در این مطلب، ویدئو به حداکثر رساندن سرعت پایتون با بردارسازی Numpy (قسمت 1) با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:08:45
تصاویر این ویدئو:
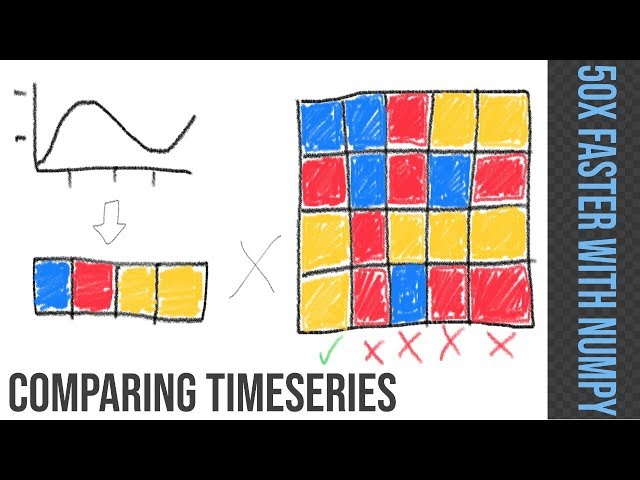

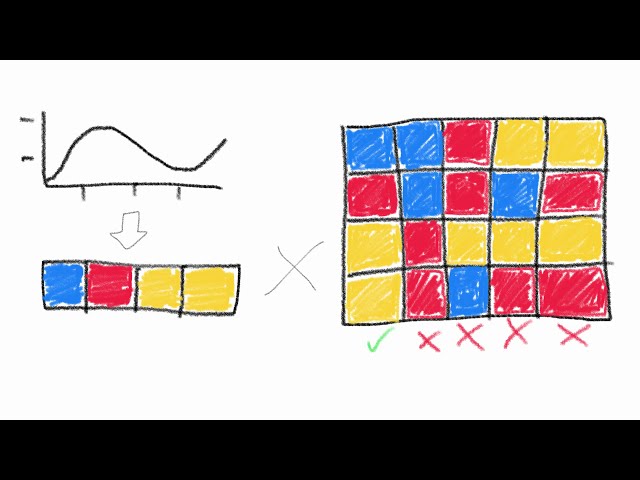

قسمتی از زیرنویس این فیلم:
00:00:00,149 –> 00:00:02,340
شخصی به سراغ من آمد که مشکلی داشت،
2
00:00:02,340 –> 00:00:03,899
ما سعی میکردیم تعداد
3
00:00:03,899 –> 00:00:07,560
چیزهایی را که باید به کاربر برای
4
00:00:07,560 –> 00:00:09,690
دادههای سری زمانی نشان میداد کاهش دهیم و
5
00:00:09,690 –> 00:00:11,700
منحنیهای کاملاً زیادی داشتند تا آن شخص بتواند به
6
00:00:11,700 –> 00:00:14,820
طور مؤثر آن را بفهمد
7
00:00:14,820 –> 00:00:17,940
و کاهش دهد. او
8
00:00:17,940 –> 00:00:19,770
شباهتهای بین این منحنیها
9
00:00:19,770 –> 00:00:23,400
را پیدا میکرد تا کاهش مؤثری
10
00:00:23,400 –> 00:00:25,859
داشته باشد، باید منحنیهای بسیار زیادی را کاهش میداد و
11
00:00:25,859 –> 00:00:28,920
تاریخچه بسیار طولانی داشتند، بنابراین وقتی
12
00:00:28,920 –> 00:00:31,710
این کار را با SQL انجام داد، بسیار
13
00:00:31,710 –> 00:00:34,980
ناکارآمد بود و SQL در واقع
14
00:00:34,980 –> 00:00:37,610
برای آن بسیار پیچیده بود.
15
00:00:37,610 –> 00:00:41,160
وقتی او آن را در پایتون بازنویسی کرد، چه کاری انجام میداد،
16
00:00:41,160 –> 00:00:43,980
بسیار کند بود و ما باید
17
00:00:43,980 –> 00:00:46,710
دریابیم که چگونه کارآمدی را بهبود بخشیم،
18
00:00:46,710 –> 00:00:49,890
بنابراین وقتی میگویید دنباله آهسته
19
00:00:49,890 –> 00:00:52,350
منظورتان چیست و چگونه میتوانیم این مشکل را حل کنیم
20
00:00:52,350 –> 00:00:56,100
تا SQL نباشد. انجام نمیشود،
21
00:00:56,100 –> 00:00:58,680
SQL برای این مورد کند نیست،
22
00:00:58,680 –> 00:01:01,320
بلکه روشی بسیار ناکارآمد برای
23
00:01:01,320 –> 00:01:04,619
حل این نوع مشکلات است، بنابراین
24
00:01:04,619 –> 00:01:07,310
بهجای انجام پیوندها، جستجوها و شاخصها،
25
00:01:07,310 –> 00:01:10,500
میدانیم که اینها و سریهای زمانی
26
00:01:10,500 –> 00:01:14,189
همه شما به خط میپردازید.
27
00:01:14,189 –> 00:01:15,750
بنابراین منطقیتر است که آنها را به ترتیب نگه دارید
28
00:01:15,750 –> 00:01:18,570
و آنها را
29
00:01:18,570 –> 00:01:22,740
بهجای تلاش برای پیوستن به یکدیگر زیپ کنید، و زمانی که
30
00:01:22,740 –> 00:01:26,250
این کد را از SQL به Python تبدیل کردید،
31
00:01:26,250 –> 00:01:30,329
بسیاری از این موارد قبلاً گفته شده بود که
32
00:01:30,329 –> 00:01:33,090
قبلاً یک مزیت بزرگ است که
33
00:01:33,090 –> 00:01:34,799
سرعت این پرس و جو قبلاً
34
00:01:34,799 –> 00:01:37,290
از زمان باورنکردنی به شش ثانیه رسیده بود، منظورم شش
35
00:01:37,290 –> 00:01:39,420
دقیقه زمان باورنکردنی
36
00:01:39,420 –> 00:01:42,479
قبل از آن زمان بود، اما هنوز راه زیادی وجود دارد،
37
00:01:42,479 –> 00:01:46,170
بنابراین من این مشکل
38
00:01:46,170 –> 00:01:49,399
را در اصل آن در اینجا خلاصه کردم که صرفاً یک
39
00:01:49,399 –> 00:01:52,560
گروه از اطلاعات سری زمانی است.
40
00:01:52,560 –> 00:01:55,290
اساساً یک ماتریس را تشکیل می دهد، بنابراین ما
41
00:01:55,290 –> 00:01:59,369
منحنی های زیادی داریم و برای مثال ما
42
00:01:59,369 –> 00:02:02,130
در اینجا هزار مورد را به شما نشان می دهم و هر
43
00:02:02,130 –> 00:02:04,020
یک از آنها تعداد معینی از
44
00:02:04,020 –> 00:02:06,540
نمونه های تاریخ مرتبط با آنها دارد
45
00:02:06,540 –> 00:02:10,050
که همچنین هزار است و ما می خواهیم
46
00:02:10,050 –> 00:02:13,250
برای هر یک از آنها پیدا کنیم. این منحنیها
47
00:02:13,250 –> 00:02:15,800
شبیهترین همسایهها هستند و با
48
00:02:15,800 –> 00:02:18,950
انجام این کار، ما فقط مجموع مجذور
49
00:02:18,950 –> 00:02:21,200
خطا را در برابر هر یک از همسایگان آنها گرفتیم
50
00:02:21,200 –> 00:02:24,770
و سپس شبیهترین
51
00:02:24,770 –> 00:02:26,720
همسایه را از همسایگان آنها انتخاب کردیم، بسیار
52
00:02:26,720 –> 00:02:30,050
ساده است. اما این می تواند آغاز یک
53
00:02:30,050 –> 00:02:33,290
الگوریتم نسبتاً خوب باشد، بنابراین وقتی برای اولین بار
54
00:02:33,290 –> 00:02:35,090
این را در پایتون می نویسید، ساده ترین
55
00:02:35,090 –> 00:02:38,750
راه این است که همه آنها
56
00:02:38,750 –> 00:02:43,790
را در لیستی از لیست ها قرار دهید و سپس دو لیست را
57
00:02:43,790 –> 00:02:46,340
با هم مقایسه کنید و متوجه شوید که چقدر شبیه
58
00:02:46,340 –> 00:02:48,650
هستند. و سپس آن را برای هر
59
00:02:48,650 –> 00:02:51,860
جفت لیست ممکن تکرار کنید و هنگامی
60
00:02:51,860 –> 00:02:55,580
که آن ساختار را داشته باشید، کمترین
61
00:02:55,580 –> 00:02:57,709
تفاوت و مرتبط با هر
62
00:02:57,709 –> 00:03:00,320
منحنی را پیدا خواهید کرد، چرا می خواهیم کمترین
63
00:03:00,320 –> 00:03:02,650
تفاوت را با هر منحنی مرتبط
64
00:03:02,650 –> 00:03:05,180
کنیم زیرا در این مورد از آن استفاده می کنیم
65
00:03:05,180 –> 00:03:08,840
این برای خوشهبندی تجمعی است، بنابراین ما به
66
00:03:08,840 –> 00:03:11,570
سادگی میگوییم که میتوانید
67
00:03:11,570 –> 00:03:16,190
این درخت از خوشهها را بزرگنمایی یا کوچک کنید و
68
00:03:16,190 –> 00:03:20,180
این خانواده خوشهای و یا این بخش
69
00:03:20,180 –> 00:03:24,140
از این گروه از منحنیها و هر یک
70
00:03:24,140 –> 00:03:26,959
از منحنیترین منحنیهای آنها و برای
71
00:03:26,959 –> 00:03:28,280
هر یک از آنها را پیدا کنید. از
72
00:03:28,280 –> 00:03:30,590
نشاندهندهترین منحنیها و غیره تا
73
00:03:30,590 –> 00:03:33,110
مردم بتوانند انتخاب کنند اگر فکر
74
00:03:33,110 –> 00:03:34,940
میکنند این منحنی جالب است، میتوانند
75
00:03:34,940 –> 00:03:37,820
بروند زیربخشها یا خانوادهها یا
76
00:03:37,820 –> 00:03:40,970
خانوادههای فرعی آن منحنی را پیدا کنند، بنابراین بیایید بگوییم اگر من
77
00:03:40,970 –> 00:03:43,100
100 دارم. منحنی 0 منظور شما از
78
00:03:43,100 –> 00:03:45,799
یافتن جالب ترین منحنی ها چیست این است که من
79
00:03:45,799 –> 00:03:48,290
می خواهم مقدار را به
80
00:03:48,290 –> 00:03:52,000
10 کاهش دهم و روشی را برای
81
00:03:52,000 –> 00:03:55,670
کاهش کارآمد آنچه باید به آن نگاه
82
00:03:55,670 –> 00:04:00,140
کنیم به 10 ابداع کرده ام، بنابراین 10 یک نوع است. در اینجا دلخواه است،
83
00:04:00,140 –> 00:04:04,430
اما ما می خواهیم برای شروع منحنی های بسیار کمی را به کاربر نشان
84
00:04:04,430 –> 00:04:06,410
دهیم، زیرا می
85
00:04:06,410 –> 00:04:10,820
خواهیم همه آنها را در یک صفحه نمایش دهیم، بنابراین
86
00:04:10,820 –> 00:04:13,280
10 عدد معقولی است که
87
00:04:13,280 –> 00:04:15,799
در بیشتر موارد روی صفحه قرار می گیرد و ما آنها را
88
00:04:15,799 –> 00:04:19,220
به 10 من نشان می دهیم. حدس بزنید می توانید
89
00:04:19,220 –> 00:04:23,539
منحنی های مختلف را بگویید و برای هر یک از
90
00:04:23,539 –> 00:04:24,540
آن 10
91
00:04:24,540 –> 00:04:26,790
منحنی که شبیه ترین منحنی ها هستند، به
92
00:04:26,790 –> 00:04:28,710
این ترتیب شما فقط باید حدود