در این مطلب، ویدئو آموزش پانداس: چگونه داده ها را مرتب کنیم با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,669
سلام دنیا من مادر هستم و شما
2
00:00:02,669 –> 00:00:04,170
دوباره به مجموعه ویدیوهای آموزشی من خوش آمدید،
3
00:00:04,170 –> 00:00:07,230
آموزش اسپانیایی و من واقعا متاسفم
4
00:00:07,230 –> 00:00:09,360
که این ویدیو خیلی دیر منتشر
5
00:00:09,360 –> 00:00:11,190
شده است، تقریباً دو هفته است که
6
00:00:11,190 –> 00:00:13,740
آخرین ویدیوی خود را آپلود کرده ام اما این به دلیل
7
00:00:13,740 –> 00:00:15,509
برخی مشکلات سلامتی است. که من در حال گذراندن آن بودم،
8
00:00:15,509 –> 00:00:18,630
بنابراین اکنون سعی خواهم کرد ویدیوها
9
00:00:18,630 –> 00:00:20,939
را کمی سریعتر بسازم و این مجموعه را در اسرع وقت تکمیل کنم،
10
00:00:20,939 –> 00:00:23,460
بنابراین موضوع امروز
11
00:00:23,460 –> 00:00:25,890
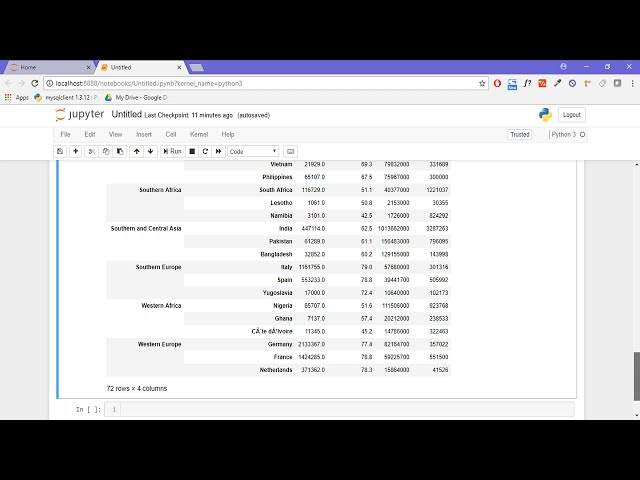
ما این است که چگونه می توانیم داده ها را در dataframe pandas مرتب کنیم،
12
00:00:25,890 –> 00:00:29,490
بنابراین اجازه دهید یک
13
00:00:29,490 –> 00:00:32,340
نوت بوک جدید پایتون را شروع کنم و این داده
14
00:00:32,340 –> 00:00:35,280
ای است که یک فرمت XLS است و نه به عنوان
15
00:00:35,280 –> 00:00:37,590
کاربرگ اکسل بابا، ما قرار است از آن استفاده کنیم،
16
00:00:37,590 –> 00:00:39,210
بنابراین اولین کاری که می خواهم انجام دهم این است که
17
00:00:39,210 –> 00:00:44,250
پانداس را وارد کنیم، متأسفم و سپس
18
00:00:44,250 –> 00:00:46,980
آن را به یک متغیر DF اختصاص می دهم و سپس
19
00:00:46,980 –> 00:00:54,809
از آن استفاده می کنم. اکسل را بخوانید امیدوارم
20
00:00:54,809 –> 00:00:57,239
نام را درست گذاشته باشم، بنابراین بیایید داده های جمعیت را ببینیم،
21
00:00:57,239 –> 00:00:59,699
بله عالی است،
22
00:00:59,699 –> 00:01:02,640
بنابراین اجازه دهید بروم و
23
00:01:02,640 –> 00:01:05,099
اگر آن را خوب خواندم چند رکورد را بررسی کنم، بنابراین این
24
00:01:05,099 –> 00:01:07,110
داده خاصی است که ما از آن استفاده می کنیم در
25
00:01:07,110 –> 00:01:08,970
واقع از دنباله من است. نمونه
26
00:01:08,970 –> 00:01:12,420
پایگاه داده از ta من فکر میکنم ما
27
00:01:12,420 –> 00:01:15,810
آن را شهر از پایگاه داده جهان مینامیم، بنابراین
28
00:01:15,810 –> 00:01:17,340
اساساً شامل نام منطقه،
29
00:01:17,340 –> 00:01:19,290
نام کشور سطح
30
00:01:19,290 –> 00:01:22,920
امید به زندگی جمعیت و تولید ناخالص ملی است، بنابراین قبل از
31
00:01:22,920 –> 00:01:24,720
این به شما بگویم که فقط میخواهم
32
00:01:24,720 –> 00:01:26,640
به شما اطلاع دهم که این دادهها قبلاً
33
00:01:26,640 –> 00:01:28,950
بر اساس منطقه مرتب شدهاند و
34
00:01:28,950 –> 00:01:31,799
ستونهای جمعیت بهاینترتیب همه مناطق مرتب شدهاند و
35
00:01:31,799 –> 00:01:34,229
پس از آن یک رابطه بین منطقهای
36
00:01:34,229 –> 00:01:36,659
مانند اینجا برای قطب جنوب وجود دارد، سپس ما
37
00:01:36,659 –> 00:01:38,549
دادهها را بر اساس جمعیت مرتب کردهایم
38
00:01:38,549 –> 00:01:40,860
تا به جای استفاده از head، اگر با
39
00:01:40,860 –> 00:01:43,770
۲۰ رکورد با کلاه ۲۰ برویم، آن منطقه را خواهید دید.
40
00:01:43,770 –> 00:01:45,869
در حال حاضر در یک قالب مرتب شده
41
00:01:45,869 –> 00:01:47,880
و در یک منطقه خاص،
42
00:01:47,880 –> 00:01:50,340
کشورها بر اساس جمعیت مرتب شده اند، به
43
00:01:50,340 –> 00:01:53,189
طوری که داده های از پیش مرتب
44
00:01:53,189 –> 00:01:55,680
شده ما در اختیار داریم، اما هدف ما از امروز این است که
45
00:01:55,680 –> 00:01:58,740
یاد بگیریم چگونه داده ها را ببینیم، بنابراین من فقط
46
00:01:58,740 –> 00:02:02,399
دوست دارم این فهرست را فراخوانی کنم. آن را
47
00:02:02,399 –> 00:02:06,450
جالب تر کنید و من فقط 0
48
00:02:06,450 –> 00:02:08,699
کاما 1 را انجام می دهم، بنابراین از این
49
00:02:08,699 –> 00:02:12,090
ستون نام منطقه و کشور به عنوان شاخص استفاده می کنم و اجازه
50
00:02:12,090 –> 00:02:13,740
دهید فقط بروم و
51
00:02:13,740 –> 00:02:16,740
پنج را محدود کنم و این کد را کامل بخوانم، بنابراین
52
00:02:16,740 –> 00:02:19,110
اکنون می توانید ببینید نام منطقه و کشور
53
00:02:19,110 –> 00:02:21,810
بهعنوان شاخص و
54
00:02:21,810 –> 00:02:24,960
ستونهای دیگر بهعنوان مجموعه داده یا
55
00:02:24,960 –> 00:02:27,330
ستونهای قاب داده استفاده میشود، اکنون اولین چیزی که
56
00:02:27,330 –> 00:02:29,460
در مرتبسازی پانداس وجود دارد، یک
57
00:02:29,460 –> 00:02:33,960
فهرست مرتبسازی نام تابع داریم، بنابراین DF یا شاخص مرتبسازی داریم،
58
00:02:33,960 –> 00:02:36,510
بنابراین این تابع اصلی است.
59
00:02:36,510 –> 00:02:39,570
که ما داریم و در این تابع
60
00:02:39,570 –> 00:02:41,610
میتوانیم محوری
61
00:02:41,610 –> 00:02:44,160
را که میخواهیم دادهها را بر اساس آن مرتب کنیم ارائه کنیم، بنابراین
62
00:02:44,160 –> 00:02:46,470
ابتدا میخواهید دادهها را همانطور
63
00:02:46,470 –> 00:02:49,470
که در فهرست ما در دادههای ردیفی است مرتب کنید
64
00:02:49,470 –> 00:02:52,560
و اگر فقط آن را به این شکل رها
65
00:02:52,560 –> 00:02:55,140
کنم، با اجرای این کد خواهید دید که اکنون
66
00:02:55,140 –> 00:02:58,080
داده های خود را بر اساس فهرست مرتب می کنیم،
67
00:02:58,080 –> 00:03:00,720
زیرا Midea قبلاً در فهرست مرتب شده است، ما
68
00:03:00,720 –> 00:03:03,180
تغییرات زیادی را مشاهده نخواهیم کرد، بنابراین
69
00:03:03,180 –> 00:03:04,950
تنها چیزی که در اینجا تغییر می کند این است
70
00:03:04,950 –> 00:03:08,820
که مانند کشورهای بالتیک، حتی
71
00:03:08,820 –> 00:03:11,310
اگر جمعیت لتونی بیشتر است
72
00:03:11,310 –> 00:03:14,700
در حال حاضر یک نام کشور به
73
00:03:14,700 –> 00:03:17,760
ترتیب حروف الفبا مرتب شده است، بنابراین از آنجایی که استونی در
74
00:03:17,760 –> 00:03:20,340
دست برتر است همانطور که با E به ترتیب صعودی شروع می شود
75
00:03:20,340 –> 00:03:21,840
تا لتونی،
76
00:03:21,840 –> 00:03:24,390
بنابراین استونی اکنون در کشورهای بالتیک
77
00:03:24,390 –> 00:03:26,940
در سطح اول یا در سطح
78
00:03:26,940 –> 00:03:30,000
اول حضور دارد. ردیف در حالی که اگر من ru در این
79
00:03:30,000 –> 00:03:33,510
کد قبلی و کمی این محدودیت را افزایش دهید و
80
00:03:33,510 –> 00:03:36,210
می توانید ببینید که استونی به
81
00:03:36,210 –> 00:03:38,670
دلیل کمترین جمعیت
82
00:03:38,670 –> 00:03:41,160
آن در آن منطقه آخرین بود، اما در حال حاضر وقتی ما
83
00:03:41,160 –> 00:03:45,240
صخره ها یا گارسون قاب بر شاخص داریم،
84
00:03:45,240 –> 00:03:47,370
این تونیا را در همان سطح اول داریم که
85
00:03:47,370 –> 00:03:50,400
به این دلیل است که ما شاخصها را بر اساس مقادیرشان مرتب کردهایم،
86
00:03:50,400 –> 00:03:53,250
بهطوری که یک مقدار رشتهای
87
00:03:53,250 –> 00:03:55,260
است، آنها بر اساس حروف الفبا مرتب میشوند
88
00:03:55,260 –> 00:03:57,870
تا جایی که شما میتوانید فهرست را مرتب کنید،
89
00:03:57,870 –> 00:04:00,390
ما همچنین میتوانیم یک چیز را در اینجا تعریف کنیم
90
00:04:00,390 –> 00:04:02,550
این است که میتوانیم برای مرتبسازی ایندکس تعریف کنیم.
91
00:04:02,550 –> 00:04:05,460
بر اساس سطوح،
92
00:04:05,460 –> 00:04:07,230
منطقه او یک سطح است در حالی که نام کشور سطح
93
00:04:07,230 –> 00:04:10,440
دیگری است، می توانیم از سطح برابر استفاده کنیم و
94
00:04:10,440 –> 00:04:12,920
می توانیم این متغیر نام کشور را پاس کنیم
95
00:04:12,920 –> 00:04:17,790
و حالا اگر این کد را اجرا کنم، متوجه می شوید
96
00:04:17,790 –> 00:04:20,010
که داده ها اکنون بر اساس نام کشورها مرتب شده اند.
97
00:04:20,010 –> 00:04:22,350
اکنون مرتبسازی بر اساس
98
00:04:22,350 –> 00:04:24,990
مناطق حذف شده است و سطحی که برای
99
00:04:24,990 –> 00:04:26,790
مرتبسازی استفاده میشود، نام کشور است،
100
00:04:26,790 –> 00:04:27,540
101
00:04:27,540 –> 00:04:29,220
از این رو ما همه نامهای کشورها را مرتببندی کردهایم،
102
00:04:29,220 –> 00:04:32,790
بنابراین
103
00:04:32,790 –> 00:04:35,850
میتوانید الجزایر آنگولا قطب جنوب را ببینید که همه
104
00:04:35,850 –> 00:04:38,790
در یک ردیف قرار گرفتهاند. ترتیب داده شده است به
105
00:04:38,790 –> 00:04:41,310
طوری که ما داده ها را بر اساس سطوح شاخص هایی که در اختیار داریم مرتب کرده
106
00:04:41,310 –> 00:04:44,730
ایم، اما همانطور
107
00:04:44,730 –> 00:04:46,950
که می بینید در اینجا یک مقدار اسکالر
108
00:04:46,950 –> 00:04:49,740
یک نام ستون یا نام شاخص است
109
00:04:49,740 –> 00:04:52,380
که لازم نیست این باشد، می توانید
110
00:04:52,380 –> 00:04:54,840
یک عدد ارسال کنید. فهرستی از نامها وقتی فهرست چند
111
00:04:54,840 –> 00:04:57,000
سلسله مراتبی دارید و از آن
112
00:04:57,000 –> 00:04:59,940
برای مرتبسازی دادهها بر اساس آن استفاده میشود، اما
113
00:04:59,940 –> 00:05:01,980
همانطور که در اینجا فقط دو ستون
114
00:05:01,980 –> 00:05:04,140
از فهرست عبور میکنند چیزی ایجاد نمیکنند
115
00:05:04,140 –> 00:05:06,810
، فقط برای نشان دادن هدف شما
116
00:05:06,810 –> 00:05:10,070
میتوانید این کار را در به این ترتیب شما فقط می توانید
117
00:05:10,070 –> 00:05:13,700
تمام این موارد را محصور کنید با عرض پوزش ما
118
00:05:13,700 –> 00:05:18,150
اشتباه کرده ایم و دقیقاً مانند این می
119
00:05:18,150 –> 00:05:21,840
توانید کارهایی مانند این انجام دهید و
120
00:05:21,840 –> 00:05:24,900
کل لیست ستون ها را پاس کنید و سپس
121
00:05:24,900 –> 00:05:27,150
اگر این کد را اجرا کنید ابتدا
122
00:05:27,150 –> 00:05:28,830
بر اساس نام کشور مرتب می شود و وقتی
123
00:05:28,830 –> 00:05:31,290
چندین کشور داریم، نام منطقه
124
00:05:31,290 –> 00:05:33,510
برای مرتبسازی
125
00:05:33,510 –> 00:05:35,820
یا گسستن پیوندها استفاده میشود، بهطوریکه یکی
126
00:05:35,820 –> 00:05:38,580
از
127
00:05:38,580 –> 00:05:41,250
سطوحی است که ما در اینجا
128
00:05:41,250 –> 00:05:43,830
داریم.
129
00:05:43,830 –> 00:05:47,730
چی ما می توانیم انجام دهیم این است که فقط می توانیم یک
130
00:05:47,730 –> 00:05:50,040
پارامتر اضافی را ارسال کنیم که صعودی است
131
00:05:50,040 –> 00:05:54,390
و در اینجا می توانیم false ارائه دهیم بنابراین
132
00:05:54,390 –> 00:05:57,690
قبلاً ترتیب صعودی بود
133
00:05:57,690 –> 00:05:59,820
اکنون به صورت نزولی مرتب می شود
134
00:05:59,820 –> 00:06:02,870
و می بینیم که کشوری با
135
00:06:02,870 –> 00:06:05,940
الفبا داریم که چرا شما Slavia هستید
136
00:06:05,940 –> 00:06:10,460
در بالا و سپس به سمت پایین
137
00:06:10,460 –> 00:06:13,710
و الجزایر آخرین مورد است،
138
00:06:13,710 –> 00:06:16,620
بنابراین شما می توانید داده ها را به
139
00:06:16,620 –> 00:06:18,480
ترتیب نزولی مرتب کنید و فقط آن
140
00:06:18,480 –> 00:06:20,550
صعودی را برابر false به عنوان
141
00:06:20,550 –> 00:06:23,280
پارامتری تعریف کنید که





![فیلم آموزشی: چگونه صفحه نمایش خود را در Pygame محو کنید [کد در توضیحات] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/H2r2N7D56Uwimage2.jpg)