در این مطلب، ویدئو تجزیه و تحلیل متن زیست پزشکی و بالینی با کتابخانه Stanza Python NLP | اجلاس NLP مراقبت های بهداشتی با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:29:45
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:01,439 –> 00:00:03,840
بسیار خوب سلام به
2
00:00:03,840 –> 00:00:06,399
همه امیدوارم تا اینجا از صحبت لذت برده
3
00:00:06,399 –> 00:00:07,839
باشید نام من یوها جونگ است،
4
00:00:07,839 –> 00:00:09,519
من یک محقق از
5
00:00:09,519 –> 00:00:12,160
دانشگاه استنفورد هستم، بسیار هیجان زده هستم که
6
00:00:12,160 –> 00:00:13,040
7
00:00:13,040 –> 00:00:15,360
در اجلاس Healthcare nlp فرصتی دارم تا در
8
00:00:15,360 –> 00:00:16,320
مورد آخرین بند
9
00:00:16,320 –> 00:00:18,240
ما در مورد پردازش زبان طبیعی پایتون صحبت کنم.
10
00:00:18,240 –> 00:00:19,600
جعبه ابزار
11
00:00:19,600 –> 00:00:21,920
و نحوه تجزیه و تحلیل متن زیست پزشکی و
12
00:00:21,920 –> 00:00:23,119
بالینی
13
00:00:23,119 –> 00:00:26,240
با جعبه ابزار مصراع اکنون قبل از
14
00:00:26,240 –> 00:00:27,039
15
00:00:27,039 –> 00:00:28,720
شروع، می خواهم ابتدا از
16
00:00:28,720 –> 00:00:30,640
همکاران و همکارانم
17
00:00:30,640 –> 00:00:34,000
تشکر کنم، پانچی یو هویژانگ جیسون بااتن
18
00:00:34,000 –> 00:00:36,480
جان بائر، پروفسور کریس منینگ و
19
00:00:36,480 –> 00:00:38,320
پروفسور کورتیس لانگلوتس،
20
00:00:38,320 –> 00:00:40,160
که تلاش های آنها به طور
21
00:00:40,160 –> 00:00:42,000
قابل توجهی به مواد کمک کرده است.
22
00:00:42,000 –> 00:00:45,600
در این سخنرانی
23
00:00:45,600 –> 00:00:47,600
در گفتگوی امروز، امیدوارم
24
00:00:47,600 –> 00:00:49,760
موضوعات زیر را به
25
00:00:49,760 –> 00:00:51,760
تفصیل پوشش دهم، ابتدا یک معرفی سریع
26
00:00:51,760 –> 00:00:53,360
از گروه nlp استانفورد
27
00:00:53,360 –> 00:00:55,520
و مرکز امی استنفورد که
28
00:00:55,520 –> 00:00:57,440
در آن گروه های تحقیقاتی هستند که
29
00:00:57,440 –> 00:00:58,480
به طور مشترک بسته های
30
00:00:58,480 –> 00:01:00,160
مدل زیست پزشکی و بالینی را ایجاد می کنند، ارائه خواهم کرد.
31
00:01:00,160 –> 00:01:02,640
در بند
32
00:01:02,640 –> 00:01:05,360
و سپس میخواهم
33
00:01:05,360 –> 00:01:07,439
با معرفی طراحی
34
00:01:07,439 –> 00:01:08,720
جعبه ابزار بند nlp به بند بپردازم
35
00:01:08,720 –> 00:01:12,240
و معماری عصبی آن
36
00:01:12,240 –> 00:01:14,400
در ادامه در مورد چگونگی گسترش
37
00:01:14,400 –> 00:01:16,320
عملکرد بند اصلی
38
00:01:16,320 –> 00:01:19,200
به حوزه زیست پزشکی و ایجاد
39
00:01:19,200 –> 00:01:20,080
40
00:01:20,080 –> 00:01:23,439
بسته های مدل زیست پزشکی و بالینی صحبت خواهم کرد، همچنین
41
00:01:23,439 –> 00:01:24,080
در مورد
42
00:01:24,080 –> 00:01:26,159
نحوه ارزیابی عملکرد این
43
00:01:26,159 –> 00:01:29,119
بسته های مدل زیست پزشکی و
44
00:01:29,119 –> 00:01:31,119
بالینی صحبت خواهیم کرد. در مورد نحوه استفاده از
45
00:01:31,119 –> 00:01:33,040
بستههای زیستپزشکی و بالینی
46
00:01:33,040 –> 00:01:35,840
با نشان دادن چند مثال ساده،
47
00:01:35,840 –> 00:01:37,520
امیدوارم تا پایان این
48
00:01:37,520 –> 00:01:39,520
سخنرانی یاد بگیرید که بند یک
49
00:01:39,520 –> 00:01:41,759
ابزار دقیق و آسان
50
00:01:41,759 –> 00:01:44,159
برای تجزیه و تحلیل متن زیستپزشکی و بالینی
51
00:01:44,159 –> 00:01:46,479
است،
52
00:01:46,720 –> 00:01:48,159
اجازه دهید ابتدا درباره گروههای تحقیقاتی صحبت کنیم
53
00:01:48,159 –> 00:01:49,759
. پشت بند
54
00:01:49,759 –> 00:01:52,880
و بسته های زیست پزشکی
55
00:01:52,880 –> 00:01:54,720
آن اولین گروه تحقیقاتی که می خواهم
56
00:01:54,720 –> 00:01:56,799
معرفی کنم nlp استاندارد
57
00:01:56,799 –> 00:01:59,439
در گروه nlp استانفورد است همانطور که می
58
00:01:59,439 –> 00:01:59,840
دانید
59
00:01:59,840 –> 00:02:02,399
گروه nlp استانفورد یک آزمایشگاه تحقیقاتی
60
00:02:02,399 –> 00:02:04,799
متمرکز بر تحقیقات فناوری زبان است
61
00:02:04,799 –> 00:02:07,200
و به طور مشترک توسط پنج استاد دانشکده استانفورد رهبری می شود.
62
00:02:07,200 –> 00:02:08,878
اعضای
63
00:02:08,878 –> 00:02:11,760
کریس منینگ پرسی لیانگ دن
64
00:02:11,760 –> 00:02:12,560
یاروفسکی کریس
65
00:02:12,560 –> 00:02:15,840
پاتس و تاتسو هاشیموتو گروه در حال حاضر
66
00:02:15,840 –> 00:02:17,520
ha بیش از 50 دانشجوی
67
00:02:17,520 –> 00:02:20,160
68
00:02:20,160 –> 00:02:21,120
69
00:02:21,120 –> 00:02:24,480
فوق دکترا و کارمند از جمله دانشجویان کارشناسی ارشد و دکترا، تمرکز اصلی این گروه
70
00:02:24,480 –> 00:02:25,120
71
00:02:25,120 –> 00:02:27,280
انجام تحقیقات هیجان انگیز در
72
00:02:27,280 –> 00:02:29,280
زمینه پردازش زبان طبیعی
73
00:02:29,280 –> 00:02:31,920
و ایجاد منابع تحقیقاتی در دسترس عموم
74
00:02:31,920 –> 00:02:32,800
75
00:02:32,800 –> 00:02:34,879
برای تحقیقات و کاربردها در این
76
00:02:34,879 –> 00:02:37,280
زمینه
77
00:02:37,280 –> 00:02:39,680
در طول سالیان استنفورد است. گروه
78
00:02:39,680 –> 00:02:40,560
79
00:02:40,560 –> 00:02:42,720
nlp چندین
80
00:02:42,720 –> 00:02:45,360
ابزار یا بسته نرم افزاری محبوب و پرکاربرد ایجاد کرده است که از
81
00:02:45,360 –> 00:02:48,080
میان آنها شناخته شده ترین آنها
82
00:02:48,080 –> 00:02:50,560
کتابخانه java nlp core stanford
83
00:02:50,560 –> 00:02:52,959
است که یکی از پرکاربردترین ابزارهای nlp
84
00:02:52,959 –> 00:02:53,840
در جهان
85
00:02:53,840 –> 00:02:56,319
است و از زمان انتشار تاکنون برنامه های تحقیقاتی و صنعتی متعددی را
86
00:02:56,319 –> 00:02:57,840
تامین
87
00:02:57,840 –> 00:03:01,680
کرده است. مثال عالی دیگر
88
00:03:01,680 –> 00:03:04,640
بردارهای دستکش است که
89
00:03:04,640 –> 00:03:05,840
90
00:03:05,840 –> 00:03:09,760
پایه و اساس بسیاری از کارهای تحقیقاتی nlp یادگیری عمیق بوده است،
91
00:03:09,760 –> 00:03:11,920
سپس ما بند جدیدترین
92
00:03:11,920 –> 00:03:13,599
جعبه ابزار پایتون nlp را
93
00:03:13,599 –> 00:03:16,959
داریم که تمرکز صحبت امروز من خواهد بود
94
00:03:16,959 –> 00:03:18,959
و بسیاری از مقالات تحقیقاتی و
95
00:03:18,959 –> 00:03:20,319
بسته های نرم
96
00:03:20,319 –> 00:03:23,040
افزاری دیگر
97
00:03:23,680 –> 00:03:25,360
سال دوم گروهی است که
98
00:03:25,360 –> 00:03:27,920
استاندارد زیست پزشکی و بالینی را ساخته است
99
00:03:27,920 –> 00:03:30,480
kages ممکن است مرکز استانفورد
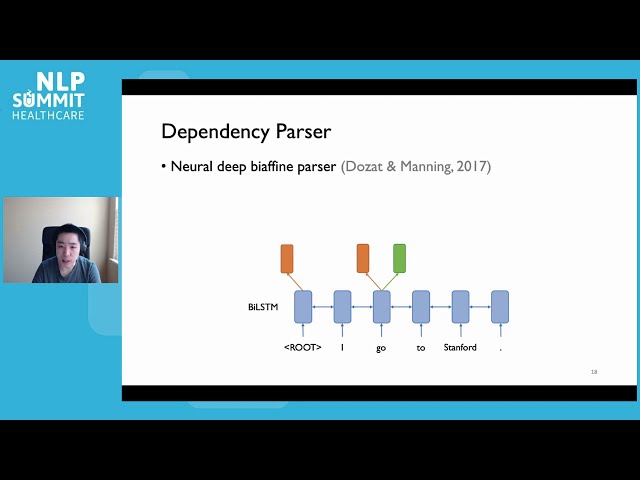
100
00:03:30,480 –> 00:03:32,400
برای هوش مصنوعی در پزشکی
101
00:03:32,400 –> 00:03:33,280
و تصویربرداری
102
00:03:33,280 –> 00:03:36,560
یا به اصطلاح کارکنان مرکز هدف گیری است.
103
00:03:36,560 –> 00:03:37,360
104
00:03:37,360 –> 00:03:39,519
105
00:03:39,519 –> 00:03:41,920
106
00:03:41,920 –> 00:03:42,959
107
00:03:42,959 –> 00:03:45,840
108
00:03:45,840 –> 00:03:46,799
109
00:03:46,799 –> 00:03:48,640
اطلاعات در مورد
110
00:03:48,640 –> 00:03:53,519
مرکز من در amy.stanford.edu مرکز آمی
111
00:03:53,680 –> 00:03:56,080
بر انجام
112
00:03:56,080 –> 00:03:58,319
تحقیقات در تقاطع هوش مصنوعی و
113
00:03:58,319 –> 00:03:59,360
پزشکی تمرکز کرده است
114
00:03:59,360 –> 00:04:01,439
بخش بزرگی از تلاش ها در
115
00:04:01,439 –> 00:04:02,879
مرکز هدف ایجاد
116
00:04:02,879 –> 00:04:05,360
منابع مشترک برای تحقیقات در زمینه هوش مصنوعی و
117
00:04:05,360 –> 00:04:06,239
پزشکی است
118
00:04:06,239 –> 00:04:08,480
که برای آن یک چند نمونه در سمت راست نشان داده شده است
119
00:04:08,480 –> 00:04:10,000
،
120
00:04:10,000 –> 00:04:12,239
این منابع همچنین شامل استانداردهای
121
00:04:12,239 –> 00:04:13,599
بسته های زیست پزشکی است
122
00:04:13,599 –> 00:04:17,120
که امروز در مورد آنها صحبت می کنیم،
123
00:04:17,680 –> 00:04:19,358
امیدوارم قبل از اینکه به پردازش متن زیست پزشکی بپردازیم،
124
00:04:19,358 –> 00:04:21,600
اطلاعات سریعی در مورد گروه nlp استانفورد
125
00:04:21,600 –> 00:04:24,880
و مرکز امی استنفورد به شما بدهد
126
00:04:24,880 –> 00:04:26,400
127
00:04:26,400 –> 00:04:27,759
128
00:04:27,759 –> 00:04:30,240
. امیدواریم ابتدا یک مرور کلی از
129
00:04:30,240 –> 00:04:31,440
جعبه ابزار بند
130
00:04:31,440 –> 00:04:34,479
با تمرکز بر انگیزه آن در
131
00:04:34,479 –> 00:04:35,840
معماری عصبی ارائه شود
132
00:04:35,840 –> 00:04:39,440
d عملکرد چند زبانه
133
00:04:40,400 –> 00:04:43,199
در چند سال گذشته ابزارهای nlp
134
00:04:43,199 –> 00:04:45,120
که قادر به پردازش و حاشیه نویسی
135
00:04:45,120 –> 00:04:45,680
داده
136
00:04:45,680 –> 00:04:48,560
های مالیاتی هستند، برای کاربردهای تحقیقاتی و صنعتی بسیار مفید
137
00:04:48,560 –> 00:04:50,240
138
00:04:50,240 –> 00:04:52,479
بوده و به طور گسترده توسط
139
00:04:52,479 –> 00:04:55,280
کاربران دانشگاهی و صنعتی استفاده شده است
140
00:04:55,280 –> 00:04:58,400
، در نتیجه بسیاری از ابزارهای nlp
141
00:04:58,400 –> 00:05:01,280
موجود برای تولید بسیار بهینه شده اند.
142
00:05:01,280 –> 00:05:03,840
حاشیه نویسی های دقیق برای متن انگلیسی
143
00:05:03,840 –> 00:05:06,479
این مثال در اینجا خروجی
144
00:05:06,479 –> 00:05:08,320
تجزیه کننده وابستگی در جعبه ابزار nlp هسته استنفورد را نشان می دهد،
145
00:05:08,320 –> 00:05:09,039
146
00:05:09,039 –> 00:05:12,639
اما عملکرد این جعبه
147
00:05:12,639 –> 00:05:13,280
148
00:05:13,280 –> 00:05:15,120
ابزار اغلب زمانی که
149
00:05:15,120 –> 00:05:16,479
برای پوشش
150
00:05:16,479 –> 00:05:19,840
سایر زبان های اصلی گسترش می یابند به خطر می افتد و به طرز ناامیدکننده ای
151
00:05:19,840 –> 00:05:22,240
به اندازه زبان های انسانی غنی و متنوع است.
152
00:05:22,240 –> 00:05:23,199
153
00:05:23,199 –> 00:05:25,600
دسترسی به
154
00:05:25,600 –> 00:05:27,039
قابلیتهای پردازشی
155
00:05:27,039 –> 00:05:29,280
این زبانها از طریق یک چارچوب یکپارچه بسیار
156
00:05:29,280 –> 00:05:31,680
157
00:05:31,680 –> 00:05:34,160
دشوار بوده است، بنابراین چرا ایجاد کیت
158
00:05:34,160 –> 00:05:34,880
ابزار nlp
159
00:05:34,880 –> 00:05:37,600
برای زبانها و دامنههای مختلف دشوار است،
160
00:05:37,600 –> 00:05:38,400
اساساً
161
00:05:38,400 –> 00:05:40,240
دو مشکل وجود دارد که با
162
00:05:40,240 –> 00:05:42,400
هم کمک کرده است در ابتدا برای سالها در دسترس بودن
163
00:05:42,400 –> 00:05:45,280
جعبهابزار چندزبانه nlp خوب باشد.
164
00:05:45,280 –> 00:05:48,000
نسخه وجود داشته است
165
00:05:48,000 –> 00:05:49,440
166
00:05:49,440 –> 00:05:51,840
منابع زبانی چند دامنه ای چند زبانه محدود،
167
00:05:51,840 –> 00:05:53,199
به ویژه برای زبان
168
00:05:53,199 –> 00:05:55,680
هایی که کمتر صحبت می شود یا برای حوزه هایی که
169
00:05:55,680 –> 00:05:57,759
حاشیه نویسی آنها دشوارتر است،
170
00:05:57,759 –> 00:06:01,360
مانند حوزه زیست پزشکی، در مرحله دوم،
171
00:06:01,360 –> 00:06:03,600
حتی منابع جدیدی که برای زبان در دسترس هستند،
172
00:06:03,600 –> 00:06:04,800
173
00:06:04,800 –> 00:06:06,720
تطبیق ابزارهای موجود با این
174
00:06:06,720 –> 00:06:08,639
زبان دشوار بوده است،
175
00:06:08,639 –> 00:06:11,039
زیرا ابزارهای موجود. به شدت به
176
00:06:11,039 –> 00:06:13,600
قوانین و الگوهای دست ساز تکیه می کنند،
177
00:06:13,600 –> 00:06:16,080
برای مثال در اینجا فقط
178
00:06:16,080 –> 00:06:17,680
بخش کوچکی از الگوهای
179
00:06:17,680 –> 00:06:19,759
استفاده شده در توکنایزر انگلیسی
180
00:06:19,759 –> 00:06:21,759
سیستم هسته nlp
181
00:06:21,759 –> 00:06:24,400
182
00:06:24,400 –> 00:06:25,440
183
00:06:25,440 –> 00:06:28,000
184
00:06:28,000 –> 00:06:29,120
185
00:06:29,120 –> 00:06:31,199
را نشان می دهد. زبانها و دامنههایی
186
00:06:31,199 –> 00:06:32,240
که قوانین مورد نیاز
187
00:06:32,240 –> 00:06:35,680
188
00:06:35,680 –> 00:06:38,639
برای غلبه بر این محدودیتها میتوانند کاملاً متفاوت باشند، ما
189
00:06:38,639 –> 00:06:40,880
جعبه ابزار nlp stanza python را
190
00:06:40,880 –> 00:06:44,000
بر اساس دو انتخاب طراحی مرکزی
191
00:06:44,000 –> 00:06:46,960
ایجاد کردیم، ابتدا خطوط لوله تجزیه و تحلیل نحوی
192
00:06:46,960 –> 00:06:48,240
danza را
193
00:06:48,240 –> 00:06:51,199
با استفاده از
194
00:06:51,199 –> 00:06:53,280
فرمالیسم و مجموعه دادههای وابستگی جهانی که
195
00:06:53,280 –> 00:06:54,240
196
00:06:54,240 –> 00:06:56,240
خیراً معرفی شدهاند ایجاد کردیم. کیفیت بالا
197
00:06:56,240 –> 00:07:00,160
حاشیه نویسی های زبانی برای بیش از 90 زبان در
198
00:07:00,160 –> 00:07:02,800
مرحله دوم ما بند را طراحی کردیم تا
199
00:07:02,800 –> 00:07:04,479
خط لوله کاملاً عصبی
200
00:07:04,479 –> 00:07:06,080
داشته باشد با عملکردهای مختلف از
201
00:07:06,080 –> 00:07:08,880
توکن سازی تا تجزیه وابستگی
202
00:07:08,880 –> 00:07:10,639
همه ماژول های موجود در خط لوله
203
00:07:10,639 –> 00:07:12,960
قابل آموزش هستند که علاوه بر این دو ویژگی کاملاً عصبی، سازگاری با یک
204
00:07:12,960 –> 00:07:13,759
زبان
205
00:07:13,759 –> 00:07:16,800
جدید یا دامنه جدید را بسیار آسان تر می کند.
206
00:07:16,800 –> 00:07:19,039
207
00:07:19,039 –> 00:07:20,400
طراحی بند
208
00:07:20,400 –> 00:07:22,639
به ما اجازه می دهد تا مدل های از پیش آموزش دیده را
209
00:07:22,639 –> 00:07:23,440
برای
210
00:07:23,440 –> 00:07:26,240
مجموع بیش از 70 زبان انسانی منتشر کنیم که بیش
211
00:07:26,240 –> 00:07:28,160
از 100 مجموعه داده
212
00:07:28,160 –> 00:07:29,840
را پوشش می دهد و همچنین قادر به تعمیم به
213
00:07:29,840 –> 00:07:32,000
حوزه های مختلف مانند حوزه های زیست پزشکی
214
00:07:32,000 –> 00:07:33,280
و بالینی
215
00:07:33,280 –> 00:07:36,240
هستیم که بعداً به تفصیل به آنها خواهیم پرداخت و
216
00:07:36,240 –> 00:07:36,960
در نهایت
217
00:07:36,960 –> 00:07:39,440
حسگر را نیز حس خواهیم کرد. دارای یک رابط کلاینت پایتون
218
00:07:39,440 –> 00:07:40,080
219
00:07:40,080 –> 00:07:42,960
به کتابخانه پرکاربرد nlp java core است
220
00:07:42,960 –> 00:07:44,319
که امکان دسترسی آسان
221
00:07:44,319 –> 00:07:48,879
به nlp هسته با حداقل کد پایتون
222
00:07:49,440 –> 00:07:51,840
را فراهم می کند، بنابراین آنچه که stanza به عنوان یک
223
00:07:51,840 –> 00:07:53,039
جعبه ابزار
224
00:07:53,039 –> 00:07:55,039
nlp در سطح بالایی ارائه
225
00:07:55,039 –> 00:07:56,720
می دهد، می تواند
226
00:07:56,720 –> 00:07:59,759
به شش جزء جداگانه تقسیم شود.
227
00:07:59,759 –> 00:08:01,840
228
00:08:01,840 –> 00:08:02,639
229
00:08:02,639 –> 00:08:05,039
ماژول تقسیم بندی جمله که ورودی را به نشانه ها و
230
00:08:05,039 –> 00:08:06,560
sente تقسیم می کند
231
00:08:06,560 –> 00:08:08,879
یک ماژول بسط نشانه چند کلمه ای است
232
00:08:08,879 –> 00:08:11,039
که کلمات نحوی زیرین را از یک نشانه بازیابی می کند،
233
00:08:11,039 –> 00:08:11,520
234
00:08:11,520 –> 00:08:14,560
بخشی از
235
00:08:14,560 –> 00:08:16,800
ماژول برچسب گذاری گفتار و ویژگی های
236
00:08:16,800 –> 00:08:19,039
صرفی که قوانین نحوی و
237
00:08:19,039 –> 00:08:21,680
ویژگی های یک ماژول allematization کلمه را پیش بینی می کند، یک
238
00:08:21,680 –> 00:08:24,319
ماژول تجزیه وابستگی
239
00:08:24,319 –> 00:08:25,280
240
00:08:25,280 –> 00:08:27,599
و در نهایت یک ماژول تشخیص موجودیت نام
241
00:08:27,599 –> 00:08:29,680
242
00:08:29,680 –> 00:08:31,039
. ابتدا نگاهی به ماژول
243
00:08:31,039 –> 00:08:33,279
توکن سازی و تقسیم بندی جمله بیندازید
244
00:08:33,279 –> 00:08:35,039
245
00:08:35,039 –> 00:08:37,519
من اکثر جعبه ابزارهای nlp موجود را دوست دارم که
246
00:08:37,519 –> 00:08:39,519
از قوانینی برای
247
00:08:39,519 –> 00:08:41,599
مدل های بند توکن سازی و
248
00:08:41,599 –> 00:08:42,640
تقسیم بندی جملات
249
00:08:42,640 –> 00:08:44,959
به طور مشترک به عنوان یک مشکل برچسب گذاری دنباله کاراکتر استفاده می
250
00:08:44,959 –> 00:08:45,839
کنند
251
00:08:45,839 –> 00:08:47,680
که توسط یک شبکه عصبی سبک وزن تحقق می یابد،
252
00:08:47,680 –> 00:08:49,440
253
00:08:49,440 –> 00:08:52,000
این شبکه ابتدا کاراکتر ورودی را رمزگذاری می کند.
254
00:08:52,000 –> 00:08:53,040
دنباله ای
255
00:08:53,040 –> 00:08:55,839
با یک lstm دو جهته و سپس پی
256
00:08:55,839 –> 00:08:56,480
بینی می کند که
257
00:08:56,480 –> 00:08:58,800
یا یک نشانه یا یک جمله با
258
00:08:58,800 –> 00:09:01,360
د در مکان فعلی تقسیم شود یا خی
259
00:09:01,360 –> 00:09:03,760
260
00:09:03,760 –> 00:09:04,640
261
00:09:04,640 –> 00:09:08,080
262
00:09:08,080 –> 00:09:10,160
263
00:09:10,160 –> 00:09:11,279
. گس
264
00:09:11,279 –> 00:09:13,360
توکن و ماژول های محدودسازی که
265
00:09:13,360 –> 00:09:15,279
تا حد زیادی به اشتراک گذاشته می شوند با همان
266
00:09:15,279 –> 00:09:17,600
267
00:09:17,680 –> 00:09:20,080
طراحی معماری، ماژول توکن چند کلمه ای یک
268
00:09:20,080 –> 00:09:20,959
نشانه ردیف
269
00:09:20,959 –> 00:09:23,600
را به چندین کار نحوی گسترش می دهد و
270
00:09:23,600 –> 00:09:25,760
تجزیه و تحلیل وابستگی جهانی را
271
00:09:25,760 –> 00:09:28,959
برای بسیاری از زبان ها در هسته ساده تر می
272
00:09:28,959 –> 00:09:29,839
273
00:09:29,839 –> 00:09:31,519
274
00:09:31,519 –> 00:09:33,920
275
00:09:33,920 –> 00:09:36,240
276
00:09:36,240 –> 00:09:38,480
کند. فرهنگ لغت برای ذخیره کردن تمام
277
00:09:38,480 –> 00:09:40,800
نگاشت های مکرر از یک نشانه به کلمات زیربنایی آن
278
00:09:40,800 –> 00:09:42,399
279
00:09:42,399 –> 00:09:44,560
و هنگامی که فرهنگ لغت از
280
00:09:44,560 –> 00:09:46,000
کار
281
00:09:46,000 –> 00:09:48,399
می افتد، یک مدل رمزگشای رمزگذار عصبی، کلمات نحوی را از نشانه رمزگشایی می کند،
282
00:09:48,399 –> 00:09:50,720
283
00:09:50,720 –> 00:09:53,040
یک معماری مشابه نیز برای محدود کردن استفاده می شود
284
00:09:53,040 –> 00:09:54,000
285
00:09:54,000 –> 00:09:56,160
که در آن دنباله لیما از رمزگشایی رمزگشایی
286
00:09:56,160 –> 00:10:00,000
می شود. نمایش عصبی یک کلمه
287
00:10:00,080 –> 00:10:01,839
اکنون بیایید نگاهی به ماژول تجزیه وابستگی بیندازیم
288
00:10:01,839 –> 00:10:03,920
که
289
00:10:03,920 –> 00:10:05,839
معماری مشابهی با بخش گفتار
290
00:10:05,839 –> 00:10:09,519
و ماژول برچسبگذاری ویژگی مورفولوژیکی
291
00:10:09,519 –> 00:10:11,760
برای تجزیه دارد. ما
292
00:10:11,760 –> 00:10:13,920
معماری عصبی بیوفیلم عمیق
293
00:10:13,920 –> 00:10:16,240
294
00:10:16,240 –> 00:10:18,880
را پیادهسازی میکنیم. lstm
295
00:10:18,880 –> 00:10:21,120
در مرحله بعد یک نمایش سر و یک
296
00:10:21,120 –> 00:10:23,040
نمایش وابسته بهتر است
297
00:10:23,040 –> 00:10:26,399
برای هر کلمه در جمله ورودی
298
00:10:26,399 –> 00:10:28,399
بعدی، نمایشهای سر و
299
00:10:28,399 –> 00:10:30,720
وابسته هر جفت
300
00:10:30,720 –> 00:10:33,279
کلمه با یک لایه توجه بیاتلون مقایسه میشود
301
00:10:33,279 –> 00:10:34,079
302
00:10:34,079 –> 00:10:36,800
که سپس یک نمره اسکالر مشابه ایجاد میکند
303
00:10:36,800 –> 00:10:38,720
که مدلسازی میکند که چقدر احتمال دارد
304
00:10:38,720 –> 00:10:42,399
دو کلمه یک رابطه نحوی تشکیل دهند که
305
00:10:42,399 –> 00:10:45,120
معماری بیوفن مشابه استفاده میشود.
306
00:10:45,120 –> 00:10:46,240
برای بخشی از ماژول
307
00:10:46,240 –> 00:10:47,760
برچسبگذاری گفتار و ویژگیهای مورفولوژیکی، در
308
00:10:47,760 –> 00:10:50,160
309
00:10:50,160 –> 00:10:51,839
آخر، اجازه دهید نگاهی به نام
310
00:10:51,839 –> 00:10:54,560
ماژول ملت ضد جهتدهنده
311
00:10:54,560 –> 00:10:56,800
برای این ماژول بیندازیم، ما
312
00:10:56,800 –> 00:10:59,519
تگر بایت عصبی lsdm crf را
313
00:10:59,519 –> 00:11:01,519
با مدلهای زبان سطح کاراکتر تقویت کردیم،
314
00:11:01,519 –> 00:11:02,640
همانطور که
315
00:11:02,640 –> 00:11:06,560
در چارچوب شعلهور این مدل ابتدا
316
00:11:06,560 –> 00:11:08,880
دو اجرا میشود. مدلهای زبان سطح کاراکتر
317
00:11:08,880 –> 00:11:11,120
بر روی دنباله کاراکتر ورودی
318
00:11:11,120 –> 00:11:14,160
یکی برای هر جهت، خروجیهای مدل زبان
319
00:11:14,160 –> 00:11:14,720
320
00:11:14,720 –> 00:11:16,800
سپس
321
00:11:16,800 –> 00:11:17,760
322
00:11:17,760 –> 00:11:20,240
با بردارهای کلمه به هم
323
00:11:20,240 –> 00:11:21,120
324
00:11:21,120 –> 00:11:24,959
پیوسته میشوند تا با
325
00:11:24,959 –> 00:11:26,560
آموزش مدل زبان سطح کاراکتر
326
00:11:26,560 –> 00:11:29,440
، مقدار زیادی از استانداردهای متنی را که
327
00:11:29,440 –> 00:11:30,480
مدل میتواند به دست آورد، یک مدل استاندارد bios lstm
328
00:11:30,480 –> 00:11:32,480
crf را تقویت کند. عملکرد پیشرفته
329
00:11:32,480 –> 00:11:34,480
با حفظ حافظه کم ردپای
330
00:11:34,480 –> 00:11:37,519
و سرعت معقول
331
00:11:38,240 –> 00:11:40,320
به طوری که اجزای اصلی عصبی
332
00:11:40,320 –> 00:11:42,160
را در بند جمع می
333
00:11:42,160 –> 00:11:44,800
کند، این معماری های شبکه عصبی هستند
334
00:11:44,800 –> 00:11:45,760
که به ما امکان می
335
00:11:45,760 –> 00:11:47,760
دهند مدل های استاندارد را
336
00:11:47,760 –> 00:11:51,360
از زبان ها و دامنه های زیادی در دسترس قرار دهیم که
337
00:11:51,360 –> 00:11:52,639
338
00:11:52,639 –> 00:11:54,560
بسته های چند زبانه استاندارد عمومی چگونه کار می کنند
339
00:11:54,560 –> 00:11:57,200
و با ابزارهای دیگر مقایسه می شوند که سانسا را در مقایسه با آنها مق
340
00:11:57,200 –> 00:11:58,320
یسه می کن
341
00:11:58,320 –> 00:12:00,399
. ابزارهای محبوب در هر دو
342
00:12:00,399 –> 00:12:02,399
مجموعه داده های وابستگی جهانی
343
00:12:02,399 –> 00:12:05,040
و مجموعه داده های مختلف ner که ما
344
00:12:05,040 –> 00:12:06,880
مدل های خود را در
345
00:12:06,880 –> 00:12:09,440
مورد وظایف تجزیه و تحلیل نحوی آموزش می دهیم،
346
00:12:09,440 –> 00:12:10,079
بند
347
00:12:10,079 –> 00:12:12,639
را با ud pipe و spacey را در
348
00:12:12,639 –> 00:12:13,839
امتیاز پیوست برچسب
349
00:12:13,839 –> 00:12:17,200
یا las به عنوان یک معیار استاندارد برای
350
00:12:17,200 –> 00:12:20,320
ارزیابی سیستم های تجزیه وابستگی مقایسه
351
00:12:20,320 –> 00:12:22,240
می کنیم. تنظیمات ارزیابی انتها به انتها
352
00:12:22,240 –> 00:12:23,519
353
00:12:23,519 –> 00:12:25,920
که در آن همه جعبههای ابزار باید قبل از پیشبینی تحلیل نحوی صحیح
354
00:12:25,920 –> 00:12:26,720
جملات، تقسیمبندی کلمه و جمله را
355
00:12:26,720 –> 00:12:28,880
از متن ردیف انجام
356
00:12:28,880 –> 00:12:30,560
357
00:12:30,560 –> 00:12:31,279
358
00:12:31,279 –> 00:12:34,480
دهند، همانطور که در طرح
359
00:12:34,480 –> 00:12:35,120
اینجا مشاهده میشود،
360
00:12:35,120 –> 00:12:38,160
بند
361
00:12:38,160 –> 00:12:41,200
زمانی که در سراسر آن جمعآوری میشود، به نمره لاس بسیار بالایی در حدود 76 درصد میرسد.
362
00:12:41,200 –> 00:12:42,000
363
00:12:42,000 –> 00:12:45,600
100 بانک درخت به بیش از 70 زبان انسانی
364
00:12:45,600 –> 00:12:47,040
365
00:12:47,040 –> 00:12:49,200
و نشانه با
366
00:12:49,200 –> 00:12:51,279
367
00:12:51,279 –> 00:12:51,680
368
00:12:51,680 –> 00:12:54,639
369
00:12:55,680 –> 00:12:57,519
توجه به مدلهای چندزبانه عمومی و
370
00:12:57,519 –> 00:12:59,040
مدلهای er
371
00:12:59,040 –> 00:13:01,760
که ما stanza را با کتابخانه flare مقایسه میکنیم
372
00:13:01,760 –> 00:13:03,279
که
373
00:13:03,279 –> 00:13:06,399
برای کار ner و کتابخانه فضایی
374
00:13:06,399 –> 00:13:08,720
بر روی مجموعه دادههای مختلف ner در هشت
375
00:13:08,720 –> 00:13:10,800
انسان مختلف بسیار بهینهسازی شده است، از ابزارهای موجود برای همه زبانهای اصلی که در این اسلاید نشان داده شدهاند، بهتر عمل میکند. زبانهایی
376
00:13:10,800 –> 00:13:12,800
که ما این سیستمها را بر اساس امتیازات سطح موجودی f1 ارزیابی میکنیم،
377
00:13:12,800 –> 00:13:14,880
378
00:13:14,880 –> 00:13:17,200
همانطور که در اسلاید اینجا نشان داده شده است، نه تنها
379
00:13:17,200 –> 00:13:18,639
استانداردها از زبانهایی پشتیبانی میکنند
380
00:13:18,639 –> 00:13:20,720
که توسط جعبهابزارهای موجود در نظر گرفته نشدهاند،
381
00:13:20,720 –> 00:13:21,760
382
00:13:21,760 –> 00:13:24,079
بلکه عملکرد رقابتی اگر نگوییم
383
00:13:24,079 –> 00:13:25,120
بهتر
384
00:13:25,120 –> 00:13:27,279
در همه زبانها در مقایسه با سیستم بد به دست
385
00:13:27,279 –> 00:13:29,600
386
00:13:30,399 –> 00:13:32,480
میآیند، امیدوارم که این زبانها مقایسه ها به
387
00:13:32,480 –> 00:13:34,399
شما درک سریعی از استانداردها
388
00:13:34,399 –> 00:13:36,000
، قابلیت های پردازش چند زبانه عمومی داده است،
389
00:13:36,000 –> 00:13:37,440
390
00:13:37,440 –> 00:13:39,600
در عین حال مهم است بدانید که
391
00:13:39,600 –> 00:13:41,680
برای تمام نتایجی که ارائه کرده
392
00:13:41,680 –> 00:13:44,320
ایم، مدل های از پیش آموزش دیده را برای دانلود رایگان ارائه کرده ایم
393
00:13:44,320 –> 00:13:45,040
394
00:13:45,040 –> 00:13:47,120
که برای بیش از 100
395
00:13:47,120 –> 00:13:48,240
مجموعه داده که
396
00:13:48,240 –> 00:13:50,720
بیش از 70 زبان انسانی را پوشش می دهد، در دسترس است. و
397
00:13:50,720 –> 00:13:53,279
هنوز در حال رشد هستند
398
00:13:53,279 –> 00:13:55,839
تا جعبه ابزار ما را بهتر کنند در دسترس ما
399
00:13:55,839 –> 00:13:56,720
همچنین یک
400
00:13:56,720 –> 00:13:59,600
نسخه نمایشی آنلاین در stanza.run ساختیم که به
401
00:13:59,600 –> 00:14:01,120
شما امکان می دهد به راحتی
402
00:14:01,120 –> 00:14:04,000
نحوه پردازش متن را به
403
00:14:04,000 –> 00:14:07,279
زبان دلخواه خود تجسم کنید،
404
00:14:08,320 –> 00:14:11,199
به طوری که نمای کلی بند را
405
00:14:11,199 –> 00:14:14,240
به عنوان یک جعبه ابزار nlp با هدف کلی جمع بندی می کند.
406
00:14:14,240 –> 00:14:16,639
بعد می خواهم روی صحبت کردن تمرکز کنم. در مورد
407
00:14:16,639 –> 00:14:19,040
اینکه چگونه طراحی کاملاً عصبی بند
408
00:14:19,040 –> 00:14:21,519
به ما امکان می دهد آن را به حوزه های زیست پزشکی و بالینی گسترش دهیم
409
00:14:21,519 –> 00:14:23,040
410
00:14:23,040 –> 00:14:25,440
و بسته های در دسترس عموم را
411
00:14:25,440 –> 00:14:27,199
در این زمینه ها
412
00:14:27,199 –> 00:14:29,440
413
00:14:29,440 –> 00:14:30,959
414
00:14:30,959 –> 00:14:34,480
415
00:14:35,360 –> 00:14:37,440
ایجاد کنیم.
416
00:14:37,440 –> 00:14:38,720
بستههای مدل
417
00:14:38,720 –> 00:14:40,639
سه هدف اصلی وجود دارد که انعطافپذیری اول
418
00:14:40,639 –> 00:14:43,040
اکتشاف ما را هدایت کرده است،
419
00:14:43,040 –> 00:14:46,560
امیدواریم که
420
00:14:46,560 –> 00:14:49,360
بستههای ما بتوانند
421
00:14:49,360 –> 00:14:50,560
برای ژانرهای
422
00:14:50,560 –> 00:14:52,800
مختلف متون زیست پزشکی و بالینی
423
00:1





![فیلم آموزشی: مسابقات فوتبال اسکرپینگ وب از EPL با پایتون [بخش 1 از 2] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/Nt7WJa2iu0simage2.jpg)