در این مطلب، ویدئو علوم فضایی با پایتون – AI 1-14: GMM – انتخاب خوبی است؟ با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:13:01
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:04,880 –> 00:00:06,560
به قسمت دیگری از علوم فضایی با
2
00:00:06,560 –> 00:00:07,680
پایتون،
3
00:00:07,680 –> 00:00:09,599
امروز
4
00:00:09,599 –> 00:00:12,960
پروژه طیف بازتاب سیارکی خود را با اسکریپت
5
00:00:12,960 –> 00:00:14,240
شماره 14 به پایان میرسانیم
6
00:00:14,240 –> 00:00:17,119
و امروز میخواهیم
7
00:00:17,119 –> 00:00:20,800
بررسی کنیم که آیا الگوریتم
8
00:00:20,800 –> 00:00:23,199
gmm ما که آخرین بار ایجاد شدیم
9
00:00:23,199 –> 00:00:25,119
منطقی است یا خیر.
10
00:00:25,119 –> 00:00:27,199
است یا فرض آخرین
11
00:00:27,199 –> 00:00:29,920
بار این بود که داده های فضای نهفته
12
00:00:29,920 –> 00:00:31,279
13
00:00:31,279 –> 00:00:33,840
توسط گاوسی های چند متغیره ترسیم می شوند و
14
00:00:33,840 –> 00:00:35,680
ما با مدل های مخلوط گاوسی بازی
15
00:00:35,680 –> 00:00:37,200
کردیم و
16
00:00:37,200 –> 00:00:38,879
از معیار اطلاعات بیزی
17
00:00:38,879 –> 00:00:41,280
برای یافتن بهترین تعداد
18
00:00:41,280 –> 00:00:43,680
گاوسی ها استفاده می کنیم که داده های ما را توصیف می کند
19
00:00:43,680 –> 00:00:45,360
و در واقع می توان گفت خوب،
20
00:00:45,360 –> 00:00:47,280
اکنون تمام شده است، من کلاسترهای خود را دارم
21
00:00:47,280 –> 00:00:49,840
و از کلاس های بدون نظارت خود بازدید می کنم، اما باید
22
00:00:49,840 –> 00:00:52,480
آزمایش کنیم یا ببینیم که آیا داده های ما اصلاً
23
00:00:52,480 –> 00:00:55,199
توسط گاوسی ها ترسیم شده است، بنابراین این همان کاری است
24
00:00:55,199 –> 00:00:56,239
25
00:00:56,239 –> 00:00:58,559
که امروز و سپس
26
00:00:58,559 –> 00:01:01,039
پس از آن این خلاصه و
27
00:01:01,039 –> 00:01:03,039
چشم انداز را انجام خواهیم داد. من می خواهم
28
00:01:03,039 –> 00:01:06,159
کمی صحبت کنم که آینده این پروژه چگونه
29
00:01:06,159 –> 00:01:08,080
خواهد بود اکنون
30
00:01:08,080 –> 00:01:10,080
جلسه امروز از سلول شماره 15 شروع می شود،
31
00:01:10,080 –> 00:01:13,600
بنابراین می توانید مستقیماً به آن
32
00:01:13,600 –> 00:01:15,600
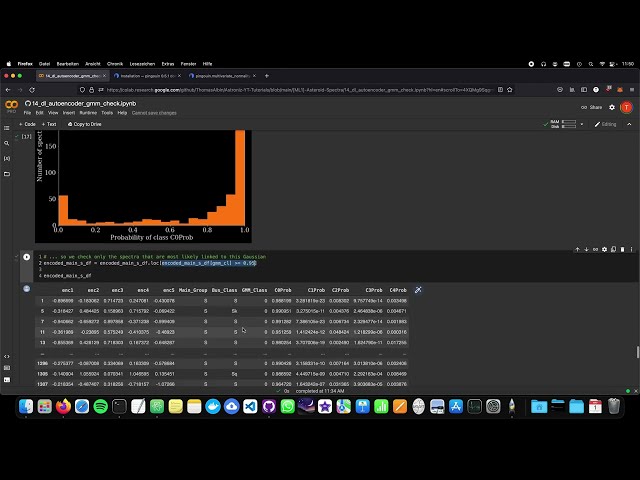
اینجا بروید و c ollab این ویژگی بله
33
00:01:15,600 –> 00:01:17,840
کار نمی کند شما نمی توانید فقط روی آن کلیک کنید
34
00:01:17,840 –> 00:01:20,080
و سپس به آنجا می پرد، فقط در
35
00:01:20,080 –> 00:01:21,520
36
00:01:21,520 –> 00:01:24,000
لپ تاپ jupyter یا نوت بوک jupiter 100 کار می کند، بنابراین بیایید
37
00:01:24,000 –> 00:01:26,159
به سلول 15 برویم این قسمت رمزگذار خودکار است
38
00:01:26,159 –> 00:01:27,439
که آخرین بار بازسازی سیگنال را انجام دادیم
39
00:01:27,439 –> 00:01:29,600
و بنابراین در
40
00:01:29,600 –> 00:01:32,720
مدل مخلوط گاوسی از آخرین بار و سپس باید
41
00:01:32,720 –> 00:01:34,240
42
00:01:34,240 –> 00:01:36,000
43
00:01:36,000 –> 00:01:39,200
در سلول شماره 15 باشیم. اکنون اینجا هستیم،
44
00:01:39,200 –> 00:01:40,479
این
45
00:01:40,479 –> 00:01:43,119
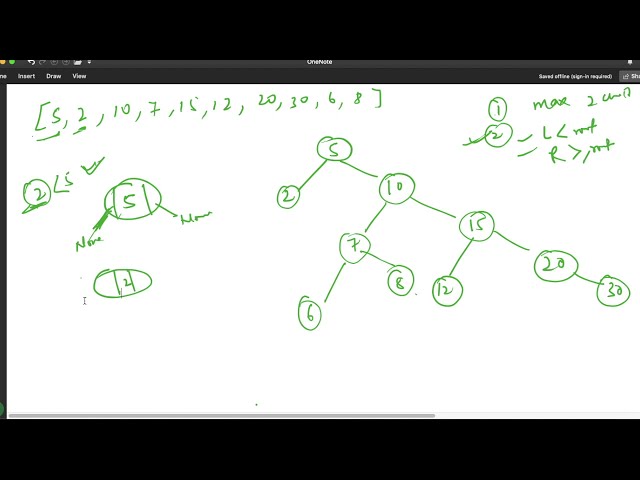
ماتریس سردرگمی است که آخرین بار روی
46
00:01:43,119 –> 00:01:45,360
آن کار کردیم، جایی که دیدیم برای مثال در اینجا این
47
00:01:45,360 –> 00:01:48,240
کلاس gmm به نام c0 با s- مطابقت دارد.
48
00:01:48,240 –> 00:01:50,799
کلاس یا تعداد زیادی از سیارکهای کلاس s
49
00:01:50,799 –> 00:01:53,759
به این کلاس c0
50
00:01:53,759 –> 00:01:54,640
51
00:01:54,640 –> 00:01:57,759
در این بخش خوشهبندی gmm اختصاص داده میشوند
52
00:01:57,759 –> 00:01:59,280
و اکنون ما در حال بررسی هستیم که آیا این
53
00:01:59,280 –> 00:02:01,759
کلاس منطقی است یا نه، بنابراین بیایید
54
00:02:01,759 –> 00:02:03,759
با سلول 15 شروع
55
00:02:03,759 –> 00:02:05,439
کنیم. در سلول 15
56
00:02:05,439 –> 00:02:06,880
57
00:02:06,880 –> 00:02:09,919
به طور کلی من
58
00:02:09,919 –> 00:02:11,760
میخواهم امروز فقط کلاس s را ببینم یا بررسی کنم، بنابراین نه همه
59
00:02:11,760 –> 00:02:13,120
کلاسهای دیگر، بلکه فقط آزمون s،
60
00:02:13,120 –> 00:02:15,520
زیرا این مهمترین مورد است،
61
00:02:15,520 –> 00:02:19,040
بنابراین در اینجا ما فقط
62
00:02:19,040 –> 00:02:22,879
دادهها را به کلاس s اختصاص میدهیم یا میگیریم و
63
00:02:22,879 –> 00:02:25,760
بر اساس ما گروهبندی میکنیم. کلاس gmm و چیزی که ما می بینیم
64
00:02:25,760 –> 00:02:27,280
این است
65
00:02:27,280 –> 00:02:30,879
حدود 430
66
00:02:30,879 –> 00:02:32,959
سیارک کلاس s به این
67
00:02:32,959 –> 00:02:37,599
کلاس gmm 0 در حدود 100 کلاس 2 و 22
68
00:02:37,599 –> 00:02:40,640
به علاوه 4 اختصاص داده شده اند. بنابراین بیایید نگاهی دقیق به
69
00:02:40,640 –> 00:02:43,680
کلاس 0 gmm بیندازیم و ببینیم که آیا این داده ها
70
00:02:43,680 –> 00:02:47,519
در اینجا نوعی
71
00:02:47,519 –> 00:02:49,040
72
00:02:49,040 –> 00:02:51,200
توزیع گاوسی چند بعدی را توصیف می کنند یا خیر.
73
00:02:51,200 –> 00:02:55,200
پس چگونه این کار را اینجا در سلول 16 انجام
74
00:02:55,200 –> 00:02:58,239
دهیم، اکنون به
75
00:02:58,239 –> 00:03:02,000
احتمالات مختلف نیز نگاهی می اندازیم به um
76
00:03:02,000 –> 00:03:05,040
از
77
00:03:05,040 –> 00:03:07,280
کلاس های گاوسی گاوسی، بنابراین در اینجا c0
78
00:03:07,280 –> 00:03:10,159
کلاس c1 c2 c3 و c4
79
00:03:10,159 –> 00:03:12,319
و آنچه که ما داریم را داریم. میخواهیم ببینیم یا ببریم، میخواهیم
80
00:03:12,319 –> 00:03:14,800
کلاس s کلاس اتوبوس را بگیریم
81
00:03:14,800 –> 00:03:17,599
و همچنین احتمال c0 را در نظر بگیریم،
82
00:03:17,599 –> 00:03:19,920
بنابراین فقط
83
00:03:19,920 –> 00:03:21,840
احتمالات یا
84
00:03:21,840 –> 00:03:23,040
85
00:03:23,040 –> 00:03:25,680
طیفهای کلاس s بله را میگیریم که احتمال بالایی دارند و
86
00:03:25,680 –> 00:03:26,959
احتمال
87
00:03:26,959 –> 00:03:29,920
88
00:03:29,920 –> 00:03:34,080
بالایی دارند که کلاس c0 باشند. بله، ما
89
00:03:34,080 –> 00:03:36,799
میخواهیم باس کلاس s و کلاس gm m کلاس
90
00:03:36,799 –> 00:03:37,760
0 را انتخاب
91
00:03:37,760 –> 00:03:41,760
کنیم که احتمال بالای c0 بودن دارند،
92
00:03:41,760 –> 00:03:43,519
بنابراین این کاری است که میخواهیم انجام دهیم و
93
00:03:43,519 –> 00:03:46,000
سپس این دادهها برای بررسی گاوسی ما استفاده میشوند،
94
00:03:46,000 –> 00:03:48,959
95
00:03:50,560 –> 00:03:53,920
بنابراین در اینجا اجازه دهید به سرعت یک به
96
00:03:53,920 –> 00:03:56,560
توزیع c0 ما به احتمالات نگاه کنید
97
00:03:56,560 –> 00:04:00,720
این c صفرها با گروه اصلی s
98
00:04:00,720 –> 00:04:03,040
و این فقط یک روال رسم
99
00:04:03,040 –> 00:04:06,879
در اینجا در سلول شماره سلول 16 یا
100
00:04:06,879 –> 00:04:08,720
شماره 17 است
101
00:04:08,720 –> 00:04:11,760
و در اینجا می بینیم که بله بسیاری از
102
00:04:11,760 –> 00:04:13,760
همه داده ها فقط بین
103
00:04:13,760 –> 00:04:15,760
صفر و یک تا صفر درصد پراکنده شده اند.
104
00:04:15,760 –> 00:04:17,199
صد در صد
105
00:04:17,199 –> 00:04:20,639
و ما می بینیم که داده های زیادی بالای 250
106
00:04:20,639 –> 00:04:24,800
بین 95 تا 100 درصد است، بنابراین ما فقط
107
00:04:24,800 –> 00:04:28,240
نگاهی به این احتمال
108
00:04:28,240 –> 00:04:30,160
بالا در این میله های احتمال بالا می اندازیم شما
109
00:04:30,160 –> 00:04:32,639
فقط سیارک های کلاس s را که
110
00:04:32,639 –> 00:04:35,040
متعلق به این نوار خاص هستند و این را در نظر می گیریم.
111
00:04:35,040 –> 00:04:38,080
در سلول شماره 18 انجام می شود. بنابراین
112
00:04:38,080 –> 00:04:40,400
اینجاست که ما فقط می گوییم باشه
113
00:04:40,400 –> 00:04:42,639
لطفاً فقط
114
00:04:42,639 –> 00:04:45,120
سیارک های کلاس s با
115
00:04:45,120 –> 00:04:47,440
احتمال بزرگتر از 95 درصد را
116
00:04:47,440 –> 00:04:50,400
به من بدهید که به این کلاس c0 gmm اختصاص داده شده اند
117
00:04:50,400 –> 00:04:51,440
118
00:04:51,440 –> 00:04:54,080
و این اکنون ما است. قاب داده بعدی را پیدا
119
00:04:54,080 –> 00:04:56,560
کنید اساساً مانند قبل است،
120
00:04:56,560 –> 00:04:58,479
اما ما اینجا
121
00:04:58,479 –> 00:04:59,840
122
00:04:59,840 –> 00:05:02,720
کلاس های c0 یا احتمالات خود را داریم که به ترتیب
123
00:05:02,720 –> 00:05:08,320
حداقل 95 درصد یا 0.95 دارند،
124
00:05:09,680 –> 00:05:10,560
125
00:05:10,560 –> 00:05:12,720
اکنون سؤال این است که ما می خواهیم چه کاری انجام دهیم
126
00:05:12,720 –> 00:05:16,000
127
00:05:16,000 –> 00:05:18,080
تا مشخص شود آیا این داده ها در اینجا این لاتین هستند یا خیر.
128
00:05:18,080 –> 00:05:20,400
فضا نوعی توزیع گاوسی را ترسیم می کند
129
00:05:20,400 –> 00:05:22,960
یا نه و برای این کار از
130
00:05:22,960 –> 00:05:25,840
یک بسته پایتون جدید استفاده می کنیم که به آن pin
131
00:05:25,840 –> 00:05:28,880
going یا بنابراین پنگوئن نیست،
132
00:05:28,880 –> 00:05:30,000
کمی متفاوت نوشته شده است
133
00:05:30,000 –> 00:05:31,840
pingoyin من نمی دانم چگونه
134
00:05:31,840 –> 00:05:34,080
آن را به درستی تلفظ کنم و فقط سریع تلفظش کنم.
135
00:05:34,080 –> 00:05:36,800
توجه داشته باشید که اگر آن را در google
136
00:05:36,800 –> 00:05:39,360
collab نصب میکنید،
137
00:05:39,360 –> 00:05:41,600
نسخه دیگری از scipy را نیز نصب میکند و سپس این
138
00:05:41,600 –> 00:05:43,440
اتفاق میافتد که هنگام وارد کردن پنگوئن خطایی ایجاد میشود،
139
00:05:43,440 –> 00:05:46,000
بنابراین باید
140
00:05:46,000 –> 00:05:47,840
زمان اجرا خود را در collab مجدداً راهاندازی کنید، اما
141
00:05:47,840 –> 00:05:50,560
همه چیز باید کار کند، بنابراین فقط یک
142
00:05:50,560 –> 00:05:53,520
هشدار کوچک در اینجا وجود دارد. بنابراین در سلول 19 ما در حال
143
00:05:53,520 –> 00:05:54,720
نصب
144
00:05:54,720 –> 00:05:57,280
پنگوئن هستیم و همچنین آن را وارد می کنیم
145
00:05:57,280 –> 00:05:59,520
و pingoin چیست، بله، اینجا می گوید
146
00:05:59,520 –> 00:06:01,600
این یک بسته آماری منبع باز
147
00:06:01,600 –> 00:06:04,560
است که برای یا در پایتون 3 نوشته شده است
148
00:06:04,560 –> 00:06:07,280
و با پانداهایی با numpy
149
00:06:07,280 –> 00:06:09,520
و غیره کار می کند و برخی از عملکردها را اضافه می کند.
150
00:06:09,520 –> 00:06:11,680
نه برای مثال numpy یا
151
00:06:11,680 –> 00:06:14,800
scipy برای چیزهای آماری بله، بنابراین
152
00:06:14,800 –> 00:06:16,240
چیزهای مختلف زیادی وجود دارد
153
00:06:16,240 –> 00:06:18,960
فقط کافی است api را بررسی کنید، بله
154
00:06:18,960 –> 00:06:21,600
، اساساً یک ابزار آماری است و یکی
155
00:06:21,600 –> 00:06:23,520
از ابزارهایی که وجود دارد این به
156
00:06:23,520 –> 00:06:26,560
اصطلاح نرمال بودن چند متغیره است و در اینجا
157
00:06:26,560 –> 00:06:28,400
آنها بررسی میکنند که آیا
158
00:06:28,400 –> 00:06:30,240
um این تابع بررسی میکند که آیا دادهها uh است یا خیر
159
00:06:30,240 –> 00:06:30,880
160
00:06:30,880 –> 00:06:34,960
، یک نرمال بودن چند متغیره را توصیف میکند،
161
00:06:34,960 –> 00:06:37,360
بنابراین بر اساس بنابراین و دایرهای است که
162
00:06:37,360 –> 00:06:40,720
مقالهای از سال 1990 است، فکر میکنم بله وج