در این مطلب، ویدئو کتابخانه Missingno Python | تجسم مقادیر گمشده در داده ها قبل از یادگیری ماشینی با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:09:35
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,080 –> 00:00:01,920
سلام به همه و خوش آمدید
2
00:00:01,920 –> 00:00:03,919
اگر تازه وارد هستید من اندی هستم و در
3
00:00:03,919 –> 00:00:05,440
ویدیوی امروز به موضوع بسیار
4
00:00:05,440 –> 00:00:07,359
مهمی در هنگام کار با داده ها می پردازیم
5
00:00:07,359 –> 00:00:09,840
و آن عدم وجود داده از دست رفته
6
00:00:09,840 –> 00:00:11,599
احتمالاً یکی از رایج ترین
7
00:00:11,599 –> 00:00:13,599
موارد است. هنگام کار با
8
00:00:13,599 –> 00:00:15,599
مجموعه دادههای دنیای واقعی با مشکلاتی مواجه میشوید و اینکه دادهها ممکن
9
00:00:15,599 –> 00:00:17,279
است به دلایل متعددی از دست رفته باشند، از
10
00:00:17,279 –> 00:00:20,240
جمله خطای انسانی حسگر و
11
00:00:20,240 –> 00:00:22,160
مدیریت ضعیف داده، دادههای از دست رفته
12
00:00:22,160 –> 00:00:24,480
میتواند از یک نقطه واحد تا یک
13
00:00:24,480 –> 00:00:26,880
ستون یا ویژگی کامل وجود نداشته باشد و بسیاری از
14
00:00:26,880 –> 00:00:28,800
یادگیری ماشینی وجود داشته باشد. الگوریتمهایی که امروزه استفاده میکنیم
15
00:00:28,800 –> 00:00:31,439
نیاز دارند که دادهها تا حد امکان کامل باشند
16
00:00:31,439 –> 00:00:33,280
هنگام انجام
17
00:00:33,280 –> 00:00:35,040
فرآیند آموزشی،
18
00:00:35,040 –> 00:00:37,760
بنابراین شناسایی و درک
19
00:00:37,760 –> 00:00:39,680
میزان آن دادههای از دست رفته در یک
20
00:00:39,680 –> 00:00:42,079
مجموعه داده ضروری است،
21
00:00:42,079 –> 00:00:43,600
البته در برخی از مدلهای یادگیری ماشین استثناهایی نیز وجود دارد.
22
00:00:43,600 –> 00:00:45,840
مانند جنگل تصادفی می تواند
23
00:00:45,840 –> 00:00:47,440
داده های از دست رفته را به عنوان بخشی از
24
00:00:47,440 –> 00:00:49,280
الگوریتم مدیریت کند. ویدیوی امروز قرار است
25
00:00:49,280 –> 00:00:51,760
بر روی یک کتابخانه بسیار ساده اما بسیار
26
00:00:51,760 –> 00:00:54,399
قدرتمند به نام mi تمرکز کند. ssingno و ما
27
00:00:54,399 –> 00:00:56,960
میتوانیم از missingno برای ارزیابی میزان
28
00:00:56,960 –> 00:01:00,079
فقدان در یک مجموعه داده و
29
00:01:00,079 –> 00:01:01,920
چگونگی ارتباط هر یک از این مقادیر گمشده
30
00:01:01,920 –> 00:01:03,760
با یکدیگر استفاده کنیم و این کار را
31
00:01:03,760 –> 00:01:06,159
از طریق مشاهده چهار نمودار کلیدی انجام خواهیم داد.
32
00:01:06,159 –> 00:01:08,400
33
00:01:08,400 –> 00:01:10,799
نقشه
34
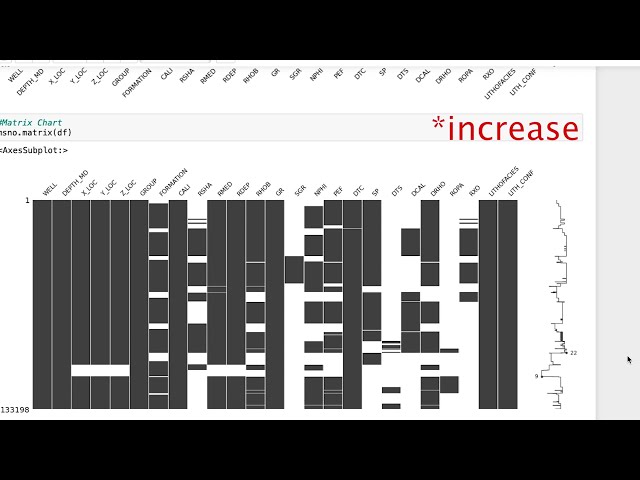
00:01:10,799 –> 00:01:12,560
ما اکنون به نوت بوک jupyter خود می رویم و می بینیم
35
00:01:12,560 –> 00:01:14,720
که چگونه می توانیم اینها را در اینجا در
36
00:01:14,720 –> 00:01:16,880
دفترچه یادداشت jupiter خود ایجاد کنیم، اگر
37
00:01:16,880 –> 00:01:19,360
کتابخانه missingno را نصب نکرده اید، می توانید
38
00:01:19,360 –> 00:01:21,119
آن را بدون ترک دفترچه یادداشت jupiter نصب کنید
39
00:01:21,119 –> 00:01:23,360
و این را می توان با تایپ کردن
40
00:01:23,360 –> 00:01:25,920
علامت تعجب انجام داد. علامت گذاری به دنبال نصب pip
41
00:01:25,920 –> 00:01:28,240
missing jupiter سپس کتابخانه را نصب می کند،
42
00:01:28,240 –> 00:01:30,159
اما اگر قبلاً آن را
43
00:01:30,159 –> 00:01:32,079
نصب کرده باشید، پیامی مشابه این پیام خواهید دید،
44
00:01:32,079 –> 00:01:33,759
بنابراین اولین قدم در
45
00:01:33,759 –> 00:01:35,759
فرآیند ما این است که کتابخانه هایی
46
00:01:35,759 –> 00:01:37,920
را که قرار است استفاده کنیم و برای این کار وارد کنیم. آموزش
47
00:01:37,920 –> 00:01:39,360
ما قرار است با پانداها
48
00:01:39,360 –> 00:01:42,000
برای بارگیری و ذخیره داده های خود کار کنیم و
49
00:01:42,000 –> 00:01:44,320
کتابخانه missingno برای تجسم کامل بودن داده ها
50
00:01:44,320 –> 00:01:46,240
51
00:01:46,240 –> 00:01:47,759
و مجموعه داده ای که می خواهیم
52
00:01:47,759 –> 00:01:50,240
استفاده کنیم یک su است.
53
00:01:50,240 –> 00:01:52,079
مجموعه ای از مجموعه داده های در دسترس عموم از
54
00:01:52,079 –> 00:01:53,920
مسابقه یادگیری ماشینی که توسط
55
00:01:53,920 –> 00:01:57,040
zeke و force 2020 اجرا شد و هدف
56
00:01:57,040 –> 00:01:58,560
این مسابقه پیش بینی
57
00:01:58,560 –> 00:02:01,520
سنگ شناسی از داده های برچسب موجود بود و
58
00:02:01,520 –> 00:02:03,520
مجموعه داده های اصلی شامل
59
00:02:03,520 –> 00:02:06,399
حدود 118 چاه از دریای شمال نروژ است.
60
00:02:06,399 –> 00:02:08,639
ما با زیرمجموعه
61
00:02:08,639 –> 00:02:11,200
ای از چندین چاه کار می کنیم قبل از اینکه
62
00:02:11,200 –> 00:02:13,200
به سمت استفاده از کتابخانه missingno برویم،
63
00:02:13,200 –> 00:02:15,360
چند ویژگی در کتابخانه پانداها وجود دارد
64
00:02:15,360 –> 00:02:17,680
که می تواند بینش اولیه را در
65
00:02:17,680 –> 00:02:19,920
مورد اینکه واقعاً چه مقدار داده وجود ندارد
66
00:02:19,920 –> 00:02:21,920
و اولین مورد استفاده از روش توصیف نقطهای
67
00:02:21,920 –> 00:02:23,840
و این جدولی
68
00:02:23,840 –> 00:02:25,760
حاوی آمار خلاصه در مورد
69
00:02:25,760 –> 00:02:28,319
قاب داده را برمیگرداند، مانند مقادیر میانگین حداکثر و
70
00:02:28,319 –> 00:02:30,720
حداقل در بالای
71
00:02:30,720 –> 00:02:32,720
جدول، نقشی به نام count وجود دارد و در این
72
00:02:32,720 –> 00:02:34,480
مثال میبینیم که
73
00:02:34,480 –> 00:02:36,319
برای هر کدام تعداد متغیری داریم. ویژگی های درون
74
00:02:36,319 –> 00:02:38,319
چارچوب داده و این یک
75
00:02:38,319 –> 00:02:40,640
نشانه اولیه است که
76
00:02:40,640 –> 00:02:42,720
همه مقادیر در داده های ما وجود ندارند، ما می توانیم
77
00:02:42,720 –> 00:02:44,720
این را یک قدم جلوتر ببریم و ما روش اطلاعات نقطهای
78
00:02:44,720 –> 00:02:46,239
79
00:02:46,239 –> 00:02:48,080
و این خلاصهای
80
00:02:48,080 –> 00:02:50,000
از قاب داده و همچنین تعداد
81
00:02:50,000 –> 00:02:52,400
مقادیر غیر تهی را برمیگرداند، میتوانیم ببینیم که وقتی
82
00:02:52,400 –> 00:02:54,959
این سلول را اجرا میکنیم،
83
00:02:54,959 –> 00:02:57,200
خلاصهای مختصر از وضعیت دادهها و
84
00:02:57,200 –> 00:02:59,519
میزان داده های از دست رفته دیگر
85
00:02:59,519 –> 00:03:03,280
روش سریع دیگری که می توانیم استفاده کنیم df dot s
86
00:03:03,280 –> 00:03:04,239
n a است
87
00:03:04,239 –> 00:03:06,959
که می توانیم جمع نقطه ای را به این
88
00:03:06,959 –> 00:03:09,599
تابع اضافه کنیم و سپس جدول خلاصه ای
89
00:03:09,599 –> 00:03:12,800
از تعداد کل مقادیر تهی در
90
00:03:12,800 –> 00:03:15,120
هر یک از ستون های قاب داده را دریافت می کنیم.
91
00:03:15,120 –> 00:03:16,480
از این خلاصه میتوانیم ببینیم
92
00:03:16,480 –> 00:03:19,200
که تعدادی ستون داریم، یعنی
93
00:03:19,200 –> 00:03:23,440
گروه md gr و
94
00:03:23,440 –> 00:03:26,000
lithofascis که در آن هیچ null وجود ندارد، اما همه
95
00:03:26,000 –> 00:03:28,400
ستونهای دیگر درجاتی از
96
00:03:28,400 –> 00:03:30,000
مقادیر گمشده دارند،
97
00:03:30,000 –> 00:03:31,519
بنابراین اجازه دهید به کتابخانه missingno برویم،
98
00:03:31,519 –> 00:03:32,560
99
00:03:32,560 –> 00:03:34,480
بنابراین در کتابخانه missingno.
100
00:03:34,480 –> 00:03:36,640
چهار نوع نمودار اصلی برای
101
00:03:36,640 –> 00:03:39,040
تجسم کامل بودن داده ها وجود دارد،
102
00:03:39,040 –> 00:03:42,000
نمودار میله ای، نمودار ماتریس، نقشه حرارتی
103
00:03:42,000 –> 00:03:44,720
و دندروگرام، هر کدام از این نمودارها
104
00:03:44,720 –> 00:03:46,560
مزایای خاص خود را برای شناسایی
105
00:03:46,560 –> 00:03:48,720
داده های از دست رفته دارند، بنابراین اجازه دهید به هر یک نگاهی بیندازیم.
106
00:03:48,720 –> 00:03:50,640
به نوبه خود اولین موردی که ما
107
00:03:50,640 –> 00:03:52,799
به آن نگاه خواهیم کرد یک نمودار میله ای است و می توان آن را
108
00:03:52,799 –> 00:03:56,080
به سادگی با فراخوانی نوار نقطه
109
00:03:56,080 –> 00:03:58,959
msno و سپس ارسال یک df در قاب داده تولید کرد
110
00:03:58,959 –> 00:04:00,879
و این یک نمودار ساده را ارائه می دهد که در آن
111
00:04:00,879 –> 00:04:02,879
هر نوار نشان دهنده یک ستون در
112
00:04:02,879 –> 00:04:04,799
داده ها است. قاب ارتفاع نوار
113
00:04:04,799 –> 00:04:06,879
نشان می دهد که ستون چقدر کامل است
114
00:04:06,879 –> 00:04:09,200
و چند مقدار غیر تهی وجود دارد،
115
00:04:09,200 –> 00:04:11,040
بنابراین وقتی این را اجرا می کنیم می توانیم ببینیم که در
116
00:04:11,040 –> 00:04:12,720
سمت چپ نمودار،
117
00:04:12,720 –> 00:04:15,760
مقیاس محور y از صفر تا یک
118
00:04:15,760 –> 00:04:17,759
در محدوده یک است. نشان دهنده صد در صد
119
00:04:17,759 –> 00:04:19,759
کامل بودن داده است اگر نوار کمتر
120
00:04:19,759 –> 00:04:21,519
از این باشد، نشان می دهد که
121
00:04:21,519 –> 00:04:23,840
مقادیر گم شده در آن ستون در
122
00:04:23,840 –> 00:04:25,680
سمت راست نمودار وجود دارد، مقیاس
123
00:04:25,680 –> 00:04:28,080
در مقادیر شاخص اندازه گیری می شود و
124
00:04:28,080 –> 00:04:30,400
سمت راست بالا نشان دهنده حداکثر تعداد
125
00:04:30,400 –> 00:04:32,639
ردیف ها در داخل نمودار است. قاب داده در امتداد
126
00:04:32,639 –> 00:04:34,320
بالای نمودار یک سری
127
00:04:34,320 –> 00:04:36,800
اعداد وجود دارد که تعداد
128
00:04:36,800 –> 00:04:38,720
کل مقادیر غیر تهی را در آن
129
00:04:38,720 –> 00:04:39,759
ستون نشان می دهد
130
00:04:39,759 –> 00:04:41,680
در این مثال می بینیم که تعدادی
131
00:04:41,