در این مطلب، ویدئو چگونه XLOOKUP مایکروسافت اکسل را به پایتون برای Pandas DataFrame تبدیل کنیم با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:06:02
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,719 –> 00:00:02,080
در این ویدیو من قصد دارم در
2
00:00:02,080 –> 00:00:05,200
مورد نحوه تبدیل x lookup
3
00:00:05,200 –> 00:00:07,680
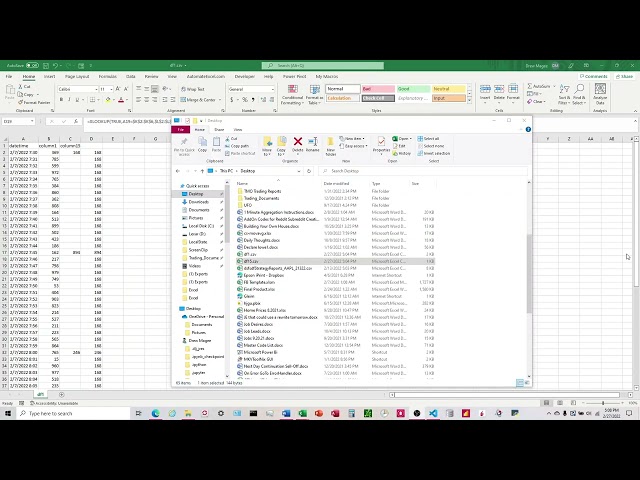
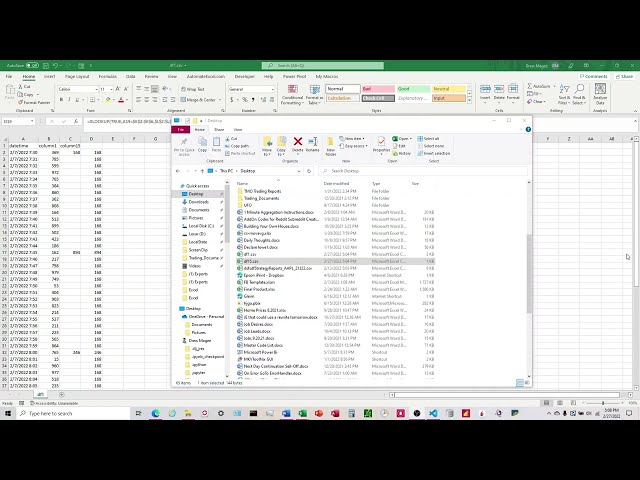
به پایتون صحبت کنم، زمانی که ما دو جدول جداگانه داریم
4
00:00:07,680 –> 00:00:09,360
5
00:00:09,360 –> 00:00:12,960
و بنابراین جداول من اینجا
6
00:00:12,960 –> 00:00:15,120
دارم، یک جدول در اینجا با زمان تاریخ
7
00:00:15,120 –> 00:00:17,039
و سپس یک عدد
8
00:00:17,039 –> 00:00:18,880
و سپس جدول دیگری در اینجا دارم. در
9
00:00:18,880 –> 00:00:20,720
فواصل 15 دقیقه و
10
00:00:20,720 –> 00:00:23,680
یک عدد دیگر در اینجا افزایش می یابد و بنابراین می خواهم به
11
00:00:23,680 –> 00:00:25,760
این زمان نگاه
12
00:00:25,760 –> 00:00:27,760
کند به اینجا به این جدول
13
00:00:27,760 –> 00:00:29,519
بیایید ببینم آیا در این جدول است یا خیر و
14
00:00:29,519 –> 00:00:32,000
اگر نیست آن عدد را برگردانید اگر نه هیچ کاری انجام
15
00:00:32,000 –> 00:00:32,960
نمی
16
00:00:32,960 –> 00:00:36,480
دهد. زمانی که
17
00:00:36,480 –> 00:00:37,840
18
00:00:37,840 –> 00:00:39,840
این عدد برابر با
19
00:00:39,840 –> 00:00:42,840
عددی از این ردیف در اینجاست،
20
00:00:42,840 –> 00:00:45,840
ستون 15 را برگردانید.
21
00:00:45,840 –> 00:00:48,320
سپس میخواهم جای اوه را خالی بگذارم و
22
00:00:48,320 –> 00:00:49,600
23
00:00:49,600 –> 00:00:50,960
فعلاً فقط n8 داشته باشیم،
24
00:00:50,960 –> 00:00:52,079
25
00:00:52,079 –> 00:00:53,600
بنابراین قسمت آخر کدامها را
26
00:00:53,600 –> 00:00:55,199
میخواهم قفل کنم، بنابراین میخواهم قفل کنم، میخواهم
27
00:00:55,199 –> 00:00:57,199
این جدول را دست نخورده نگه دارم، زیرا این میز
28
00:00:57,199 –> 00:00:58,559
پایین میآید، بنابراین من این دو
29
00:00:58,559 –> 00:01:00,800
را همینجا
30
00:01:00,800 –> 00:01:02,879
قفل میکنم و قفل a2 را میگذارم
31
00:01:02,879 –> 00:01:04,720
زیرا ما میخواهیم که برای پایین رفتن هر
32
00:01:04,720 –> 00:01:05,680
33
00:01:05,680 –> 00:01:07,280
ضربه مساوی
34
00:01:07,280 –> 00:01:08,479
، آن را پایین
35
00:01:08,479 –> 00:01:10,960
بیاوریم، می توانیم ببینیم که اینجا در حال ادغام
36
00:01:10,960 –> 00:01:13,040
است 651
37
00:01:13,040 –> 00:01:14,400
93 3
38
00:01:14,400 –> 00:01:17,200
و 354.
39
00:01:17,200 –> 00:01:18,880
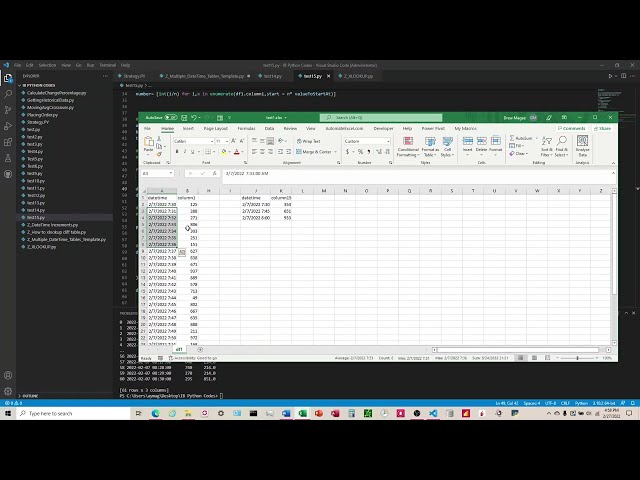
بنابراین برای انجام این کار در داخل پایتون، ما
40
00:01:18,880 –> 00:01:22,880
از یک pd.merge خیلی ساده استفاده می
41
00:01:22,880 –> 00:01:24,799
کنیم، بنابراین باید کتابخانه پانداها را
42
00:01:24,799 –> 00:01:26,640
در اینجا وارد کنیم و من همه اینها را
43
00:01:26,640 –> 00:01:28,560
در اینجا با
44
00:01:28,560 –> 00:01:30,799
جداولی که چاپ کرده ایم تنظیم کرده ام.
45
00:01:30,799 –> 00:01:32,560
pd.merge و سپس ما
46
00:01:32,560 –> 00:01:34,240
سه پارامتر خواهیم داشت که
47
00:01:34,240 –> 00:01:36,000
سمت چپ
48
00:01:36,000 –> 00:01:38,560
این جدول است،
49
00:01:38,560 –> 00:01:42,399
بنابراین در کد من df1 نامیده می شود،
50
00:01:42,399 –> 00:01:44,240
بنابراین من
51
00:01:44,240 –> 00:01:46,079
به آن گفتم df1 سمت راست
52
00:01:46,079 –> 00:01:48,560
نام این جدول است. در اینجا df-15 است
53
00:01:48,560 –> 00:01:51,520
و سپس نحوه تعیین
54
00:01:51,520 –> 00:01:56,000
ردیفهایی که میخواهیم در این جدید داشته باشیم
55
00:01:56,000 –> 00:01:58,719
، میگویم جدید از نظر فنی جدید نیست، اما
56
00:01:58,719 –> 00:02:01,759
در حال بازآفرینی قاب دادهای است
57
00:02:01,759 –> 00:02:03,520
که چه ردیفهایی را در این
58
00:02:03,520 –> 00:02:05,119
قاب دادهای بازسازیشده
59
00:02:05,119 –> 00:02:08,119
60
00:02:09,038 –> 00:02:11,520
میخواهیم. میخواهیم x جستجو در
61
00:02:11,520 –> 00:02:13,120
اولین جدول قاب داده باشد،
62
00:02:13,120 –> 00:02:15,280
در اینجا میخواهیم
63
00:02:15,280 –> 00:02:17,280
مشخص کنیم که میخواهیم آن را
64
00:02:17,280 –> 00:02:19,680
در سمت چپ ادغام
65
00:02:19,680 –> 00:02:22,239
کنیم که اولین جدول قاب داده خواهد بود و تمام،
66
00:02:22,239 –> 00:02:24,560
بنابراین میزان کد به همین اندازه
67
00:02:24,560 –> 00:02:26,000
است. در اینجا و بنابراین، من میروم
68
00:02:26,000 –> 00:02:28,319
و این چاپ را در یک csv اجرا
69
00:02:28,319 –> 00:02:29,680
میکنم و سپس نگاه میکنیم و ببینید نتیجه چه چیزی
70
00:02:29,680 –> 00:02:31,840
71
00:02:32,400 –> 00:02:34,560
خوب است، میتوانیم ببینیم که
72
00:02:34,560 –> 00:02:36,239
دقیقاً همانطور که میخواستیم کار کرد، این اعداد متفاوت هستند،
73
00:02:36,239 –> 00:02:38,560
زیرا من آنها را
74
00:02:38,560 –> 00:02:40,560
میخواهم که بهطور تصادفی اعداد مختلفی ایجاد کنم،
75
00:02:40,560 –> 00:02:43,280
اما میتوانیم 168 مطابقت
76
00:02:43,280 –> 00:02:47,599
را در 730 و 894 در 745 و
77
00:02:47,599 –> 00:02:49,360
غیره ببینیم. حالا کاری که میخواهیم انجام دهیم این است که
78
00:02:49,360 –> 00:02:51,760