

در این مطلب، ویدئو نحوه طراحی و ساخت یک خط لوله سیستم توصیه در پایتون (جیل کیتس) با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:21:45
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:04,940 –> 00:00:08,880
بنابراین سلام به همه، نام من جیل کیتس است و
2
00:00:08,880 –> 00:00:11,510
من یک دانشمند داده در شرکتی به نام
3
00:00:11,510 –> 00:00:15,570
بیومتریک در تورنتو هستم، بنابراین در اوایل
4
00:00:15,570 –> 00:00:17,880
سال جاری، من
5
00:00:17,880 –> 00:00:20,250
وظیفه ایجاد یک سیستم توصیهکننده قابل استقرار
6
00:00:20,250 –> 00:00:22,380
برای مقالات تحقیقاتی پزشکی را برعهده
7
00:00:22,380 –> 00:00:26,039
گرفتم و به سرعت متوجه شدم که تعداد زیادی وجود دارد.
8
00:00:26,039 –> 00:00:28,320
منابع موجود برای مدلهای توصیهگر وجود دارد،
9
00:00:28,320 –> 00:00:31,499
اما یافتن اطلاعات در
10
00:00:31,499 –> 00:00:33,150
مورد سایر مراحل مربوط به
11
00:00:33,150 –> 00:00:34,890
خط لوله توصیهگر بسیار
12
00:00:34,890 –> 00:00:38,670
دشوار بود، بنابراین امروز
13
00:00:38,670 –> 00:00:42,000
تمام مراحل مربوط
14
00:00:42,000 –> 00:00:43,410
به ساخت یک
15
00:00:43,410 –> 00:00:45,960
خط لوله توصیهگر را طی میکنم، بنابراین من این مراحل را طی خواهم کرد.
16
00:00:45,960 –> 00:00:48,329
مراحل آموزش پیش پردازش
17
00:00:48,329 –> 00:00:53,399
مدل تنظیم پارامترهایپرومتر پس از پردازش
18
00:00:53,399 –> 00:00:55,829
و همچنین ارزیابی، بنابراین در پایان این
19
00:00:55,829 –> 00:00:57,840
بحث، ایده خوبی در مورد اینکه از
20
00:00:57,840 –> 00:00:58,440
کجا شروع کنید
21
00:00:58,440 –> 00:01:00,600
و از چه ابزارهایی برای ساختن
22
00:01:00,600 –> 00:01:03,600
خط لوله توصیهکننده خود استفاده کنید، خواهید داشت، اما
23
00:01:03,600 –> 00:01:05,580
قبل از اینکه ما وارد جزئیات این
24
00:01:05,580 –> 00:01:07,680
خط لوله شوید، من ابتدا قصد دارم یک
25
00:01:07,680 –> 00:01:10,650
معرفی سریع در مورد توصیهکنندگان به شما ارائه کنم، بنابراین
26
00:01:10,650 –> 00:01:12,630
احتمالاً بسیاری از شما قبلاً توصیهکننده را
27
00:01:12,630 –> 00:01:16,200
میشناسید. هر جا که ما
28
00:01:16,200 –> 00:01:18,390
آن را میبینیم، Spotify و Spotify بهصورت هفتگی کشف میکنند که در
29
00:01:18,390 –> 00:01:20,520
آن
30
00:01:20,520 –> 00:01:24,300
فهرستهای پخش شخصیسازی شده را در نتفلیکس میبینیم، بنابراین
31
00:01:24,300 –> 00:01:26,430
چون شما نارنجی و شما
32
00:01:26,430 –> 00:01:29,040
سیاهپوست تماشا کردهاید، توصیه میکنیم همه این
33
00:01:29,040 –> 00:01:32,160
برنامههای دیگر را تماشا کنید و همچنین آن را در آمازون میبینیم،
34
00:01:32,160 –> 00:01:34,980
بنابراین مشتریانی که پاپ میکنند این را خریداری کنند. کتاب
35
00:01:34,980 –> 00:01:38,880
همچنین همه این موارد دیگر را خریداری کرده است که
36
00:01:38,880 –> 00:01:41,880
ما آن را در سایتهای دوستیابی میبینیم، بنابراین آنها معمولاً
37
00:01:41,880 –> 00:01:43,980
همه این اطلاعات را درباره شما جمعآوری
38
00:01:43,980 –> 00:01:46,590
میکنند و سعی میکنند بر اساس شخصیت شما حدس بزنند که بهترین منطبق
39
00:01:46,590 –> 00:01:47,940
با شما کدام است
40
00:01:47,940 –> 00:01:51,960
و فقط برای ادامه
41
00:01:51,960 –> 00:01:55,620
این فهرست کار جستجو میکند. اخبار و حتی
42
00:01:55,620 –> 00:01:59,390
در پزشکی برای توصیهکنندگان تصمیمگیری بالینی
43
00:01:59,420 –> 00:02:02,040
اگرچه موضوع بسیار داغ
44
00:02:02,040 –> 00:02:05,910
در تجارت الکترونیک است، اما در زمانی که
45
00:02:05,910 –> 00:02:08,758
تجارت الکترونیکی وجود نداشت، چیزها
46
00:02:08,758 –> 00:02:10,830
منحصراً در فروشگاههای آجری فروخته میشد،
47
00:02:10,830 –> 00:02:14,939
بنابراین موجودی فروشگاهها به محدود بود.
48
00:02:14,939 –> 00:02:15,540
49
00:02:15,540 –> 00:02:17,790
فضای فروشگاه و محصولاتی که
50
00:02:17,790 –> 00:02:22,349
فروش خوبی نداشتند سودآور نبودند، بنابراین
51
00:02:22,349 –> 00:02:25,370
منطقی ترین انتخاب این بود که فقط
52
00:02:25,370 –> 00:02:28,620
محبوب ترین محصولات را بفروشید و مطمئن هستم که
53
00:02:28,620 –> 00:02:30,510
اکثر شما این کار را کرده اید. وارد یک کتابفروشی شدم
54
00:02:30,510 –> 00:02:33,510
و بلافاصله همه
55
00:02:33,510 –> 00:02:37,549
کتابهای پرفروش ارائه شده به شما را دیدم، اما زمانی که
56
00:02:37,549 –> 00:02:40,650
تجارت الکترونیک شروع شد،
57
00:02:40,650 –> 00:02:43,049
روش فروش ما تغییر کرد، بنابراین اکنون
58
00:02:43,049 –> 00:02:45,420
موجودی نامحدودی داریم که به این معنی است که
59
00:02:45,420 –> 00:02:47,400
محصولات ویژهای که قبلا
60
00:02:47,400 –> 00:02:50,040
در آجر و آجر نادیده گرفته میشدند. فروشگاههای ملات
61
00:02:50,040 –> 00:02:54,450
اکنون بهراحتی آنلاین در دسترس هستند و بنابراین برای
62
00:02:54,450 –> 00:02:55,799
کسانی از شما که کتابی
63
00:02:55,799 –> 00:02:58,169
به نام دم دراز نوشته کریس
64
00:02:58,169 –> 00:03:00,090
اندرسون را خواندهاند، میآموزند که محصولات
65
00:03:00,090 –> 00:03:02,519
خاص درآمد بسیار زیادی
66
00:03:02,519 –> 00:03:06,419
را در خردهفروشیهای آنلاین ایجاد میکنند، اما داشتن
67
00:03:06,419 –> 00:03:09,090
مجموعه گستردهای از پیشنهادات باعث نمیشود.
68
00:03:09,090 –> 00:03:10,889
لزوماً به این معنی نیست که کاربران کالاهای بیشتری خریداری خواهند
69
00:03:10,889 –> 00:03:14,730
کرد، بنابراین در سال 2000
70
00:03:14,730 –> 00:03:16,680
یک مطالعه تحقیقاتی در
71
00:03:16,680 –> 00:03:19,949
غرفه مزه سوپرمارکت انجام شد که یک غرفه دارای
72
00:03:19,949 –> 00:03:22,680
6 نمونه مربا بود و غرفه دیگر
73
00:03:22,680 –> 00:03:24,510
دارای 24 نمونه مربا بود،
74
00:03:24,510 –> 00:03:27,540
بنابراین غرفه با نمونه های بیشتر بیشتر جذب شد.
75
00:03:27,540 –> 00:03:30,510
کاربران اما به نظر می رسد که این
76
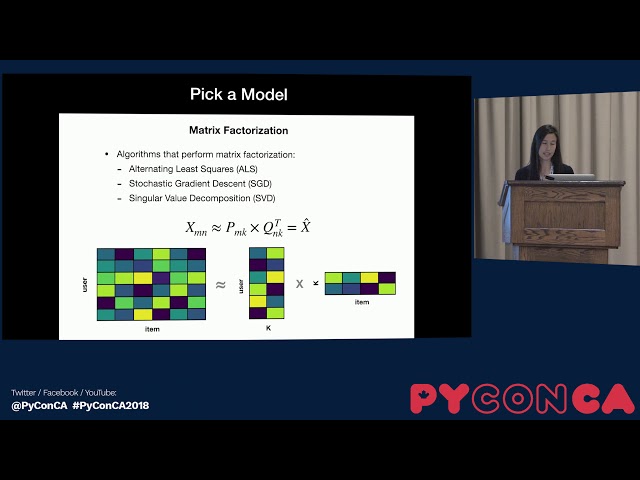
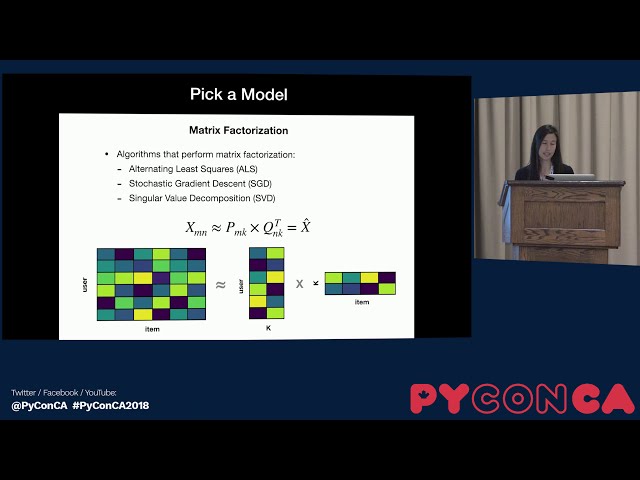
00:03:30,510 –> 00:03:33,659
غرفه شش نمونه بوده و دارای نرخ تبدیل 30 درصدی
77
00:03:33,659 –> 00:03:35,669
بوده و غرفه های 24
78
00:03:35,669 –> 00:03:37,019
نمونه تنها دارای نرخ تبدیل سه درصدی
79
00:03:37,019 –> 00:03:39,479
بوده اند. داشتن طیف گسترده ای
80
00:03:39,479 –> 00:03:41,940
از گزینه ها ممکن است برای مصرف کنندگان بسیار جذاب به نظر برسد،
81
00:03:41,940 –> 00:03:44,069
اما نشان داده شده است که
82
00:03:44,069 –> 00:03:45,870
در واقع انگیزه آنها
83
00:03:45,870 –> 00:03:48,840
را برای خرید محصول بعدی کاهش می دهد.
84
00:03:48,840 –> 00:03:50,310
85
00:03:50,310 –> 00:03:51,900
86
00:03:51,900 –> 00:03:54,409
87
00:03:54,409 –> 00:03:58,229
بسیار مهم است که وقتی
88
00:03:58,229 –> 00:04:00,659
موجودی نامحدود داریم، توصیهکنندگان
89
00:04:00,659 –> 00:04:02,939
فقط مرتبطترین موارد را
90
00:04:02,939 –> 00:04:08,760
برای یک کاربر خاص فیلتر میکنند، بنابراین یک
91
00:04:08,760 –> 00:04:11,129
سیستم توصیهگر درست مانند هر
92
00:04:11,129 –> 00:04:13,859
مدل یادگیری ماشینی است که با
93
00:04:13,859 –> 00:04:16,738
مقداری داده شروع میکنید، آنها را به مدل ارسال میکنید
94
00:04:16,738 –> 00:04:20,519
و پیشبینیها را خروجی میدهد، بنابراین در این
95
00:04:20,519 –> 00:04:24,150
سناریو دادههای ما ترجیح کاربر
96
00:04:24,150 –> 00:04:25,879
نسبت به یک محصول است،
97
00:04:25,879 –> 00:04:28,160
بنابراین این میتواند به صورت
98
00:04:28,160 –> 00:04:31,160
بازخورد صریح باشد، بنابراین کاربر به
99
00:04:31,160 –> 00:04:33,410
طور مستقیم رتبهبندی میکند یا مستقیماً یک
100
00:04:33,410 –> 00:04:36,289
فیلم را دوست دارد و همچنین
101
00:04:36,289 –> 00:04:38,210
به صورت بازخورد ضمنی میآید.
102
00:04:38,210 –> 00:04:39,919
این کمی ظریفتر است، اما این
103
00:04:39,919 –> 00:04:42,110
رفتار غیرمستقیم شما نسبت به یک آیتم است، بنابراین
104
00:04:42,110 –> 00:04:45,879
چه آن برنامه را تماشا کنید یا
105
00:04:45,879 –> 00:04:49,340
روی پخش مجدد یک آهنگ کلیک کرده باشید.
106
00:04:49,340 –> 00:04:49,900
107
00:04:49,900 –> 00:04:52,430
بنابراین، با وارد کردن همه این
108
00:04:52,430 –> 00:04:55,550
تنظیمات برگزیده کاربر به
109
00:04:55,550 –> 00:04:58,610
مدل سیستم توصیهگر خود، میتوانیم
110
00:04:58,610 –> 00:05:00,590
پیشبینیهایی در مورد رفتار آینده شما ایجاد
111
00:05:00,590 –> 00:05:03,050
کنیم، بنابراین پیشبینی میکنیم کدام
112
00:05:03,050 –> 00:05:05,630
آهنگ بعدی را دوست خواهید داشت یا کدام برنامه
113
00:05:05,630 –> 00:05:08,900
را بعداً تماشا خواهید کرد. اینها
114
00:05:08,900 –> 00:05:12,880
اساساً همان چیزی است که ما توصیه مینامیم،
115
00:05:12,880 –> 00:05:16,310
بنابراین دو رویکرد رایج برای
116
00:05:16,310 –> 00:05:18,199
سیستمهای توصیهگر وجود دارد، ما
117
00:05:18,199 –> 00:05:19,580
فیلتر مشارکتی و فیلتر
118
00:05:19,580 –> 00:05:23,479
مبتنی بر محتوا داریم، بنابراین
119
00:05:23,479 –> 00:05:25,610
فیلتر مشارکتی بر این فرض استوار است که
120
00:05:25,610 –> 00:05:29,120
افراد مشابه چیزهای مشابه را دوست دارند، بنابراین
121
00:05:29,120 –> 00:05:31,880
بیایید بگوییم که در حال ساخت یک فیلم توصیهکننده
122
00:05:31,880 –> 00:05:34,550
برای آن هستیم. نمیداند شما کی هستید
123
00:05:34,550 –> 00:05:37,819
یا این فیلمها چیست، ما فقط
124
00:05:37,819 –> 00:05:40,849
به تعاملات شما با
125
00:05:40,849 –> 00:05:42,560
این فیلمها و سایر
126
00:05:42,560 –> 00:05:45,110
تعاملات کاربران با فیلم نگاه میکنیم، بنابراین
127
00:05:45,110 –> 00:05:48,469
دادههای اصلی یک مدل فیلتر مشترک
128
00:05:48,469 –> 00:05:51,650
، ماتریس آیتم کاربر یا چیزی است که ما آن را
129
00:05:51,650 –> 00:05:55,360
مینامیم. ماتریس ابزار و بنابراین هر عدد در
130
00:05:55,360 –> 00:05:59,150
این ماتریس نشان دهنده امتیاز یک کاربر
131
00:05:59,150 –> 00:06:02,659
از یک فیلم معین است و هدف ما در اینجا
132
00:06:02,659 –> 00:06:05,330
پر کردن جاهای خالی آن است. بنابراین
133
00:06:05,330 –> 00:06:07,250
اساساً ما سعی میکنیم پیشبینی کنیم
134
00:06:07,250 –> 00:06:08,659
که به همه فیلمهایی
135
00:06:08,659 –> 00:06:12,560
که هنوز تماشا نکردهاید به چه امتیازی میدهید، خوب است، بنابراین
136
00:06:12,560 –> 00:06:15,469
نوع دیگر توصیهکننده یک
137
00:06:15,469 –> 00:06:19,610
مدل فیلتر مبتنی بر محتوا است و
138
00:06:19,610 –> 00:06:22,370
بنابراین به محتوای کاربران و
139
00:06:22,370 –> 00:06:25,190
فیلمها نگاه میکند.
140
00:06:25,190 –> 00:06:29,090
ویژگیهای شما مانند سن یا جنسیت
141
00:06:29,090 –> 00:06:32,029
شما را در نظر میگیرد که به چه زبانی صحبت میکنید و همچنین به
142
00:06:32,029 –> 00:06:35,449
ویژگیهای فیلم نگاه میکند، بنابراین در سالی که فیلم
143
00:06:35,449 –> 00:06:37,860
تولید شد، چه خندهدار بود،
144
00:06:37,860 –> 00:06:40,590
چه یک فیلم مستقل یا یک
145
00:06:40,590 –> 00:06:42,689
تولید فیلم بزرگ و با نگاه کردن به همه فیلمها.
146
00:06:42,689 –> 00:06:44,669
این ویژگیها سعی میکند
147
00:06:44,669 –> 00:06:48,870
توصیههایی را از این طریق ایجاد کند، بنابراین اکنون که ما
148
00:06:48,870 –> 00:06:51,150
ایده بهتری درباره اینکه یک توصیهکننده
149
00:06:51,150 –> 00:06:53,849
چیست، بیایید با ساخت خط لوله خود شروع کنیم،
150
00:06:53,849 –> 00:06:56,219
بنابراین من
151
00:06:56,219 –> 00:06:58,979
تمام مراحل پنجگانه این خط لوله را که
152
00:06:58,979 –> 00:07:01,919
شامل پارامترهایپر پیش پردازش میشود، طی خواهم کرد.
153
00:07:01,919 –> 00:07:04,430
آموزش مدل تنظیم
154
00:07:04,430 –> 00:07:07,439
قبل از پردازش و آخرین اما نه کم اهمیت ترین
155
00:07:07,439 –> 00:07:10,860
ارزیابی، بنابراین برای ادامه با مثال فیلم،
156
00:07:10,860 –> 00:07:12,960
ما قصد داریم با
157
00:07:12,960 –> 00:07:15,990
مجموعه داده ای کار کنیم که رتبه بندی کاربران را به ما ارائه می دهد.
158
00:07:15,990 –> 00:07:18,900
vies، بنابراین ما
159
00:07:18,900 –> 00:07:21,150
چیزی در مورد این کاربران نمی دانیم، ما
160
00:07:21,150 –> 00:07:23,639
چیزی در مورد این فیلم ها نمی دانیم، ما فقط رتبه بندی ها را داریم
161
00:07:23,639 –> 00:07:26,069
، بنابراین این بدان معنی است که ما
162
00:07:26,069 –> 00:07:29,400
از فیلتر مشترک استفاده می کنیم،
163
00:07:29,400 –> 00:07:32,159
ابتدا باید این جدول را که
164
00:07:32,159 –> 00:07:34,979
در اینجا داریم به یک کاربر تبدیل کنیم. بر اساس ماتریس آیتم و
165
00:07:34,979 –> 00:07:38,639
در این ماتریس، هر سطر نشاندهنده
166
00:07:38,639 –> 00:07:41,219
رتبهبندی یک کاربر و هر ستون
167
00:07:41,219 –> 00:07:45,449
نشاندهنده رتبهبندی یک فیلم است،
168
00:07:45,449 –> 00:07:48,270
بنابراین تمام سلولهای او در اینجا
169
00:07:48,270 –> 00:07:51,330
با رتبهبندیهایی که به ما داده شده است پر میشوند، بنابراین
170
00:07:51,330 –> 00:07:53,879
این ماتریس معمولاً به عنوان
171
00:07:53,879 –> 00:07:57,539
یک داستان علمی تخیلی نشان داده میشود. ماتریس CSR پراکنده و من فقط
172
00:07:57,539 –> 00:07:59,129
میخواهم توجه داشته باشم که همه این
173
00:07:59,129 –> 00:08:01,589
سلولهای خالی در اینجا با صفر پر
174
00:08:01,589 –> 00:08:03,360
نشدهاند، در واقع خالی هستند، بنابراین حتی اگر
175
00:08:03,360 –> 00:08:06,960
ماتریس شما میتواند بسیار بزرگ باشد،
176
00:08:06,960 –> 00:08:12,960
معمولاً اندازه کوچکی دارد و
177
00:08:12,960 –> 00:08:14,909
این در واقع یک اشکال است. که همراه
178
00:08:14,909 –> 00:08:16,889
با فیلتر مشارکتی است،
179
00:08:16,889 –> 00:08:20,419
اگر مجموعه دادههای شما پراکنده باشد، عملکرد خوبی ندارد،
180
00:08:20,419 –> 00:08:22,650
بنابراین برای ما مهم است
181
00:08:22,650 –> 00:08:25,680
که پراکندگی ماتریس خود را محاسبه کنیم، میتوانیم این کار را
182
00:08:25,680 –> 00:08:27,779
با شمارش تعداد کل
183
00:08:27,779 –> 00:08:30,210
رتبهبندیهایی که داریم و تقسیم انجام دهیم. آن را بر
184
00:08:30,210 –> 00:08:34,110
اساس تعداد سلولهای ماتریس خود محاسبه کنید و اگر
185
00:08:34,110 –> 00:08:36,360
دادههای شما خیلی کم است و چیزی در
186
00:08:36,360 –> 00:08:39,899
حدود 0.5 درصد
187
00:08:39,899 –> 00:08:41,578
است، ممکن است فیلتر مشارکتی بهترین گزینه
188
00:08:41,578 –> 00:08:45,959
نباشد، همچنین ارزش این را دارد که
189
00:08:45,959 –> 00:08:48,830
به تعداد کاربران جدید و موارد جدید
190
00:08:48,830 –> 00:08:52,640
ما توجه کنید. به این ماتریس نگاه کنید،
191
00:08:52,640 –> 00:08:55,340
ردیفهایی که خالی هستند و ستونهایی که
192
00:08:55,340 –> 00:08:57,320
خالی هستند نشاندهنده کاربران جدید هستند و
193
00:08:57,320 –> 00:09:00,560
فیلمهای جدید جدید و فیلترینگ مشترک
194
00:09:00,560 –> 00:09:04,180
برای این افراد یا فیلمها کار نمیکند،
195
00:09:04,180 –> 00:09:07,310
بنابراین اگر نسبت بالایی از
196
00:09:07,310 –> 00:09:10,280
کاربران و فیلمهای جدید داریم، ممکن است
197
00:09:10,280 –> 00:09:13,130
استفاده از آن را در نظر بگیریم. برخی از فیلترهای مبتنی بر محتوا یا
198
00:09:13,130 –> 00:09:14,630
ترکیبی از فیلترهای مشارکتی و
199
00:09:14,630 –> 00:09:16,910
مبتنی بر محتوا، اما برای
200
00:09:16,910 –> 00:09:19,400
هدف این بحث، اجازه دهید فرض کنیم
201
00:09:19,400 –> 00:09:23,000
که ما تعدادی داریم، مجموعه داده ای داریم
202
00:09:23,000 –> 00:09:26,480
که به اندازه کافی متراکم است که بتوانیم ادامه دهیم،
203
00:09:26,480 –> 00:09:29,120
بنابراین مرحله بعدی برای ما است. برای عادی
204
00:09:29,120 –> 00:09:31,790
سازی داده های ما، همیشه تعدادی کاربر
205
00:09:31,790 –> 00:09:34,880
بیش از حد مثبت و کاربران بیش از حد
206
00:09:34,880 –> 00:09:37,400
منفی وجود خواهد داشت، بنابراین باید
207
00:09:37,400 –> 00:09:40,670
تعصب کاربر و مورد را در نظر بگیریم، من دوست دارم این
208
00:09:40,670 –> 00:09:43,550
افراد را خوش بین یا بدبین بنامم.
209
00:09:43,550 –> 00:09:45,080
خوش بین ها تمایل دارند
210
00:09:45,080 –> 00:09:47,330
همه چیز را چهار یا پنج رتبه بندی کنند و
211
00:09:47,330 –> 00:09:48,950
اگرچه کمی نادرتر هستند، برخی بدبینان وجود دارند
212
00:09:48,950 –> 00:09:50,900
که همه چیز را با یک یا دو رتبه بندی می کنند،
213
00:09:50,900 –> 00:09:54,460
بنابراین یک راه بسیار ساده
214
00:09:54,460 –> 00:09:59,000
برای توضیح این سوگیری استفاده از عادی سازی میانگین است،
215
00:09:59,000 –> 00:10:01,520
بنابراین اساساً آنچه انجام می
216
00:10:01,520 –> 00:10:04,340
دهید شما هستید. میانگین امتیاز یک فیلم را بگیرید
217
00:10:04,340 –> 00:10:07,820
و آن میانگین را از
218
00:10:07,820 –> 00:10:10,610
هر رتبه بندی کاربران آن فیلم کم کنید و می
219
00:10:10,610 –> 00:10:12,350
توانید همین کار را برای کاربر انجام دهید،
220
00:10:12,350 –> 00:10:14,840
بنابراین میانگین امتیاز یک جوان را از یک
221
00:10:14,840 –> 00:10:17,030
کاربر متوسط بگیرید و آن را از هم
222
00:10:17,030 –> 00:10:20,000
رتبه های آن کم کنید. کاربر داده است و به
223
00:10:20,000 –> 00:10:23,360
این ترتیب است که ما داده های خود را عادی می کنیم،
224
00:10:23,360 –> 00:10:26,300
بنابراین اکنون که داده های خود را از قبل پردازش کرده ایم،
225
00:10:26,300 –> 00:10:29,570
اکنون باید یک مدل انتخاب کنیم و بنابراین
226
00:10:29,570 –> 00:10:31,670
فاکتورسازی ماتریس یک تکنیک رایج
227
00:10:31,670 –> 00:10:34,730
در فیلترینگ مشترک است،
228
00:10:34,730 –> 00:10:37,730
ما با ماتریس مورد کاربر خود شروع می کنیم و
229
00:10:37,730 –> 00:10:40,520
آن را فاکتورسازی می کنیم. به دو
230
00:10:40,520 –> 00:10:44,420
ماتریس عامل پنهان، بنابراین ما یک کاربر داریم، یک
231
00:10:44,420 –> 00:10:48,890
ماتریس عامل کاربر و یک ماتریس عامل آیتم
232
00:10:48,890 –> 00:10:50,240
233
00:10:50,240 –> 00:10:53,029
و فاکتورهای نهفته در اینجا با K نشان داده می
234
00:10:53,029 –> 00:10:56,899
شوند، همانطور که در این نمودار می بینید و
235
00:10:56,899 –> 00:10:59,270
می توان آن را به عنوان ویژگیهای پنهانی
236
00:10:59,270 –> 00:11:01,070
که زیربنای تعاملات بین
237
00:11:01,070 –> 00:11:04,820
کاربران و آیتمها هستند، بنابراین ما در واقع
238
00:11:04,820 –> 00:11:07,250
نمیدانیم هر آینده پنهان چه چیزی را نشان م








![فیلم آموزشی: [حل شد] python pyenv - خطا zlib در دسترس نیست مک](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/iX-LsOf7VVgimage2.jpg)



