در این مطلب، ویدئو پایتون: همبستگی و P-value در Numpy، Pandas و Scipy با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:11:20
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,799 –> 00:00:03,120
خوب حالا بیایید برخی از این
2
00:00:03,120 –> 00:00:05,920
آمارهای عددی عددی را ایجاد کنیم که
3
00:00:05,920 –> 00:00:07,279
فقط در مورد آن صحبت میکردیم،
4
00:00:07,279 –> 00:00:11,200
من این دو متغیره را num
5
00:00:11,200 –> 00:00:14,639
num مینامیم و این همان چیزی است که
6
00:00:14,639 –> 00:00:17,440
ما همه تحلیلها را همینجا انجام میدهیم، بنابراین
7
00:00:17,440 –> 00:00:18,640
اول از همه
8
00:00:18,640 –> 00:00:20,160
بیایید برخی از موارد اساسی را انجام دهیم. چیزهایی را که
9
00:00:20,160 –> 00:00:23,279
numpy را وارد میکنم
10
00:00:23,279 –> 00:00:26,800
اوه، ما numpy را برای چیزهای ریاضی پایه
11
00:00:26,800 –> 00:00:29,679
بهعنوان np دوست داریم و اجازه دهید فقط چند لیست Uh ایجاد کنیم،
12
00:00:29,679 –> 00:00:30,160
13
00:00:30,160 –> 00:00:32,479
بنابراین بیایید یک ارتفاع
14
00:00:32,479 –> 00:00:34,880
ایجاد کنیم و چند مقدار را در اینجا قرار دهیم 60
15
00:00:34,880 –> 00:00:39,520
62 65 68
16
00:00:39,520 –> 00:00:42,559
70 و 74.
17
00:00:42,559 –> 00:00:46,800
و سپس بیایید چند وزن
18
00:00:49,120 –> 00:00:52,320
بسازیم و اینها را برابر با
19
00:00:52,320 –> 00:00:55,600
140 38
20
00:00:55,600 –> 00:00:59,120
150 166 190
21
00:00:59,120 –> 00:01:02,480
250 قرار می دهیم. بسیار خوب،
22
00:01:02,480 –> 00:01:05,438
بنابراین بیایید با یک همبستگی ساده
23
00:01:05,438 –> 00:01:06,000
بین
24
00:01:06,000 –> 00:01:09,439
قد و وزن سفید شروع
25
00:01:09,439 –> 00:01:13,040
26
00:01:13,040 –> 00:01:15,280
کنیم. به سادگی دو لیست
27
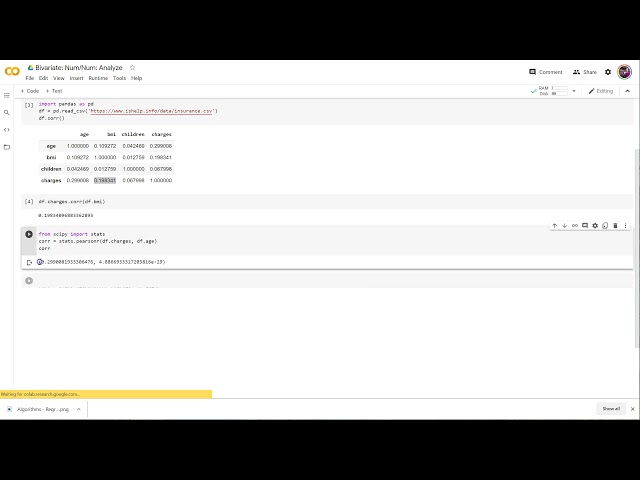
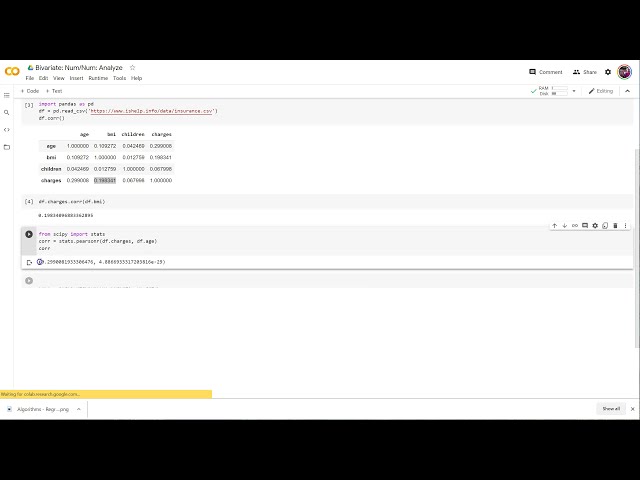
00:01:15,280 –> 00:01:16,320
را در آن قرار دهید،
28
00:01:16,320 –> 00:01:19,520
بنابراین دو ویژگی یا دو متغیر
29
00:01:19,520 –> 00:01:21,759
یا یک ویژگی و یک برچسب است و
30
00:01:21,759 –> 00:01:22,799
باید طول یکسانی داشته
31
00:01:22,799 –> 00:01:25,280
باشند، بنابراین تعداد ارقام یکسان در
32
00:01:25,280 –> 00:01:26,880
هر یک از آنها
33
00:01:26,880 –> 00:01:29,840
بیایید ادامه دهیم و اجرا
34
00:01:31,439 –> 00:01:33,439
کنیم go همیشه یک
35
00:01:33,439 –> 00:01:35,200
ماتریس همبستگی را به ما باز میگرداند، به
36
00:01:35,200 –> 00:01:37,759
این دلیل که ما از دو ویژگی عبور کردیم
37
00:01:37,759 –> 00:01:39,200
این اساساً معادل این است
38
00:01:39,200 –> 00:01:40,240
که بگوییم خوب، ما
39
00:01:40,240 –> 00:01:42,640
قد را در اینجا داریم، وزن را در آنجا قد روی
40
00:01:42,640 –> 00:01:43,840
وزن بالایی در آنجا داریم
41
00:01:43,840 –> 00:01:46,560
و این دو مورد اینجا هستند زیرا
42
00:01:46,560 –> 00:01:47,200
همبستگی
43
00:01:47,200 –> 00:01:49,439
بین قد و خودش یک خواهد بود
44
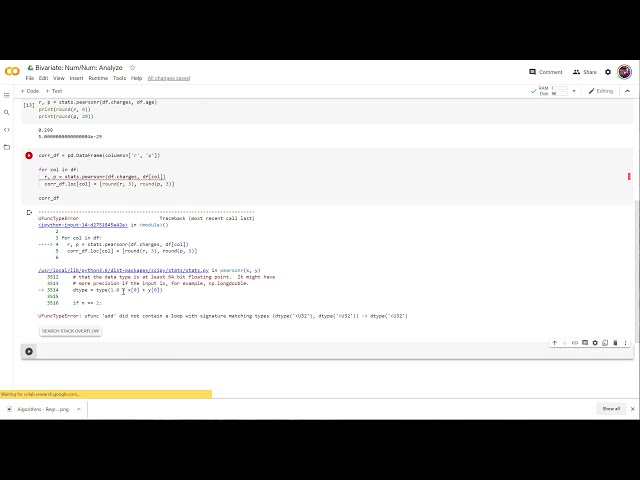
00:01:49,439 –> 00:01:51,680
و یک وزن به خودی خود یک خواهد بود
45
00:01:51,680 –> 00:01:53,040
و همبستگی بین قد و
46
00:01:53,040 –> 00:01:55,439
وزن در واقع 0.92989 است که
47
00:01:55,439 –> 00:01:56,159
عدد بزرگی وجود دارد که
48
00:01:56,159 –> 00:01:58,640
آن را در سمت راست پایین
49
00:01:58,640 –> 00:01:59,600
و سمت راست بالا قرار می دهد در اینجا
50
00:01:59,600 –> 00:02:02,560
همان چیزی است که در هر دو طرف بسیار خوب است
51
00:02:02,560 –> 00:02:03,840
52
00:02:03,840 –> 00:02:06,159
53
00:02:06,159 –> 00:02:08,239
54
00:02:08,239 –> 00:02:11,520
. با گفتن go
55
00:02:11,520 –> 00:02:14,720
ابتدا این شاخص اول می گوید
56
00:02:14,720 –> 00:02:18,959
برو داخل این آرایه دقیقاً در اینجا تنظیم
57
00:02:18,959 –> 00:02:21,120
می کنم تا قسمت آن در موقعیت صفر باشد
58
00:02:21,120 –> 00:02:22,239
59
00:02:22,239 –> 00:02:25,360
و سپس به شماره یک
60
00:02:25,360 –> 00:02:28,319
می رویم تا به ضریب همبستگی واقعی برسیم و
61
00:02:28,319 –> 00:02:30,720
بعد از آن
62
00:02:30,720 –> 00:02:33,440
فقط به دست می آوریم. که اغلب ما از آن عدد
63
00:02:33,440 –> 00:02:34,840
بسیار
64
00:02:34,840 –> 00:02:37,120
ناچیز
65
00:02:37,120 –> 00:02:38,879
استفاده نمی کنیم، اما شاید چیزی
66
00:02:38,879 –> 00:02:41,760
شبیه پانداها باشد، بنابراین بیایید به
67
00:02:41,760 –> 00:02:44,879
جای آن پانداها را وارد کنیم و مزیت
68
00:02:44,879 –> 00:02:46,800
numpai این است که اغلب کمی سریعتر از
69
00:02:46,800 –> 00:02:47,840
پانداها است و
70
00:02:47,840 –> 00:02:50,720
نه همیشه اما ما همیشه از
71
00:02:50,720 –> 00:02:52,640
پانداها برای خیلی چیزهای دیگر استفاده می کنیم، بنابراین
72
00:02:52,640 –> 00:02:53,840
بیایید ادامه دهیم و نحوه استفاده از آن را
73
00:02:53,840 –> 00:02:56,160
در آنجا نیز یاد بگیریم، من می خواهم
74
00:02:56,160 –> 00:02:57,920
بگویم df برابر است و ادامه دهید و
75
00:02:57,920 –> 00:03:01,280
مجموعه داده های خود
76
00:03:01,280 –> 00:03:05,500
را وارد کنید.
77
00:03:05,500 –> 00:03:08,629
[موسیقی]
78
00:03:11,760 –> 00:03:15,680
csv میرویم و
79
00:03:15,680 –> 00:03:19,040
به سادگی df.core را میبینیم
80
00:03:19,040 –> 00:03:21,440
که مجموعه دادههای ما را بررسی میکند و
81
00:03:21,440 –> 00:03:23,120
همه ویژگیهای عددی را میگیرد
82
00:03:23,120 –> 00:03:26,239
و همه آنها را به ماتریس اینجا اضافه میکند
83
00:03:26,239 –> 00:03:28,480
تا ببیند چگونه به طور خودکار
84
00:03:28,480 –> 00:03:29,360
جنسیت
85
00:03:29,360 –> 00:03:32,640
و منطقه و جنسیت یا متاسفم و اوه
86
00:03:32,640 –> 00:03:36,239
سیگاری را نادیده میگیرد. و اوه همان
87
00:03:36,239 –> 00:03:37,040
مورب را به
88
00:03:37,040 –> 00:03:39,200
ما می دهد، بنابراین ما حتی همبستگی
89
00:03:39,200 –> 00:03:41,280
بین سن و سن bmi و bmi
90
00:03:41,280 –> 00:03:43,280
را در نظر نمی گیریم، این فقط به ما مکانی می دهد تا چشم ما
91
00:03:43,280 –> 00:03:45,040
قطر را ببیند، این همان چیزی است
92
00:03:45,040 –> 00:03:47,200
که هر کجا آن ها را می بینیم و سپس به آن می
93
00:03:47,200 –> 00:03:48,159
رسیم.
94
00:03:48,159 –> 00:03:50,480
همبستگی بین سن و bmi که ما
95
00:03:50,480 –> 00:03:51,920
واقعاً فقط به این سه مورد علاقه مندیم در
96
00:03:51,920 –> 00:03:52,879
اینجا
97
00:03:52,879 –> 00:03:54,879
برچسب ما را شارژ می کند و سه
98
00:03:54,879 –> 00:03:56,799
ویژگی دیگر که شما چندان به
99
00:03:56,799 –> 00:03:58,159
این همبستگی های دیگر اهمیت نمی دهید زیرا آنها
100
00:03:58,159 –> 00:04:00,400
بین ویژگی ها هستند اکنون
101
00:04:00,400 –> 00:04:01,680
دلایل دیگری وجود دارد که ممکن است به ما اهمیت بدهند.
102
00:04:01,680 –> 00:04:03,040
که بعداً در تی او کتاب می کند، اما
103
00:04:03,040 –> 00:04:04,799
ما در حال حاضر نگران این موضوع خواهیم بود،
104
00:04:04,799 –> 00:04:07,040
بنابراین اگر ما فقط می
105
00:04:07,040 –> 00:04:09,120
خواهیم ارتباط بین
106
00:04:09,120 –> 00:04:12,480
یک جفت منفرد و پانداهای
107
00:04:12,480 –> 00:04:16,720
df dot را بخواهیم، بیایید شارژهای هسته نقطه ای را
108
00:04:16,720 –> 00:04:18,639
گیریم، بنابراین ابتدا به سری هایی که
109
00:04:18,639 –> 00:04:20,959
رای مثال نقطه df bmi می خواهیم اشاره کر
110
00:04:20,959 –> 00:04:24,160
111
00:04:24,720 –> 00:04:26,160
یم. آنجا که می رویم، همبستگی های فردی را به ما می دهد
112
00:04:26,160 –> 00:04:27,919
همان همبستگی هایی که
113
00:04:27,919 –> 00:04:30,040
در اینجا می بینید که 0.198341 گرد شده است،
114
00:04:30,040 –> 00:04:34,240
بسیار خوب، ما می توانیم انجام
115
00:04:34,240 –> 00:04:36,160
دهیم، می توانیم همبستگی را بدست آوریم، اما چیزی که ما
116
00:04:36,160 –> 00:04:37,360
واقعاً می خواهیم
117
00:04:37,360 –> 00:04:38,639
اغلب با همبستگی، مقدار p
118
00:04:38,639 –> 00:04:40,479
است، بنابراین برای انجام این کار، اجازه دهید به یک
119
00:04:40,479 –> 00:04:42,240
به طور کامل از یک بسته متفاوت استفاده
120
00:04:42,240 –> 00:04:44,639
کنیم که احتمالاً شما
121
00:04:44,639 –> 00:04:45,680
هنوز در این کتاب
122
00:04:45,680 –> 00:04:48,800
استفاده نکرده ایم.
123
00:04:48,800 –> 00:04:52,000
124
00:04:52,000 –> 00:04:53,919
125
00:04:53,919 –> 00:04:55,360
126
00:04:55,360 –> 00:04:56,800
قاب، بنابراین
127
00:04:56,800 –> 00:04:58,479
من آن را دوباره وارد نمیکنم،
128
00:04:58,479 –> 00:05:00,800
بهجای آن، میخواهم بگویم هسته برابر است و
129
00:05:00,800 –> 00:05:02,199
از statspackage استفاده میکنم
130
00:05:02,199 –> 00:05:03,360
131
00:05:03,360 –> 00:05:05,520
.pearsonr نام تابع است و ما
132
00:05:05,520 –> 00:05:06,880
دوباره در
133
00:05:06,880 –> 00:05:10,320
دو لیست بارها را ارسال میکنیم. df dot
134
00:05:10,320 –> 00:05:14,320
age خیلی
135
00:05:14,320 –> 00:05:15,520
خوبه پردازش شده است، باید
136
00:05:15,520 –> 00:05:17,919
آن را در
137
00:05:17,919 –> 00:05:22,000
هسته چاپ کنم، ما همه چیز را درست میکنیم،
138
00:05:22,000 –> 00:05:25,440
یک جفت مقدار یک همبستگی را به ما برمیگرداند و سپس
139
00:05:25,440 –> 00:05:26,720
همراه با آن
140
00:05:26,720 –> 00:05:29,360
یک مقدار p برای آن همبستگی بسیار خوب
141
00:05:29,360 –> 00:05:30,479
جالب است
142
00:05:30,479 –> 00:05:33,120
اجازه دهید هر دو را گرد کنیم تا این کار را انجام
143
00:05:33,120 –> 00:05:36,080
دهیم.
144
00:05:36,080 –> 00:05:37,600
145
00:05:37,600 –> 00:05:39,199
هر زمان که دو یا
146
00:05:39,199 –> 00:05:40,880
بیشتر از یک مقدار دریافت می کنیم که همیشه در قالب یکسان هستند، از
147
00:05:40,880 –> 00:05:42,560
148
00:05:42,560 –> 00:05:44,000
149
00:05:44,000 –> 00:05:47,520
نمادی استفاده می
150
00:05:47,520 –> 00:05:50,560
کنم که ممکن است قبلاً ندیده باشید یا نه. نتیجه برابر با دو