در این مطلب، ویدئو پایتون برای تجزیه و تحلیل داده ها: تست های مجذور کای با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:17:32
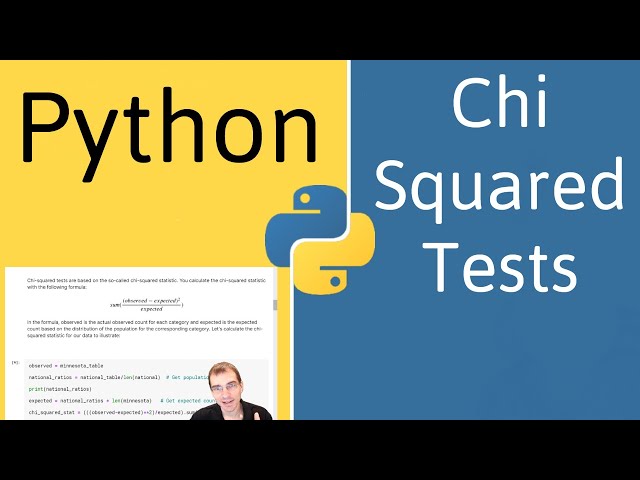
تصاویر این ویدئو:

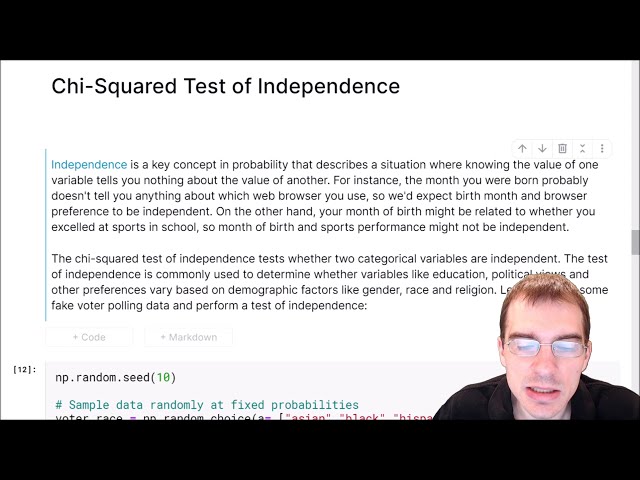
قسمتی از زیرنویس این فیلم:
00:00:02,080 –> 00:00:03,360
سلام به همه
2
00:00:03,360 –> 00:00:05,120
در این درس، ما در
3
00:00:05,120 –> 00:00:08,080
مورد آزمون استنتاج آماری دیگری
4
00:00:08,080 –> 00:00:11,280
به نام آزمون کای اسکوئر و نحوه
5
00:00:11,280 –> 00:00:14,000
انجام تست های مجذور کای با استفاده از پایتون آشنا خواهیم شد،
6
00:00:14,000 –> 00:00:16,400
بنابراین در درس آخر از آزمون t استفاده کردیم
7
00:00:16,400 –> 00:00:18,800
تا بررسی کنیم که آیا میانگین برخی از دادههای نمونه
8
00:00:18,800 –> 00:00:19,520
9
00:00:19,520 –> 00:00:22,160
با میانگین یک
10
00:00:22,160 –> 00:00:23,439
جامعه متفاوت بود،
11
00:00:23,439 –> 00:00:26,160
اکنون آزمون کایدو خوب بودن برازش
12
00:00:26,160 –> 00:00:26,880
13
00:00:26,880 –> 00:00:29,920
مشابه این آزمون t یکطرفه است، اما
14
00:00:29,920 –> 00:00:32,000
به
15
00:00:32,000 –> 00:00:33,600
جای متغیرهای عددی روی متغیرهای طبقهای عمل میکند
16
00:00:33,600 –> 00:00:35,120
و آزمایش میکند که آیا
17
00:00:35,120 –> 00:00:38,320
توزیع برخی از دادههای طبقهبندی
18
00:00:38,320 –> 00:00:41,360
با توزیع مورد انتظار منطبق است، به
19
00:00:41,360 –> 00:00:43,200
عنوان مثال، میتوانیم از این
20
00:00:43,200 –> 00:00:44,399
تست برازش خی دو استفاده کنیم
21
00:00:44,399 –> 00:00:47,039
تا بررسی کنیم که آیا برخی از دستههای جمعیتی
22
00:00:47,039 –> 00:00:48,399
23
00:00:48,399 –> 00:00:51,280
در کلیسا یا مدرسه شما با توزیعهای جمعیتی
24
00:00:51,280 –> 00:00:51,920
شناخته شده
25
00:00:51,920 –> 00:00:55,039
در
26
00:00:55,039 –> 00:00:56,320
کل جمعیت ایالات متحده مطابقت دارند یا خیر که
27
00:00:56,320 –> 00:00:58,399
اکنون در حال کار با دادههای طبقهبندی
28
00:00:58,399 –> 00:00:59,680
مقادیر هستند.
29
00:00:59,680 –> 00:01:01,359
خودشان واقعاً برای
30
00:01:01,359 –> 00:01:03,199
آزمایش های آماری کاربرد زیادی ندارند، زیرا
31
00:01:03,199 –> 00:01:06,080
مقوله هایی مانند زن مرد و سایرین
32
00:01:06,080 –> 00:01:07,840
برای مثال هیچ معنای ریاضی ندارند،
33
00:01:07,840 –> 00:01:08,640
34
00:01:08,640 –> 00:01:10,560
بنابراین وقتی ما انجام مجدد تستهایی که با
35
00:01:10,560 –> 00:01:12,080
دستههایی از این دست سروکار دارند،
36
00:01:12,080 –> 00:01:14,400
آنها بر اساس تعداد
37
00:01:14,400 –> 00:01:15,840
در هر دسته هستند
38
00:01:15,840 –> 00:01:18,479
و این به ما امکان میدهد از اعداد
39
00:01:18,479 –> 00:01:19,520
مرتبط
40
00:01:19,520 –> 00:01:21,680
با دستهها استفاده کنیم، بنابراین برای شروع با یک
41
00:01:21,680 –> 00:01:23,600
مثال، میخواهم برخی از
42
00:01:23,600 –> 00:01:26,320
دادههای دموگرافیک جعلی را برای ایالات متحده تولید کنم. یک
43
00:01:26,320 –> 00:01:26,720
کل
44
00:01:26,720 –> 00:01:28,479
و سپس برای ایالت مینهسوتا و
45
00:01:28,479 –> 00:01:30,079
نحوه انجام
46
00:01:30,079 –> 00:01:32,000
تست تناسب فیت را با chi-square بررسی
47
00:01:32,000 –> 00:01:33,360
میکنیم، بنابراین ما میخواهیم با بارگیری
48
00:01:33,360 –> 00:01:35,840
چند بسته ضروری در اینجا دوباره
49
00:01:35,840 –> 00:01:39,360
پانداهای ناتوان و scipy.stats شروع کنیم. افراد
50
00:01:39,360 –> 00:01:41,920
مشکوک معمول برای این نوع چیزها و حالا
51
00:01:41,920 –> 00:01:43,680
این سلول فقط می خواهد داده هایی
52
00:01:43,680 –> 00:01:45,280
را برای ما تولید کند تا با
53
00:01:45,280 –> 00:01:46,720
آن کار کنیم، دو
54
00:01:46,720 –> 00:01:48,720
جدول مختلف یک جدول ملی
55
00:01:48,720 –> 00:01:51,200
و سپس یک جدول برای مینه سوتا ایجاد می کند، بنابراین ما
56
00:01:51,200 –> 00:01:52,880
این را اجرا می کنیم و نتایج را در اینجا مشاهده می کنیم.
57
00:01:52,880 –> 00:01:54,000
میتوانیم ببینیم که ما دو
58
00:01:54,000 –> 00:01:57,040
جدول متفاوت از برخی متغیرهای طبقهبندی و
59
00:01:57,040 –> 00:01:58,719
تعداد متفاوت برای هر یک داریم، بنابراین
60
00:01:58,719 –> 00:02:00,560
اساساً به ما یک
61
00:02:00,560 –> 00:02:02,320
تفکیک نژادی از
62
00:02:02,320 –> 00:02:05,200
رای دهندگان در ایالات متحده و سپس رای دهندگان در
63
00:02:05,200 –> 00:02:06,240
ایالت مینهسوتا را نشان میدهد
64
00:02:06,240 –> 00:02:07,520
و ما میتوانیم ببینیم. تعداد متفاوتی
65
00:02:07,520 –> 00:02:09,758
برای هر یک از دستهها
66
00:02:09,758 –> 00:02:12,319
و یک چیز برای مینهسوتا وجود دارد، بنابراین
67
00:02:12,319 –> 00:02:14,080
سؤالی که میخواهیم در اینجا با
68
00:02:14,080 –> 00:02:15,760
آزمون مجذور کای بپرسیم این است
69
00:02:15,760 –> 00:02:18,959
که آیا این توزیع تعداد در
70
00:02:18,959 –> 00:02:22,000
این دستههای مختلف برای
71
00:02:22,000 –> 00:02:24,640
مینهسوتا یکسان است و برای جمعیت به عنوان
72
00:02:24,640 –> 00:02:25,440
یک به طور کامل
73
00:02:25,440 –> 00:02:28,239
و ما میتوانیم نحوه
74
00:02:28,239 –> 00:02:30,000
تولید دادهها را بررسی کنیم تا در واقع مطمئن شویم
75
00:02:30,000 –> 00:02:30,560
که آیا
76
00:02:30,560 –> 00:02:32,239
آنها باید یکسان باشند یا نه، اما بیایید
77
00:02:32,239 –> 00:02:34,080
فقط از آزمون مجذور کای استفاده کنیم
78
00:02:34,080 –> 00:02:34,480
79
00:02:34,480 –> 00:02:37,040
تا بررسی کنیم که آیا این توزیعها
80
00:02:37,040 –> 00:02:38,720
در این دستهها
81
00:02:38,720 –> 00:02:40,959
میتوانند یکسان در نظر گرفته شوند یا خیر. نه پس
82
00:02:40,959 –> 00:02:42,160
آزمون کای اسکوئر
83
00:02:42,160 –> 00:02:44,560
بر اساس آمار کای اسکوئر است
84
00:02:44,560 –> 00:02:46,000
85
00:02:46,000 –> 00:02:48,239
و شما می توانید این آمار را
86
00:02:48,239 –> 00:02:50,000
با استفاده از فرمول زیر محاسبه
87
00:02:50,000 –> 00:02:52,239
کنید.
88
00:02:52,239 –> 00:02:54,080
89
00:02:54,080 –> 00:02:57,519
90
00:02:57,519 –> 00:02:58,560
91
00:02:58,560 –> 00:03:01,599
شمارش در این
92
00:03:01,599 –> 00:03:02,239
فرمول
93
00:03:02,239 –> 00:03:05,040
این تعداد مشاهده شده در اینجا تعداد واقعی
94
00:03:05,040 –> 00:03:06,879
مشاهده شده است که ما در نمونه خود دیدیم،
95
00:03:06,879 –> 00:03:09,040
بنابراین این تعداد در اینجا است
96
00:03:09,040 –> 00:03:11,680
که برای Minnesota a مشاهده کردیم. و سپس
97
00:03:11,680 –> 00:03:13,200
شمارشهای مورد انتظار
98
00:03:13,200 –> 00:03:15,840
، حسابهایی هستند که باید انتظار داشته باشیم اگر
99
00:03:15,840 –> 00:03:16,800
این
100
00:03:16,800 –> 00:03:18,800
توزیع شمارشها در بین
101
00:03:18,800 –> 00:03:20,720
دستهها
102
00:03:20,720 –> 00:03:23,599
با توزیع شمارشها در میان
103
00:03:23,599 –> 00:03:25,599
جمعیتی که ما آن را با آن مقایسه میکنیم یکسان بود،
104
00:03:25,599 –> 00:03:26,879
بنابراین این چیزی است که
105
00:03:26,879 –> 00:03:28,560
باید محاسبه کنیم تا بفهمیم چه چیزی چیست.
106
00:03:28,560 –> 00:03:30,319
نسبت
107
00:03:30,319 –> 00:03:32,560
شمارشها در هر یک از این دستهها هستند و وقتی
108
00:03:32,560 –> 00:03:34,640
متوجه شدیم میتوانیم محاسبه
109
00:03:34,640 –> 00:03:36,239
کنیم که
110
00:03:36,239 –> 00:03:38,959
با توجه به تعداد کل
111
00:03:38,959 –> 00:03:41,360
مشاهدات ما برای مینهسوتا چقدر انتظار داریم که همه شمارشها برای مینسوتا باشد، بنابراین
112
00:03:41,360 –> 00:03:43,120
در واقع با انجام این کار شروع میکنیم.
113
00:03:43,120 –> 00:03:43,840
این
114
00:03:43,840 –> 00:03:46,239
تست مجذور کای به صورت دستی با محاسبه
115
00:03:46,239 –> 00:03:47,200
آن به این صورت است،
116
00:03:47,200 –> 00:03:48,640
اما سپس ما نشان خواهیم داد که چگونه می توان آن را در
117
00:03:48,640 –> 00:03:51,760
پایتون سریعتر با فراخوانی تابع scipy.stats
118
00:03:51,760 –> 00:03:52,799
انجام داد،
119
00:03:52,799 –> 00:03:54,799
بنابراین من فقط با نشان دادن نحوه انجام
120
00:03:54,799 –> 00:03:55,840
آن به روش دستی شروع می کنم،
121
00:03:55,840 –> 00:03:58,799
بنابراین ابتدا ما مشاهدات را برای
122
00:03:58,799 –> 00:04:00,400
مینه سوتا می خواهید که
123
00:04:00,400 –> 00:04:02,080
دقیقاً مشابه جدول مینسوتای ما است، بنابراین
124
00:04:02,080 –> 00:04:04,159
ما آن را در مشاهده ذخیره می
125
00:04:04,159 –> 00:04:06,400
کنیم و سپس باید تعداد مورد انتظار را محاسبه
126
00:04:06,400 –> 00:04:08,879
کنیم و همانطور که گفتم این بر اساس
127
00:04:08,879 –> 00:04:09,439
128
00:04:09,439 –> 00:04:12,640
نسبت است. سیستم های شمارش در سراسر دسته ها
129
00:04:12,640 –> 00:04:14,959
برای جمعیت، بنابراین این کاری است که ما در
130
00:04:14,959 –> 00:04:16,079
اینجا انجام می دهیم، جدول ملی را می گیریم
131
00:04:16,079 –> 00:04:16,560
132
00:04:16,560 –> 00:04:18,798
، آن را بر طول جدول ملی تقسیم
133
00:04:18,798 –> 00:04:20,000
134
00:04:20,000 –> 00:04:22,560
می کنیم، این نسبت ها را برای هر یک
135
00:04:22,560 –> 00:04:23,759
از دسته ها دریافت می کند
136
00:04:23,759 –> 00:04:25,840
و سپس برای محاسبه مقدار مورد انتظار،
137
00:04:25,840 –> 00:04:28,320
فقط باید آن نسبت ها را در نظر بگیریم
138
00:04:28,320 –> 00:04:31,280
و آنها را در تعداد
139
00:04:31,280 –> 00:04:33,120
مشاهدات خود برای مینه سوتا ضرب کنیم،
140
00:04:33,120 –> 00:04:36,080
بنابراین
141
00:04:36,080 –> 00:04:37,120
اکنون که
142
00:04:37,120 –> 00:04:39,600
تعداد مشاهده شده و تعداد مورد انتظار خود را داریم،
143
00:04:39,600 –> 00:04:40,560
فقط باید
144
00:04:40,560 –> 00:04:43,199
مجذور کای خود را محاسبه کنیم. آمار
145
00:04:43,199 –> 00:04:44,240
با استفاده از این فرمول،
146
00:04:44,240 –> 00:04:47,120
بنابراین ما منهای مشاهده شده را
147
00:04:47,120 –> 00:04:48,080
مجذور
148
00:04:48,080 –> 00:04:50,479
میگیریم، این همان کاری است که در صورتدهنده انجام دادیم و
149
00:04:50,479 –> 00:04:51,680
سپس تقسیم بر
150
00:04:51,680 –> 00:04:54,080
انتظار میشود تا مخرج
151
00:04:54,080 –> 00:04:55,120
آن باشد و سپس کل این چیز
152
00:04:55,120 –> 00:04:56,880
فقط باید جمع شود، بنابراین از
153
00:04:56,880 –> 00:04:59,360
مجموع نقطهای numpy استفاده میکنیم. تابع وجود دارد
154
00:04:59,360 –> 00:05:01,680
و یک آمار مجذور خی را
155
00:05:01,680 –> 00:05:02,400
156
00:05:02,400 –> 00:05:04,720
برای این وضعیتی که با
157
00:05:04,720 –> 00:05:05,600
این مجموعه داده ها ایجاد کردیم محاسبه می کند
158
00:05:05,600 –> 00:05:06,960
و ما فقط آن را از این
159
00:05:06,960 –> 00:05:08,800
کد چاپ می کنیم و می بینیم که این بیت اول فقط
160
00:05:08,800 –> 00:05:10,400
شما را نشان می دهد.
161
00:05:10,400 –> 00:05:13,199
نسبت جمعیت این عدد نهایی
162
00:05:13,199 –> 00:05:14,880
در اینجا آمار آزمون کای دو ما است،
163
00:05:14,880 –> 00:05:18,240
بنابراین 18.19
164
00:05:18,240 –> 00:05:20,639
اکنون مشابه آزمون t است که
165
00:05:20,639 –> 00:05:21,360
در
166
00:05:21,360 –> 00:05:25,680
آن آمار آزمون t را با یک مقدار بحرانی
167
00:05:25,680 –> 00:05:28,560
بر اساس توزیع t مقایسه کردیم تا مشخص کنیم
168
00:05:28,560 –> 00:05:29,039
169
00:05:29,039 –> 00:05:31,440
آیا نتیجه واقعاً از نظر آماری بوده است یا خیر.
170
00:05:31,440 –> 00:05:32,720
معنی دار یا نه،
171
00:05:32,720 –> 00:05:34,560
ما اساساً همین کار را در اینجا با
172
00:05:34,560 –> 00:05:36,000
آزمون کای دو انجام می دهیم، می خواهیم
173
00:05:36,000 –> 00:05:37,280
این
174
00:05:37,280 –> 00:05:40,560
آمار آزمون کای دو را بگیریم و سپس آن را با
175
00:05:40,560 –> 00:05:43,759
یک مقدار بحرانی مقایسه کنیم که به جای
176
00:05:43,759 –> 00:05:44,880
توزیع t،
177
00:05:44,880 –> 00:05:47,520
توزیع کای دو است، بنابراین بیایید
178
00:05:47,520 –> 00:05:48,400
از پایتون استفاده کنیم.
179
00:05:48,400 –> 00:05:52,000
و کتابخانه scipy stats برای محاسبه
180
00:05:52,000 –> 00:05:54,800
مقدار بحرانی ما
181
00:05:54,800 –> 00:05:56,400
که میخواهیم آن را با آن مقایسه کنیم
182
00:05:56,400 –> 00:05:58,720
و سپس از آن برای محاسبه
183
00:05:58,720 –> 00:06:00,000
مقدار p
184
00:06:00,000 –> 00:06:02,400
برای این آزمایش استفاده کنیم و میتوانیم از آن برای دیدن
185
00:06:02,400 –> 00:06:04,720
اینکه آیا این دو توزیع واقعاً
186
00:06:04,720 –> 00:06:05,520
متفاوت هستند استفاده کنیم.
187
00:06:05,520 –> 00:06:07,520
در سطوح مختلف
188
00:06:07,520 –> 00:06:08,800
دسته، بنابراین
189
00:06:08,800 –> 00:06:10,880
ما با محاسبه مقدار بحرانی شروع
190
00:06:10,880 –> 00:06:12,720
می کنیم و از
191
00:06:12,720 –> 00:06:16,880
سطح معنی داری 5 یا سطح اطمینان 95 درصد
192
00:06:16,880 –> 00:06:17,759
193
00:06:17,759 –> 00:06:20,240
برای محاسبه استفاده می کنیم. با خوردن آن
194
00:06:20,240 –> 00:06:22,080
مقدار بحرانی، میتوانیم از
195
00:06:22,080 –> 00:06:25,600
آمار نقطه chi 2 استفاده کنیم که به این معنی است که آرگومان chi مربع
196
00:06:25,600 –> 00:06:28,960
نقطه ppf اولین آرگومان این q
197
00:06:28,960 –> 00:06:30,639
برای کمیت 0.95 خواهد بود
198
00:06:30,639 –> 00:06:33,440
زیرا و باید توجه داشت که
199
00:06:33,440 –> 00:06:34,080
200
00:06:34,080 –> 00:06:37,600
توزیع کای دو یک طرفه است
201
00:06:37,600 –> 00:06:38,720
که از صفر شروع میشود.
202
00:06:38,720 –> 00:06:40,560
ما چیزی نداریم که در
203
00:06:40,560 –> 00:06:42,560
آن چندین دنباله داشته باشیم، ما
204
00:06:42,560 –> 00:06:44,880
فقط به دنبال انتهای بالایی برای این
205
00:06:44,880 –> 00:06:48,000
کار علاقه داریم، بنابراین به همین دلیل است که در اینجا به جای 0.975 از 0.95 استفاده می کنیم
206
00:06:48,000 –> 00:06:51,120
و وضعیت دو دنباله داریم
207
00:06:51,120 –> 00:06:52,319
208
00:06:52,319 –> 00:06:54,160
و سپس آرگومان بعدی عبارتند از
209
00:06:54,160 –> 00:06:55,360
درجات آزادی
210
00:06:55,360 –> 00:06:58,319
و برای آزمون مجذور کای این
211
00:06:58,319 –> 00:07:00,240
تعداد دستههایی است
212
00:07:00,240 –> 00:07:03,120
که ما با آنها سر و کار داریم منهای یک، بنابراین ما در
213
00:07:03,120 –> 00:07:06,240
اینجا پنج دسته داشتیم، بنابراین
214
00:07:06,240 –> 00:07:08,000
درجه آزادی ما df چهار خواهد بود
215
00:07:08,000 –> 00:07:10,479
و وقتی این را اجرا کنیم این خواهد شد.
216
00:07:10,479 –> 00:07:12,240
مقدار بحرانی مورد علاقه
217
00:07:12,240 –> 00:07:13,759
ما را به ما بدهید که
218
00:07:13,759 –> 00:07:17,440
میخواهیم آمار مجذور کای 18.1 خود را با آن مقایسه کنیم،
219
00:07:17,440 –> 00:07:19,840
بنابراین آن را چاپ میکنیم و سپس
220
00:07:19,840 –> 00:07:21,599
از آن مقدار p مقدار p را محاسبه میکنیم.
221
00:07:21,599 –> 00:07:22,400
222
00:07:22,400 –> 00:07:26,080
مقدار 1 منهای
223
00:07:26,080 –> 00:07:30,240
آمار نقطه chi 2.cdf خواهد بود بنابراین ما دریافت می کنیم با استفاده از
224
00:07:30,240 –> 00:07:32,639
تابع توزیع تجمعی، بنابراین
225
00:07:32,639 –> 00:07:34,560
ما اساساً می گوییم تمام مساحت
226
00:07:34,560 –> 00:07:37,919
زیر توزیع
227
00:07:37,919 –> 00:07:40,400
تا آمار آزمون کای دو با
228
00:07:40,400 –> 00:07:41,440
درجات آزادی
229
00:07:41,440 –> 00:07:43,520
برابر با 4 است. بنابراین اساساً می گوییم هر
230
00:07:43,520 –> 00:07:44,879
چه نتیجه ما شدیدتر
231
00:07:44,879 –> 00:07:48,160
باشد، این مقدار بزرگتر و یک خواهد بود.
232
00:07:48,160 –> 00:07:50,080
منهای آن مقدار کوچکتر میشود،
233
00:07:50,080 –> 00:07:52,160
بنابراین اساساً هر چه
234
00:07:52,160 –> 00:07:53,199
نتیجه شدیدتر باشد،
235
00:07:53,199 –> 00:07:56,000
مقدار p کوچکتری به دست میآوریم و
236
00:07:56,000 –> 00:07:56,960
وقتی این را اجرا
237
00:07:56,960 –> 00:08:00,319
میکنیم، میتوانیم ببینیم که مقدار chi-squad بحرانی
238
00:08:00,319 –> 00:08:04,720
9.48 است و همان مقداری است که ما پیدا کردیم 18
239
00:08:04,720 –> 00:08:06,319
که بسیار است. بزرگتر از آن،
240
00:08:06,319 –> 00:08:09,360
بنابراین در سطح 5 قابل توجه خواهد بود
241
00:08:09,360 –> 00:08:12,840
و مقدار
242
00:08:12,840 –> 00:08:15,520
p 0.001 است، بنابراین این یک مقدار p بسیار کوچک
243
00:08:15,520 –> 00:08:17,599
است، حتی در سطح 1 قابل توجه است،
244
00:08:17,599 –> 00:08:20,000
بنابراین می توان کاملاً مطمئن بود که
245
00:08:20,000 –> 00:08:21,680
246
00:08:21,680 –> 00:08:24,560
توزیع تعداد در آن دسته ها
247
00:08:24,560 –> 00:08:26,720
واقعاً است. برای نمونه مینه سوتا متفاوت
248
00:08:26,720 –> 00:08:29,759
از جامعه بود،
249
00:08:29,759 –> 00:08:32,080
بنابراین در این مورد از آنجایی که آمار کای دو ما
250
00:08:32,080 –> 00:08:34,080
از مقدار بحرانی فراتر می رود و
251
00:08:34,080 –> 00:08:35,599
مقدار p پایین است
252
00:08:35,599 –> 00:08:38,080
، فرضیه صفر را رد می کنیم که این
253
00:08:38,080 –> 00:08:40,159
دو بخش butions یکسان هستند
254
00:08:40,159 –> 00:08:42,159
و فرضیه جایگزین را می پذیرند
255
00:08:42,159 –> 00:08:44,480
که آنها در واقع متفاوت هستند،
256
00:08:44,480 –> 00:08:46,240
اکنون ما با مشکل
257
00:08:46,240 –> 00:08:48,240
محاسبه آمار مجذور کای
258
00:08:48,240 –> 00:08:49,839
و مقدار p با دست روبرو شدیم،
259
00:08:49,839 –> 00:08:52,399
اما البته در پایتون می توانید در
260
00:08:52,399 –> 00:08:53,279
بسته
261
00:08:53,279 –> 00:08:54,880
هایی بارگیری کنید که عملکردهایی را اجرا کنند که می توانند انجام دهند.
262
00:08:54,880 –> 00:08:56,480
بسیاری از این چیزها
263
00:08:56,480 –> 00:08:58,080
تقریباً به طور خود