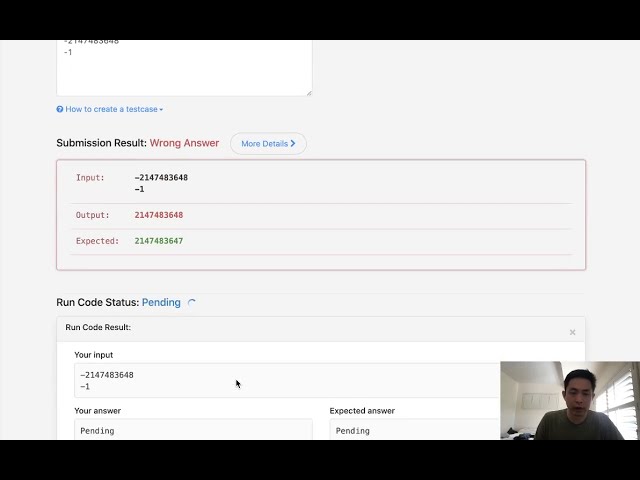
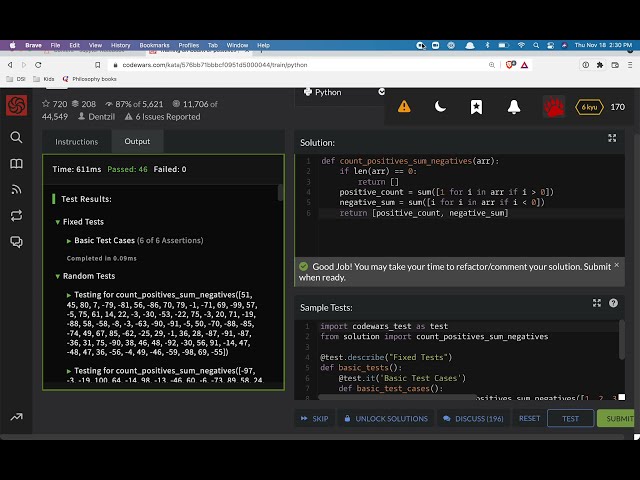
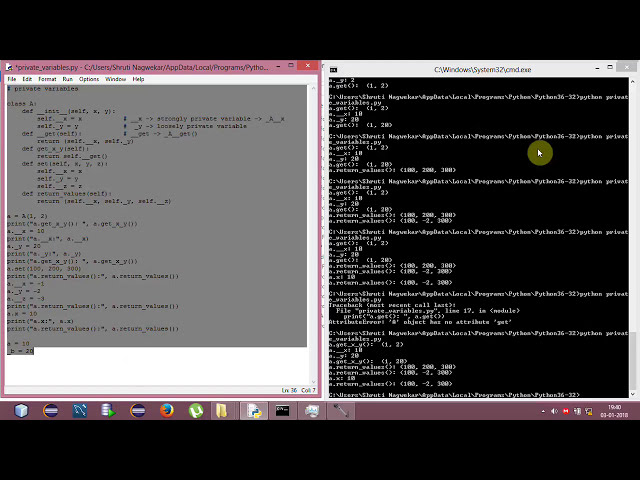
در این مطلب، ویدئو رونویسی ویدیو به متن با پایتون و واتسون در 15 دقیقه با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:15:11
تصاویر این ویدئو:
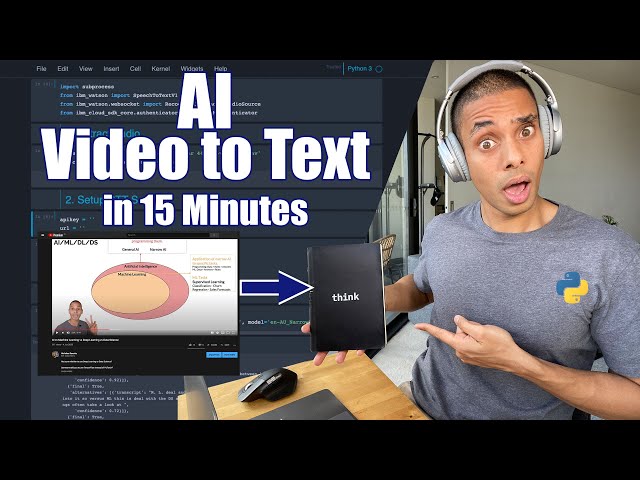

قسمتی از زیرنویس این فیلم:
00:00:00,080 –> 00:00:01,599
همیشه ای کاش می توانستید به طور خودکار
2
00:00:01,599 –> 00:00:03,360
یادداشت های سخنرانی را از فیلم های سخنرانی خود ایجاد کنید
3
00:00:03,360 –> 00:00:04,080
4
00:00:04,080 –> 00:00:05,920
یا شاید از نوشتن صورتجلسات جلسه خسته شده اید،
5
00:00:05,920 –> 00:00:07,520
می دانم که من
6
00:00:07,520 –> 00:00:09,120
خوب هستم در این ویدیو ما به
7
00:00:09,120 –> 00:00:11,280
طور کامل حل می کنیم آنچه اتفاق می افتد بچه ها
8
00:00:11,280 –> 00:00:12,639
نام من نیکلاس رونت است و در این
9
00:00:12,639 –> 00:00:14,160
ویدیو ما قصد داریم به
10
00:00:14,160 –> 00:00:15,360
ویدیو به متن
11
00:00:15,360 –> 00:00:17,199
علاقه مند نگاهی بیندازیم، بیایید با
12
00:00:17,199 –> 00:00:18,560
جزئیات بیشتری به آنچه که قرار است بگذریم نگاهی بیندازیم،
13
00:00:18,560 –> 00:00:19,199
14
00:00:19,199 –> 00:00:20,720
بنابراین در این ویدیو ما قصد داریم
15
00:00:20,720 –> 00:00:22,720
ویدیو را به متن تبدیل
16
00:00:22,720 –> 00:00:24,800
کنیم تا ابتدا با
17
00:00:24,800 –> 00:00:27,279
استفاده از کتابخانه dl یوتیوب برای دانلود
18
00:00:27,279 –> 00:00:29,279
تقریباً هر ویدیوی یوتیوب شروع
19
00:00:29,279 –> 00:00:30,880
می کنیم، سپس آن
20
00:00:30,880 –> 00:00:32,399
ویدیو را با استفاده از کتابخانه ffmpeg به صوت از قبل پردازش می کنیم،
21
00:00:32,399 –> 00:00:34,880
بنابراین این کار واقعاً آسان است
22
00:00:34,880 –> 00:00:36,160
و به شما امکان می دهد
23
00:00:36,160 –> 00:00:38,640
صدا را خارج کنید. از هر ویدیویی،
24
00:00:38,640 –> 00:00:40,719
سپس آن ویدیو را
25
00:00:40,719 –> 00:00:42,719
با استفاده از سرویس فناوری بلندگوی واتسون
26
00:00:42,719 –> 00:00:44,879
به صورت رایگان به متن تبدیل میکنیم و سپس
27
00:00:44,879 –> 00:00:46,239
نتایج حاصل
28
00:00:46,239 –> 00:00:48,239
از آن تبدیل را به یک فایل متنی خروجی
29
00:00:48,239 –> 00:00:50,000
میدهیم تا پس از آن یک تصویر کامل داشته باشید. رونوشت
30
00:00:50,000 –> 00:00:50,800
که می توانید
31
00:00:50,800 –> 00:00:53,280
سپس دور شوید و بدون نگرانی
32
00:00:53,280 –> 00:00:54,879
در مورد آن استفاده کنید، بنابراین از نظر
33
00:00:54,879 –> 00:00:56,160
نحوه انجام این کار، ما
34
00:00:56,160 –> 00:00:57,920
عمدتاً در داخل یک
35
00:00:57,920 –> 00:00:59,760
نوت بوک مشتری کار می کنیم، بنابراین ابتدا با
36
00:00:59,760 –> 00:01:01,840
استخراج صدای خود از دستگاه خود شروع می کنیم. ویدیویی را که
37
00:01:01,840 –> 00:01:02,960
قبلاً
38
00:01:02,960 –> 00:01:05,438
با استفاده از عملکرد dl youtube دانلود کردهایم،
39
00:01:05,438 –> 00:01:07,280
سپس آن را با استفاده از گفتار watson
40
00:01:07,280 –> 00:01:08,240
به سرویس فناوری تبدیل میکنیم
41
00:01:08,240 –> 00:01:09,840
و در آخر میخواهیم
42
00:01:09,840 –> 00:01:12,159
آن را با استفاده از عملکرد بومی پایتون
43
00:01:12,159 –> 00:01:14,320
برای ایجاد یک فایل متنی
44
00:01:14,320 –> 00:01:16,400
آماده کنیم. این کار را انجام دهید، بیایید به آن برسیم، بنابراین در
45
00:01:16,400 –> 00:01:17,920
این ویدیو ما روی
46
00:01:17,920 –> 00:01:19,200
تبدیل یک
47
00:01:19,200 –> 00:01:21,119
ویدیو به متن تمرکز خواهیم کرد، اکنون
48
00:01:21,119 –> 00:01:23,040
عمدتاً در پایتون کار می کنیم، بنابراین
49
00:01:23,040 –> 00:01:24,880
من قبلاً یک نوت بوک
50
00:01:24,880 –> 00:01:26,880
jupyter در اینجا دارم. مراحل اصلی ما که
51
00:01:26,880 –> 00:01:28,640
قرار است طی کنیم، نصب
52
00:01:28,640 –> 00:01:30,240
و وارد کردن وابستگیهایی است
53
00:01:30,240 –> 00:01:33,439
که صدای ما را با استفاده از ffmpeg استخراج میکند
54
00:01:33,439 –> 00:01:35,360
و سپس سرویس گفتار خود را به متن ایجاد میکند و آن را
55
00:01:35,360 –> 00:01:36,880
به متن تبدیل میکند
56
00:01:36,880 –> 00:01:40,159
و آن را به یک فایل txt خروجی میدهیم،
57
00:01:40,159 –> 00:01:41,840
اکنون در این مورد میخواهیم اضافه کنیم در
58
00:01:41,840 –> 00:01:43,360
یک مرحله اضافی که در
59
00:01:43,360 –> 00:01:44,960
اینجا گنجانده نشده است و گرفتن یک
60
00:01:44,960 –> 00:01:45,600
ویدیو
61
00:01:45,600 –> 00:01:47,600
است، برای مثال بگویید ما یک
62
00:01:47,600 –> 00:01:49,360
ویدیوی یوتیوب داشتیم که میخواستیم آن را به خوبی بگیریم، در واقع میتوانیم آن را بگیریم
63
00:01:49,360 –> 00:01:50,399
که
64
00:01:50,399 –> 00:01:52,960
با استفاده از کتابخانه YouTube dl این
65
00:01:52,960 –> 00:01:54,880
احتمالاً یکی از کتابخانههای مورد علاقه من است
66
00:01:54,880 –> 00:01:56,640
که به شما امکان میدهد آن را بگیرید. اگر میخواهید یادداشت برداری
67
00:01:56,640 –> 00:01:58,320
کنید، ویدیوهای خود را تبدیل کنید و ویدیوهای خود را تبدیل کنید یا ویدیوهای دیگر را تبدیل کنید،
68
00:01:58,320 –> 00:01:58,799
69
00:01:58,799 –> 00:02:00,960
70
00:02:00,960 –> 00:02:02,719
بنابراین برای نصب youtube
71
00:02:02,719 –> 00:02:05,280
dl فقط باید یک ترمینال جدید باز کنیم
72
00:02:05,280 –> 00:02:07,759
و سپس pip install
73
00:02:07,759 –> 00:02:11,360
youtube dl را تایپ کنیم تا
74
00:02:11,360 –> 00:02:11,760
مراحل
75
00:02:11,760 –> 00:02:13,280
نصب انجام شود.
76
00:02:13,280 –> 00:02:15,360
برای استفاده از دستور نصب pip به هر چیزی که نیاز دارید به python نیاز دارید،
77
00:02:15,360 –> 00:02:17,280
اما باید
78
00:02:17,280 –> 00:02:19,120
آن را برای شما نصب کند، سپس تنها کاری که باید
79
00:02:19,120 –> 00:02:20,400
انجام دهید این است که یوتیوب dl را تایپ کنید
80
00:02:20,400 –> 00:02:22,800
و سپس یک لینک از ویدیوی مورد نظر خود را
81
00:02:22,800 –> 00:02:24,319
بگیرید، بنابراین در این مورد من او را
82
00:02:24,319 –> 00:02:24,879
83
00:02:24,879 –> 00:02:26,879
در مقابل یادگیری ماشینی در مقابل یادگیری عمیق
84
00:02:26,879 –> 00:02:28,720
در مقابل ویدیوی علم داده دریافت کردم
85
00:02:28,720 –> 00:02:31,599
و میتوانیم آن پیوند را بعد
86
00:02:31,599 –> 00:02:33,200
از دستور dl
87
00:02:33,200 –> 00:02:34,959
88
00:02:34,959 –> 00:02:36,879
یوتیوب بچسبانیم و
89
00:02:36,879 –> 00:02:38,319
اینتر را بزنید. ng آن را در فهرست اصلی خود دانلود کنید
90
00:02:38,319 –> 00:02:40,000
، اما سپس میتوانیم آن
91
00:02:40,000 –> 00:02:42,560
را برداریم و در همان فهرستی
92
00:02:42,560 –> 00:02:44,000
که نوتبوک jupyter خود را داریم قرار دهیم، بنابراین
93
00:02:44,000 –> 00:02:45,760
اجازه دهید آن دانلود شود و سپس میتوانیم
94
00:02:45,760 –> 00:02:47,360
شروع
95
00:02:47,360 –> 00:02:49,200
کنیم تا ویدیوی ما اکنون دانلود شود.
96
00:02:49,200 –> 00:02:51,120
باز را فشار دهید
97
00:02:51,120 –> 00:02:52,640
و آن را در
98
00:02:52,640 –> 00:02:54,400
همان دایرکتوری باز کنید، بنابراین میتوانید در اینجا ببینید که ما در
99
00:02:54,400 –> 00:02:56,319
مقابل یادگیری ماشینی در مقابل
100
00:02:56,319 –> 00:02:57,920
یادگیری عمیق، نقطه make v
101
00:02:57,920 –> 00:03:00,640
را داریم، بنابراین میتوانیم آن را در پوشه ویدیوی
102
00:03:00,640 –> 00:03:01,360
خود در
103
00:03:01,360 –> 00:03:03,440
پوشه متن کپی کنیم. وقتی واقعاً کار با این فایل را شروع میکنیم، نام آن را تغییر میدهیم
104
00:03:03,440 –> 00:03:04,879
تا زندگیمان کمی آسانتر
105
00:03:04,879 –> 00:03:06,400
106
00:03:06,400 –> 00:03:09,519
شود، بنابراین آن را
107
00:03:09,519 –> 00:03:12,560
aiml dot make v بسیار عالی مینامیم، بنابراین
108
00:03:12,560 –> 00:03:15,280
فایل ویدیوی ما تمام شده است، اکنون میتوانیم وارد
109
00:03:15,280 –> 00:03:16,400
قسمت
110
00:03:16,400 –> 00:03:17,519
خوب شویم. اولین کاری که میخواهیم
111
00:03:17,519 –> 00:03:19,680
انجام دهیم این است که ابتدا وابستگیهای خود را نصب کنیم،
112
00:03:19,680 –> 00:03:21,760
اکنون دو وابستگی کلیدی در اینجا
113
00:03:21,760 –> 00:03:24,239
داریم که باید خدمات ibm watson را داشته
114
00:03:24,239 –> 00:03:26,200
باشیم و همچنین باید ffmpeg را نصب کنیم،
115
00:03:26,200 –> 00:03:29,920
بنابراین ffmpeg اساساً یک کتابخانه است
116
00:03:29,920 –> 00:03:31,200
که به شما کمک میکند با آن کار کنید.
117
00:03:31,200 –> 00:03:33,040
یک دسته کامل از فایل های ویدئویی و فایل های
118
00:03:33,040 –> 00:03:34,879
صوتی es و ما از آن برای
119
00:03:34,879 –> 00:03:37,120
استخراج صدا از ویدیوی خود استفاده می کنیم
120
00:03:37,120 –> 00:03:38,239
تا آن
121
00:03:38,239 –> 00:03:41,280
را به سرویس گفتار واتسون به متن ارسال
122
00:03:41,280 –> 00:03:42,799
کنیم تا بتوانیم این وابستگی ها را
123
00:03:42,799 –> 00:03:44,640
در نوت بوک jupyter خود نصب کنیم، پس بیایید ادامه دهیم
124
00:03:44,640 –> 00:03:47,840
و این کار را انجام دهیم
125
00:03:50,560 –> 00:03:52,239
تا من ادامه دادیم و
126
00:03:52,239 –> 00:03:54,159
این وابستگیها را اکنون نصب کردیم تا این کار را انجام
127
00:03:54,159 –> 00:03:55,360
دهیم، ما از دستور pip
128
00:03:55,360 –> 00:03:57,760
install ibm watson استفاده کردهایم و
129
00:03:57,760 –> 00:03:59,760
آن را کامنت گذاشتهام، اما اگر
130
00:03:59,760 –> 00:04:00,319
131
00:04:00,319 –> 00:04:03,280
میخواهید ffmpeg را نصب کنید، فقط باید brew
132
00:04:03,280 –> 00:04:04,000
install
133
00:04:04,000 –> 00:04:06,400
ffmpeg را تایپ کنید. یک مک اگر از یک
134
00:04:06,400 –> 00:04:07,280
دستگاه ویندوز استفاده
135
00:04:07,280 –> 00:04:08,799
می کنید، مراحل اضافی روی این
136
00:04:08,799 –> 00:04:10,480
پیوند وجود دارد، اما من
137
00:04:10,480 –> 00:04:12,560
دوباره لینک این را برای نصب آن
138
00:04:12,560 –> 00:04:15,360
و همچنین یک مخزن کامل github برای این
139
00:04:15,360 –> 00:04:16,399
آموزش
140
00:04:16,399 –> 00:04:19,358
در توضیحات زیر قرار می
141
00:04:19,358 –> 00:04:21,040
دهم، بنابراین اکنون که چیزی که میتوانیم برویم و
142
00:04:21,040 –> 00:04:21,440
انجام دهیم این
143
00:04:21,440 –> 00:04:23,919
است که وابستگیهای خود را وارد کنیم، بنابراین در این
144
00:04:23,919 –> 00:04:25,440
مورد از
145
00:04:25,440 –> 00:04:27,120
وابستگیهای ibm watson به علاوه
146
00:04:27,120 –> 00:04:29,600
از فرآیند فرعی برای اجرای واقعی
147
00:04:29,600 –> 00:04:31,199
استخراج صدا استفاده میکنیم،
148
00:04:31,199 –> 00:04:34,880
بنابراین اجازه دهید ابتدا وابستگیهای خود را وارد کنیم.
149
00:04:40,840 –> 00:04:43,840
150
00:04:47,680 –> 00:04:50,000
تا آن آر وابستگیهای ما وارد شدند،
151
00:04:50,000 –> 00:04:51,120
بنابراین ما
152
00:04:51,120 –> 00:04:52,800
چند چیز
153
00:04:52,800 –> 00:04:54,800
را وارد کردیم، بنابراین ابتدا فرآیند فرعی را وارد کردیم و این
154
00:04:54,800 –> 00:04:56,000
به ما امکان میدهد
155
00:04:56,000 –> 00:04:58,560
با استفاده از ترمینال معمولی خود یک فراخوانی فرآیند فرعی برقرار کنیم،
156
00:04:58,560 –> 00:04:59,360
157
00:04:59,360 –> 00:05:01,520
سپس گفتار را به کلاس متن وارد کردیم.
158
00:05:01,520 –> 00:05:03,280
از ibm watson
159
00:05:03,280 –> 00:05:04,960
و این قرار است برای
160
00:05:04,960 –> 00:05:06,639
اتصال به سرویس گفتار ما به متن استفاده شود،
161
00:05:06,639 –> 00:05:08,720
ما همچنین چند کمک کننده را
162
00:05:08,720 –> 00:05:10,160
در اینجا وارد کرده ایم، بنابراین تماس
163
00:05:10,160 –> 00:05:12,400
مجدد و همچنین منبع صوتی را دوباره از ibm
164
00:05:12,400 –> 00:05:13,520
watson شناسایی کنید و
165
00:05:13,520 –> 00:05:15,840
آخرین اما مهم نیست که ما وارد کرده ایم. iam
166
00:05:15,840 –> 00:05:17,520
authenticator بنابراین به ما اجازه میدهد
167
00:05:17,520 –> 00:05:18,880
تا در مقابل
168
00:05:18,880 –> 00:05:20,240
سرویس گفتار به نوشتار خود احراز هویت کنیم،
169
00:05:20,240 –> 00:05:22,240
پس از راهاندازی آن، کار بعدی
170
00:05:22,240 –> 00:05:23,680
که میخواهیم انجام دهیم این است که در واقع
171
00:05:23,680 –> 00:05:25,120
صدای خود را استخراج کنیم،
172
00:05:25,120 –> 00:05:27,280
بنابراین به یاد داشته باشید زمانی که ویدیوی خود را استخراج
173
00:05:27,280 –> 00:05:29,840
کردیم، این مورد را داشتیم. ویدیوی aiml در اینجا
174
00:05:29,840 –> 00:05:31,600
اکنون اولین کاری که میخواهیم انجام دهیم این است که
175
00:05:31,600 –> 00:05:33,919
آن ویدیو را بگیریم و صدا را از آن استخراج کنیم
176
00:05:33,919 –> 00:05:36,560
تا بتوانیم گفتار را به متن تبدیل کنیم، بنابراین
177
00:05:36,560 –> 00:05:38,400
بیایید این کار را انجام دهیم و
178
00:05:38,400 –> 00:05:41,600
برای انجام آن از ffmpeg استفاده میکنیم.
179
00:05:50,840 –> 00:05:53,199
180
00:05:53,199 –> 00:05:55,360
پس ما اکنون رفتهایم و
181
00:05:55,360 –> 00:05:57,039
صدای خود را استخراج کردهایم و اکنون از نظر کارهایی که در
182
00:05:57,039 –> 00:05:58,560
اینجا انجام دادهایم، از طریق یک دستور عبور دادهایم
183
00:05:58,560 –> 00:05:59,600
184
00:05:59,600 –> 00:06:01,440
و آن دستور اساساً کتابخانه ffmpeg ما را فراخوانی میکند و
185
00:06:01,440 –> 00:06:03,039
186
00:06:03,039 –> 00:06:05,120
در حال عبور
187
00:06:05,120 –> 00:06:06,880
از نام فایلی است که میخواهیم آن را استخراج کنیم.
188
00:06:06,880 –> 00:06:07,680
صدا از
189
00:06:07,680 –> 00:06:09,919
نرخ بیت و همچنین فرکانس و
190
00:06:09,919 –> 00:06:11,680
در آخر ما
191
00:06:11,680 –> 00:06:13,680
مشخص کردهایم که میخواهیم نام فایل چیست،
192
00:06:13,680 –> 00:06:15,520
بنابراین اگر ویدیوی یوتیوب را دانلود نکردهاید
193
00:06:15,520 –> 00:06:17,440
یا میخواهید از ویدیوی خود استفاده کنید،
194
00:06:17,440 –> 00:06:19,600
همه باید انجام دهید. یک
195
00:06:19,600 –> 00:06:21,199
نام فایل متفاوت را در اینجا مشخص کنید
196
00:06:21,199 –> 00:06:22,720
و این فقط باید فایلی باشد که
197
00:06:22,720 –> 00:06:24,639
می خواهید آن را تبدیل کنید،
198
00:06:24,639 –> 00:06:26,479
سپس کاری که ما انجام دادیم این است که رفته ایم و
199
00:06:26,479 –> 00:06:29,120
با استفاده از کتابخانه فرعی خود آن دستور را فراخوانی کرده
200
00:06:29,120 –> 00:06:31,840
ایم و اکنون از پوسته خود استفاده کرده ایم.
201
00:06:31,840 –> 00:06:33,440
اگر به پوشه خود نگاهی بیندازیم
202
00:06:33,440 –> 00:06:34,000
203
00:06:34,000 –> 00:06:37,520
، فایلی به نام audio.wav داریم، بنابراین
204
00:06:37,520 –> 00:06:39,199
این فایل صوتی ماست، بنابراین اگر واقعاً
205
00:06:39,199 –> 00:06:41,039
در مورد تفاوت
206
00:06:41,039 –> 00:06:41,680
بین
207
00:06:41,680 –> 00:06:43,919
ai فکر کرده ایم، می توانید ببینید که ما اکنون
208
00:06:43,919 –> 00:06:46,960
صدا را از آن استخراج کرده ایم. ویدیوی ما
209
00:06:46,960 –> 00:06:48,800
اکنون مرحله بعدی شروع به تنظیم
210
00:06:48,800 –> 00:06:50,639
wa ما است سرویس گفتار tson به متن،
211
00:06:50,639 –> 00:06:52,160
بنابراین در این مورد ما از
212
00:06:52,160 –> 00:06:53,919
یک سرویس رایگان واتسون استفاده خواهیم کرد، بنابراین شما میتوانید
213
00:06:53,919 –> 00:06:55,680
حداکثر 500
214
00:06:55,680 –> 00:06:56,560
دقیقه
215
00:06:56,560 –> 00:06:59,440
گفتار آزاد را به متن در ماه تبدیل کنید، بنابراین اجازه دهید ادامه دهیم
216
00:06:59,440 –> 00:06:59,680
217
00:06:59,680 –> 00:07:01,520
و شروع به تنظیم کنیم. در حال حاضر در
218
00:07:01,520 –> 00:07:02,800
این مورد اولین کاری که باید
219
00:07:02,800 –> 00:07:04,479
انجام دهیم این است که دو متغیر را بگیریم، بنابراین
220
00:07:04,479 –> 00:07:05,360
ما به یک
221
00:07:05,360 –> 00:07:08,479
کلید api و همچنین یک آدرس اینترنتی نیاز
222
00:07:08,479 –> 00:07:11,360
داریم تا یک کلید api دریافت کنیم و یک آدرس اینترنتی
223
00:07:11,360 –> 00:07:13,080
که فقط باید به ابر بروید.
224
00:07:13,080 –> 00:07:16,160
کاتالوگ اسلش رو به جلو .ibm.com سپس
225
00:07:16,160 –> 00:07:17,280
سرویس ها را
226
00:07:17,280 –> 00:07:20,800
در اینجا کلیک کنید و سپس به سمت پایین بروید تا به
227
00:07: