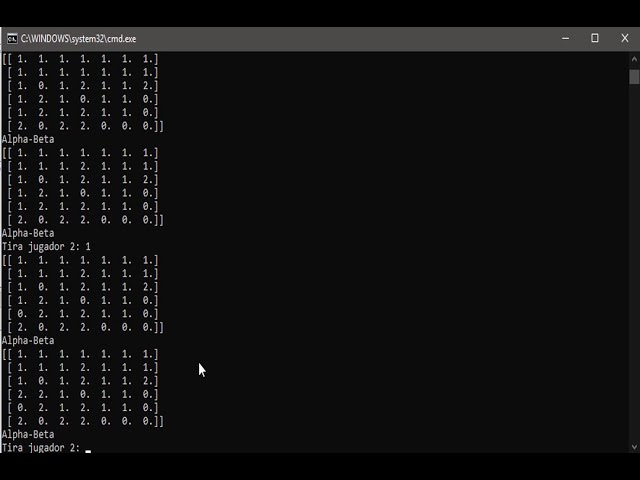
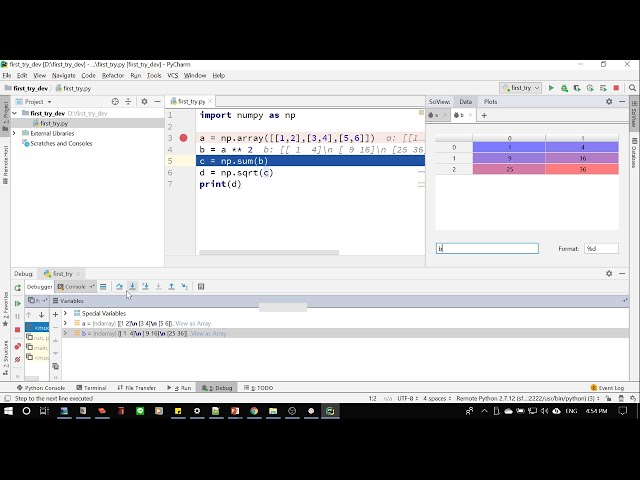
در این مطلب، ویدئو مقدمه ای بر شبکه های عصبی در پایتون (آنچه باید بدانید) | تنسورفلو/کراس با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 1:00:36
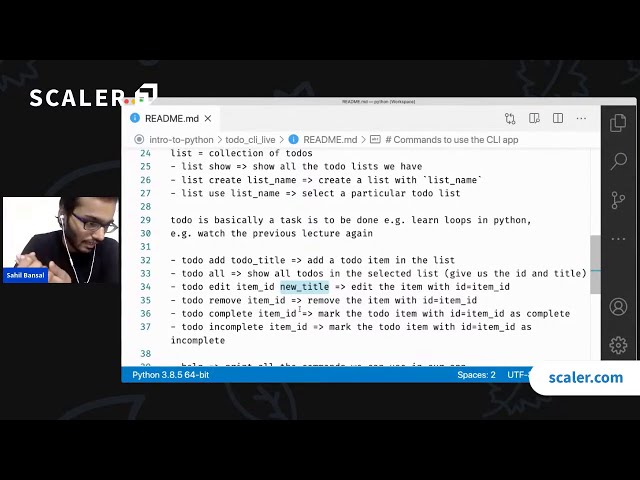
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,000 –> 00:00:02,250
سلام، همه چیز چطور پیش می رود و
2
00:00:02,250 –> 00:00:04,140
به ویدیوی دیگری در این ویدیو خوش آمدید،
3
00:00:04,140 –> 00:00:05,970
ما همه چیز را در مورد
4
00:00:05,970 –> 00:00:07,919
شبکه های عصبی در پایتون صحبت می کنیم، بنابراین
5
00:00:07,919 –> 00:00:09,660
با مروری بر مفاهیم مهم
6
00:00:09,660 –> 00:00:11,400
و شبکه های عصبی شروع می
7
00:00:11,400 –> 00:00:12,420
کنیم، من واقعا فکر می کنم درک آن مهم است.
8
00:00:12,420 –> 00:00:13,920
چگونه آنها در سطح بالایی کار می کنند،
9
00:00:13,920 –> 00:00:15,900
بنابراین ما اصول اولیه نحوه
10
00:00:15,900 –> 00:00:17,789
کار آنها را بررسی خواهیم کرد و همچنین
11
00:00:17,789 –> 00:00:20,189
اطلاعاتی در مورد
12
00:00:20,189 –> 00:00:22,380
پارامترهای فوق العاده معماری شبکه و توابع فعال سازی
13
00:00:22,380 –> 00:00:23,850
را مرور
14
00:00:23,850 –> 00:00:25,650
خواهیم کرد. کد و
15
00:00:25,650 –> 00:00:27,090
بنابراین اولین بخش کد نویسی ما
16
00:00:27,090 –> 00:00:29,460
اصول اولیه نوشتن
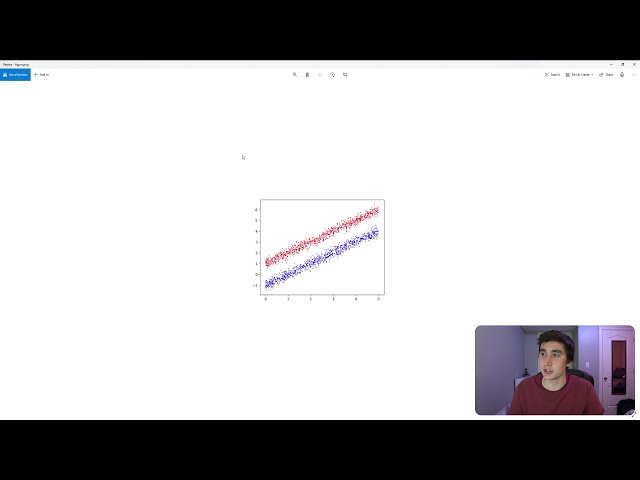
17
00:00:29,460 –> 00:00:31,439
شبکه های عصبی با کتابخانه Charis را بررسی می
18
00:00:31,439 –> 00:00:32,910
کنیم و به نوعی
19
00:00:32,910 –> 00:00:35,130
نمونه هایی از ساخت مدل های واقعی
20
00:00:35,130 –> 00:00:37,140
با آن را مرور خواهیم کرد و سپس بخش دوم
21
00:00:37,140 –> 00:00:39,660
واقعی خواهد بود. – مشکل جهانی و بنابراین در
22
00:00:39,660 –> 00:00:41,010
آن بخش، ما در حال
23
00:00:41,010 –> 00:00:42,690
ساخت یک شبکه عصبی هستیم تا به
24
00:00:42,690 –> 00:00:45,570
طور خودکار تصاویر را
25
00:00:45,570 –> 00:00:48,780
قبل از شروع به کار به عنوان کاغذ سنگی یا قیچی طبقه بندی کنیم،
26
00:00:48,780 –> 00:00:50,010
اگرچه من می خواهم یک فریاد سریع
27
00:00:50,010 –> 00:00:53,530
به این موضوع بدهم. حامی ویدیوها و این است که kite
28
00:00:53,530 –> 00:00:56,079
kite یک ابزار تکمیل کد برای
29
00:00:56,079 –> 00:00:58,329
پایتون است که از یادگیری ماشین برای
30
00:00:58,329 –> 00:01:00,100
یافتن بهترین پیشنهادات
31
00:01:00,100 –> 00:01:01,690
32
00:01:01,690 –> 00:01:04,690
33
00:01:04,690 –> 00:01:07,330
34
00:01:07,330 –> 00:01:09,040
35
00:01:09,040 –> 00:01:11,890
استفاده میکند. کد کایت
36
00:01:11,890 –> 00:01:13,869
با محبوب ترین ویرایشگرهای پایتون
37
00:01:13,869 –> 00:01:19,060
مانند atom vs code sublime vim pycharm و spider ادغام می شود
38
00:01:19,060 –> 00:01:22,060
و بهترین بخش در مورد کایت
39
00:01:22,060 –> 00:01:23,830
این است که دانلود آن کاملا رایگان است
40
00:01:23,830 –> 00:01:26,140
برای شروع، من یک لینک در
41
00:01:26,140 –> 00:01:27,880
توضیحاتی که از کیت استفاده کرده ام گذاشته ام. برای
42
00:01:27,880 –> 00:01:30,130
حدود سه یا چهار ماه در این مرحله
43
00:01:30,130 –> 00:01:32,440
و استفاده از آن بسیار سرگرم کننده بوده است، بنابراین من
44
00:01:32,440 –> 00:01:34,000
قطعاً توصیه می
45
00:01:34,000 –> 00:01:36,100
کنم برای شروع به آن نگاهی بیاندازید.
46
00:01:36,100 –> 00:01:37,780
47
00:01:37,780 –> 00:01:40,300
48
00:01:40,300 –> 00:01:41,890
می توان به خوبی
49
00:01:41,890 –> 00:01:45,369
از طریق چند مثال تصویری توضیح داد، بنابراین
50
00:01:45,369 –> 00:01:46,659
تصور کنید که نموداری
51
00:01:46,659 –> 00:01:48,970
شبیه این دارید و می دانید که این
52
00:01:48,970 –> 00:01:50,860
نقاط قرمز و این نقاط آبی را دارید و ما
53
00:01:50,860 –> 00:01:52,080
تلاش برای ساخت یک طبقهبندی کننده برای
54
00:01:52,080 –> 00:01:55,270
طبقهبندی خودکار نقاط قرمز و نقاط آبی
55
00:01:55,270 –> 00:01:57,490
به درستی، بنابراین این مثال اول
56
00:01:57,490 –> 00:01:59,290
بسیار ساده است، ما میتوانیم به سادگی
57
00:01:59,290 –> 00:02:02,159
بین آنها یک خط بکشیم و طبقهبندی کاملی داشته باشیم،
58
00:02:02,159 –> 00:02:04,899
بنابراین یک
59
00:02:04,899 –> 00:02:06,820
مثال کمی پیچیدهتر تصور کنید که اکنون
60
00:02:06,820 –> 00:02:11,500
این دو مجموعه از نقاط منحنی را داریم. در این
61
00:02:11,500 –> 00:02:13,030
مورد مطمئناً به
62
00:02:13,030 –> 00:02:16,390
اندازه خط بی اهمیت نیست، اما اگر از یک
63
00:02:16,390 –> 00:02:19,090
معادله درجه دوم در اینجا استفاده کنیم، میتوانیم
64
00:02:19,090 –> 00:02:21,790
دوباره به راحتی
65
00:02:21,790 –> 00:02:24,519
نقاط قرمز و آبی را کاملاً طبقهبندی کنیم، اما این
66
00:02:24,519 –> 00:02:27,010
ما را به مورد استفاده واقعی واقعی
67
00:02:27,010 –> 00:02:30,700
از شبکههای عصبی و در واقعیت،
68
00:02:30,700 –> 00:02:33,430
اغلب اوقات دادههای ما به خوبی از
69
00:02:33,430 –> 00:02:36,010
هم جدا نمیشوند، زیرا اغلب اوقات دادههای ما
70
00:02:36,010 –> 00:02:38,109
کمی بیشتر شبیه چیزی
71
00:02:38,109 –> 00:02:40,570
شبیه به این به نظر میرسند، جایی که میدانید
72
00:02:40,570 –> 00:02:43,750
نقاط قرمز رنگی در سرتاسر مکان وجود دارد که
73
00:02:43,750 –> 00:02:46,329
ظاهراً تصادفی هستند و نقاط آبی بین آنها پراکنده شده است.
74
00:02:46,329 –> 00:02:48,820
75
00:02:48,820 –> 00:02:50,769
ما میتوانیم چند خط بکشیم و
76
00:02:50,769 –> 00:02:53,140
قرمز را از آبی جدا کنیم، اما
77
00:02:53,140 –> 00:02:55,359
آموزش و طبقهبندیکننده به طور خودکار
78
00:02:55,359 –> 00:02:58,049
انجام میشود که اینطور نیست.
79
00:02:58,049 –> 00:03:01,329
شبكههاي عصبي ميتوانند اين كار را انجام دهند، شبكههاي عصبي
80
00:03:01,329 –> 00:03:03,459
ميتوانند الگوها را بيابند و
81
00:03:03,459 –> 00:03:06,129
گروههايي را در درون دادهها بيابند و به نوعي از آنها خارج ميشوند
82
00:03:06,129 –> 00:03:07,130
83
00:03:07,130 –> 00:03:09,830
و به همين دليل است كه آنها بسيار قدرتمند هستند، پس
84
00:03:09,830 –> 00:03:11,810
اجازه دهيد به نوعي شبيهي شبكه عصبي بپردازيم.
85
00:03:11,810 –> 00:03:13,220
86
00:03:13,220 –> 00:03:13,940
اصول اولیه
87
00:03:13,940 –> 00:03:16,910
بنابراین با استفاده از آخرین مثال که
88
00:03:16,910 –> 00:03:19,100
نمودار آخر یک مثال است تصور کنید ما
89
00:03:19,100 –> 00:03:20,990
سعی می کنیم نقاط آبی و قرمز را
90
00:03:20,990 –> 00:03:22,670
به خوبی طبقه بندی کنید همه شبکه های عصبی
91
00:03:22,670 –> 00:03:25,130
قرار است با یک لایه ورودی شروع شوند و در
92
00:03:25,130 –> 00:03:27,770
این حالت لایه ورودی دو خواهد بود.
93
00:03:27,770 –> 00:03:30,200
بعد فقط مختصات x
94
00:03:30,200 –> 00:03:32,270
و مختصات y
95
00:03:32,270 –> 00:03:34,670
نقطهای است که ما سعی میکنیم آنها را به عنوان قرمز یا آبی طبقهبندی کنیم، در مرحله
96
00:03:34,670 –> 00:03:36,770
بعد همه
97
00:03:36,770 –> 00:03:38,270
شبکههای عصبی ما چند لایه پنهان خواهند داشت
98
00:03:38,270 –> 00:03:41,420
، بنابراین در این مثال ما
99
00:03:41,420 –> 00:03:44,240
هر کدام دو لایه پنهان داریم. برای چهار نورون،
100
00:03:44,240 –> 00:03:47,210
همه این نورونها در اینجا
101
00:03:47,210 –> 00:03:49,490
با لایه ورودی در ارتباط هستند، مقادیر
102
00:03:49,490 –> 00:03:51,590
لایه ورودی از طریق
103
00:03:51,590 –> 00:03:54,440
وزنههای این اتصالات منتقل میشوند و سپس
104
00:03:54,440 –> 00:03:56,270
رنگ قرمز را در این سمت میشناسید و سپس
105
00:03:56,270 –> 00:03:58,550
بیشتر به سمت th میروید. لایه بعدی و
106
00:03:58,550 –> 00:04:01,220
در نهایت منجر به انتقال آنها
107
00:04:01,220 –> 00:04:04,550
به یک لایه خروجی می شود و در این مورد
108
00:04:04,550 –> 00:04:06,080
لایه خروجی ما تعیین می کند
109
00:04:06,080 –> 00:04:09,410
که آیا نقطه ای قرمز است یا آبی
110
00:04:09,410 –> 00:04:11,230
با درجه خاصی از اطمینان
111
00:04:11,230 –> 00:04:13,700
واقعاً کاری که یک شبکه عصبی انجام می دهد این است
112
00:04:13,700 –> 00:04:16,850
که اینها را به روز می کند. اوزان بین
113
00:04:16,850 –> 00:04:20,238
اتصالات امیدواریم بتوان به
114
00:04:20,238 –> 00:04:23,450
درستی نموداری مانند این را طبقه بندی کرد، بنابراین
115
00:04:23,450 –> 00:04:25,490
آنچه که قرار است شروع شود این است که می دانید
116
00:04:25,490 –> 00:04:27,050
شبکه عصبی هیچ ایده ای
117
00:04:27,050 –> 00:04:28,820
در مورد نحوه طبقه بندی آن نخواهد داشت، ممکن است به
118
00:04:28,820 –> 00:04:31,220
نوعی فقط یک خط بکشد و همه چیز را
119
00:04:31,220 –> 00:04:32,960
به آن بگوید. سمت چپ خط آبی است و
120
00:04:32,960 –> 00:04:34,610
همه چیز در سمت راست قرمز است و
121
00:04:34,610 –> 00:04:36,680
این خیلی دقیق نیست، اما
122
00:04:36,680 –> 00:04:38,600
یک نقطه شروع به ما می دهد و بنابراین
123
00:04:38,600 –> 00:04:40,160
دره از طریق این شبکه عبور می کند
124
00:04:40,160 –> 00:04:41,420
و آنها درجه خاصی
125
00:04:41,420 –> 00:04:43,430
از اطمینان خواهند داشت، پس بیایید بگوییم که
126
00:04:43,430 –> 00:04:45,830
ما در اینجا به یک مثال قرمز نگاه میکردیم، شبکه عصبی ما
127
00:04:45,830 –> 00:04:46,850
نباید پیشبینیهایی به ما بدهد،
128
00:04:46,850 –> 00:04:48,500
مثلاً با پنجاه و پنج درصد
129
00:04:48,500 –> 00:04:50,570
احتمال قرمز بودن، چهل و پنج درصد
130
00:04:50,570 –> 00:04:53,000
احتمال آبی و آنچه ما در تلاش هستیم.
131
00:04:53,000 –> 00:04:55,190
دریافت این است که آن مقدار درصدی که
132
00:04:55,190 –> 00:04:57,890
مقدار اطمینان در اینجا به مقدار واقعی نزدیک است،
133
00:04:57,890 –> 00:04:59,360
بنابراین در این مورد،
134
00:04:59,360 –> 00:05:01,100
اگر به یک مثال قرمز نگاه
135
00:05:01,100 –> 00:05:03,860
کنیم، بر اساس این محاسبه، این یک خواهد بود و این یک صفر
136
00:05:03,860 –> 00:05:05,210
خواهد بود. برای
137
00:05:05,210 –> 00:05:08,150
اینکه ببینیم خوب، همانطور که قرار بود 1 و صفر نبودیم
138
00:05:08,150 –> 00:05:09,560
، مقداری
139
00:05:09,560 –> 00:05:11,150
ضرر داشتیم و به آنها میگوییم
140
00:05:11,150 –> 00:05:14,480
وزنها را مطابق با آن بهروزرسانی کنند و این
141
00:05:14,480 –> 00:05:16,210
ما را به نوعی جدایی جدید
142
00:05:16,210 –> 00:05:17,850
در ما
143
00:05:17,850 –> 00:05:21,090
و یک بار سوق میدهد. مجدداً شما ارزش های ما را می دانید
144
00:05:21,090 –> 00:05:22,710
همانطور که نمونه های بیشتری دریافت
145
00:05:22,710 –> 00:05:23,910
می کنیم، به روز می شوند، ما شروع
146
00:05:23,910 –> 00:05:25,560
به اطمینان بیشتر در مورد آنچه در آینده داریم
147
00:05:25,560 –> 00:05:27,450
می کنیم، به روز رسانی این نمودار
148
00:05:27,450 –> 00:05:28,980
ادامه می دهم و مقدار به نوعی
149
00:05:28,980 –> 00:05:32,520
بیشتر می شود و مطمئنتر
150
00:05:32,520 –> 00:05:34,440
اگر واقعاً جدایی در
151
00:05:34,440 –> 00:05:36,840
دادهها وجود داشته باشد، آنها به نوعی به
152
00:05:36,840 –> 00:05:39,060
مقادیر بهتر و بهتر همگرا میشوند و در نهایت امیدواریم
153
00:05:39,060 –> 00:05:41,070
که اگر آن را به اندازه کافی آموزش دهیم،
154
00:05:41,070 –> 00:05:44,100
چیزی شبیه به این به دست آوریم که در آن
155
00:05:44,100 –> 00:05:46,770
دادهها به نظر کاملاً مناسب هستند. توسط
156
00:05:46,770 –> 00:05:48,990
شبکه ما و ارزش هایی که ج
157
00:05:48,990 –> 00:05:51,360
158
00:05:51,360 –> 00:05:53,700
اگر میخواهید
159
00:05:53,700 –> 00:05:55,500
یک توضیح بصری خوب در مورد نحوه عملکرد
160
00:05:55,500 –> 00:05:57,600
این شبکههای عصبی داشته باشید، با اطمینان کامل به صورت قرمز یا
161
00:05:57,600 –> 00:05:59,250
162
00:05:59,250 –> 00:06:01,590
آبی پیشبینی میشود.
163
00:06:01,590 –> 00:06:05,310
164
00:06:05,310 –> 00:06:06,690
قطعاً میتواند به بررسی برخی از
165
00:06:06,690 –> 00:06:08,580
این مفاهیم سطح بالا کمک کند، قبل از اینکه
166
00:06:08,580 –> 00:06:12,180
وارد شبکههای کدگذاری واقعی شویم،
167
00:06:12,180 –> 00:06:14,520
در ادامه در مورد پارامترهای فوقالعاده این
168
00:06:14,520 –> 00:06:15,930
شبکه
169
00:06:15,930 –> 00:06:18,780
170
00:06:18,780 –> 00:06:20,940
171
00:06:20,940 –> 00:06:23,040
صحبت کنیم. تعداد
172
00:06:23,040 –> 00:06:24,750
لایههای پنهان و تعداد نورونها
173
00:06:24,750 –> 00:06:26,610
در هر لایه، برخی از لایههای دیگر
174
00:06:26,610 –> 00:06:28,560
به اندازه دستهای خواهند بود، بنابراین
175
00:06:28,560 –> 00:06:30,450
در هر مرحله بهروزرسانی چند نقطه داده را از شبکه عبور میدهیم تا از
176
00:06:30,450 –> 00:06:33,210
177
00:06:33,210 –> 00:06:35,010
آن عبور نکنیم. معمولاً یک نقطه واحد را
178
00:06:35,010 –> 00:06:36,450
در
179
00:06:36,450 –> 00:06:39,330
شانزده نقطه یا 32 یا 64 به شبکه خود منتقل می کنیم،
180
00:06:39,330 –> 00:06:40,440
181
00:06:40,440 –> 00:06:42,350
بنابراین اگر اندازه دسته ای آن
182
00:06:42,350 –> 00:06:44,640
بهینه ساز را تعیین می کند، پس ما چگونه یادگیری شبکه ای
183
00:06:44,640 –> 00:06:46,980
و الگوریتمی برای به روز رسانی
184
00:06:46,980 –> 00:06:48,360
مجدد نقشه عصبی است. نکته ای که می خواستم به آن
185
00:06:48,360 –> 00:06:50,400
توجه کنم این است که شما معمولاً می توانید از اتم به عنوان
186
00:06:50,400 –> 00:06:52,500
یک شرط مطمئن برای بهینه ساز خود استفاده کنید
187
00:06:52,500 –> 00:06:54,720
و همچنین ما را به نرخ یادگیری هدایت می کند،
188
00:06:54,720 –> 00:06:58,290
بنابراین این وزن ها هر کدام چقدر به روز می شوند.
189
00:06:58,290 –> 00:07:02,280
زمانی که ما یک دسته ورودی را می بینیم و بنابراین اگر
190
00:07:02,280 –> 00:07:04,050
آن را بالاتر تنظیم کنید،
191
00:07:04,050 –> 00:07:06,360
اگر
192
00:07:06,360 –> 00:07:08,130
سرعت یادگیری کمتری داشته باشد، با بزرگی بیشتری به روز می شود، به روز رسانی ها
193
00:07:08,130 –> 00:07:10,080
کوچکتر می شوند، بنابراین ما می توانیم
194
00:07:10,080 –> 00:07:12,090
با آن به عنوان یک پارامتر هایپر، یکی دیگر از
195
00:07:12,090 –> 00:07:14,370
پارامترهای هایپر که مهم است بازی کنیم. توجه داشته باشید
196
00:07:14,370 –> 00:07:16,380
که حذف شده است، بنابراین یکی از چیزهایی که مییابیم
197
00:07:16,380 –> 00:07:18,570
به تعمیم بهتر شبکههای ما کمک میکند این است که
198
00:07:18,570 –> 00:07:20,850
اگر به طور تصادفی
199
00:07:20,850 –> 00:07:22,310
گرهها را با احتمال خاصی قطع کنیم،
200
00:07:22,310 –> 00:07:25,020
اساساً کاری که انجام میدهد این است
201
00:07:25,020 –> 00:07:27,300
که اگر به طور تصادفی گرهها را حذف کنیم،
202
00:07:27,300 –> 00:07:29,580
بقیه شبکه باید این کار را انجام دهند.
203
00:07:29,580 –> 00:07:29,910
بیشتر
204
00:07:29,910 –> 00:07:31,680
یا تأثیر بیشتر من نمی توانم به یک گره تکیه کنم
205
00:07:31,680 –> 00:07:34,080
تا همه چیز را یاد بگیرم و
206
00:07:34,080 –> 00:07:35,880
این کمک می کند زیرا ما قرار
207
00:07:35,880 –> 00:07:37,710
نیست همه داده هایی را که در طبیعت وجود دارد ببینیم و
208
00:07:37,710 –> 00:07:39,840
به نوعی به ما کمک می کند برخی
209
00:07:39,840 –> 00:07:41,640
از شرایطی را که ما در واقع می
210
00:07:41,640 –> 00:07:43,260
توانیم به تنهایی ببینیم
211
00:07:43,260 –> 00:07:45,480
یکی دیگر از پارامترهای مهم دیگری
212
00:07:45,480 –> 00:07:47,430
که باید بدانیم آبله است و این است که چند بار
213
00:07:47,430 –> 00:07:49,650
داده های خود را در حالی که آنها را آموزش می دهیم مرور می کنیم
214
00:07:49,650 –> 00:07:51,750
، بنابراین این پارامتر دیگری است
215
00:07:51,750 –> 00:07:54,120
که نمی توانید آن را تنظیم کنید. سوالی
216
00:07:54,120 –> 00:07:56,070
که زیاد پرسیده میشود این است که میدانید چگونه
217
00:07:56,070 –> 00:07:57,840
این لایهها را انتخاب کنیم، نورونها و
218
00:07:57,840 –> 00:08:01,530
پارامترهای فوق را به خوبی انتخاب کنیم، بزرگترین چیزی که
219
00:08:01,530 –> 00:08:02,760
میتوانم بگویم این است که
220
00:08:02,760 –> 00:08:05,910
221
00:08:05,910 –> 00:08:08,040
اگر دقت بالایی در دادههای آموزشی دریافت میکنید، از عملکرد آموزشی خود برای هدایت تصمیمهای خود
222
00:08:08,040 –> 00:08:10,650
استفاده کنید. مجموعه اعتبار سنجی
223
00:08:10,650 –> 00:08:13,230
پس شما به نوعی بیش از حد
224
00:08:13,230 –> 00:08:15,060
برازش خود را با داده های آموزشی خود تطبیق می دهید
225
00:08:15,060 –> 00:08:16,770
و اگر
226
00:08:16,770 –> 00:08:20,010
227
00:08:20,010 –> 00:08:21,330
دقت پایینی در تمرین دریافت می کنید مانند
228
00:08:21,330 –> 00:08:22,890
دقت نسبتاً پایین و فکر می
229
00:08:22,890 –> 00:08:24,420
کنید می توانید آن را افزایش دهید احتمالاً باید تعداد پارامترها را کاهش دهید. ممکن است
230
00:08:24,420 –> 00:08:26,070
داده ها کم باشد و شاید شما
231
00:08:26,070 –> 00:08:27,390
باید تعداد پارامترها را افزایش دهید
232
00:08:27,390 –> 00:08:29,640
و چیزی که من به آن اشاره خواهم کرد این است که
233
00:08:29,640 –> 00:08:31,440
هیچ علم دقیقی در این مورد وجود ندارد، این
234
00:08:31,440 –> 00:08:33,510
یک نوع توئیک زیاد خواهد بود. اعداد ng و
235
00:08:33,510 –> 00:08:35,700
تغییر دادن مقادیر و این فقط
236
00:08:35,700 –> 00:08:38,099
ماهیت ساخت شبکه های عصبی است و
237
00:08:38,099 –> 00:08:39,870
نگران نباشید که
238
00:08:39,870 –> 00:08:41,340
در مورد هر کاری
239
00:08:41,340 –> 00:08:43,440
که انجام می دهید مطمئن
240
00:08:43,440 –> 00:08:46,290
نیستید.
241
00:08:46,290 –> 00:08:49,950
ما میتوانیم پارامترهای فوق را انتخاب کنیم، استفاده از
242
00:08:49,950 –> 00:08:53,070
برخی از روشهای جستجوی خودکار برای
243
00:08:53,070 –> 00:08:55,470
کمک به آزمایش ما به ما کمک میکند مقدار زیادی از
244
00:08:55,470 –> 00:08:56,910
مقادیر مختلف را همزمان آزمایش کنیم
245
00:08:56,910 –> 00:08:59,970
و در نهایت بهترین ترکیبی از
246
00:08:59,970 –> 00:09:02,160
چیزها را انتخاب کنیم و بنابراین با یادگیری مانند SK
247
00:09:02,160 –> 00:09:04,740
میتوانید از CV جستجوی شبکه برای کمک به ما استفاده کنید. این کار را انجام
248
00:09:04,740 –> 00:09:06,510
دهید و من فکر می کنم در
249
00:09:06,510 –> 00:09:07,830
بخش کدگذاری واقعی
250
00:09:07,830 –> 00:09:09,570
آموزش به آن چیزی خواهیم رسید که من هنوز به آن اشاره
251
00:09:09,570 –> 00:09:11,430
نکرده ام اما برای نحوه
252
00:09:11,430 –> 00:09:14,160
عملکرد شبکه های عصبی ما بسیار مهم است توابع فعال سازی
253
00:09:14,160 –> 00:09:17,300
توابع فعال سازی
254
00:09:17,300 –> 00:09:19,550
غیرخطی بودن را در محاسبات شبکه ما معرفی می کنند.
255
00:09:19,550 –> 00:09:22,620
و این ممکن است
256
00:09:22,620 –> 00:09:24,810
برای شما معنایی نداشته باشد، اما چیزی که
257
00:09:24,810 –> 00:09:27,300
واقعاً به آن می رسد مانند
258
00:09:27,300 –> 00:09:29,700
مثال ما در اینجا است که اگر می
259
00:09:29,700 –> 00:09:30,870
خواستیم شبکه ای پیرامون
260
00:09:30,870 –> 00:09:34,440
این داده بسازیم در نهایت انجام می دادیم. ما مقادیر گره خود را می گیریم،
261
00:09:34,440 –> 00:09:37,490
بنابراین نوع مقادیر ورودی خود،
262
00:09:37,490 –> 00:09:39,570
آنها را در مقداری وزن ضرب می کنیم و
263
00:09:39,570 –> 00:09:42,480
همه آن مقادیر را با هم جمع می کنیم
264
00:09:42,480 –> 00:09:44,250
تا به نوعی خروجی گره را به دست آوریم
265
00:09:44,250 –> 00:09:47,120
و کاری که یک تابع فعال سازی انجام
266
00:09:47,120 –> 00:09:50,880
می دهد این است که به آن اجازه می دهد تا به این مقدار گره برسد به جای اینکه فقط به آن مقدار گره برسد.
267
00:09:50,880 –> 00:09:53,940
با افزودن مقادیر ورودی
268
00:09:53,940 –> 00:09:57,060
ضربدر وزن، این غیر خطی بودن را
269
00:09:57,060 –> 00:10:00,240
اضافه میکند و اساساً به
270
00:10:00,240 –> 00:10:01,920
مقادیری که از آن گره خروجی میدهیم، پیچیدگی اضافه میکند
271
00:10:01,920 –> 00:10:06,120
تا به نوعی جمع شود که در
272
00:10:06,120 –> 00:10:08,130
تابع فعالسازی به ما اجازه میدهد
273
00:10:08,130 –> 00:10:10,920
شبکههای عصبی خود را با دادههای پیچیدهتر تطبیق دهیم
274
00:10:10,920 –> 00:10:12,900
و کارهای بسیار هیجان انگیزی انجام دهید،
275
00:10:12,900 –> 00:10:15,390
بنابراین به ما اجازه می دهد اساساً دو داده را
276
00:10:15,390 –> 00:10:17,790
که به نظر می رسد پیچیده
277
00:10:17,790 –> 00:10:21,830
تر هستند، راحت تر جاسازی کنیم و سوال دیگری که
278
00:10:21,830 –> 00:10:24,900
شنیده ام زیاد پرسیده می شود این است که
279
00:10:24,900 –> 00:10:28,230
به طور کلی از چه توابع فعال سازی باید به خوبی استفاده کنم.
280
00:10:28,230 –> 00:10:30,750
281
00:10:30,750 –> 00:10:33,800
با رابطه شما و لایههای مخفی خود بروید
282
00:10:33,800 –> 00:10:36,780
، در شبکههای عصبی مفهومی وجود دارد که
283
00:10:36,780 –> 00:10:38,880
به آن گرادیانهای ناپدید میگویند، اساساً
284
00:10:38,880 –> 00:10:41,040
زمانی که آن وزنها را بهروزرسانی میکنید و
285
00:10:41,040 –> 00:10:43,830
تا چه اندازه میتوانید وزنها را بهروزرسانی کنید.
286
00:10:43,830 –> 00:10:46,830
و از دادههای آموزشی خود بیاموزید،
287
00:10:46,830 –> 00:10:49,740
تابع فعالسازی به جلوگیری از این
288
00:10:49,740 –> 00:10:51,990
مشکل گرادیان ناپدید میشود، بنابراین به طور کلی
289
00:10:51,990 –> 00:10:53,820
میگویم برای لایههای مخفی واقعاً از
290
00:10:53,820 –> 00:10:55,650
یک شرط امن استفاده کنید و سپس
291
00:10:55,650 –> 00:10:58,950
اگر
292
00:10:58,950 –> 00:11:01,410
یک برچسب واحد را طبقهبندی میکنید، آنچه میگویم برای لایه خروجی شماست. شما
293
00:11:01,410 –> 00:11:04,080
مثل این کار میکنید که قرمز آبی
294
00:11:04,080 –> 00:11:05,730
زرد سبز را میشناسید و فقط باید
295
00:11:05,730 –> 00:11:08,160
هر نقطه را به عنوان یکی از آن
296
00:11:08,160 –> 00:11:12,120
حداکثرهای نرم طبقهبندی کنید، شرط خوبی است، اما اگر میخواهید
297
00:11:12,120 –> 00:11:15,990
ممکن است چیزها را طبقهبندی کنید، ممکن است چیزهایی
298
00:11:15,990 –> 00:11:17,760
مانند قدیس در آنجا قرمز و آبی باشند.
299
00:11:17,760 –> 00:11:21,000
برای طبقهبندی چند برچسبی میتواند هم قرمز و هم آبی
300
00:11:21,000 –> 00:11:22,890
301
00:11:22,890 –> 00:11:27,540
باشد، تابع فعالسازی سیگموئید شرط بسیار خوبی است و
302
00:11:27,540 –> 00:11:29,220
سپس آخرین چیزی که میخواهم وارد آن شوم، قبل از اینکه
303
00:11:29,220 –> 00:11:31,620
وارد کد شویم، مروری سریع از
304
00:11:31,620 –> 00:11:35,940
tensorflow / Kaos در مقابل مشعل PI و در
305
00:11:35,940 –> 00:11:37,020
این آموزش است. ما از
306
00:11:37,020 –> 00:11:39,780
Kerris استفاده میکنیم و برای
307
00:11:39,780 –> 00:11:41,700
شروع سریع و آزمایشهای واقعاً سریع
308
00:11:41,700 –> 00:11:43,290
با شبکههای عصبی که با
309
00:11:43,290 –> 00:11:45,510
310
00:11:45,510 –> 00:11:47,730
پیشرفت بیشتر و بیشتر که فاقد
311
00:11:47,730 –> 00:11:50,070
کنترل و سفارشیسازی کامل میشوید، عالی است. این که مشعل پی
312
00:11:50,070 –> 00:11:52,440
و نوع
313
00:11:52,440 –> 00:11:55,640
کاملتر تنسورفلو دارای تنسورفلو است،
314
00:11:55,640 –> 00:11:57,320
محبوبترین چارچوب
315
00:11:57,320 –> 00:11:59,810
برای صنعت است، اما میتوانم بگویم که
316
00:11:59,810 –> 00:12:02,000
میتواند بسیار پیچیده باشد و
317
00:12:02,000 –> 00:12:03,500
مستندات آن همیشه
318
00:12:03,500 –> 00:12:05,720
منسجم نیست، شخصاً من هستم. نه
319
00:12:05,720 –> 00:12:07,760
با تجربه ترین در مورد جریان مداد چیزی که
320
00:12:07,760 –> 00:12:10,100
من معمولاً در صورت انجام کارهای
321
00:12:10,100 –> 00:12:11,840
پیچیده تری از شبکه های عصبی استفاده می کنم و چیزی
322
00:12:11,840 –> 00:12:13,310
که برای پایان نامه کارشناسی ارشد خود استفاده می کنم در
323
00:12:13,310 –> 00:12:15,380
نهایت وقتی روی
324
00:12:15,380 –> 00:12:17,540
انواع مختلف شبکه ها کار می کردم مشعل PI است
325
00:12:17,540 –> 00:12:20,150
و این یک نوع است. برای مدتی
326
00:12:20,150 –> 00:12:21,680
مورد علاقه جامعه پژوهشی و
327
00:12:21,680 –> 00:12:23,420
دانشگاهی بوده است، دارای یک
328
00:12:23,420 –> 00:12:25,940
نحو بسیار pythonic است و شما می توانید به راحتی
329
00:12:25,940 –> 00:12:29,600
در هر نقطه از شبکه به مقادیر دسترسی داشته باشید
330
00:12:29,600 –> 00:12:31,130
تا بخش کدگذاری
331
00:12:31,130 –> 00:12:33,020
این آموزش را شروع کنید، من می گویم بهترین
332
00:12:33,020 –> 00:12:34,730
راه برای یادگیری این است که با انجام این کار، ما
333
00:12:34,730 –> 00:12:37,550
مستقیماً به چند نمونه از
334
00:12:37,550 –> 00:12:39,470
ساخت شبکه های عصبی می پردازیم و از طریق
335
00:12:39,470 –> 00:12:40,850
آن، باید
336
00:12:40,850 –> 00:12:43,160
اصول اولیه آنچه را که باید
337
00:12:43,160 –> 00:12:46,550
با جریان تانسور و چرخش بدانید، بسازید، بنابراین اگر
338
00:12:46,550 –> 00:12:48,530
به صفحه github من دریافت comm slash
339
00:12:48,530 –> 00:12:50,750
Keith galley slash neuro dash nets و
340
00:12:50,750 –> 00:12:52,030
این به آن در توضیحات مرتبط است که
341
00:12:52,030 –> 00:12:55,070
من چند نمونه را در آنجا گذاشته ام، بنابراین می
342
00:12:55,070 –> 00:12:56,810
خواهیم برای هر یک
343
00:12:56,810 –> 00:12:59,000
از این نمونه ها در این پوشه یک شبکه عصبی بسازیم و
344
00:12:59,000 –> 00:13:01,760
وظیفه چیست. is درست مانند چیزی است
345
00:13:01,760 –> 00:13:03,800
که در ابتدای ویدیو معرفی کردم، بنابراین
346
00:13:03,800 –> 00:13:05,750
ما با این مثال خطی شروع می کنیم
347
00:13:05,750 –> 00:13:07,760
و اساساً یک شبکه عصبی ساده می نویسیم
348
00:13:07,760 –> 00:13:09,950
349
00:13:09,950 –> 00:13:12,560
تا نقاط قرمز و آبی را به درستی طبقه بندی کنیم، بنابراین بیایید این مخزن github را دانلود کنیم
350
00:13:12,560 –> 00:13:14,950
و دو راه برای انجام این کار وجود دارد. من
351
00:13:14,950 –> 00:13:17,960
توصیه می کنم آن را فورک کنید و
352
00:13:17,960 –> 00:13:19,640
آن را به صورت محلی شبیه سازی کنید و من دستورالعمل هایی در مورد
353
00:13:19,640 –> 00:13:21,890
نحوه انجام این کار در اینجا دارم، اما
354
00:13:21,890 –> 00:13:24,470
گزینه دیگری که می توانید با آن بروید این است که به سادگی
355
00:13:24,470 –> 00:13:26,690
فایل فشرده را دانلود کنید و سپس آن را بردارید
356
00:13:26,690 –> 00:13:28,550
و آن را به هر کجا که می خواهید برای
357
00:13:28,550 –> 00:13:30,200
نوشتن کد استخراج کنید. آخرین چیزی که
358
00:13:30,200 –> 00:13:32,090
قبل از شروع به نوشتن کد می گویم این است که
359
00:13:32,090 –> 00:13:33,980
مطمئن شوید tensorflow را نصب کرده اید و
360
00:13:33,980 –> 00:13:35,630
احتمالاً ساده ترین راه برای انجام این کار
361
00:13:35,630 –> 00:13:38,030
نصب توزیع آناکوندا است
362
00:13:38,030 –> 00:13:39,440
و بنابراین من یک لینک در
363
00:13:39,440 –> 00:13:41,260
توضیحات در مورد نحوه انجام آن خواهم داشت. برای نصب آن
364
00:13:41,260 –> 00:13:44,720
درست و من از متن عالی استفاده خواهم کرد، ذهن
365
00:13:44,720 –> 00:13:46,820
من در آنجاست، اما ما می خواهیم به
366
00:13:46,820 –> 00:13:49,370
پوشه ای برویم که در
367
00:13:49,370 –> 00:13:51,680
هر جایی که فایل های خود را استخراج کردید یا فایل های خود را
368
00:13:51,680 –> 00:13:56,770
شبیه سازی کردید، آن را ایجاد کردیم و من با
369
00:13:56,770 –> 00:13:59,390
وارد شدن به مثال ها شروع می کنم. به
370
00:13:59,390 –> 00:14:03,530
صورت خطی و صرفاً فایلی
371
00:14:03,530 –> 00:14:06,850
به نام Network linear T را ذخیره می کنیم،
372
00:14:06,850 –> 00:14:08,859
چرا ما در حال نوشتن یک شبکه عصبی
373
00:14:08,859 –> 00:14:10,689
374
00:14:10,689 –> 00:14:12,939
375
00:14:12,939 –> 00:14:14,709
هستیم، اگر از آن استفاده می کنید و به طور خاص، همیشه اولین کاری که انجام می دهید این نیست که کتابخانه کامل تانسور کتابخانه مشعل PI را وارد کنید.
376
00:14:14,709 –> 00:14:16,239
برای این مثال، ما
377
00:14:16,239 –> 00:14:18,339
از Karis استفاده میکنیم، بنابراین میخواهیم Karis را
378
00:14:18,339 –> 00:14:21,299
از جریان تنسور وارد کنیم، بنابراین از
379
00:14:21,299 –> 00:14:27,759
واردات tensorflow، خاریس خوب است، پس
380
00:14:27,759 –> 00:14:30,459
احتمالاً میخواهیم برخی از کتابخانههای کمکی را نیز وارد کنیم،
381
00:14:30,459 –> 00:14:34,539
بنابراین فکر میکنم که
382
00:14:34,539 –> 00:14:36,970
در حال حاضر مهم هستند. برای وارد کردن پانداهای
383
00:14:36,970 –> 00:14:41,739
SPD و وارد کردن numpy بهعنوان NP و یک چیزی
384
00:14:41,739 –> 00:14:43,419
که میخواهم به سرعت به آن اشاره کنم این است که من
385
00:14:43,419 –> 00:14:46,869
در اینجا از کیت کمکپایلوت استفاده میکنم، بنابراین این یک
386
00:14:46,869 –> 00:14:49,089
ویژگی بسیار خوب است و اساساً وقتی
387
00:14:49,089 –> 00:14:52,509
چیزهایی را تایپ میکنم، نشانگر من را دنبال میکند
388
00:14:52,509 –> 00:14:56,970
و مستندات را بالا میبرد. را
389
00:14:56,970 –> 00:15:00,759
کد مرتبط بسیار خوب است و
390
00:15:00,759 –> 00:15:03,579
نکته دیگری که باید به سرعت به آن توجه کرد این است که در
391
00:15:03,579 –> 00:15:07,119
همان پوشه خطی که
392
00:15:07,119 –> 00:15:08,709
تصویر مثال را دارد و در جایی که
393
00:15:08,709 –> 00:15:10,959
فایل خود را ذخیره کردیم، دو فایل داده نیز
394
00:15:10,959 –> 00:15:13,149
وجود دارد، یک مجموعه داده آموزشی و یک مجموعه داده آزمایشی وجود دارد
395
00:15:13,149 –> 00:15:15,759
که با تولید نموداری
396
00:15:15,759 –> 00:15:19,720
که در اینجا میبینید، بنابراین ما به بارگیری نیاز داریم
397
00:15:19,720 –> 00:15:22,629
که این دادهها را انجام دهد، بنابراین فایلهای ما دقیقاً در اینجا هستند، بنابراین
398
00:15:22,629 –> 00:15:25,029
باید به دادهها برویم و سپس در آموزش بارگذاری کنیم
399
00:15:25,029 –> 00:15:27,639
تا شروع کنیم و سپس
400
00:15:27,639 –> 00:15:30,609
با آزمایش نیز همین کار را انجام میدهیم.
401
00:15:30,609 –> 00:15:32,529
فایل CSV با پانداها بارگیری می شود، بنابراین
402
00:15:32,529 –> 00:15:36,129
پانداها CSV را می خوانند و سپس مسیری که به
403
00:15:36,129 –> 00:15:39,970
شما نشان دادم پوشه داده بود و سپس
404
00:15:39,970 –> 00:15:42,909
فایل CSV Train dot و من همه
405
00:15:42,909 –> 00:15:44,559
این کدها را کمی بزرگتر می کنم تا بتوانید
406
00:15:44,559 –> 00:15:47,470
آن را بیشتر ببینید. واضح است و ما احتمالاً می خواهیم
407
00:15:47,470 –> 00:15:49,629
آن را برای مدتی ذخیره کنیم، بنابراین فقط
408
00:15:49,629 –> 00:15:52,539
آن را قاب داده آموزشی برابر
409
00:15:52,539 –> 00:15:55,239
آن می نامیم و می توانیم تأیید کنیم که
410
00:15:55,239 –> 00:15:58,809
با انجام Train D F سر نقطه بارگذاری شده است، اوه و
411
00:15:58,809 –> 00:16:01,679
احتمالاً باید آن را چاپ کنیم که
412
00:16:04,000 –> 00:16:06,680
خیلی خوب است، بنابراین بله. ما یک نقطه x
413
00:16:06,680 –> 00:16:08,690
نقطه Y و سپس رنگ و colo داریم r
414
00:16:08,690 –> 00:16:11,990
در اینجا فقط یک آرگومان صفر یا یک است، بنابراین
415
00:16:11,990 –> 00:16:14,690
ما آن را بارگذاری کرده ایم که خوب است، بنابراین اکنون
416
00:16:14,690 –> 00:16:16,100
می توانیم ادامه دهیم و در واقع یک
417
00:16:16,100 –> 00:16:18,110
شبکه عصبی حول این داده های آموزشی بسازیم
418
00:16:18,110 –> 00:16:20,540
و برای انجام این کار، می خواهیم
419
00:16:20,540 –> 00:16:24,740
با تعریف یک نوع متوالی Karass شروع کنیم. و
420
00:16:24,740 –> 00:16:27,200
چیزی که این ترتیب می گوید این است که
421
00:16:27,200 –> 00:16:29,330
ما تعداد مشخصی لایه
422
00:16:29,330 –> 00:16:31,310
در شبکه عصبی خود داریم، بنابراین این ترتیب
423
00:16:31,310 –> 00:16:34,130
در اینجا به ما امکان می
424
00:16:34,130 –> 00:16:35,570
دهد لایه های مختلفی را که در
425
00:16:35,570 –> 00:16:37,880
شبکه خود داریم لیست کنیم، بنابراین ما به جلو برویم و
426
00:16:37,880 –> 00:16:42,020
شروع به تعریف لایه ها کنیم. برای دسترسی به
427
00:16:42,020 –> 00:16:43,910
لایهها در هویج، میتوانید
428
00:16:43,910 –> 00:16:47,990
لایههای Karis dot را انجام دهید و سپس همه انواعی که
429
00:16:47,990 –> 00:16:49,280
در اینجا میبینید انواع مختلفی از لایهها هستند
430
00:16:49,280 –> 00:16:51,860
که میتوانید اضافه کنید.
431
00:16:51,860 –> 00:16:53,930
432
00:16:53,930 –> 00:16:56,540
433
00:16:56,540 –> 00:17:00,890
در اینجا چند
434
00:17:00,890 –> 00:17:02,960
چیز مختلف وجود دارد که میتوانیم آنها را به صورت متراکم بگذرانیم و
435
00:17:02,960 –> 00:17:06,200
میتوانید این آرگومانهای کلیدواژه مختلف
436
00:17:06,200 –> 00:17:08,300
را در اینجا در سمت راست در
437
00:17:08,300 –> 00:17:11,180
پنجره کمکی بادبادک ببینید، اما اولین
438
00:17:11,180 –> 00:17:12,470
چیزی که مورد نیاز
439
00:17:12,470 –> 00:17:15,310
است تعداد واحدهای w است. می خواهید استفاده کنید و
440
00:17:15,310 –> 00:17:18,380
با این کار آنچه می خواهید انجام دهید این
441
00:17:18,380 –> 00:17:20,480
است که در واقع اولین لایه خود را به عنوان اولین لایه پنهان خود تعریف کنید
442
00:17:20,480 –> 00:17:23,420
و خواهید دید
443
00:17:23,420 –> 00:17:26,750
که چرا در یک ثانیه، اما می توانم بگویم که
444
00:17:26,750 –> 00:17:28,850
فرض کنید ما فقط می خواهیم فورد بدون نورون در ما نباشد.
445
00:17:28,850 –> 00:17:30,830
اولین لایه پنهان در مرحله بعدی قرار است وارد
446
00:17:30,830 –> 00:17:32,570
کنیم و من به این
447
00:17:32,570 –> 00:17:34,010
مستندات نگاه می کنم تا کمی مرا راهنمایی کند که
448
00:17:34,010 –> 00:17:37,730
شکل ورودی است بنابراین
449
00:17:37,730 –> 00:17:39,710
ما در واقع شکل ورودی خود را
450
00:17:39,710 –> 00:17:43,310
به این لایه منتقل می کنیم و بنابراین اگر ما
451
00:17:43,310 –> 00:17:45,980
به یاد داشته باشید که x و y است،
452
00:17:45,980 –> 00:17:49,910
بنابراین یک بعد منفرد دو خواهد بود، سپس
453
00:17:49,910 –> 00:17:51,230
چیز دیگری که می توانیم به این
454
00:17:51,230 –> 00:17:54,050
لایه متراکم منتقل کنیم، عملکرد فعال سازی ما است
455
00:17:54,050 –> 00:17:55,520
و همانطور که در ابتدای این ویدیو ذکر کردم،
456
00:17:55,520 –> 00:17:57,740
معمولاً یک شرط مطمئن برای
457
00:17:57,740 –> 00:18:02,030
فعال سازی یک rel u است. واحد و به آنجا
458
00:18:02,030 –> 00:18:06,500
می رویم، اکنون یک لایه ورودی از
459
00:18:06,500 –> 00:18:10,190
دو نورون بدون نورون تعریف کرده ایم که به یک
460
00:18:10,190 –> 00:18:12,860
لایه مخفی از چهار نورون تغذیه می کند و آن
461
00:18:12,860 –> 00:18:14,720
چهار نورون لایه Hinn دارای یک فعال سازی rel u است
462
00:18:14,720 –> 00:18:16,559
463
00:18:16,559 –> 00:18:20,919
و سپس بیایید بگوییم بیایید این مثال اول را انجام دهیم
464
00:18:20,919 –> 00:18:22,749
زیرا داده ها خیلی ساده
465
00:18:22,749 –> 00:18:25,570
بیایید مثال اول خود را بسیار ساده بیان کنیم le
466
00:18:25,570 –> 00:18:26,980
و ما فقط می خواهیم این را در
467
00:18:26,980 –> 00:18:30,309
این یک لایه پنهان به لایه خروجی خود وارد کنیم
468
00:18:30,309 –> 00:18:32,200
و لایه خروجی ما نیز
469
00:18:32,200 –> 00:18:34,269
به این دلیل است که رنگ ها می توانند قرمز یا آبی باشند
470
00:18:34,269 –> 00:18:37,950
و در داده های ما مانند 0 یا 1 به نظر می رسد
471
00:18:37,950 –> 00:18:40,690
اما اینجا اولین عصبی ماست.
472
00:18:40,690 –> 00:18:43,419
این شبکه یک نورون دو گره به چهار
473
00:18:43,419 –> 00:18:46,539
نورون به دو نورون است، بنابراین بیایید در واقع
474
00:18:46,539 –> 00:18:48,549
مدل خود را با آن تطبیق دهیم و
475
00:18:48,549 –> 00:18:51,340
ابتدا می خواهیم مدل خود را کامپایل کنیم و این
476
00:18:51,340 –> 00:18:54,879
به ما می گوید که چگونه آن را آموزش دهیم
477
00:18:54,879 –> 00:18:56,529
تا بخواهیم از آن استفاده کنیم.
478
00:18:56,529 –> 00:19:01,720
بهینه ساز اتم و دوباره با این کامپایل خواهید دید،
479
00:19:01,720 –> 00:19:03,759
اغلب اوقات من
480
00:19:03,759 –> 00:19:06,190
نحو دقیق نوشتن این
481
00:19:06,190 –> 00:19:10,450
شبکه های کریس را فراموش می کنم، اما اگر به کامپایل بروم و سپس
482
00:19:10,450 –> 00:19:12,249
به یادداشت های خود در اینجا نگاه کنم، می بینیم که
483
00:19:12,249 –> 00:19:14,649
باید یک بهینه ساز را پاس کنیم. شرط مطمئن
484
00:19:14,649 –> 00:19:17,499
در اینجا این است که از اتم استفاده کنیم و سپس
485
00:19:17,499 –> 00:19:19,119
میتوانیم پیش برویم و یک تابع ضرر
486
00:19:19,119 –> 00:19:22,809
برای شبکه خود تعریف کنیم و برای انجام این کار میخواهیم
487
00:19:22,809 –> 00:19:26,710
تلفات نقطه caris را انجام دهیم و
488
00:19:26,710 –> 00:19:27,490
سپس خواهیم دید که چند
489
00:19:27,490 –> 00:19:30,700
گزینه مختلف در اینجا داریم. اما با ضرر به
490
00:19:30,700 –> 00:19:32,950
طور خاص من فکر می کنم گاهی اوقات آن را
491
00:19:32,950 –> 00:19:33,970
خوب است کمی اطلاعات بیشتری دریافت کنید
492
00:19:33,970 –> 00:19:35,559
و اگر روی آنها کلیک کنم
493
00:19:35,559 –> 00:19:38,190
، چیز زیادی در مورد
494
00:19:38,190 –> 00:19:41,049
نوع از دست دادن در اینجا به ما نمی گوید، بنابراین کاری که ما می خواهیم
495
00:19:41,049 –> 00:19:43,230
انجام دهیم این است که در واقع به مستندات تانسور فلوئورو برویم
496
00:19:43,230 –> 00:19:46,539
و من صفحه تلفات را می خواهم
497
00:19:46,539 –> 00:19:48,340
و به عنوان میتوانید ببینید که یک دسته
498
00:19:48,340 –> 00:19:51,100
گزینههای مختلف وجود دارد و دو
499
00:19:51,100 –> 00:19:52,990
عضو محبوبی که در اینجا دیدیم،
500
00:19:52,990 –> 00:19:54,879
آنتروپی متقاطع طبقهبندی بودند و آنتروپی طبقهبندی
501
00:19:54,879 –> 00:19:57,730
شده را جدا میکند، برای من مشخص نیست که فقط
502
00:19:57,730 –> 00:19:59,889
میخوانم تفاوت اینجا چیست،
503
00:19:59,889 –> 00:20:01,869
بنابراین این چیز خوبی است که میتوانیم به نوعی آن را
504
00:20:01,869 –> 00:20:05,740
بررسی کنیم. صفحه تلفات و زمان
505
00:20:05,740 –> 00:20:08,110
مستندات جریان، بنابراین ابتدا
506
00:20:08,110 –> 00:20:12,279
بر روی آنتروپی متقاطع طبقهای کلیک میکنم تا
507
00:20:12,279 –> 00:20:13,720
اتلاف آنتروپی متقاطع
508
00:20:13,720 –> 00:20:18,159
بین برچسبها و پیشبینیها را محاسبه کند، بنابراین همانطور که
509
00:20:18,159 –> 00:20:20,919
میبینید اینجا 0.9 بود، این نقطه
510
00:20:20,919 –> 00:20:22,720
صفر پنج بود و نقطه صفر پنج، واقعی بود.
511
00:20:22,720 –> 00:20:25,389
یک صفر صفر بود، بنابراین ما ضرر را
512
00:20:25,389 –> 00:20:26,230
بر روی آن محاسبه می کنیم که
513
00:20:26,230 –> 00:20:28,240
می دانید تفاوت بین آن است
514
00:20:28,240 –> 00:20:30,309
که بسیار خوب به نظر می رسد، اما
515
00:20:30,309 –> 00:20:33,580
مشکلی که در اینجا داریم این است که نحوه
516
00:20:33,580 –> 00:20:35,010
کدگذاری آنها کمی عجیب است
517
00:20:35,010 –> 00:20:37,390
. آنها در چیزی کدگذاری میشوند که به
518
00:20:37,390 –> 00:20:40,150
آن بازنماییهای تک داغ
519
00:20:40,150 –> 00:20:42,520
میگویند، بنابراین اساساً این میگوید برچسب 1
520
00:20:42,520 –> 00:20:44,679
میگوید برچسب 2 این میگوید برچسب 3
521
00:20:44,679 –> 00:20:46,960
و در دادههای ما که به آن نگاه
522
00:20:46,960 –> 00:20:50,410
میکنیم مقدار شناور فقط 0 یا 1 بود، پس
523
00:20:50,410 –> 00:20:52,900
چه چیزی است. برای ما خوب است که
524
00:20:52,900 –> 00:20:55,450
در اینجا انجام دهیم این است که در واقع بررسی کنیم که
525
00:20:55,450 –> 00:20:58,360
آنتروپی متقاطع طبقه بندی فضایی چیست و
526
00:20:58,360 –> 00:21:00,940
تفاوت بین این دو در این است
527
00:21:00,940 –> 00:21:02,860
که دقیقاً همان چیزی است که آخرین ضرر را می گوید،
528
00:21:02,860 –> 00:21:06,940
اما تفاوت اصلی اینجاست که می
529
00:21:06,940 –> 00:21:08,980
گوید از این تلفات آنتروپی متقاطع استفاده کنید. وقتی
530
00:21:08,980 –> 00:21:10,720
دو برچسب دیگر وجود دارد و این
531
00:21:10,720 –> 00:21:13,240
برای ما خوب است و ما انتظار داریم که برچسب ها به
532
00:21:13,240 –> 00:21:16,870
جای یک نمایش داغ به صورت اعداد صحیح ارائه شوند
533
00:21:16,870 –> 00:21:20,410
تا بتوانیم
534
00:21:20,410 –> 00:21:22,540
اعداد صحیح را در اینجا منتقل کنیم و مجبور نباشیم
535
00:21:22,540 –> 00:21:25,510
آنها را در یک نمایش داغ رمزگذاری کنیم،
536
00:21:25,510 –> 00:21:28,570
بنابراین برای این کار خوب است. بنابراین ما تعریف
537
00:21:28,570 –> 00:21:31,360
می کنیم که آنتروپی متقاطع طبقه بندی را حفظ می کند، بنابراین
538
00:21:31,360 –> 00:21:37,350
من آنتروپی متقاطع طبقه ای Perce را انجام می دهم
539
00:21:37,350 –> 00:21:46,590
و ببینیم اینطوری پیداش می کنیم
540
00:21:49,720 –> 00:21:52,700
و صادقانه بگویم اگر
541
00:21:52,700 –> 00:21:54,650
تکمیل خودکار را دیدید من پیشنهاد می کردم
542
00:21:54,650 –> 00:21:57,200
آن را اینگونه قالب بندی کنم و نه کاملا
543
00:21:57,200 –> 00:21:59,150
تفاوت بین این را بدانید من فقط می دانم در
544
00:21:59,150 –> 00:22:00,200
تمام مثال هایی که روی آنها کار
545
00:22:00,200 –> 00:22:02,650
کرده ام آن را با این نمایش تعریف می کنم
546
00:22:02,650 –> 00:22:05,390
و سپس آخرین چیزی که
547
00:22:05,390 –> 00:22:07,190
با این می خواهیم بگوییم این است
548
00:22:07,190 –> 00:22:12,800
که از logits برابر است درست است، بنابراین اگر
549
00:22:12,800 –> 00:22:16,130
به آن برگردم ضرر که یکی از
550
00:22:16,130 –> 00:22:17,900
گزینه هایی بود که ما با
551
00:22:17,900 –> 00:22:20,480
آنتروپی متقاطع طبقه بندی ویژه داشتیم و اگر
552
00:22:20,480 –> 00:22:22,610
کنجکاو هستید که چه چیزی از logits برابر است
553
00:22:22,610 –> 00:22:26,480
به این معنی است که من همیشه توصیه می کنم بدانید که
554
00:22:26,480 –> 00:22:30,820
ادامه دهید و در مورد این سوال در گوگل جستجو کنید
555
00:22:30,820 –> 00:22:34,640
و همانطور که می بینید من در حال بررسی بودم
556
00:22:34,640 –> 00:22:36,110
جریان پتانسیل API Docs در اینجا
557
00:22:36,110 –> 00:22:37,550
و مستندات پر تنش آنها
558
00:22:37,550 –> 00:22:39,260
از یک کلمه کلیدی به نام logits استفاده میکنند،
559
00:22:39,260 –> 00:22:42,410
خوب ما یک پاسخ کوچک خوب در اینجا پیدا کردیم
560
00:22:42,410 –> 00:22:44,360
و به سادگی به این معنی است که تابع
561
00:22:44,360 –> 00:22:46,130
بر روی خروجی
562
00:22:46,130 –> 00:22:49,550
مقیاسناپذیر لایههای قبلی و به
563
00:22:49,550 –> 00:22:51,860
ویژه مجموع ممکن است ورودیها با 1 برابر نباشند
564
00:22:51,860 –> 00:22:54,020
و این همان چیزی است که ما میخواهیم، زیرا ما از
565
00:22:54,020 –> 00:22:56,300
قادیری استفاده میکنیم که لزوماً مش
566
00:22:56,300 –> 00:22:59,480
به نی
567
00:22:59,480 –> 00:23:01,070
568
00:23:01,070 –> 00:23:03,740
تند. nt برای استفاده از
569
00:23:03,740 –> 00:23:07,730
from logits برابر است با کلمه کلیدی واقعی و
570
00:23:07,730 –> 00:23:09,800
سپس آخرین چیزی که میخواهیم آن را پیگیری کنیم
571
00:23:09,800 –> 00:23:12,860
یک متریک است و میخواهیم از
572
00:23:12,860 –> 00:23:15,380
متریک دقت استفاده کنیم تا ببینیم
573
00:23:15,380 –> 00:23:19,220
شبکه ما هنگام ارزیابی آن
574
00:23:19,220 –> 00:23:23,090
چگونه عمل میکند، بنابراین در آنجا نحوه کار را کامپایل کردهایم. شبکه
575
00:23:23,090 –> 00:23:25,880
قرار است آموزش ببیند و یاد بگیرد، بنابراین
576
00:23:25,880 –> 00:23:28,340
از بهینهساز اتمی استفاده میکند که
577
00:23:28,340 –> 00:23:31,220
میفهمد در حال بهروزرسانی است، اوه عکس، دیدم
578
00:23:31,220 –> 00:23:36,190
من یک چشم از بهینهساز رها کردهام که
579
00:23:36,190 –> 00:23:39,080
شبکه را بر اساس تابع تلفات متقاطع آنتروپی یدکی بهروزرسانی میکند.
580
00:23:39,080 –> 00:23:43,660
581
00:23:45,370 –> 00:23:46,870
که ما واقعاً میتوانیم
582
00:23:46,870 –> 00:23:49,510
پیش برویم و دادههای آموزشی را در
583
00:23:49,510 –> 00:23:53,680
شبکه خود قرار دهیم، بنابراین همانطور که در اینجا میبینید،
584
00:23:53,680 –> 00:23:58,660
انتظار یک X Y و یک اندازه دستهای وجود دارد، بنابراین
585
00:23:58,660 –> 00:24:02,860
مقادیر X ما در اینجا مختصات x و
586
00:24:02,860 –> 00:24:05,230
y و مقادیر مرتبط
587
00:24:05,230 –> 00:24:07,630
با آنها Y هستند. مقدار در
588
00:24:07,630 –> 00:24:11,260
اینجا رنگ 0 یا 1 خواهد بود و اندازه دسته ای
589
00:24:11,260 –> 00:24:13,090
که می توانیم به نوعی تعیین کنیم که می خواهیم چقدر بزرگ
590
00:24:13,090 –> 00:24:16,170
باشد، بنابراین بیایید بگوییم اندازه دسته
591
00:24:16,170 –> 00:24:21,490
برابر با 16 است تا شروع کنیم، بنابراین اکنون x
592
00:24:21,490 –> 00:24:23,320
و y ما به خوبی در اینجا به چه چیزی نگاه می کنیم.
593
00:24:23,320 –> 00:24:26,980
اسناد ما می بینیم که arg ument X
594
00:24:26,980 –> 00:24:30,400
داده ورودی است و انتظار دارد یک
595
00:24:30,400 –> 00:24:34,210
نوع آرایه numpy یا لیستی از
596
00:24:34,210 –> 00:24:34,770
آرایه
597
00:24:34,770 –> 00:24:37,210
ها را نیز در یک تانسور جریان
598
00:24:37,210 –> 00:24:41,320
تانسور یا لیستی از تانسورها ارسال کنید و
599
00:24:41,320 –> 00:24:43,150
سپس چند گزینه دیگر وجود دارد که ما
600
00:24:43,150 –> 00:24:46,230
روی آن numpy تمرکز می کنیم. آرایه و
601
00:24:46,230 –> 00:24:48,610
بنابراین در حال حاضر ما داده های خود را در یک قاب داده داریم
602
00:24:48,610 –> 00:24:50,380
که بدیهی است یک
603
00:24:50,380 –> 00:24:52,810
آرایه numpy نیست، اما آنچه واقعاً خوب است این است که
604
00:24:52,810 –> 00:24:56,530
می توانیم به راحتی فریم داده را از
605
00:24:56,530 –> 00:25:00,010
پانداها به یک آرایه numpy تبدیل کنیم و فقط با انجام
606
00:25:00,010 –> 00:25:04,030
نقطه Train DF در ستونی که ما انجام می دهیم میخواهید به
607
00:25:04,030 –> 00:25:09,250
مقادیر نقطه دسترسی داشته باشید و بنابراین
608
00:25:09,250 –> 00:25:12,670
دادهها را به شکل numpy دریافت میکند و من میتوانم به
609
00:25:12,670 –> 00:25:16,660
شما نشان دهم که با انجام 0 تا 5 و Train DF
610
00:25:16,660 –> 00:25:20,350
dot X Dogg میتوانیم اطراف آن را
611
00:25:20,350 –> 00:25:24,760
با یک نوع احاطه کنیم و سپس میتوانیم هر
612
00:25:24,760 –> 00:25:33,490
دوی این موارد را چاپ کنیم. و این را چاپ کنید
613
00:25:33,490 –> 00:25:34,930
و همه اینها را سریعاً نظر
614
00:25:34,930 –> 00:25:38,140
میدهیم تا اجرا نشود، ببینید این
615
00:25:38,140 –> 00:25:41,740
مقادیر X ما به شکل numpy هستند و نوع
616
00:25:41,740 –> 00:25:44,590
آن numpy است، بنابراین میبینیم که درست است،
617
00:25:44,590 –> 00:25:46,540
بنابراین اجازه دهید ادامه دهیم و
618
00:25:46,540 –> 00:25:49,600
چیزها را به شبکه خود منتقل کنیم. و ما توجه می کنیم که
619
00:25:49,600 –> 00:25:50,860
می توانستیم دقیقا همین کار را انجام دهیم g
620
00:25:50,860 –> 00:25:55,120
با برچسب رنگ و همچنین مقادیر Y
621
00:25:55,120 –> 00:25:57,870
622
00:25:58,380 –> 00:26:00,640
و فقط برای کمک به ما می خواهم
623
00:26:00,640 –> 00:26:08,860
دوباره آن قاب داده را چاپ کنم تا
624
00:26:08,860 –> 00:26:12,160
برای مقدار y ما که رنگ است،
625
00:26:12,160 –> 00:26:15,580
بتوانیم جلو برویم و رنگ نقطه D F را
626
00:26:15,580 –> 00:26:18,250
پر کنیم. مقادیر نقطه برای به دست آوردن آن در
627
00:26:18,250 –> 00:26:20,890
شکل ناقص X کمی مشکل است
628
00:26:20,890 –> 00:26:24,940
زیرا فقط مقدار x نیست، بلکه X و
629
00:26:24,940 –> 00:26:26,530
مقدار y است زیرا هر دوی آنها
630
00:26:26,530 –> 00:26:28,540
در تأثیرگذاری بر اینکه آیا
631
00:26:28,540 –> 00:26:31,840
چیزی در نمودار قرمز یا آبی است یا نه، مهم هستند، بنابراین
632
00:26:31,840 –> 00:26:33,250
ما چه میکنیم. در اینجا باید این کار را انجام دهید این است که
633
00:26:33,250 –> 00:26:37,270
در واقع آن ستون ها را کنار هم قرار دهید تا
634
00:26:37,270 –> 00:26:39,490
جفت شوند، بنابراین من می گویم x
635
00:26:39,490 –> 00:26:44,320
برابر است با پشته ستون numpy و ما می خواهیم
636
00:26:44,320 –> 00:26:48,640
مقادیری را که در
637
00:26:48,640 –> 00:26:51,070
ستون X هستند، مقادیر X نقطه را روی هم قرار دهیم تا به یک عدد برسیم.
638
00:26:51,070 –> 00:26:53,350
قبل و مقادیری که در ستون Y هستند
639
00:26:53,350 –> 00:26:58,450
مقادیر DF dot y dot را آموزش می دهند، بنابراین اکنون
640
00:26:58,450 –> 00:27:00,880
کاری که این کار انجام می دهد جفت شدن
641
00:27:00,880 –> 00:27:04,510
این است به عنوان نوع ورودی اول این
642
00:27:04,510 –> 00:27:06,250
ورودی دوم است این ورودی سوم
643
00:27:06,250 –> 00:27:09,820
تمام این ستون ها X و ستون y
644
00:27:09,820 –> 00:27:11,920
اکنون با این دستور پشته ستون با هم جفت می شود
645
00:27:11,920 –> 00:27:14,290
و من فقط می توانم پاس کنم یک X