:05,040 –> 00:01:07,439
و ما این داده ها را
29
00:01:07,439 –> 00:01:10,000
درست از نظر فایل های گزارش
30
00:01:10,000 –> 00:01:12,080
از نظر داده هایی که تولید می کنید تولید نمی کنیم.
31
00:01:12,080 –> 00:01:13,680
از نظر تصاویری که به اشتراک می گذارید یا هر چیز دیگری که
32
00:01:13,680 –> 00:01:14,479
هست،
33
00:01:14,479 –> 00:01:17,680
و به همین دلیل است که بسیاری از داده های ساختاریافته
34
00:01:17,680 –> 00:01:19,840
و بدون ساختار نیز درست
35
00:01:19,840 –> 00:01:21,200
تولید می
36
00:01:21,200 –> 00:01:22,799
شوند، تعداد زیادی داده ساختاریافته یا
37
00:01:22,799 –> 00:01:24,000
بدون ساختار
38
00:01:24,000 –> 00:01:27,439
تولید می شوند تا ضبط
39
00:01:27,439 –> 00:01:29,079
یا پردازش این
40
00:01:29,079 –> 00:01:31,840
نیمه نیمه را ذخیره کنند. دادههای ساختاریافته یا بدون ساختار
41
00:01:31,840 –> 00:01:34,400
سیستمهای rdbms موجود به
42
00:01:34,400 –> 00:01:36,799
اندازه کافی کافی نیستند و به همین دلیل است که مردم
43
00:01:36,799 –> 00:01:37,840
چیزی به نام
44
00:01:37,840 –> 00:01:40,159
ذخیرهسازیهای توزیعشده و
45
00:01:40,159 –> 00:01:42,640
محاسبات توزیعشده مانند هادوپ دارند
46
00:01:42,640 –> 00:01:45,520
که در آن هادوپ چارچوبی دارد که
47
00:01:45,520 –> 00:01:47,600
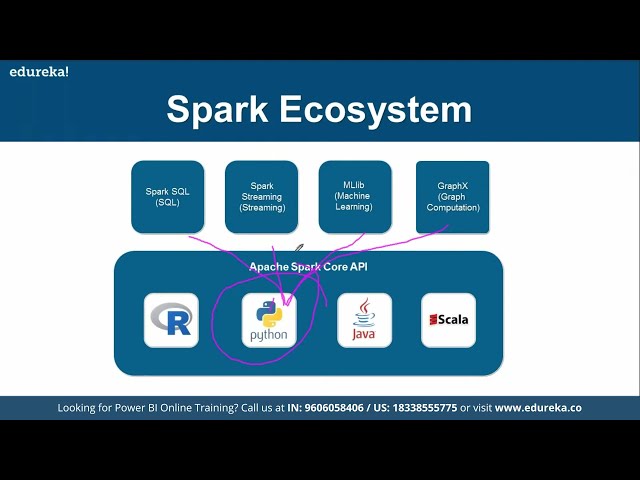
با استفاده از یک زبان برنامهنویسی
48
00:01:47,600 –> 00:01:50,960
به نام java hadoop به عنوان چارچوبی
49
00:01:50,960 –> 00:01:52,720
ساخته شده است که با استفاده از آن ساخته شده است. یک زبان برنامه نویسی
50
00:01:52,720 –> 00:01:55,920
به نام جاوا که در آن می توانیم
51
00:01:55,920 –> 00:01:57,680
از هادوپ استفاده
52
00:01:57,680 –> 00:01:59,920
کنیم، می توانیم هادوپ را
53
00:01:59,920 –> 00:02:02,000
در بالای سیستم های توزیع شده در بالای
54
00:02:02,000 –> 00:02:03,920
خوشه های توزیع شده در گروهی از
55
00:02:03,920 –> 00:02:06,320
خوشه ها نصب کنیم و می توانیم داده ها را ذخیره
56
00:02:06,320 –> 00:02:08,878
کنیم و می توانیم داده ها را با استفاده از موتور کاهش نقشه پردازش کنیم
57
00:02:08,878 –> 00:02:11,200
تا جایی که هادوپ خواهد شد. دارای دو
58
00:02:11,200 –> 00:02:15,200
جزء اصلی مانند hvfs
59
00:02:17,280 –> 00:02:19,440
است که برای ذخیره داده ها استفاده می شود
60
00:02:19,440 –> 00:02:23,520
و همچنین چیزی به نام قرمز داریم
61
00:02:23,920 –> 00:02:25,120
درست است، ما همچنین چیزی به نام
62
00:02:25,120 –> 00:02:27,200
کاهش نقشه داریم که اساساً می تواند به ما
63
00:02:27,200 –> 00:02:30,000
در پردازش داده ها کمک کند، بنابراین ما نیز
64
00:02:30,000 –> 00:02:32,239
قادر خواهیم بود تا ما مردمی که استفاده می کردیم
65
00:02:32,239 –> 00:02:34,319
داده ها را ذخیره کرده و داده ها را با استفاده از چارچوب چوب سخت پردازش کنیم،
66
00:02:34,319 –> 00:02:35,200
67
00:02:35,200 –> 00:02:37,599
در حالی که mapreduce قبلاً بسیار سریعتر از
68
00:02:37,599 –> 00:02:39,519
mapreduce استفاده می شد. برای پردازش داده ها بسیار
69
00:02:39,519 –> 00:02:42,080
سریع و با در نظر گرفتن این واقعیت که
70
00:02:42,080 –> 00:02:44,239
mapreduce به شدت به
71
00:02:44,239 –> 00:02:47,440
چیزی به نام عملیات خروجی ورودی بستگی دارد
72
00:02:47,440 –> 00:02:48,800
که به
73
00:02:48,800 –> 00:02:52,000
چندین برنامه mapreduce برای شروع
74
00:02:52,000 –> 00:02:54,480
خواندن داده ها و نوشتن داده ها
75
00:02:54,480 –> 00:02:57,040
از یا روی دیسک نیاز دارد که باعث می شود
76
00:02:57,040 –> 00:02:59,920
کل اجرا بسیار زیاد شود.
77
00:02:59,920 –> 00:03:02,080
آجرهای داده کندتر به عنوان یک سازمان
78
00:03:02,080 –> 00:03:04,319
چیزی به نام spar ارائه
79
00:03:04,319 –> 00:03:06,239
کرده است که یک موتور محاسباتی است که یک
80
00:03:06,239 –> 00:03:08,239
موتور پردازش داده موتور پردازش داده
81
00:03:08,239 –> 00:03:10,319
است که صرفاً با استفاده از
82
00:03:10,319 –> 00:03:11,920
زبان برنامه نویسی Scala ساخته شده است،
83
00:03:11,920 –> 00:03:13,440
در حالی که
84
00:03:13,440 –> 00:03:15,200
به برخی از زبان های دیگر نیز بستگی
85
00:03:15,200 –> 00:03:16,640
دارد که در دسترس هستند.
86
00:03:16,640 –> 00:03:18,720
فقط در بالای اسکالا
87
00:03:18,720 –> 00:03:20,159
ساخته می شود و همچنین با استفاده از برخی
88
00:03:20,159 –> 00:03:21,920
زبان های دیگر مانند جاوا ساخته می شود
89
00:03:21,920 –> 00:03:24,000
جنبه ها، یعنی
90
00:03:24,000 –> 00:03:25,840
برای نوشتن هر چیزی به منظور
91
00:03:25,840 –> 00:03:28,480
پیاده سازی هر چیزی که می دانید در
92
00:03:28,480 –> 00:03:30,560
sparkcore باید یک زبان برنامه نویسی
93
00:03:30,560 –> 00:03:33,680
به نام اسکالا بلد باشید، اما یادگیری اسکالا
94
00:03:33,680 –> 00:03:35,200
چیزی است که بسیار دشوار
95
00:03:35,200 –> 00:03:36,720
است که کم و بیش
96
00:03:36,720 –> 00:03:39,599
شبیه به جاوا مردم است. کسی که در جاوا کار می کرد
97
00:03:39,599 –> 00:03:41,360
شخصی که در جاوا کار می
98
00:03:41,360 –> 00:03:43,360
کرد از جاوا خارج شد و سپس من شروع به
99
00:03:43,360 –> 00:03:44,879
ساختن Scala کردم که
100
00:03:44,879 –> 00:03:47,040
مزایای دیگری مانند تغییرپذیری ریخته گری و دعوت پذیری را
101
00:03:47,040 –> 00:03:48,319
دارم چیزهای زیادی
102
00:03:48,319 –> 00:03:50,480
در اسکالا پیاده سازی شده است که عمدتا
103
00:03:50,480 –> 00:03:52,720
مخفف مقیاس پذیری است و به همین دلیل است که
104
00:03:52,720 –> 00:03:55,280
از مفهوم اسکالا برای
105
00:03:55,280 –> 00:03:57,519
ساخت این قسمت به عنوان فریمورک استفاده می شود و
106
00:03:57,519 –> 00:03:59,200
با توجه به اینکه
107
00:03:59,200 –> 00:04:01,360
یادگیری و پارک برای افراد بسیار سخت است
108
00:04:01,360 –> 00:04:03,840
فریم ورک یا api آنها را نیز
109
00:04:03,840 –> 00:04:05,599
با زبان های برنامه نویسی دیگر مانند
110
00:04:05,599 –> 00:04:07,760
پایتون java r ادغام کرده است
111
00:04:07,760 –> 00:04:09,760
تا در صورت تمایل برای
112
00:04:09,760 –> 00:04:11,760
پردازش داده های خود در اسپارک به این معنا نیست که شما فقط می توانید
113
00:04:11,760 –> 00:04:14,480
از رنگی استفاده کنید که جرقه
114
00:04:14,480 –> 00:04:16,238
اصلی چیزی نیست، بلکه یک جرقه با scala
115
00:04:16,238 –> 00:04:18,399
است در حالی که th چند پسوند
116
00:04:18,399 –> 00:04:20,238
ایجاد شده است تا بتوانیم با استفاده از زبان های دیگر مانند پایتون جاوا شروع به نوشتن
117
00:04:20,238 –> 00:04:21,918
منطق شما یا ساختن برنامه های کاربردی شما
118
00:04:21,918 –> 00:04:24,160
119
00:04:24,160 –> 00:04:25,759
کنیم،
120
00:04:25,759 –> 00:04:27,520
با توجه به این واقعیت که پایتون یکی
121
00:04:27,520 –> 00:04:29,440
از پرکاربردترین
122
00:04:29,440 –> 00:04:31,520
زبان های برنامه نویسی است به دلایل متعددی که
123
00:04:31,520 –> 00:04:33,600
دارد بسیار زیاد است. پسوندها زیرا
124
00:04:33,600 –> 00:04:35,759
یادگیری آن بسیار آسان است و توصیه شده
125
00:04:35,759 –> 00:04:37,440
یا ترجیح داده شده ترین زبان برنامه نویسی
126
00:04:37,440 –> 00:04:39,360
توسط چندین نفر است و به همین دلیل است که این
127
00:04:39,360 –> 00:04:41,759
پایتون در
128
00:04:41,759 –> 00:04:43,759
مقایسه با اسکالا بسیار معروف شده است،
129
00:04:43,759 –> 00:04:45,520
اگر از من بپرسید فکر می کنم اکثر
130
00:04:45,520 –> 00:04:46,960
مردم واقعاً از pi استفاده می کنند. مربع در مقایسه
131
00:04:46,960 –> 00:04:48,639
با پروناتورها، یکی
132
00:04:48,639 –> 00:04:49,840
و بیشتر سازمانها
133
00:04:49,840 –> 00:04:51,360
ترجیح میدهند به سراغ لولهها و توسعهدهندگان بروند،
134
00:04:51,360 –> 00:04:52,880
زیرا به راحتی میتوان
135
00:04:52,880 –> 00:04:55,280
افراد پایتون را به افراد در پایتون متصل کرد، همچنین
136
00:04:55,280 –> 00:04:57,680
اگر کسی بخواهد یاد بگیرد
137
00:04:57,680 –> 00:04:58,800
و این همان چیزی است که شما در نهایت از
138
00:04:58,800 –> 00:05:01,280
این پایتون استفاده میکنید. با توجه به اینکه هسته
139
00:05:01,280 –> 00:05:03,039
نمی تواند همه چیز را حفظ
140
00:05:03,039 –> 00:05:04,800
کند و اسپارک چندین
141
00:05:04,800 –> 00:05:07,120
کتابخانه مانند spark sql ایجاد کرده است،
142
00:05:07,120 –> 00:05:09,680
بنابراین مسیر sql در هسته اسپا است که ممکن است
143
00:05:09,680 –> 00:05:11,199
مجبور شوید شروع به نوشتن معامله خود با
144
00:05:11,199 –> 00:05:13,520
موجودیت های خود کنید که می تواند به شما کمک کند
145
00:05:13,520 –> 00:05:15,440
داده های پردازشی خود را ابتدا
146
00:05:15,440 –> 00:05:17,840
با استفاده از uh rdds پیاده سازی کنید و ممکن است مجبور
147
00:05:17,840 –> 00:05:20,000
شوید شروع خود را برای نوشتن توابع خود بنویسید
148
00:05:20,000 –> 00:05:21,680
و این جایی است که مردم به این نتیجه رسیده اند.
149
00:05:21,680 –> 00:05:23,600
چیزی به نام کتابخانه های دیگر
150
00:05:23,600 –> 00:05:25,840
که در بالای اسپارک
151
00:05:25,840 –> 00:05:27,360
درست سطوح دیگری نیز ساخته شده اند که با استفاده از اسپارک ساخته می شوند،
152
00:05:27,360 –> 00:05:30,400
153
00:05:30,400 –> 00:05:32,960
بنابراین استفاده از اسپارک با پایتون چه مزایایی دارد،
154
00:05:32,960 –> 00:05:35,199
بنابراین همانطور که گفتم
155
00:05:35,199 –> 00:05:37,280
یادگیری آسان است که یکی از اولین
156
00:05:37,280 –> 00:05:39,360
مزیت هاست. و api های بسیار ساده و
157
00:05:39,360 –> 00:05:40,720
بسیار جامعی بود که در
158
00:05:40,720 –> 00:05:42,720
دسترس هستند و می توانید موارد را
159
00:05:42,720 –> 00:05:44,560
به روشی بهتر کدنویسی کنید زیرا بسیاری از
160
00:05:44,560 –> 00:05:46,160
عملکردها می توانند به شما کمک کنند تا
161
00:05:46,160 –> 00:05:48,080
هسته کلی و توابع ساخت را کاهش دهید و
162
00:05:48,080 –> 00:05:50,080
همچنین می توانید دید ایجاد کنید معمولاً
163
00:05:50,080 –> 00:05:51,360
می توانید آنچه را نیز تجسم کنید.
164
00:05:51,360 –> 00:05:52,800
مواردی هستند که در حال رخ دادن هستند و
165
00:05:52,800 –> 00:05:54,720
166
00:05:54,720 –> 00:05:56,639
اگر بخواهید دوباره
167
00:05:56,639 –> 00:05:58,240
برنامه نویسی فیلتر آبجکت خود را پیاده سازی کنید، حفظ کد خود به عنوان بخشی از ماژول ها بسیار آسان خواهد بود.
168
00:05:58,240 –> 00:05:59,919
از جمله پیاده سازی
169
00:05:59,919 –> 00:06:01,840
برنامه نویسی تابعی شما و تعداد
170
00:06:01,840 –> 00:06:03,520
زیادی کتابخانه
171
00:06:03,520 –> 00:06:05,520
که توسط زبان هایی مانند پایتون پشتیبانی می شوند وجود
172
00:06:05,520 –> 00:06:06,400
دارد
173
00:06:06,400 –> 00:06:08,160
و با توجه به اینکه پایتون یک
174
00:06:08,160 –> 00:06:09,759
جامعه بسیار قوی دارد و شما افراد زیادی خواهید داشت
175
00:06:09,759 –> 00:06:11,360
که می توانند به شما کمک کنند تا
176
00:06:11,360 –> 00:06:13,520
با آن به آن فایل نیز رسیدگی کنید.
177
00:06:13,520 –> 00:06:15,199
بنابراین این مزیت برای
178
00:06:15,199 –> 00:06:16,479
پایتون بود،
179
00:06:16,479 –> 00:06:18,000
بنابراین چه چیزهایی وجود دارد که چگونه
180
00:06:18,000 –> 00:06:19,919
pi spark را نصب کنیم در صورتی که می خواهید pi spark را نصب کنید
181
00:06:19,919 –> 00:06:22,039
تا بتوانیم به
182
00:06:22,039 –> 00:06:23,840
spark.apache.org بروید، شما می توانید به سادگی
183
00:06:23,840 –> 00:06:25,039
به صفحه گوگل خود بروید. می توانید شروع به
184
00:06:25,039 –> 00:06:26,560
جستجوی آن کنید،
185
00:06:26,560 –> 00:06:28,080
آخرین نسخه را به شما می دهد، همچنین می توانید
186
00:06:28,080 –> 00:06:30,319
آن را نصب کنید، بنابراین وقتی آن را دریافت کردید، بنابراین می
187
00:06:30,319 –> 00:06:32,000
توانید ببینید که باید
188
00:06:32,000 –> 00:06:33,759
پیپ خود را نیز در لحظه نصب
189
00:06:33,759 –> 00:06:35,759
پایتون نصب کنید، آن را نیز دریافت خواهید کرد و همچنین می توانید
190
00:06:35,759 –> 00:06:36,960
شروع به نصب نوت بوک jupyter کنید،
191
00:06:36,960 –> 00:06:38,800
همچنین می توانید مستقیماً از این نصب ها استفاده
192
00:06:38,800 –> 00:06:40,639
کنید، می توانید پیکربندی آن را شروع کنید
193
00:06:40,639 –> 00:06:42,880
، بنابراین هنگامی که این و آن را نصب کردید،
194
00:06:42,880 –> 00:06:44,560
تنظیماتی وجود خواهد داشت
195
00:06:44,560 –> 00:06:46,160
که در نهایت با آنها انجام می دهید.
196
00:06:46,160 –> 00:06:48,400
با احترام به روشی که چگونه
197
00:06:48,400 –> 00:06:50,400
می توان این مراحل را اجرا کرد و ممکن است
198
00:06:50,400 –> 00:06:51,759
مجبور شوید برخی از
199
00:06:51,759 –> 00:06:53,360
فایل های پیکربندی را تغییر دهید، همه چیز در
200
00:06:53,360 –> 00:06:55,440
خوشه شما خوب است، بنابراین می توانید من نیز بتوانم
201
00:06:55,440 –> 00:06:57,759
از آن در کل کار استفاده کنم،
202
00:06:57,759 –> 00:06:59,680
بنابراین اصول اولیه جرقه چیست؟
203
00:06:59,680 –> 00:07:01,840
بنابراین برای شروع با اسپار
204
00:07:01,840 –> 00:07:04,319
اول از همه، اسپارک نیز
205
00:07:04,319 –> 00:07:06,560
با استفاده از معماری استاد و برده ساخته میشود،
206
00:07:06,560 –> 00:07:09,039
اسپارک راست بهعنوان فریمورک نیز
207
00:07:09,039 –> 00:07:11,120
با استفاده از معماری استاد و برده ساخته میشود
208
00:07:11,120 –> 00:07:13,120
که در نهایت با فعال کردن
209
00:07:13,120 –> 00:07:15,199
زمینه اسپار ابتدا با استفاده از زمینه جرقهای
210
00:07:15,199 –> 00:07:16,960
که در ابتدای برنامه خود و
211
00:07:16,960 –> 00:07:18,800
با استفاده از زمینه spar که قرار است
212
00:07:18,800 –> 00:07:20,720
زمینه اسپارک خود را شروع کنید بسیار
213
00:07:20,720 –> 00:07:22,240
خوب است و سپس می توانید شروع به ایجاد
214
00:07:22,240 –> 00:07:24,639
rdds خود در بالای داده های خود کنید، پس از
215
00:07:24,639 –> 00:07:26,720
ایجاد rdds که می توانید شروع کنید،
216
00:07:26,720 –> 00:07:28,800
چندین پیکربندی
217
00:07:28,800 –> 00:07:30,639
سیستم های فایل های spark و فریم های داده و به
218
00:07:30,639 –> 00:07:32,080
همین ترتیب چندین چیز وجود دارد که
219
00:07:32,080 –> 00:07:33,520
در دسترس هستند و شما شروع به
220
00:07:33,520 –> 00:07:35,360
یادگیری آن چیزها به عنوان بخشی از زمینه انتقال خود خواهید کرد، البته
221
00:07:35,360 –> 00:07:37,360
به عنوان بخشی از کار
222
00:07:37,360 –> 00:07:39,360
شما بنابراین، اکنون کاری که میخواهید
223
00:07:39,360 –> 00:07:40,800
انجام دهید، بررسی خواهیم کرد که چگونه
224
00:07:40,800 –> 00:07:44,360
خوشه خود را راهاندازی کنیم،
225
00:07:44,639 –> 00:07:45,520
226
00:07:45,520 –> 00:07:47,120
بنابراین اکنون زمانی که آزمایشگاه ابری خود را باز
227
00:07:47,120 –> 00:07:48,639
میکنید، قادر خواهید
228
00:07:48,639 –> 00:07:50,319
بود مستقیماً بتوانید زمینه جرقه خود را به هم متصل کنید
229
00:07:50,319 –> 00:07:51,919
و همه چیزهایی را که میبینید، من
230
00:07:51,919 –> 00:07:53,759
تمام کتابخانههایی را وارد میکنم که میتوانم
231
00:07:53,759 –> 00:07:56,319
از آنها برای ایجاد زمینههای spar و
232
00:07:56,319 –> 00:07:57,360
جلسه اسپارک خود استفاده کنم،
233
00:07:57,360 –> 00:07:59,680
بنابراین در نهایت با
234
00:07:59,680 –> 00:08:02,319
فعال کردن زمینه اسپارک در اینجا خوب است، بنابراین
235
00:08:02,319 –> 00:08:03,840
اکنون میخواهم چیزی به نام ساده ایجاد کنم.
236
00:08:03,840 –> 00:08:05,599
برنامه ای با نام برنامه
237
00:08:05,599 –> 00:08:07,039
که در آن من قصد دارم این
238
00:08:07,039 –> 00:08:08,960
نام برنامه را در اینجا راه اندازی کنم و جایی که
239
00:08:08,960 –> 00:08:10,960
فقط یک نام از آن اضافه می کنم و اگر
240
00:08:10,960 –> 00:08:12,560
اینجا جایی است که من یک زمینه جرقه ایجاد می
241
00:08:12,560 –> 00:08:14,720
کنم، می توانید ببینید که دارم ایجاد می کنم یک زمینه جرقه
242
00:08:14,720 –> 00:08:16,720
چیزی نیست جز اینکه من در اینجا در spark cluster فلان
243
00:08:16,720 –> 00:08:18,400
برنامه به نام یک برنامه را
244
00:08:18,400 –> 00:08:20,160
راه اندازی می کنم.
245
00:08:20,160 –> 00:08:22,479
246
00:08:22,479 –> 00:08:23,840
247
00:08:23,840 –> 00:08:24,840
248
00:08:24,840 –> 00:08:27,280
می خواهم یاد بگیرم و
249
00:08:27,280 –> 00:08:30,080
این یک آزمایشگاه ابری است که در aws ارسال
250
00:08:30,080 –> 00:08:31,680
شده است ws شما با
251
00:08:31,680 –> 00:08:33,120
داشتن این پوشه تمام
252
00:08:33,120 –> 00:08:34,479
میشوید و میتوانید ببینید که فایلهایی
253
00:08:34,479 –> 00:08:36,320
وجود دارند که نوشته شدهاند، من یک تابع
254
00:08:36,320 –> 00:08:38,719
با استفاده از پایتون نوشتم، یک تابع پایتون معمولی است
255
00:08:38,719 –> 00:08:40,159
که مقداری ورودی میگیرد و
256
00:08:40,159 –> 00:08:42,080
به طور خودکار کاربر من را آماده میکند
257
00:08:42,080 –> 00:08:44,080
و سعی خواهد کرد به هر
258
00:08:44,080 –> 00:08:47,760
فایلی که به عنوان ورودی به عنوان موقعیت مکانی خود ارسال می کنم به نقطه ای مراجعه کنید
259
00:08:47,760 –> 00:08:49,519
تا بتوانم ببینم که سعی می کنم
260
00:08:49,519 –> 00:08:50,880
چندین فایل پردازشی را ارسال کنم که
261
00:08:50,880 –> 00:08:52,800
در مکان hdfs من موجود است، آنها
262
00:08:52,800 –> 00:08:56,399
قبلاً در دسترس
263
00:08:56,399 –> 00:08:59,120
هستند فایل sample.txt eggpots.csv readme.md با ما از چند متن معمولی
264
00:08:59,120 –> 00:09:01,040
استفاده می کنیم که
265
00:09:01,040 –> 00:09:03,040
در دسترس هستند و من می خواستم شروع به
266
00:09:03,040 –> 00:09:05,680
ایجاد rdds کنم تا جایی که rdd مخفف
267
00:09:05,680 –> 00:09:08,160
مجموعه داده های توزیع شده انعطاف پذیر است و
268
00:09:08,160 –> 00:09:09,920
این چیزی نیست جز هر چیزی که می خواهید به
269
00:09:09,920 –> 00:09:12,320
عنوان rtd ایجاد کنید، ما می توانیم rds را
270
00:09:12,320 –> 00:09:14,160
تصور کنیم. این یک نوع مانند یک
271
00:09:14,160 –> 00:09:16,160
نوع داده خوب است به عنوان یک ساختار داده که
272
00:09:16,160 –> 00:09:18,640
جرقه ای در بالای هر چیزی
273
00:09:18,640 –> 00:09:20,080
که می خواهید پردازش کنید ایجاد می کند و در نهایت با
274
00:09:20,080 –> 00:09:22,480
ایجاد یک rdd در بالای rdd
275
00:09:22,480 –> 00:09:23,920
می توانید شروع به ایجاد کنید.
276
00:09:23,920 –> 00:09:25,920
با استفاده از داده های خود می توانید شروع به
277
00:09:25,920 –> 00:09:27,440
پیاده سازی Api های متعددی کنید که
278
00:09:27,440 –> 00:09:29,440
در بالای این فایل موجود است
279
00:09:29,440 –> 00:09:31,200
تفاوت بین mapreduce و spark
280
00:09:31,200 –> 00:09:33,680
همانطور که گفتم
281
00:09:33,680 –> 00:09:36,720
mapreduce یک محاسبه است که توسط هادوپ به
282
00:09:36,720 –> 00:09:38,800
طور پیش فرض به شما داده می شود که در آن قرار است
283
00:09:38,800 –> 00:09:41,519
برنامه کتابخانه مبتنی بر جاوا خود را بنویسید
284
00:09:41,519 –> 00:09:42,560
در حالی که
285
00:09:42,560 –> 00:09:45,440
اسپارک یک محاسبه جداگانه است، مثل این است که
286
00:09:45,440 –> 00:09:47,040
تصور کنید یک نوع
287
00:09:47,040 –> 00:09:48,800
زبان برنامه نویسی متفاوت است،
288
00:09:48,800 –> 00:09:51,600
اما ستاره مزایای بیشتری
289
00:09:51,600 –> 00:09:53,839
از نظر پردازش موازی شما دارد
290
00:09:53,839 –> 00:09:55,279
، مانند تکنیک های کش، تکنیک های
291
00:09:55,279 –> 00:09:57,279
بهینه سازی
292
00:09:57,279 –> 00:09:59,519
حافظه و نظارت بر حافظه و اینکه
293
00:09:59,519 –> 00:10:02,240
چگونه می توانید نحوه مشاهده خود را فعال کنید. برچسب شما تمام
294
00:10:02,240 –> 00:10:03,680
گزینه هایی که توسط smart داده شده است و
295
00:10:03,680 –> 00:10:06,079
ما نمی توانیم آن را در محصول من انتظار داشته باشیم،
296
00:10:06,079 –> 00:10:08,079
با توجه به این واقعیت که
297
00:10:08,079 –> 00:10:11,040
می دانید با استفاده از تمام این مزایای
298
00:10:11,040 –> 00:10:13,680
اسپار، انتظار می رود که اسپارک
299
00:10:13,680 –> 00:10:16,800
بتواند داده ها را 10 تا 100 برابر سریعتر
300
00:10:16,800 –> 00:10:19,519
از نقشه کاهش معمولی پردازش
301
00:10:19,519 –> 00:10:21,040
کند. که شما از
302
00:10:21,040 –> 00:10:22,480
بسیاری از چیزهایی که
303
00:10:22,480 –> 00:10:25,760
حداکثر در دسترس هستند مراقبت می کنید و اسپارک شما را تولید می کند
304
00:10:25,760 –> 00:10:28,240
انتظار می رود داده های شما را پردازش کند و 200
305
00:10:28,240 –> 00:10:29,920
برابر سریعتر از
306
00:10:29,920 –> 00:10:32,399
برنامه مسابقه نقشه معمولی خوب است و این همان
307
00:10:32,399 –> 00:10:34,560
جایی است که مزیت اصلی اسپا
308
00:10:34,560 –> 00:10:36,240
درست است، بنابراین جایی که من سعی می کنم از
309
00:10:36,240 –> 00:10:37,680
عملی به نام جمع آوری جایی که قرار است
310
00:10:37,680 –> 00:10:38,959
جمع آوری شود استفاده کنم، عملی است که من از آن فراخوانی می کنم.
311
00:10:38,959 –> 00:10:41,040
یک نقطه c موازی شده است یک
312
00:10:41,040 –> 00:10:42,480
تبدیل
313
00:10:42,480 –> 00:10:44,160
خوب است که در آن دادههای
314
00:10:44,160 –> 00:10:45,680
موجود در این رشته خاص را
315
00:10:45,680 –> 00:10:46,640
316
00:10:46,640 –> 00:10:48,560
317
00:10:48,560 –> 00:10:50,720
میخواند، جایی که من سعی میکنم از یک مجموعه استفاده کنم یک نام rdd است، زیرا من فقط
318
00:10:50,720 –> 00:10:52,640
به عنوان یک نام تعریف شده توسط کاربر استفاده میکنم.
319
00:10:52,640 –> 00:10:54,640
مجموعه ای که در بالای این rdd یک فرمت rdd ایجاد می کند،
320
00:10:54,640 –> 00:10:57,200
من
321
00:10:57,200 –> 00:10:59,519
یک عمل را فراخوانی می کنم، بنابراین عملی به نام جمع می
322
00:10:59,519 –> 00:11:01,279
شود که هر رکورد
323
00:11:01,279 –> 00:11:03,120
را تقسیم می کند و هر رکورد را به
324
00:11:03,120 –> 00:11:05,040
کلمه جداگانه تقسیم می کند، به نوعی شبیه یک
325
00:11:05,040 –> 00:11:06,480
عمل است که من کار کرده ام
326
00:11:06,480 –> 00:11:08,480
و وقتی این کار انجام شد،
327
00:11:08,480 –> 00:11:10,079
دوباره دارم تابع دیگری به نام
328
00:11:10,079 –> 00:11:13,040
تابع نقشه را در بالای این rdd سمت راست لامبدای
329
00:11:13,040 –> 00:11:15,120
کلمه می نویسم، سعی می کنم یک
33