در این مطلب، ویدئو dabl – یک کتابخانه پایتون برای AutoEDA و AutoML با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:12:30
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,240 –> 00:00:02,560
در این ویدیو میخواهم یک
2
00:00:02,560 –> 00:00:05,600
کتابخانه خودکار در پایتون به نام dabble را به شما نشان دهم
3
00:00:05,600 –> 00:00:08,480
که مخفف کتابخانه پایه تجزیه و تحلیل داده
4
00:00:08,480 –> 00:00:10,639
است و بدون هیچ مقدمهای از همین الان شروع میکنیم،
5
00:00:10,639 –> 00:00:13,599
6
00:00:13,679 –> 00:00:16,000
بنابراین کتابخانه dabble به شما امکان میدهد
7
00:00:16,000 –> 00:00:19,199
یک ویرایش سریع و در عین حال انجام دهید.
8
00:00:19,199 –> 00:00:21,439
همچنین به شما این امکان را می دهد که
9
00:00:21,439 –> 00:00:24,080
مدل های یادگیری ماشینی را خیلی سریع بسازید، بنابراین اگر
10
00:00:24,080 –> 00:00:24,960
دوست دارید
11
00:00:24,960 –> 00:00:27,599
و بنابراین اگر دوست دارید پروفایل پانداها را دوست داشته باشید،
12
00:00:27,599 –> 00:00:29,279
فکر می کنم شما هم از دابل خوشتان می آید
13
00:00:29,279 –> 00:00:31,119
زیرا تقریباً به
14
00:00:31,119 –> 00:00:34,239
روشی مشابه کار می کند که به موجب آن
15
00:00:34,239 –> 00:00:37,440
برای ساخت به حداقل کد نیاز دارید. یک
16
00:00:37,440 –> 00:00:39,920
مدل یادگیری ماشین سریع همراه با
17
00:00:39,920 –> 00:00:41,840
تجسم دادهها و بنابراین بیایید نگاهی
18
00:00:41,840 –> 00:00:44,000
به وبسایت dabble بیندازیم و بنابراین در این
19
00:00:44,000 –> 00:00:46,079
مثال خاص میتوانید ببینید که شما
20
00:00:46,079 –> 00:00:48,480
میتوانید فقط وارد کردن dabble import
21
00:00:48,480 –> 00:00:50,879
توابع برای انجام تست صفحه نمایش
22
00:00:50,879 –> 00:00:53,600
بار تقسیم در مجموعه داده و سپس
23
00:00:53,600 –> 00:00:55,920
می توانید متغیرهای x و y را از
24
00:00:55,920 –> 00:00:58,559
مجموعه داده ارقام بارگذاری کنید و سپس
25
00:00:58,559 –> 00:01:00,640
تقسیم داده را انجام دهید و پس از انجام
26
00:01:00,640 –> 00:01:02,879
تقسیم داده ها، یک طبقه بندی ساده ایجاد کنید
27
00:01:02,879 –> 00:01:05,519
و سپس m را متناسب کنید. odel
28
00:01:05,519 –> 00:01:07,439
و سپس آرگومان ورودی
29
00:01:07,439 –> 00:01:10,240
داده های آموزشی x و y خواهد بود و این همه است و
30
00:01:10,240 –> 00:01:12,479
سپس شما فقط می توانید
31
00:01:12,479 –> 00:01:15,920
امتیاز دقت را با استفاده از sc.score ارزیابی کنید
32
00:01:15,920 –> 00:01:18,640
و sc طبقه بندی کننده ساده ای است که
33
00:01:18,640 –> 00:01:20,080
از dabble می آید
34
00:01:20,080 –> 00:01:21,840
و سپس نتیجه به این صورت خواهد بود
35
00:01:21,840 –> 00:01:24,000
و کنار. از توانایی
36
00:01:24,000 –> 00:01:25,759
ساخت خودکار مدلهای یادگیری ماشینی،
37
00:01:25,759 –> 00:01:29,119
میتوانید به سرعت
38
00:01:29,119 –> 00:01:32,159
تجزیه و تحلیل دادههای اکتشافی را انجام دهید، بهطوریکه اگر
39
00:01:32,159 –> 00:01:34,640
فقط از یک خط کد در اینجا
40
00:01:34,640 –> 00:01:37,920
نمودارها و سپس ورودی x و
41
00:01:37,920 –> 00:01:40,400
y استفاده کنید، یک سری نمودار
42
00:01:40,400 –> 00:01:41,759
در اینجا و اینجا نشان داده شده است
43
00:01:41,759 –> 00:01:44,560
. دارای برخی نمودارهای بیشتر و همچنین
44
00:01:44,560 –> 00:01:46,479
برخی از نمودارهای زوجی است و بنابراین اجازه دهید نگاهی
45
00:01:46,479 –> 00:01:48,799
به برخی از نمونهها در اینجا بیاندازیم، بنابراین در
46
00:01:48,799 –> 00:01:50,560
پانل سمت چپ میخواهید روی نمونههای کلی کلیک کنید
47
00:01:50,560 –> 00:01:53,200
و بنابراین برای برخی از نمونههای
48
00:01:53,200 –> 00:01:54,399
نشان داده شده در اینجا
49
00:01:54,399 –> 00:01:57,439
50
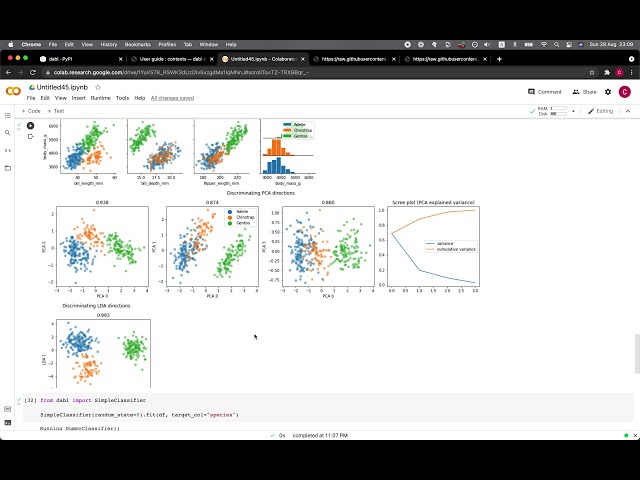
00:01:57,439 –> 00:02:00,079
مجموعه دادههای طبقهبندی شراب وجود دارد و مجموعه دادههای مسکن ames
51
00:02:00,079 –> 00:02:02,960
تصاویری زیبا ارائه میدهد، بنابراین چرا
52
00:02:02,960 –> 00:02:04,560
ما جلو برویم و روی
53
00:02:04,560 –> 00:02:07,040
مجموعه دادههای مسکن اهداف کلیک نکنیم و سپس
54
00:02:07,040 –> 00:02:10,080
آن را در Google collab نیز امتحان نکنیم،
55
00:02:10,080 –> 00:02:12,000
بنابراین این موارد v هستند.
56
00:02:12,000 –> 00:02:14,400
بیایید نگاهی به کدهای مورد نیاز برای تولید آن بیاندازیم،
57
00:02:14,400 –> 00:02:16,080
58
00:02:16,080 –> 00:02:19,120
بنابراین اجازه دهید بلوک
59
00:02:19,120 –> 00:02:21,599
کد را در اینجا کپی کنم، جایی که در واقع آنها یک
60
00:02:21,599 –> 00:02:23,440
نوت بوک مشتری را در اینجا نیز ارائه می دهند، اما
61
00:02:23,440 –> 00:02:24,959
با این وجود، من قبلاً Google
62
00:02:24,959 –> 00:02:28,720
Codelab خود را باز دارم و پس چرا این کار را نکنم. من فقط
63
00:02:28,720 –> 00:02:29,920
در اینجا تایپ میکنم
64
00:02:29,920 –> 00:02:31,120
65
00:02:31,120 –> 00:02:35,680
تجسم مجموعه دادههای مسکن هدفهای dabble،
66
00:02:35,680 –> 00:02:38,560
بنابراین ابتدا اجازه دهید
67
00:02:38,560 –> 00:02:40,560
کتابخانه
68
00:02:40,560 –> 00:02:43,200
dabble را نصب
69
00:02:43,200 –> 00:02:45,360
70
00:02:45,360 –> 00:02:48,239
71
00:02:48,239 –> 00:02:51,440
72
00:02:51,440 –> 00:02:53,280
کنیم. خیلی خب، شما میروید، بنابراین
73
00:02:53,280 –> 00:02:55,760
نمودارها را همانطور که در وبسایتهای قبلی نشان داده شده است تولید میکند،
74
00:02:55,760 –> 00:02:57,920
بنابراین با کمترین
75
00:02:57,920 –> 00:03:00,159
تلاش، اجازه دهید
76
00:03:00,159 –> 00:03:02,720
توضیح خط به خط کد را به شما نشان دهم، بنابراین
77
00:03:02,720 –> 00:03:05,840
در اینجا ما از dabble
78
00:03:05,840 –> 00:03:08,000
تابع plot و سپس از
79
00:03:08,000 –> 00:03:10,800
dabble وارد میکنیم. مجموعه دادهها را در
80
00:03:10,800 –> 00:03:13,599
مجموعه دادههای مسکن اهداف بارگذاری میکنیم و سپس
81
00:03:13,599 –> 00:03:17,360
نمودار نقطه pi matplotlib را به صورت plt وارد
82
00:03:17,360 –> 00:03:19,599
میکنیم و بنابراین
83
00:03:19,599 –> 00:03:23,120
مجموعه دادههای مسکن اهداف را که توسط دادهها ارائه
84
00:03:23,120 –> 00:03:25,519
شده است به متغیر داده اختصاص میدهیم. تابع load ams و سپس
85
00:03:25,519 –> 00:03:28,080
تابع plot به عنوان آرگومان ورودی
86
00:03:28,080 –> 00:03:29,920
در داده ها قرار می دهیم و سپس
87
00:03:29,920 –> 00:03:32,720
متغیر هدف را که قیمت فروش است
88
00:03:32,720 –> 00:03:34,959
و سپس از matplotlib در
89
00:03:34,959 –> 00:03:38,159
plt.show قرار می دهیم و تمام است بنابراین از
90
00:03:38,159 –> 00:03:40,959
خروجی اینجا آن را نشان می دهیم. مشخص می کند که هدف
91
00:03:40,959 –> 00:03:43,440
به نظر یک رگرسیون است و
92
00:03:43,440 –> 00:03:46,799
10 مورد برتر از مجموع
93
00:03:46,799 –> 00:03:49,680
26 ویژگی پیوسته را
94
00:03:49,680 –> 00:03:52,159
نشان می دهد و قیمت فروش در اینجا نشان داده می شود و به صورت هیستوگرام نشان داده می شود
95
00:03:52,159 –> 00:03:54,799
و سپس همه این
96
00:03:54,799 –> 00:03:58,159
نمودارهای پراکندگی را بین ویژگی های پیوسته
97
00:03:58,159 –> 00:04:01,040
در مقابل مشاهده می کنید. هدف که قیمت فروش است، بنابراین
98
00:04:01,040 –> 00:04:03,680
در اینجا می توانید ببینید که برخی از متغیرها
99
00:04:03,680 –> 00:04:06,400
گسسته هستند و در این مورد نیز روند مثبتی را نشان می دهند،
100
00:04:06,400 –> 00:04:08,560
اما
101
00:04:08,560 –> 00:04:10,879
در پایان در اینجا کمی پراکنده هستند، بنابراین
102
00:04:10,879 –> 00:04:12,560
اینها نمودار پراکندگی و سپس
103
00:04:12,560 –> 00:04:14,959
ویژگی طبقه بندی در مقابل هدف
104
00:04:14,959 –> 00:04:16,880
که قیمت فروش است، بنابراین می توانید
105
00:04:16,880 –> 00:04:19,279
تمام نمودارهای مختلف جعبه را برای
106
00:04:19,279 –> 00:04:21,440
ویژگی طبقه بندی در رابطه با
107
00:04:21,440 –> 00:04:24,000
قیمت فروش مشاهده کنید، بنابراین این امکان را برای شما فراهم می کند که
108
00:04:24,000 –> 00:04:26,800
یک ویرایش سریع انجام دهید، بنابراین با استفاده از
109
00:04:26,800 –> 00:04:28,800
این تابع نمودار اگر یک
110
00:04:28,800 –> 00:04:31,199
داده موجود دارید می توانید
111
00:04:31,199 –> 00:04:33,680
از نمودار و سپس داده و سپس
112
00:04:33,680 –> 00:04:37,040
متغیر هدف استفاده کنید، بنابراین اجازه دهید من این را روی
113
00:04:37,040 –> 00:04:39,680
مجموعه داده های خودم امتحان کنم، اجازه دهید
114
00:04:39,680 –> 00:04:42,400
به استاد برگردیم، به مخزن داده
115
00:04:42,400 –> 00:04:46,720
ها برویم و به دلانی برویم.
116
00:04:46,720 –> 00:04:49,440
دادهها را در اینجا تنظیم کنید حلالیت را با
117
00:04:49,440 –> 00:04:52,800
توصیفگرها حل کنید و روی کپی خام کلیک
118
00:04:52,800 –> 00:04:55,600
کنید، پیوند را به عقب برگردانید و ببینیم
119
00:04:55,600 –> 00:04:58,880
دادهها را بارگذاری میکنیم، بنابراین اجازه دهید من
120
00:04:58,880 –> 00:05:02,560
اینجا را مشخص کنم تا دادهها بارگیری شود و بنابراین ما
121
00:05:02,560 –> 00:05:06,560
پانداها را به صورت pdf
122
00:05:06,560 –> 00:05:10,400
df برابر با پی دی csv و سپس
123
00:05:10,400 –> 00:05:11,680
url را بخوانید
124
00:05:11,680 –> 00:05:13,360
و سپس اجازه دهید نگاهی به داده ها بیندازیم
125
00:05:13,360 –> 00:05:15,199
و سپس فقط باید
126
00:05:15,199 –> 00:05:17,520
نام قاب داده
127
00:05:17,520 –> 00:05:20,240
و سپس هدف که بلوک s است را در نمودار تایپ
128
00:05:20,240 –> 00:05:22,080
کنیم و اجازه دهید آن را به درستی اجرا کنیم و
129
00:05:22,080 –> 00:05:24,479
هدف ما این است. بلوک s و این
130
00:05:24,479 –> 00:05:27,120
توزیع است و ویژگی پیوسته را
131
00:05:27,120 –> 00:05:30,320
در مقابل هدف نشان می دهد خوب است، بنابراین هیچ کادری
132
00:05:30,320 –> 00:05:33,840
در اینجا ترسیم نمی شود.
133
00:05:33,840 –> 00:05:36,240
134
00:05:36,240 –> 00:05:38,880
135
00:05:38,880 –> 00:05:40,479
136
00:05:40,479 –> 00:05:42,800
137
00:05:42,800 –> 00:05:45,280
138
00:05:45,280 –> 00:05:48,080
لینک را خام کپی کنید
139
00:05:48,320 –> 00:05:51,600
تا تایپ کنم در اینجا مجموعه داده حلالیت
140
00:05:51,600 –> 00:05:52,639
141
00:05:52,639 –> 00:05:54,000
142
00:05:54,000 –> 00:05:54,960
و سپس
143
00:05:54,960 –> 00:05:57,360
در اینجا ما با مجموعه داده پنگوئن ها می رویم
144
00:05:57,360 –> 00:06:01,680
بنابراین df برابر است با pd
145
00:06:01,680 –> 00:06:02,960
146
00:06:02,960 –> 00:06:04,479
csv آدرس URL
147
00:06:04,479 –> 00:06:06,319
بیایید نگاهی به چارچوب داده بیندازیم و
148
00:06:06,319 –> 00:06:09,680
سپس df را ترسیم کنیم و سپس هدف ما اجازه دهید
149
00:06:09,680 –> 00:06:12,800
گونه ها را مشخص
150
00:06:


![فیلم آموزشی: ابزارهای علم داده - غلطگیر املا و تصحیح خودکار با پایتون[2019] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/rjXeG0aT-7wimage2.jpg)