در این مطلب، ویدئو K-نزدیکترین همسایه طبقه بندی با پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:07:38
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,560 –> 00:00:02,639
به عقب خوش آمدید نام من دارن توماس است
2
00:00:02,639 –> 00:00:04,400
و من مدیر تکنیک های تحقیق آموزشی هستم
3
00:00:04,400 –> 00:00:05,920
4
00:00:05,920 –> 00:00:07,919
در این ویدیو ما قصد
5
00:00:07,919 –> 00:00:09,519
داریم به k نزدیکترین همسایه برای
6
00:00:09,519 –> 00:00:11,040
طبقه بندی
7
00:00:11,040 –> 00:00:13,440
با پایتون نگاهی بیندازیم، پس بیایید جلو برویم و ببینیم
8
00:00:13,440 –> 00:00:16,320
چه چیزهایی می توانیم یاد بگیریم
9
00:00:16,320 –> 00:00:18,560
بنابراین با k- نزدیکترین همسایههایی
10
00:00:18,560 –> 00:00:21,680
که میخواستید یک مشاهده ناشناخته را
11
00:00:21,680 –> 00:00:23,279
بر اساس مشاهداتی که در
12
00:00:23,279 –> 00:00:24,800
اطراف آن وجود دارد پیشبینی کنید، میدانید که
13
00:00:24,800 –> 00:00:26,880
مانند یک فضای چند بعدی نقشهبرداری شده است،
14
00:00:26,880 –> 00:00:29,359
بنابراین بیایید بگوییم من این مرد را اینجا
15
00:00:29,359 –> 00:00:31,920
دارم، نمیدانم او چیست.
16
00:00:31,920 –> 00:00:34,000
کنجکاو یک علامت سوال گذاشت اما من
17
00:00:34,000 –> 00:00:36,480
این مرد را می شناسم من این مرد را می شناسم و این مرد را می شناسم
18
00:00:36,480 –> 00:00:37,680
19
00:00:37,680 –> 00:00:40,719
و بنابراین با
20
00:00:40,719 –> 00:00:43,680
دانستن طبقه بندی
21
00:00:43,680 –> 00:00:46,960
همسایه های اطرافش می توانم استنباط کنم
22
00:00:46,960 –> 00:00:49,680
که او چیست، بنابراین به
23
00:00:49,680 –> 00:00:52,480
نوعی کار می کند و به طور معمول مانند
24
00:00:52,480 –> 00:00:55,120
یک سیستم رای گیری است، بنابراین اگر من دو رای
25
00:00:55,120 –> 00:00:57,600
در اینجا داشته باشم، بیایید بگوییم که این مانند یک بله یا خیر است،
26
00:00:57,600 –> 00:00:59,680
بنابراین این مرد یک بله است این مرد یک بله است و
27
00:00:59,680 –> 00:01:02,800
این مرد یک خیر است اگر k من سه باشد،
28
00:01:02,800 –> 00:01:04,959
بنابراین من هستم به سه همسایه خوب نگاه می کنم
29
00:01:04,959 –> 00:01:07,840
، دوتا دارم بله s و من یک نه داریم، بنابراین
30
00:01:07,840 –> 00:01:09,439
میخواهم فرض کنم مردی که در این وسط
31
00:01:09,439 –> 00:01:11,439
قرار دارد نیز یک بله است، به عنوان مثالی از اینکه چگونه
32
00:01:11,439 –> 00:01:12,560
این کار اکنون کار میکند،
33
00:01:12,560 –> 00:01:14,320
ما میتوانیم با
34
00:01:14,320 –> 00:01:16,000
نگاه کردن به ریاضیات و همه
35
00:01:16,000 –> 00:01:18,400
چیزهایی که در پشت آن وجود دارد، آن را پیچیدهتر کنیم. الگوریتم
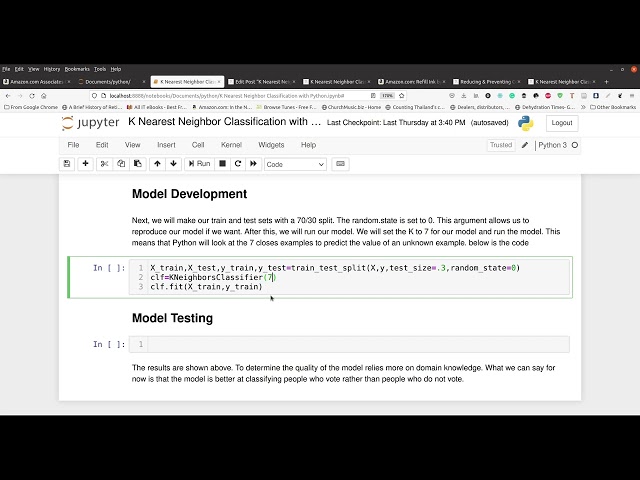
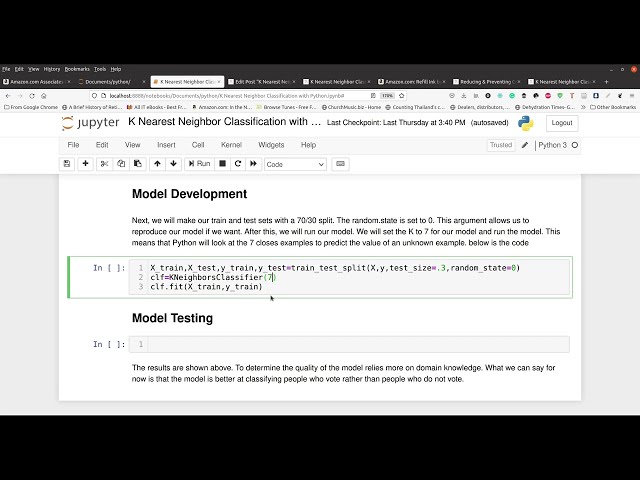
36
00:01:18,400 –> 00:01:19,759
اما ما آن را در همین جا رها می کنیم
37
00:01:19,759 –> 00:01:21,680
زیرا ما بیشتر بر یادگیری
38
00:01:21,680 –> 00:01:23,920
نحوه استفاده از پایتون متمرکز هستیم تا اینکه
39
00:01:23,920 –> 00:01:26,159
درباره مکانیک الگوریتم
40
00:01:26,159 –> 00:01:28,880
و ریاضیات مرتبط با آن
41
00:01:28,880 –> 00:01:29,840
بیاموزیم، بنابراین
42
00:01:29,840 –> 00:01:31,520
کاری که می خواهیم انجام دهیم این است که ما
43
00:01:31,520 –> 00:01:33,439
میخواهیم طبقهبندی کنیم که آیا
44
00:01:33,439 –> 00:01:35,200
میدانید مردم رای دادهاند یا نه،
45
00:01:35,200 –> 00:01:36,960
بر اساس
46
00:01:36,960 –> 00:01:39,840
مجموعه دادههایی که ما در اینجا استفاده میکنیم
47
00:01:39,840 –> 00:01:41,119
، همان چیزی است که استفاده میکنیم یا این همان کاری است که
48
00:01:41,119 –> 00:01:44,000
49
00:01:44,399 –> 00:01:46,720
ما انجام میدهیم. ابتدا
50
00:01:46,720 –> 00:01:48,640
اولین سلول خود را در اینجا مسدود کنید
51
00:01:48,640 –> 00:01:50,399
که کد خود را در اینجا داریم، بنابراین من میروم
52
00:01:50,399 –> 00:01:51,840
و این را اجرا
53
00:01:51,840 –> 00:01:53,040
میکنم البته از
54
00:01:53,040 –> 00:01:54,960
مجموعه داده pi استفاده میکنیم، جایی که دادههای ما از آنجا
55
00:01:54,960 –> 00:01:58,000
میآیند و پانداها را وارد میکنیم.
56
00:01:58,000 –> 00:02:01,439
انتخاب مدل در اینجا از um sklearn برای
57
00:02:01,439 –> 00:02:02,960
تقسیم داده های ما
58
00:02:02,960 –> 00:02:03,759
59
00:02:03,759 –> 00:02:06,000
و شماره خط f ما جایی است که
60
00:02:06,000 –> 00:02:08,479
طبقهبندیکننده خود را از آن الگوریتم دریافت میکنیم
61
00:02:08,479 –> 00:02:10,318
و سپس خط شماره پنج زمانی است که ما به آن
62
00:02:10,318 –> 00:02:12,000
نگاه میکنیم، وقتی
63
00:02:12,000 –> 00:02:14,480
مدل خود را
64
00:02:14,480 –> 00:02:16,160
اکنون برای آمادهسازی واقعی ارزیابی میکنیم، خروجی را میدانید،
65
00:02:16,160 –> 00:02:18,560
برای این ویدیو بسیار ساده است،
66
00:02:18,560 –> 00:02:20,560
چیز زیادی نیست برای
67
00:02:20,560 –> 00:02:22,800
آماده سازی آن به جز بارگذاری
68
00:02:22,800 –> 00:02:24,640
مجموعه داده های ما و جدا کردن
69
00:02:24,640 –> 00:02:26,959
متغیرهای مستقل از متغیرهای وابسته، اگر
70
00:02:26,959 –> 00:02:28,560
جزئیات بیشتری در مورد متغیرهای
71
00:02:28,560 –> 00:02:32,000
درگیر می خواهید، همیشه می توانید آنها را با
72
00:02:32,000 –> 00:02:34,480
تایپ کردن با استفاده از داده جستجو کنید و سپس فقط
73
00:02:34,480 –> 00:02:37,040
آرگومان نمایش را تایپ کنید. docs برابر با
74
00:02:37,040 –> 00:02:38,239
true است و شما می توانید در مورد متغیرهای درگیر بیشتر بیاموزید،
75
00:02:38,239 –> 00:02:39,599
76
00:02:39,599 –> 00:02:41,360
اما مجموعه داده های ما به صورت مشارکتی است، این
77
00:02:41,360 –> 00:02:42,879
دقیقاً در اینجا در خط یک است و ما
78
00:02:42,879 –> 00:02:45,280
این شی را به نام df ذخیره می کنیم
79
00:02:45,280 –> 00:02:47,599
و سپس برای متغیرهای مستقل
80
00:02:47,599 –> 00:02:49,840
خود البته به آن می رویم. فقط سه مورد
81
00:02:49,840 –> 00:02:51,360
داریم که میتوانیم آن را طولانیتر کنیم، اما نمیخواهیم
82
00:02:51,360 –> 00:02:52,400
83
00:02:52,400 –> 00:02:54,800
سطح تحصیلات و درآمد آنها را بالا ببریم و
84
00:02:54,800 –> 00:02:57,599
در آخر، متغیر وابسته
85
00:02:57,599 –> 00:02:58,560
البته
86
00:02:58,560 –> 00:03:00,640
رأی است و فقط برای سرگرمی، نگاهی سریع
87
00:03:00,640 –> 00:03:02,400
به مجموعه دادهها خواهیم داشت. بنابراین می توانید آن را
88
00:03:02,400 –> 00:03:05,200
در خط شماره چهار ببینید،
89
00:03:05,200 –> 00:03:07,040
بنابراین می توانید دقیقاً اینجا را ببینید
90
00:03:07,040 –> 00:03:09,280
که این مجموعه داده است،
91
00:03:09,280 –> 00:03:11,680
بنابراین می دانید که ما درآمد تحصیلی سنی داریم
92
00:03:11,680 –> 00:03:13,920
و اوه آیا آنها رای داده اند یا نه،
93
00:03:13,920 –> 00:03:15,280
ما نژاد را حذف کرده ایم، زیرا می توانید ببینید که نژاد کاملاً
94
00:03:15,280 –> 00:03:16,560
طبقه بندی شده است
95
00:03:16,560 –> 00:03:18,800
، منظورم این است که ممکن است استفاده از متغیرهای طبقه بندی شده
96
00:03:18,800 –> 00:03:20,640
uh اما
97
00:03:20,640 –> 00:03:21,840
ما واقعاً نمی خواهیم این کار را انجام دهیم که
98
00:03:21,840 –> 00:03:23,519
این بهترین راه برای نزدیک شدن به آن نیست
99
00:03:23,519 –> 00:03:25,680
و بنابراین ما سه متغیر دیگر را
100
00:03:25,680 –> 00:03:27,519
به عنوان وابسته خود در نظر می گیریم و
101
00:03:27,519 –> 00:03:28,799
از
102
00:03:28,799 –> 00:03:30,560
استقلال رأی خود و رأی خود به عنوان
103
00:03:30,560 –> 00:03:32,799
بهانه وابسته استفاده می کنیم. بنابراین، این همان کاری است که ما
104
00:03:32,799 –> 00:03:35,280
اینجا انجام میدهیم
105
00:03:36,080 –> 00:03:37,599
و بنابراین اکنون فقط میخواهیم
106
00:03:37,599 –> 00:03:39,120
مدل خود را توسعه دهیم، هیچ دادهای از دست رفته
107
00:03:39,120 –> 00:03:40,720
وجود ندارد، هیچ نسخهای تکراری وجود ندارد، بنابراین میتوانیم
108
00:03:40,720 –> 00:03:42,319
اینجا به جلو
109
00:03:42,319 –> 00:03:44,000
برویم و بنابراین میخواهیم مدل خود را توسعه دهیم،
110
00:03:44,000 –> 00:03:47,280
ما واقعاً به آن ن



![فیلم آموزشی: نحوه نصب کتابخانه SciPy Python و اجرای اولین برنامه [2021]](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/7BRoM0Geeq0image2.jpg)

![فیلم آموزشی: رسیدگی به خطا | پایتون برای مبتدیان [17 از 44] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/HQqqNBZosn8image2.jpg)