در این مطلب، ویدئو تجزیه و تحلیل داده های فروش با پایتون | حل مسائل دنیای واقعی علم داده | مطالعه موردی پایتون | EDS با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:28:56
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,080 –> 00:00:03,199
سلام همه به 8science خوش آمدید نام من
2
00:00:03,199 –> 00:00:04,960
aditya است و امروز مربی شما خواهم بود
3
00:00:04,960 –> 00:00:06,240
4
00:00:06,240 –> 00:00:07,839
در جلسه امروز قرار است در
5
00:00:07,839 –> 00:00:09,760
مورد تجزیه و تحلیل داده ها با پایتون
6
00:00:09,760 –> 00:00:12,799
با استفاده از یک مطالعه موردی ساده صحبت کنیم
7
00:00:12,799 –> 00:00:13,599
8
00:00:13,599 –> 00:00:16,239
. یکی
9
00:00:16,239 –> 00:00:17,760
از محبوب ترین مجموعه داده های
10
00:00:17,760 –> 00:00:20,720
مورد استفاده برای تجزیه و تحلیل داده ها برای دریافت مازاد
11
00:00:20,720 –> 00:00:21,680
این مجموعه داده ها،
12
00:00:21,680 –> 00:00:23,760
کافیست روی پیوند داده شده در
13
00:00:23,760 –> 00:00:25,519
توضیحات زیر کلیک کنید
14
00:00:25,519 –> 00:00:27,680
و آن پیوند این صفحه این github را باز می کند
15
00:00:27,680 –> 00:00:28,800
16
00:00:28,800 –> 00:00:30,880
و برای دسترسی به همه فایل ها توصیه
17
00:00:30,880 –> 00:00:32,079
می کنم این مخزن را فورک کنید.
18
00:00:32,079 –> 00:00:34,480
و آن را به صورت محلی کلون کنید یا می توانید به سادگی
19
00:00:34,480 –> 00:00:36,559
روی این دکمه سبز رنگ کلیک کنید و
20
00:00:36,559 –> 00:00:39,600
فایل فشرده را دانلود کنید
21
00:00:40,399 –> 00:00:42,800
، پوشه zip دارای سه فایل
22
00:00:42,800 –> 00:00:44,879
با فایل تجزیه و تحلیل فروش پایتون
23
00:00:44,879 –> 00:00:47,120
، لوگوی علمی head و فایل فروش سوپر سورس است
24
00:00:47,120 –> 00:00:48,079
25
00:00:48,079 –> 00:00:51,520
که با فرمت xlsx و قبل از
26
00:00:51,520 –> 00:00:52,160
شروع است.
27
00:00:52,160 –> 00:00:53,920
من به شما پیشنهاد می کنم برای مطالعات موردی بیشتر در این کانال مشترک شوید.
28
00:00:53,920 –> 00:00:56,640
29
00:00:56,640 –> 00:00:58,800
اجازه دهید با عمیق تر شدن
30
00:00:58,800 –> 00:01:00,000
به داده ها شروع کنیم و
31
00:01:00,000 –> 00:01:03,760
ببینیم مجموعه داده ها در اکسل چگونه به نظر می رسد،
32
00:01:05,920 –> 00:01:07,680
بنابراین اینگونه است مجموعه داده ها به نظر می رسد
33
00:01:07,680 –> 00:01:10,000
در اکسل ما شناسه
34
00:01:10,000 –> 00:01:13,600
سفارش تاریخ ارسال تاریخ ارسال حالت حالت
35
00:01:13,600 –> 00:01:16,960
مشتری نام بخش ایالت
36
00:01:16,960 –> 00:01:19,200
بازار کشور و چند ستون دیگر مانند
37
00:01:19,200 –> 00:01:22,159
سود تخفیف مقدار فروش
38
00:01:22,159 –> 00:01:25,520
داریم و در کل حدود 51000290
39
00:01:25,520 –> 00:01:26,080
رکورد
40
00:01:26,080 –> 00:01:28,159
در این فایل اکسل داریم.
41
00:01:28,159 –> 00:01:30,640
تجزیه و تحلیل در نوت بوک python jupyter،
42
00:01:30,640 –> 00:01:32,720
بنابراین برای باز کردن نوت بوک jupiter، من به سادگی
43
00:01:32,720 –> 00:01:34,159
ترمینال خود را باز می کنم
44
00:01:34,159 –> 00:01:37,680
و دفترچه یادداشت jupiter را در اینجا تایپ می کنم،
45
00:01:37,680 –> 00:01:39,280
اگر نوت بوک jupyter خود را
46
00:01:39,280 –> 00:01:40,880
نصب نکرده اید، به سادگی
47
00:01:40,880 –> 00:01:42,880
یک لینک در توضیحات زیر قرار می دهم، فقط
48
00:01:42,880 –> 00:01:44,000
دستورالعمل ها را دنبال کنید
49
00:01:44,000 –> 00:01:47,920
و و آن را در رایانه خود نصب کنید،
50
00:01:50,320 –> 00:01:53,119
بنابراین من به سادگی یک فایل جدید در اینجا ایجاد می
51
00:01:53,119 –> 00:01:55,840
کنم
52
00:01:55,840 –> 00:02:00,640
و بیایید نامی مانند
53
00:02:00,640 –> 00:02:04,479
تجزیه و تحلیل فروش پاندا
54
00:02:05,680 –> 00:02:07,759
بگذارم، بنابراین بیایید ابتدا با تجزیه و تحلیل فروش شروع
55
00:02:07,759 –> 00:02:09,440
کنیم، اجازه دهید هدف امروز را مورد بحث قرار دهیم،
56
00:02:09,440 –> 00:02:10,318
57
00:02:10,318 –> 00:02:12,480
بنابراین اول از همه ما در مورد
58
00:02:12,480 –> 00:02:15,840
روند فروش کلی
59
00:02:21,599 –> 00:02:23,840
بحث می کنیم، سپس در مورد
60
00:02:23,840 –> 00:02:27,120
10 محصول برتر از نظر فروش
61
00:02:32,400 –> 00:02:34,400
بحث می کنیم، سپس در مورد اینکه کدام
62
00:02:34,400 –> 00:02:37,840
محصولات پرفروش هستند
63
00:02:41,840 –> 00:02:43,920
، بحث می کنیم.
64
00:02:43,920 –> 00:02:51,840
ترجیح داده شده ترین حالت حمل
65
00:02:56,800 –> 00:02:58,879
و نقل است و در نهایت ما در
66
00:02:58,879 –> 00:03:02,560
مورد سودآورترین دسته ها و
67
00:03:02,840 –> 00:03:05,840
زیرمجموعه ها بحث خواهیم کرد،
68
00:03:13,519 –> 00:03:16,800
بنابراین اجازه دهید با وارد کردن تعداد کمی از
69
00:03:16,800 –> 00:03:18,879
کتابخانه هایی که
70
00:03:18,879 –> 00:03:20,800
در داده های خود استفاده می کنیم شروع کنیم و در حین انجام تجزیه
71
00:03:20,800 –> 00:03:21,920
72
00:03:21,920 –> 00:03:23,840
و تحلیل داده ها، هر کدام را توضیح خواهم داد. و هر خط تا
73
00:03:23,840 –> 00:03:25,599
زمانی که شما همان را در نوت بوک jupyter خود تکرار می کنید برای شما آسان تر خواهد بود
74
00:03:25,599 –> 00:03:26,400
75
00:03:26,400 –> 00:03:30,159
،
76
00:03:30,840 –> 00:03:33,760
77
00:03:33,760 –> 00:03:35,840
بنابراین وارد کردن کتابخانه های مورد نیاز
78
00:03:35,840 –> 00:03:37,120
اولین مورد
79
00:03:37,120 –> 00:03:39,599
برای دستکاری داده ها خواهد بود،
80
00:03:39,599 –> 00:03:40,879
81
00:03:40,879 –> 00:03:42,959
هنگامی که پانداهای آناکوندا را دانلود می کنید
82
00:03:42,959 –> 00:03:44,000
به طور پیش فرض از کتابخانه pandas استفاده
83
00:03:44,000 –> 00:03:47,519
می کنیم. من پانداهای کتابخانه
84
00:03:47,519 –> 00:03:50,159
پاندا را با استفاده از نام مستعار
85
00:03:50,159 –> 00:03:54,080
spd وارد میکنم و از matplotlib و cpone برای تجسم دادهها
86
00:03:58,840 –> 00:04:01,840
87
00:04:04,959 –> 00:04:08,480
با استفاده از یک تابع جادویی استفاده میکنیم
88
00:04:12,640 –> 00:04:16,159
و cboard را وارد میکنم،
89
00:04:18,160 –> 00:04:20,639
بنابراین این سه کتابخانهای هستند که
90
00:04:20,639 –> 00:04:22,800
برای تجزیه و تحلیل کل دادهها استفاده میکنیم
91
00:04:22,800 –> 00:04:29,840
. مجموعه داده
92
00:04:31,199 –> 00:04:34,080
را وارد کنید، من آن را در یک قاب داده df وارد می کنم
93
00:04:34,080 –> 00:04:35,759
و با استفاده از یک دستور
94
00:04:35,759 –> 00:04:39,199
معروف به عنوان pd pd dot read
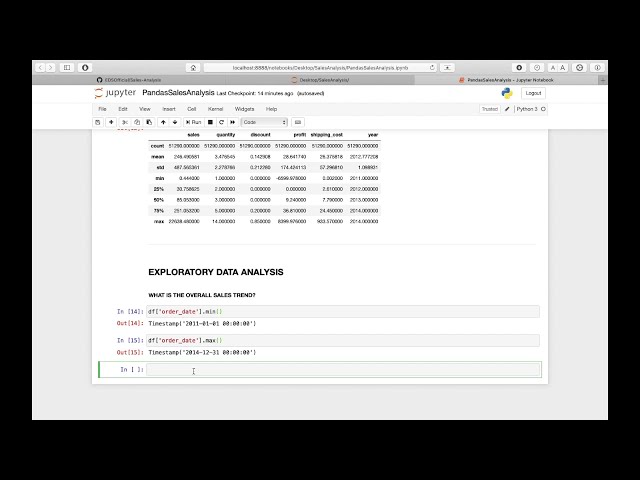
95
00:04:39,199 –> 00:04:42,080
underscore excel از آنجایی که فایل در
96
00:04:42,080 –> 00:04:43,680
قالب xlsx است،
97
00:04:43,680 –> 00:04:47,040
بنابراین من فقط sup را تایپ می کنم و
98
00:04:47,040 –> 00:04:48,960
سپس یک برگه قرار دهید تا من تمام فایلهایی را
99
00:04:48,960 –> 00:04:50,320
که با sup شروع میشوند در
100
00:04:50,320 –> 00:04:52,320
پوشه خاصی که این فایل پایتون خاص در آن است، دریافت کنم
101
00:04:52,320 –> 00:04:53,919
،
102
00:04:53,919 –> 00:04:56,479
بنابراین بیایید این فایل را وارد کنیم، توجه
103
00:04:56,479 –> 00:04:57,280
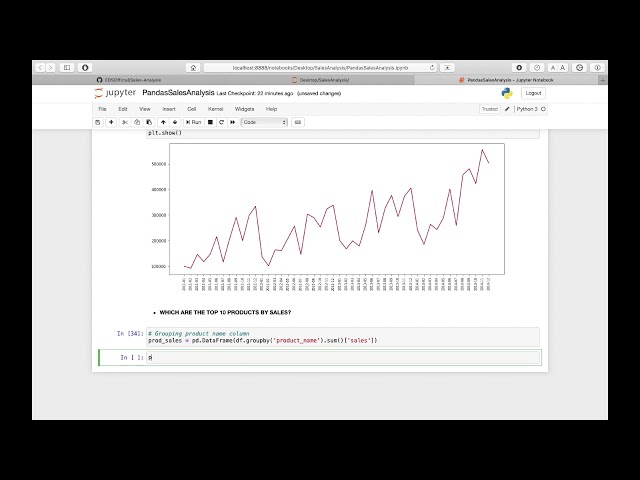
داشته باشیم که ممکن است
104
00:04:57,280 –> 00:04:59,280
کمی طول بکشد، زیرا ما
105
00:04:59,280 –> 00:05:01,440
بیش از 51000 فایل داریم. رکوردهایی که در
106
00:05:01,440 –> 00:05:04,400
قالب xlsx انجام میشوند، بنابراین
107
00:05:04,400 –> 00:05:06,160
از آنجایی که کتابخانه خود را وارد کردهایم
108
00:05:06,160 –> 00:05:08,160
، زمان آن رسیده است تا حسابرسی
109
00:05:08,160 –> 00:05:10,720
دادهها را انجام دهیم، بنابراین
110
00:05:10,720 –> 00:05:12,479
تا زمانی که ندانیم درباره چه دادههایی صحبت میکنیم،
111
00:05:12,479 –> 00:05:14,160
ساختن آن بسیار مهم است.
112
00:05:14,160 –> 00:05:15,520
دوستی با دادهها
113
00:05:15,520 –> 00:05:17,440
برای اینکه بدانیم چند ستون داریم
114
00:05:17,440 –> 00:05:19,039
چند رکورد
115
00:05:19,039 –> 00:05:21,120
داریم انواع دادهها کدامند آیا
116
00:05:21,120 –> 00:05:22,479
مقادیری از دست رفته است آیا
117
00:05:22,479 –> 00:05:24,240
مقادیر پرت در
118
00:05:24,240 –> 00:05:26,080
مجموعه دادهها وجود دارد، بنابراین اینها برخی از
119
00:05:26,080 –> 00:05:27,840
مهمترین چیزهایی هستند که
120
00:05:27,840 –> 00:05:30,400
هر حرفهای هر تحلیلگر
121
00:05:30,400 –> 00:05:32,000
دانشمند داده،
122
00:05:32,000 –> 00:05:34,000
تحلیلگر شخصی بیشتر وقت خود را صرف
123
00:05:34,000 –> 00:05:35,199
انجام این کار میکند،
124
00:05:35,199 –> 00:05:37,600
بیایید نگاهی به مجموعه دادهها بیندازیم
125
00:05:37,600 –> 00:05:38,639
تا ایدهای سریع داشته باشیم
126
00:05:38,639 –> 00:05:40,800
که دادهها چگونه به نظر میرسند، میتوانیم
127
00:05:40,800 –> 00:05:43,039
تابع head را در قاب دادهها بنامیم
128
00:05:43,039 –> 00:05:45,919
. o بیایید
129
00:05:45,919 –> 00:05:47,520
پنج
130
00:05:47,520 –> 00:05:50,880
ردیف اول مجموعه داده را نظر بدهیم، بنابراین من به سادگی از
131
00:05:50,880 –> 00:05:52,639
یک تابع head استفاده می کنم، این یادداشت پنج ردیف اول را برمی گرداند،
132
00:05:52,639 –> 00:05:54,320
133
00:05:54,320 –> 00:05:56,479
ما می توانیم
134
00:05:56,479 –> 00:05:58,400
ده ردیف را در اینجا بنویسم تا ده سطر را دریافت کنیم، اما در حال حاضر
135
00:05:58,400 –> 00:05:59,280
ما خیلی
136
00:05:59,280 –> 00:06:01,759
خوب است، اگر
137
00:06:01,759 –> 00:06:03,520
متوجه شدید این همان ظاهری
138
00:06:03,520 –> 00:06:05,039
است که در اکسل
139
00:06:05,039 –> 00:06:06,000
140
00:06:06,000 –> 00:06:08,560
141
00:06:08,560 –> 00:06:09,520
142
00:06:09,520 –> 00:06:11,840
دیده بودیم، خوب است، ما
143
00:06:11,840 –> 00:06:13,440
با پنج ردیف خوب هستیم. پنج سطر
144
00:06:13,440 –> 00:06:21,840
شبیه به چه شکلی است،
145
00:06:24,319 –> 00:06:26,240
بنابراین این پنج سطر آخر پنج سطر آخر
146
00:06:26,240 –> 00:06:28,639
ترتیب شناسه تاریخ ترتیب همه چیز
147
00:06:28,639 –> 00:06:30,240
تقریباً یکسان است،
148
00:06:30,240 –> 00:06:32,160
اما از این ده سطر
149
00:06:32,160 –> 00:06:34,000
نمی توانم دقیقا
150
00:06:34,000 –> 00:06:36,080
بگویم تعداد سطرها و
151
00:06:36,080 –> 00:06:37,840
تعداد ستون ها چقدر است. موجود در مجموعه داده
152
00:06:37,840 –> 00:06:38,400
153
00:06:38,400 –> 00:06:41,680
برای آن من از
154
00:06:41,680 –> 00:06:43,840
تابع شکل استفاده خواهم کرد تا
155
00:06:43,840 –> 00:06:46,720
شکل مجموعه داده
156
00:06:46,720 –> 00:06:50,080
157
00:06:50,080 –> 00:06:52,080
158
00:06:52,080 –> 00:06:53,280
159
00:06:53,280 –> 00:06:56,160
را به دست بیاورم. که
160
00:06:56,160 –> 00:06:58,880
دقیقاً همان چیزی است که در اکسل داشتیم بنابراین
161
00:06:58,880 –> 00:07:00,960
ما همان فایل دسترسی را
162
00:07:00,960 –> 00:07:02,080
در حال حاضر پایتون تکرار
163
00:07:02,080 –> 00:07:04,800
کرده ایم و در مجموع 21 ستون داریم، اما
164
00:07:04,800 –> 00:07:06,400
از آنجایی که مشاهده می کنید
165
00:07:06,400 –> 00:07:08,160
166
00:07:08,160 –> 00:07:10,000
167
00:07:10,000 –> 00:07:12,319
به دلیل وجود این نقطه نقطه بین
168
00:07:12,319 –> 00:07:13,280
تمام این ستون ها، نمی
169
00:07:13,280 –> 00:07:14,639
توانیم تعداد دقیق ستون ها را به درستی ببینیم. نام همه
170
00:07:14,639 –> 00:07:16,720
ستونها را تاکنون نمیدانم، بنابراین
171
00:07:16,720 –> 00:07:22,080
بیایید ستونهای موجود در مجموعه داده را
172
00:07:24,720 –> 00:07:30,080
با استفاده از df.columns دریافت
173
00:07:30,080 –> 00:07:31,919
کنیم، بنابراین بله، اکنون تعداد
174
00:07:31,919 –> 00:07:33,599
کل ستونها را در مجموعه دادههای خود به دست آوردهایم،
175
00:07:33,599 –> 00:07:35,520
بنابراین اجازه دهید یک خلاصه مختصر
176
00:07:35,520 –> 00:07:44,400
از مجموعه دادهها
177
00:07:44,400 –> 00:07:47,120
بنابراین اطلاعات نقطهای df یکی از این تابعها
178
00:07:47,120 –> 00:07:47,440
179
00:07:47,440 –> 00:07:49,919
است که خلاصهای کوچک از
180
00:07:49,919 –> 00:07:52,319
مجموعه دادهها را در رابطه با انواع دادهها،
181
00:07:52,319 –> 00:07:54,080
تعداد عناصر، تعداد ورودیها،
182
00:07:54,080 –> 00:07:58,160
تعداد ستونها، به ما نشان میدهد
183
00:07:58,160 –> 00:08:00,639
و این مطابق با مورد قبلی
184
00:08:00,639 –> 00:08:02,240
است که ما قبلاً انجام
185
00:08:02,240 –> 00:08:03,039
186
00:08:03,039 –> 00:08:06,240
دادیم که قبلاً 51290 ورودی و 20 در مجموع
187
00:08:06,240 –> 00:08:07,759
21 ستون داریم،
188
00:08:07,759 –> 00:08:09,520
گاهی اوقات چه اتفاقی می افتد وقتی که ما یک
189
00:08:09,520 –> 00:08:11,120
مجموعه داده خام داریم وقتی روی مشکلات دنیای واقعی کار می کنیم
190
00:08:11,120 –> 00:08:12,720
191
00:08:12,720 –> 00:08:15,120
و وقتی مجموعه داده های خام را دریافت می کنیم
192
00:08:15,120 –> 00:08:16,960
گاهی اوقات تاریخ ها n است.
193
00:08:16,960 –> 00:08:20,160
با فرمت مناسب فرمت مورد نیاز ما است، بنابراین می
194
00:08:20,160 –> 00:08:21,039
توانیم بگوییم که در اینجا
195
00:08:21,039 –> 00:08:23,680
شناسه سفارش شی در قالب شیء است
196
00:08:23,680 –> 00:08:25,360
تاریخ سفارش و داده ارسال در قالب تاریخ
197
00:08:25,360 –> 00:08:26,240
زمان است،
198
00:08:26,240 –> 00:08:28,400
بنابراین در مجموع ما دو تاریخ زمان
199
00:08:28,400 –> 00:08:30,560
با فرمت چهار مقدار
200
00:08:30,560 –> 00:08:33,519
شناور داریم چهار ستون شناور دو ستونهای عدد صحیح
201
00:08:33,519 –> 00:08:36,799
و 13 ستون شی،
202
00:08:36,799 –> 00:08:38,719
بنابراین اکنون میتوانیم تجزیه و تحلیل بیشتری روی
203
00:08:38,719 –> 00:08:40,719
مجموعه دادههای خود انجام دهیم تا به سؤالاتی
204
00:08:40,719 –> 00:08:43,360
که قبلاً پرسیدهایم پاسخ دهیم، اما قبل از آن
205
00:08:43,360 –> 00:08:44,640
باید ببینیم آیا
206
00:08:44,640 –> 00:08:46,480
مقادیر گمشدهای در مجموعه دادههای ما
207
00:08:46,480 –> 00:08:48,320
وجود دارد تا بررسی کنیم که آیا مقادیر گمشدهای وجود دارد یا خیر.
208
00:08:48,320 –> 00:08:49,519
کل مجموعه داده ای
209
00:08:49,519 –> 00:08:51,600
که به عنوان تابع تهی استفاده خواهیم کرد، مانند
210
00:08:51,600 –> 00:08:55,839
اینکه آیا مقادیر گم شده ای وجود دارد،
211
00:08:59,279 –> 00:09:03,040
بنابراین نقطه df null است، تابعی است
212
00:09:03,040 –> 00:09:05,600
که می توانیم از آن استفاده کنیم n a نیز برای بررسی آن
213
00:09:05,600 –> 00:09:06,240
است،
214
00:09:06,240 –> 00:09:09,120
بنابراین عدد دقیق
215
00:09:09,120 –> 00:09:10,080
این تابع
216
00:09:10,080 –> 00:09:12,080
را نشان می دهد. تعداد دقیق مقادیر از دست رفته
217
00:09:12,080 –> 00:09:14,480
موجود در هر یک از ستونها
218
00:09:14,480 –> 00:09:17,040
از آنجایی که هر ستون صفر را نشان میدهد،
219
00:09:17,040 –> 00:09:17,920
به این معنی که
220
00:09:17,920 –> 00:09:20,959
تعداد مقادیر از دست رفته صفر داریم
221
00:09:20,959 –> 00:09:23,040
، ما خوش شانس هستیم که مجموعه دادهای به این خوبی
222
00:09:23,040 –> 00:09:24,880
بدون مقادیر از دست رفته
223
00:09:24,880 –> 00:09:26,800
داریم در حالی که تمرکز نمیکنیم. در این ویدیوی خاص،
224
00:09:26,800 –> 00:09:28,800
اما یک دانشمند داده
225
00:09:28,800 –> 00:09:32,000
یا یک تحلیلگر nl، 90
226
00:09:32,000 –> 00:09:34,000
وقت خود را صرف تمیز کردن و بحث کردن
227
00:09:34,000 –> 00:09:35,839
داده ها می کند، زیرا ما هیچ مقدار از دست رفته ای
228
00:09:35,839 –> 00:09:36,399
229
00:09:36,399 –> 00:09:38,160
نداریم، می توانیم تجزیه و تحلیل بیشتر
230
00:09:38,160 –> 00:09:39,600
روی مجموعه داده را شروع کنیم،
231
00:09:39,600 –> 00:09:42,000
بنابراین بیایید کمی آن را بررسی کنیم.
232
00:09:42,000 –> 00:09:43,839
خلاصه آمار توصیفی
233
00:09:43,839 –> 00:09:51,839
مجموعه دادههای ما،
234
00:09:53,839 –> 00:09:56,320
بنابراین من از این تابع توصیف استفاده
235
00:09:56,320 –> 00:09:57,920
خواهم کرد تا خلاصه آمار توصیفی را به دست بیاورم.
236
00:09:57,920 –> 00:09:58,720
237
00:09:58,720 –> 00:10:05,839
238
00:10:06,079 –> 00:10:08,160
239
00:10:08,160 –> 00:10:09,760
240
00:10:09,760 –> 00:10:11,360
241
00:10:11,360 –> 00:10:13,360
توجه داشته باشید که از اینجا فقط آمار مربوط
242
00:10:13,360 –> 00:10:14,880
به ستون های عددی را نشان می
243
00:10:14,880 –> 00:10:16,240
دهد، می توانید آمار زیر را
244
00:10:16,240 –> 00:10:18,320
مانند تعداد ردیف ها مشاهده کنید
245
00:10:18,320 –> 00:10:20,079
که با چیزی که مشخصه shape
246
00:10:20,079 –> 00:10:21,680
میانگین را به ما نشان می دهد
247
00:10:21,680 –> 00:10:24,000
248
00:10:24,000 –> 00:10:25,760
مطابقت دارد یا می توانیم آن را میانگین و همچنین انحراف استاندارد
249
00:10:25,760 –> 00:10:28,320
بدانیم که داده های ما چگونه است. حداقل
250
00:10:28,320 –> 00:10:30,240
و حداکثر مقدار هر
251
00:10:30,240 –> 00:10:32,079
ستون تعداد آیتم هایی است که در
252
00:10:32,079 –> 00:10:34,320
صدک های دوم و سوم قرار می گیرند
253
00:10:34,320 –> 00:10:36,320
تا بتوانیم مقدار مناسبی از
254
00:10:36,320 –> 00:10:38,560
داده های خود را از این نشان دهیم.
255
00:10:38,560 –> 00:10:41,600
به عنوان مثال میانگین فروش 246 است
256
00:10:41,600 –> 00:10:44,240
. میانگین مقدار فروخته شده 3
257
00:10:44,240 –> 00:10:46,800
و میانگین تخفیف 0.4 است
258
00:10:46,800 –> 00:10:48,800
و سود متوسط سودی که ما
259
00:10:48,800 –> 00:10:50,160
ز محصول خود دریافت می
260
00:10:50,160 –> 00:10:53,200
نیم 28 اس
261
00:10:53,200 –> 00:10:54,160
262
00:10:54,160 –> 00:10:56,560
. مثل الان که
263
00:10:56,560 –> 00:10:58,079
با داده ها آشنا هستیم می دانیم
264
00:10:58,079 –> 00:10:59,839
چند ستون
265
00:10:59,839 –> 00:11:01,600
وجود دارد چند رکورد در
266
00:11:01,600 –> 00:11:03,279
مجموعه داده وجود دارد آیا مقادیر گم شده ای
267
00:11:03,279 –> 00:11:05,279
در مجموعه داده وجود دارد که انواع داده ها چیست،
268
00:11:05,279 –> 00:11:07,040
پس از این، اجازه دهید
269
00:11:07,040 –> 00:11:09,120
داده های اکتشافی را انجام دهیم. تجزیه و تحلیل برای
270
00:11:09,120 –> 00:11:11,360
جمعآوری اطلاعاتی از این مجموعه دادهها،
271
00:11:11,360 –> 00:11:13,040
بنابراین اجازه دهید
272
00:11:13,040 –> 00:11:15,040
تجزیه و تحلیل دادههای اکتشافی را انجام دهیم و با اولین
273
00:11:15,040 –> 00:11:16,079
سوال شروع کنیم
274
00:11:16,079 –> 00:11:19,920
که روند فروش کلی چیست،
275
00:11:24,000 –> 00:11:25,600
بنابراین اجازه دهید ابتدا بررسی کنیم که
276
00:11:25,600 –> 00:11:27,200
حداقل تاریخی که
277
00:11:27,200 –> 00:11:28,880
حداقل تاریخ داریم چقدر است. اول
278
00:11:28,880 –> 00:11:30,720
ژانویه 2011 است
279
00:11:30,720 –> 00:11:34,560
و بیایید حداکثر تاریخ را
280
00:11:34,560 –> 00:11:36,959
بررسی کنیم حداکثر تاریخی که داریم 31
281
00:11:36,959 –> 00:11:38,720
دسامبر 2014 است
282
00:11:38,720 –> 00:11:41,279
که می گوید مجموعه داده های ما
283
00:11:41,279 –> 00:11:44,560
از 1 ژانویه 2011 تا 31
284
00:11:44,560 –> 00:11:46,800
دسامبر 2014 است.
285
00:11:46,800 –> 00:11:49,440
و بیایید ستون
286
00:11:49,440 –> 00:11:50,160
287
00:11:50,160 –> 00:11:52,800
ماه و سال ماه و سال را از این تاریخ سفارش بیرون بیاوریم،
288
00:11:52,800 –> 00:11:53,600
بنابراین من
289
00:11:53,600 –> 00:11:57,920
فقط ماه را اینجا تایپ می کنم
290
00:11:57,920 –> 00:12:00,959
و
291
00:12:01,200 –> 00:12:03,839
اگر بعد از سفارش روی تب ضربه بزنم، df را تایپ می کنم، بنابراین
292
00:12:03,839 –> 00:12:06,160
تمام ستون های مربوط به سفارش را
293
00:12:06,160 –> 00:12:09,120
دریافت می کنم. تاریخ سفارش
294
00:12:09,120 –> 00:12:12,800
من یک تابع ساده را
295
00:12:18,399 –> 00:12:25,839
برای بدست آوردن سال از این مجموعه داده اعمال می کنم،
296
00:12:25,920 –> 00:12:29,680
بنابراین به نظر می رسد اینگونه به نظر می رسد اجازه دهید به
297
00:12:29,680 –> 00:12:31,040
شما نشان دهم،
298
00:12:31,040 –> 00:12:33,440
بنابراین در ابتدا ما روز ماه و
299
00:12:33,440 –> 00:12:35,120
سال را داشتیم، اکنون ماه و سال داریم، بنابراین ما
300
00:12:35,120 –> 00:12:36,800
یک نمودار را ترسیم خواهیم کرد.
301
00:12:36,800 –> 00:12:39,600
یک نمودار خطی را برای دقیق نشان دادن
302
00:12:39,600 –> 00:12:41,279
اینکه روند کلی فروش
303
00:12:41,279 –> 00:12:45,519
ماهانه چگونه بوده است ترسیم کنید، بنابراین اجازه دهید من نظر بدهم
304
00:12:51,120 –> 00:12:55,120
و سپس در اینجا گروه بندی بر اساس ماه
305
00:12:55,120 –> 00:12:58,880
df گروه نقطه بر
306
00:13:03,440 –> 00:13:05,680
اساس دریافت می کنم، گروه بندی بر اساس را دریافت می کنم.
307
00:13:05,680 –> 00:13:06,959
مجموع ماه سال
308
00:13:06,959 –> 00:13:09,920
بعد از ماه gopro در اینجا ما دریافت کردیم مقدار
309
00:13:09,920 –> 00:13:10,959
فروش ماه یا ماه
310
00:13:10,959 –> 00:13:13,920
تخفیف سود هزینه حمل و نقل
311
00:13:13,920 –> 00:13:14,480
312
00:13:14,480 –> 00:13:16,800
سال مجموع همه چیزهایی که فقط برای فروش در اینجا نیاز داریم،
313
00:13:16,800 –> 00:13:17,519
314
00:13:17,519 –> 00:13:20,000
بنابراین بیایید فروش را از اینجا دریافت کنیم
315
00:13:20,000 –> 00:13:20,880
316
00:13:20,880 –> 00:13:23,200
و بیایید آن را در قالب قاب داده دریافت کنیم.
317
00:13:23,200 –> 00:13:25,839
ایندکس را بازنشانی کنید،
318
00:13:25,839 –> 00:13:28,800
بنابراین مجموعه داده شبیه
319
00:13:28,800 –> 00:13:29,839
مجموعه داده جدید است
320
00:13:29,839 –> 00:13:34,560
بیایید یک نام برای آن um df
321
00:13:34,560 –> 00:13:37,600