در این مطلب، ویدئو آموزش پای اسپارک | مقدمه ای بر آپاچی اسپارک با پایتون | آموزش PySpark | ادورکا با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,500 –> 00:00:04,850
[موسیقی]
2
00:00:06,350 –> 00:00:08,970
اسپارک آپاچی یک چارچوب قدرتمند
3
00:00:08,970 –> 00:00:10,440
است که به شدت در
4
00:00:10,440 –> 00:00:12,570
صنعت برای اهداف تجزیه و تحلیل بیدرنگ و
5
00:00:12,570 –> 00:00:14,670
یادگیری ماشین استفاده میشود، بنابراین من میتوانم
6
00:00:14,670 –> 00:00:16,170
از طرف یک تارگا
7
00:00:16,170 –> 00:00:17,970
به همه شما در این جلسه آموزش PI اسپارک خوشامد بگویم،
8
00:00:17,970 –> 00:00:20,070
بنابراین قبل از ادامه کار
9
00:00:20,070 –> 00:00:22,109
در این جلسه اجازه دهید نگاهی گذرا
10
00:00:22,109 –> 00:00:23,670
به موضوعاتی داشته باشیم که امروز پوشش خواهیم داد،
11
00:00:23,670 –> 00:00:25,710
بنابراین با توضیح اینکه
12
00:00:25,710 –> 00:00:28,019
دقیقاً چه چیزی جرقه PI میزند و چگونه کار میکند،
13
00:00:28,019 –> 00:00:29,910
شروع میکنیم.
14
00:00:29,910 –> 00:00:32,250
15
00:00:32,250 –> 00:00:34,140
به شما نشان می دهم که چگونه PI
16
00:00:34,140 –> 00:00:36,120
spark را پس از اتمام نصب در سیستم
17
00:00:36,120 –> 00:00:37,770
خود نصب کنید، در مورد
18
00:00:37,770 –> 00:00:39,870
مفاهیم بنیادی PI
19
00:00:39,870 –> 00:00:43,230
spark مانند موارد عجیب و غریب MLA چارچوب داده های متنی جرقه
20
00:00:43,230 –> 00:00:46,320
و موارد دیگر صحبت خواهم کرد و در
21
00:00:46,320 –> 00:00:48,090
نهایت این جلسه را با یک نسخه نمایشی خواهم بست.
22
00:00:48,090 –> 00:00:49,980
که در آن من به شما نشان خواهم داد که چگونه PI
23
00:00:49,980 –> 00:00:52,620
spark را برای حل موارد استفاده واقعی پیاده سازی کنید، بنابراین
24
00:00:52,620 –> 00:00:54,539
بدون هیچ مقدمه دیگری اجازه دهید به سرعت
25
00:00:54,539 –> 00:00:56,969
سفر خود را به PI spark در حال حاضر
26
00:00:56,969 –> 00:00:58,829
قبل از شروع با PI spark آغاز کنیم، اجازه دهید
27
00:00:58,829 –> 00:01:00,449
ابتدا به شما توضیح دهم. در مورد اکوسیستم by spark
28
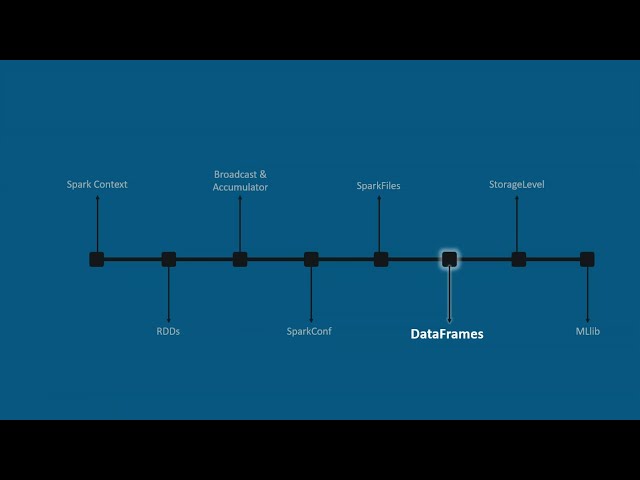
00:01:00,449 –> 00:01:02,879
همانطور که از نمودار می بینید
29
00:01:02,879 –> 00:01:05,099
اکوسیستم اسپارک
30
00:01:05,099 –> 00:01:07,260
از اجزای مختلفی مانند spark sequel
31
00:01:07,260 –> 00:01:09,840
spark streaming گرافیک MLM تشکیل شده است و
32
00:01:09,840 –> 00:01:12,299
جزء اصلی API جزء spark sequel
33
00:01:12,299 –> 00:01:13,979
برای استفاده از
34
00:01:13,979 –> 00:01:16,080
قدرت جستجوهای تزئینی و بهینه
35
00:01:16,080 –> 00:01:18,240
سازی ذخیره سازی با اجرا استفاده می شود. دنبالهای مانند
36
00:01:18,240 –> 00:01:20,460
جستارهای دادههای جرقهای که در
37
00:01:20,460 –> 00:01:22,860
شناسههای ما و سایر منابع خارجی
38
00:01:22,860 –> 00:01:24,570
ارائه میشوند، جزء جریان جرقه به توسعهدهندگان اجازه میدهد تا
39
00:01:24,570 –> 00:01:26,430
پردازش دستهای و
40
00:01:26,430 –> 00:01:28,080
جریان دادهها را با سهولت در همان
41
00:01:28,080 –> 00:01:29,759
برنامه انجام دهند، کتابخانه یادگیری ماشین
42
00:01:29,759 –> 00:01:32,280
توسعه و استقرار گرافیک
43
00:01:32,280 –> 00:01:33,990
خطوط لوله یادگیری ماشینی مقیاسپذیر را تسهیل میکند.
44
00:01:33,990 –> 00:01:36,509
اجازه دهید
45
00:01:36,509 –> 00:01:38,369
دانشمند داده با منابع گرافی و
46
00:01:38,369 –> 00:01:40,409
غیرگرافی کار کند تا به انعطافپذیری و
47
00:01:40,409 –> 00:01:42,659
انعطافپذیری در ساخت و
48
00:01:42,659 –> 00:01:45,420
تبدیل گراف دست یابد و در نهایت
49
00:01:45,420 –> 00:01:47,700
مؤلفه Sparco حیاتیترین
50
00:01:47,700 –> 00:01:49,530
مؤلفه اکوسیستم آبگرم است که
51
00:01:49,530 –> 00:01:51,680
مسئول برنامهریزی و نظارت بر کل توابع ورودی/خروجی است.
52
00:01:51,680 –> 00:01:54,780
53
00:01:54,780 –> 00:01:56,880
اکوسیستم آبگرم i بر روی این موتور اجرایی هسته ساخته شده
54
00:01:56,880 –> 00:01:59,399
است که دارای
55
00:01:59,399 –> 00:02:01,439
epa های قابل توسعه در زبان های مختلف مانند اسکالا
56
00:02:01,439 –> 00:02:04,590
پایتون و جاوا است و در جلسه امروز
57
00:02:04,590 –> 00:02:06,719
به طور خاص در مورد
58
00:02:06,719 –> 00:02:08,459
SPARC API در
59
00:02:08,459 –> 00:02:10,258
زبان های برنامه نویسی پایتون که بیشتر به
60
00:02:10,258 –> 00:02:12,540
عنوان اسپا PI شناخته می شود صحبت خواهم کرد. تعجب می کنم که
61
00:02:12,540 –> 00:02:13,959
چرا PI جرقه
62
00:02:13,959 –> 00:02:16,750
خوبی برای به دست آوردن بینش بهتر می دهد، اجازه
63
00:02:16,750 –> 00:02:19,150
دهید اکنون مختصری در مورد PI spa به شما ارائه دهم، زیرا
64
00:02:19,150 –> 00:02:20,590
قبلاً می دانیم PI spark
65
00:02:20,590 –> 00:02:21,849
همکاری دو
66
00:02:21,849 –> 00:02:24,939
فناوری قدرتمند است که Spark هستند که یک
67
00:02:24,939 –> 00:02:26,469
68
00:02:26,469 –> 00:02:28,870
چارچوب محاسباتی خوشه ای منبع باز است که بر اساس سرعت سهولت استفاده ساخته شده است.
69
00:02:28,870 –> 00:02:31,030
و جریان تجزیه و تحلیل و
70
00:02:31,030 –> 00:02:33,219
یکی دیگر پایتون البته پایتون است
71
00:02:33,219 –> 00:02:34,689
که یک زبان برنامه نویسی سطح بالا همه منظوره است و
72
00:02:34,689 –> 00:02:36,639
طیف گسترده
73
00:02:36,639 –> 00:02:38,799
ای از کتابخانه ها را ارائه می دهد و در حال حاضر عمدتاً
74
00:02:38,799 –> 00:02:40,209
برای یادگیری ماشین و
75
00:02:40,209 –> 00:02:43,719
تجزیه و تحلیل زمان واقعی استفاده می شود که جرقه PI را به ما می دهد
76
00:02:43,719 –> 00:02:46,180
. یک IPE پایتون برای جرقه که به
77
00:02:46,180 –> 00:02:47,709
شما امکان میدهد از سادگی
78
00:02:47,709 –> 00:02:50,349
پایتون و قدرت اسپارک آپاچی استفاده کنید
79
00:02:50,349 –> 00:02:53,650
تا دادههای حفرهای را رام کنید، یک جرقه PI نیز
80
00:02:53,650 –> 00:02:55,900
اجازه میدهد. با استفاده از ID DS و
81
00:02:55,900 –> 00:02:59,230
ادغام پیشفرض کتابخانه Pi 4G،
82
00:02:59,230 –> 00:03:01,150
در ادامه در این ویدیو با موارد عجیب و غریب آشنا میشویم،
83
00:03:01,150 –> 00:03:04,060
حالا که میدانید اسپارک پی چیست،
84
00:03:04,060 –> 00:03:05,709
حالا مزایای استفاده از اسپارک
85
00:03:05,709 –> 00:03:06,370
با بایت
86
00:03:06,370 –> 00:03:08,500
را ببینیم، زیرا همه میدانیم که پایتون بسیار است.
87
00:03:08,500 –> 00:03:09,519
ساده و آسان است،
88
00:03:09,519 –> 00:03:11,769
بنابراین وقتی اسپارک در پایتون نوشته
89
00:03:11,769 –> 00:03:13,569
می شود، یادگیری و استفاده از یک جرقه مهمانی را بسیار آسان می
90
00:03:13,569 –> 00:03:16,060
کند، علاوه بر این، یک
91
00:03:16,060 –> 00:03:18,010
زبان تایپ شده پویا است که به این معنی است که موارد عجیب و غریب می
92
00:03:18,010 –> 00:03:20,680
توانند اشیایی از انواع داده های متعدد را نگه دارند، نه
93
00:03:20,680 –> 00:03:22,870
تنها این EPI را ساده
94
00:03:22,870 –> 00:03:25,060
و جامع و صحبت می کند. در مورد
95
00:03:25,060 –> 00:03:26,829
خوانایی نگهداری کد و
96
00:03:26,829 –> 00:03:29,199
آشنایی با API پایتون برای
97
00:03:29,199 –> 00:03:30,970
اسپارک آپاچی به مراتب بهتر از سایر
98
00:03:30,970 –> 00:03:33,040
زبان های برنامه نویسی پایتون نیز
99
00:03:33,040 –> 00:03:34,269
گزینه های مختلفی برای
100
00:03:34,269 –> 00:03:36,159
تجسم ارائه می دهد که
101
00:03:36,159 –> 00:03:38,739
با استفاده از اسکالا یا جاوا امکان پذیر نیست، علاوه بر این می توانید به
102
00:03:38,739 –> 00:03:40,540
راحتی مستقیماً از
103
00:03:40,540 –> 00:03:43,150
پایتون در بالای آن تماس بگیرید. پایتون با
104
00:03:43,150 –> 00:03:44,949
طیف گسترده ای از کتابخانه ها مانند
105
00:03:44,949 –> 00:03:48,099
پانداهای ناتوان کاتالان Seabourn matplotlib ارائه می شود و
106
00:03:48,099 –> 00:03:50,229
این کتابخانه در تتا و آلیسون
107
00:03:50,229 –> 00:03:52,209
و همچنین
108
00:03:52,209 –> 00:03:54,879
با تمام این ویژگی، آمار بالغ و آزمایش شده را ارائه دهید که می توانید
109
00:03:54,879 –> 00:03:57,069
بدون زحمت در پارک ادویه برنامه ریزی کنید، در
110
00:03:57,069 –> 00:03:59,169
صورتی که در جایی گیر کرده اید یا عادت
111
00:03:59,169 –> 00:04:01,540
کرده اید، یک جامعه جرقه PI بزرگ
112
00:04:01,540 –> 00:04:03,639
در آنجا وجود دارد که می توانید با آنها تماس بگیرید و
113
00:04:03,639 –> 00:04:06,579
درخواست خود را مطرح کنید و این بسیار است. actor بنابراین من
114
00:04:06,579 –> 00:04:07,780
از این فرصت به خوبی استفاده
115
00:04:07,780 –> 00:04:10,120
خواهم کرد تا به شما نشان دهم چگونه PI spark را در یک
116
00:04:10,120 –> 00:04:12,819
سیستم نصب کنید، اکنون در اینجا من از یک لینوکس مبتنی بر کلاه قرمزی استفاده می کنم
117
00:04:12,819 –> 00:04:15,489
که به یک سیستم ارسال شده است، همان
118
00:04:15,489 –> 00:04:17,289
مراحل را می توان برای استفاده از
119
00:04:17,289 –> 00:04:19,570
سیستم های لینوکس نیز به ترتیب انجام داد. برای نصب
120
00:04:19,570 –> 00:04:21,699
PI spark ابتدا مطمئن شوید که
121
00:04:21,699 –> 00:04:23,500
Hadoop را در سیستم خود نصب کرده اید، بنابراین اگر
122
00:04:23,500 –> 00:04:24,880
می خواهید در مورد نحوه نصب ado اطلاعات بیشتری کسب
123
00:04:24,880 –> 00:04:27,260
کنید، لطفاً لیست پخش هیدرولیست ما را
124
00:04:27,260 –> 00:04:29,330
در YouTube بررسی کنید یا می توانید
125
00:04:29,330 –> 00:04:32,060
ابتدا وبلاگ ما را در وب سایت Drakkar بررسی کنید.
126
00:04:32,060 –> 00:04:33,500
شما باید به
127
00:04:33,500 –> 00:04:35,690
وب سایت رسمی Apache spark بروید که
128
00:04:35,690 –> 00:04:38,360
نقطه آپاچی o-r-g است و در
129
00:04:38,360 –> 00:04:39,440
بخش دانلود می توانید آخرین
130
00:04:39,440 –> 00:04:41,750
نسخه انتشار اسپارک را دانلود کنید که
131
00:04:41,750 –> 00:04:44,120
از آخرین نسخه Hadoop یا هیدرو
132
00:04:44,120 –> 00:04:46,550
نسخه 2.7 یا بالاتر پشتیبانی می کند. و حالا وقتی آن را
133
00:04:46,550 –> 00:04:48,440
دانلود کردید تنها کاری که باید انجام دهید این است
134
00:04:48,440 –> 00:04:50,690
که آن را استخراج کنید یا به قول من محتویات فایل را باز کنید
135
00:04:50,690 –> 00:04:52,790
و بعد از آن باید
136
00:04:52,790 –> 00:04:54,530
در مسیری که اسپارک در فایل bash RC نصب شده است قرار دهید
137
00:04:54,530 –> 00:04:57,320
، اکنون باید
138
00:04:57,320 –> 00:04:59,690
pip را نیز نصب کنید. و نوت بوک Jupiter با استفاده
139
00:04:59,690 –> 00:05:01,520
از دستور PIP و مطمئن شوید که
140
00:05:01,520 –> 00:05:04,220
نسخه PIP 10 یا بالاتر است، بنابراین همانطور که
141
00:05:04,220 –> 00:05:06,530
می بینید در اینجا فایل bash RC ما به
142
00:05:06,530 –> 00:05:08,450
نظر می رسد در اینجا می توانید ببینید که
143
00:05:08,450 –> 00:05:10,910
ما در مسیر Hadoop Spark قرار داده ایم
144
00:05:10,910 –> 00:05:13,040
و به عنوان و همچنین پای اسپارک راننده پایتون
145
00:05:13,040 –> 00:05:14,630
که گفته می شود یک نوت بوک قرار می دهد، کاری که
146
00:05:14,630 –> 00:05:17,150
ما انجام خواهیم داد این است که در لحظه ای که
147
00:05:17,150 –> 00:05:19,280
پوسته PI Spock را اجرا می کنید، به طور
148
00:05:19,280 –> 00:05:21,860
خودکار یک نوت بوک مشتری را برای شما باز می کند، اکنون
149
00:05:21,860 –> 00:05:24,260
کار کردن با نوت بوک مشتری بسیار آسان است.
150
00:05:24,260 –> 00:05:26,540
شل قرار است
151
00:05:26,540 –> 00:05:28,790
اکنون که
152
00:05:28,790 –> 00:05:30,770
مسیر نصب را تمام کرده ایم تعقیب کند، بیایید اکنون عمیق تر
153
00:05:30,770 –> 00:05:32,480
در PI spark غوطه ور
154
00:05:32,480 –> 00:05:34,250
155
00:05:34,250 –> 00:05:36,320
156
00:05:36,320 –> 00:05:38,060
157
00:05:38,060 –> 00:05:39,620
شویم. پوشاندن زیر هفتم e مبانی PI Spock،
158
00:05:39,620 –> 00:05:42,110
بنابراین بیایید
159
00:05:42,110 –> 00:05:43,760
با اولین موضوع در لیست خود شروع کنیم که
160
00:05:43,760 –> 00:05:46,550
زمینه جرقه است، فضای
161
00:05:46,550 –> 00:05:48,710
جرقه قلب هر برنامه کاربردی اسپارکی است که
162
00:05:48,710 –> 00:05:50,930
سرویس های داخلی را راه اندازی می کند و
163
00:05:50,930 –> 00:05:52,700
164
00:05:52,700 –> 00:05:54,680
از طریق یک شیء زمینه جرقه با یک محیط اجرای اسپا ارتباط برقرار می
165
00:05:54,680 –> 00:05:56,570
کند. شما میتوانید یک Dedes یک
166
00:05:56,570 –> 00:05:59,330
دسترسی متغیر تجمعی و پخشی به
167
00:05:59,330 –> 00:06:01,940
کارهای اجرا شده خدمات جرقه ایجاد کنید و خیلی بیشتر
168
00:06:01,940 –> 00:06:04,010
، زمینه جرقه به برنامه درایور جرقه اجازه میدهد تا
169
00:06:04,010 –> 00:06:06,020
170
00:06:06,020 –> 00:06:08,330
از طریق یک مدیر منابع به خوشه دسترسی داشته باشد که میتواند
171
00:06:08,330 –> 00:06:10,910
روی مدیر خوشه باشد یا برنامه درایور
172
00:06:10,910 –> 00:06:12,860
را اجرا کند و سپس عملیات را در داخل اجرا کند.
173
00:06:12,860 –> 00:06:14,870
مجریان در گره های کارگر و
174
00:06:14,870 –> 00:06:17,570
زمینه جرقه از PI برای Jay برای
175
00:06:17,570 –> 00:06:19,760
راه اندازی یک JVM استفاده می کنند که به نوبه خود یک
176
00:06:19,760 –> 00:06:22,220
زمینه جرقه جاوا ایجاد می کند، اکنون پارامترهای مختلفی وجود دارد
177
00:06:22,220 –> 00:06:23,780
که می توان با یک
178
00:06:23,780 –> 00:06:26,180
شیء زمینه جرقه مانند برنامه
179
00:06:26,180 –> 00:06:28,910
اصلی به نام Spock استفاده کرد.
180
00:06:28,910 –> 00:06:31,100
محیطی که در آن
181
00:06:31,100 –> 00:06:33,530
دروازه پیکربندی سریالساز اندازه مسیر تنظیم شده است
182
00:06:33,530 –> 00:06:34,670
و خیلی بیشتر
183
00:06:34,670 –> 00:06:37,190
از این پارامترها
184
00:06:37,190 –> 00:06:39,940
نام برنامه d متداولترین موردی است که
185
00:06:39,940 –> 00:06:41,710
در حال حاضر برای ارائه یک بینش اولیه در مورد نحوه عملکرد یک
186
00:06:41,710 –> 00:06:43,930
برنامه spark استفاده میشود. من
187
00:06:43,930 –> 00:06:46,600
مراحل چرخه حیات اولیه آن را فهرست کردهام.
188
00:06:46,600 –> 00:06:48,820
189
00:06:48,820 –> 00:06:50,770
190
00:06:50,770 –> 00:06:53,380
191
00:06:53,380 –> 00:06:55,450
برنامه درایور شما پس از آن ما
192
00:06:55,450 –> 00:06:58,300
193
00:06:58,300 –> 00:07:00,280
تبدیل تنبلی را داریم که با استفاده از تبدیل، عجیب و غریب های پایه را به عجیب و غریب جدید
194
00:07:00,280 –> 00:07:02,680
تبدیل می کند، سپس تعداد کمی از
195
00:07:02,680 –> 00:07:04,510
آن عجیب و غریب را برای استفاده مجدد در آینده نقد می کنیم و
196
00:07:04,510 –> 00:07:06,610
در نهایت اقدامی را برای اجرای
197
00:07:06,610 –> 00:07:08,800
محاسبات موازی و تولید
198
00:07:08,800 –> 00:07:11,200
نتایج انجام می دهیم، موضوع بعدی در لیست ما این است.
199
00:07:11,200 –> 00:07:13,300
عجیب و غریب است و مطمئنم افرادی که
200
00:07:13,300 –> 00:07:15,070
قبلاً با اسپارک کار کرده اند
201
00:07:15,070 –> 00:07:16,960
با این اصطلاح آشنا هستند اما برای افرادی که
202
00:07:16,960 –> 00:07:19,510
تازه با آن آشنا هستند اجازه دهید اکنون آن را توضیح دهم یک D
203
00:07:19,510 –> 00:07:21,430
D مخفف دیجیتال در مجموعه داده های توزیع
204
00:07:21,430 –> 00:07:23,650
شده است و به عنوان بلوک سازنده در نظر گرفته می شود
205
00:07:23,650 –> 00:07:25,630
. هر برنامه جرقه ای
206
00:07:25,630 –> 00:07:27,880
دلیل این امر این است که این عناصر
207
00:07:27,880 –> 00:07:29,860
روی چندین گره اجرا می شوند و عمل می کنند تا
208
00:07:29,860 –> 00:07:31,570
پردازش موازی را روی یک خوشه انجام دهند و
209
00:07:31,570 –> 00:07:33,550
یک بار یک چیز عجیب و غریب را تکرار کنید
210
00:07:33,550 –> 00:07:35,860
تغییر ناپذیر می شود و منظور من از تغییرناپذیر این است که
211
00:07:35,860 –> 00:07:38,290
یک شی است که حالت آن را نمی توان
212
00:07:38,290 –> 00:07:40,450
پس از ایجاد تغییر داد، اما ما می توانیم
213
00:07:40,450 –> 00:07:42,460
مقادیر آن را با اعمال
214
00:07:42,460 –> 00:07:44,320
تغییر شکل خاصی تغییر دهیم، آنها توانایی تحمل خطا را قطع کرده اند
215
00:07:44,320 –> 00:07:46,300
و می تواند به طور خودکار
216
00:07:46,300 –> 00:07:49,090
تقریباً از هر شکستی که این
217
00:07:49,090 –> 00:07:52,150
اضافه می کند بازیابی کند. یک مزیت اضافه در حال حاضر برای دستیابی به یک
218
00:07:52,150 –> 00:07:54,130
کار خاص می توان عملیات های متعددی را
219
00:07:54,130 –> 00:07:55,810
روی این شناسه ها اعمال کرد که
220
00:07:55,810 –> 00:07:58,060
به دو صورت دسته بندی می شوند: اولی در
221
00:07:58,060 –> 00:08:00,010
تبدیل و دومی اقداماتی است که
222
00:08:00,010 –> 00:08:02,410
اکنون تبدیل ها
223
00:08:02,410 –> 00:08:03,880
عملیاتی هستند که بر روی یک
224
00:08:03,880 –> 00:08:05,950
عجیب و غریب برای ایجاد یک جدید اعمال می شوند. عجیب بودن
225
00:08:05,950 –> 00:08:07,660
اکنون این تبدیل ها بر اساس
226
00:08:07,660 –> 00:08:09,780
اصل ارزیابی تنبلی کار می کنند و
227
00:08:09,780 –> 00:08:11,890
تبدیل ماهیتا تنبل هستند،
228
00:08:11,890 –> 00:08:14,470
به این معنی که وقتی عملیاتی را در حالت
229
00:08:14,470 –> 00:08:16,720
عجیبی صدا می زنیم، بلافاصله جرقه اجرا نمی
230
00:08:16,720 –> 00:08:18,970
شود، رکورد
231
00:08:18,970 –> 00:08:20,980
عملیاتی را که فراخوانی شده است
232
00:08:20,980 –> 00:08:23,110
با کمک نمودارهای غیر چرخه ای دیالکتیکی حفظ
233
00:08:23,110 –> 00:08:24,850
می کند. همچنین به عنوان AG شناخته می شود
234
00:08:24,850 –> 00:08:26,950
و از آنجایی که تبدیل ها
235
00:08:26,950 –> 00:08:29,680
در طبیعت تنبل هستند، بنابراین w
236
00:08:29,680 –> 00:08:31,480
هنگامی که هر زمان که بخواهید با فراخوانی یک عمل روی
237
00:08:31,480 –> 00:08:33,909
داده ها عملیات را اجرا می کنیم، داده های ارزیابی تنبل
238
00:08:33,909 –> 00:08:36,370
تا زمانی که لازم نباشد بارگذاری نمی شوند و
239
00:08:36,370 –> 00:08:38,559
لحظه ای که عمل را فراخوانی می کنیم، همه
240
00:08:38,559 –> 00:08:40,630
محاسبات به صورت موازی انجام می شود تا
241
00:08:40,630 –> 00:08:43,000
خروجی مورد نظر به شما ارائه شود، اکنون چند
242
00:08:43,000 –> 00:08:44,710
تبدیل مهم عبارتند از:
243
00:08:44,710 –> 00:08:45,520
فهرست
244
00:08:45,520 –> 00:08:48,430
فیلتر flatmap نقشه کاهش یافته توسط پارتیشن نقشه کلید
245
00:08:48,430 –> 00:08:50,860
مرتبسازی بر اساس عملکردها،
246
00:08:50,860 –> 00:08:52,270
عملیاتهایی هستند که به صورت
247
00:08:52,270 –> 00:08:53,620
عجیب و غریب به کار میروند تا
248
00:08:53,620 –> 00:08:55,750
به جرقه دستور اعمال محاسبات را بدهند و
249
00:08:55,750 –> 00:08:57,610
نتیجه را به راننده بازگردانند.
250
00:08:57,610 –> 00:08:59,380
251
00:08:59,380 –> 00:09:00,730
252
00:09:00,730 –> 00:09:03,640
اجازه دهید من چند مورد از
253
00:09:03,640 –> 00:09:06,559
اینها را برای درک بهتر شما پیاده کنم،
254
00:09:06,559 –> 00:09:08,809
بنابراین اول از همه اجازه دهید
255
00:09:08,809 –> 00:09:12,459
فایل RC Bosch را که در مورد آن صحبت می کردم به شما نشان دهم،
256
00:09:16,970 –> 00:09:19,280
بنابراین در اینجا می توانید در باسی که او فایل کرده
257
00:09:19,280 –> 00:09:21,260
است، مسیر را برای همه
258
00:09:21,260 –> 00:09:22,550
فریمورک هایی که در آن نصب کرده ایم را مشاهده کنید.
259
00:09:22,550 –> 00:09:24,560
سیستم را به عنوان مثال می توانید ببینید
260
00:09:24,560 –> 00:09:26,810
که ما در لحظه نصب Hadoop را
261
00:09:26,810 –> 00:09:29,390
نصب کرده ایم و آن را از حالت فشرده خارج می کنیم یا بهتر بگوییم
262
00:09:29,390 –> 00:09:30,020
263
00:09:30,020 –> 00:09:32,360
unpadded من تمام فریمورم را تغییر داده ام ks به یک
264
00:09:32,360 –> 00:09:33,890
مکان خاص همانطور که می
265
00:09:33,890 –> 00:09:36,770
بینید کاربر USR است و در داخل آن ما
266
00:09:36,770 –> 00:09:38,690
کتابخانه داریم و در داخل که من
267
00:09:38,690 –> 00:09:40,700
her2 و همچنین این پارک را نصب کرده ام
268
00:09:40,700 –> 00:09:43,040
اکنون همانطور که می بینید در اینجا دو
269
00:09:43,040 –> 00:09:44,930
خط داریم که این یکی را برجسته می کنم.
270
00:09:44,930 –> 00:09:48,080
شما راننده جرقه PI Python که
271
00:09:48,080 –> 00:09:49,790
trip etre است و ما به آن به عنوان یک
272
00:09:49,790 –> 00:09:52,340
دفترچه یادداشت داده ایم گزینه موجود است توجه داشته باشید
273
00:09:52,340 –> 00:09:54,590
کاری که ما انجام خواهیم داد این است که در لحظه شروع
274
00:09:54,590 –> 00:09:56,840
جرقه من را به طور خودکار
275
00:09:56,840 –> 00:09:59,890
به نوت بوک مشتری هدایت می کند
276
00:10:01,930 –> 00:10:04,210
بنابراین اجازه دهید نام آن را تغییر دهم. این نوت بوک به عنوان یک
277
00:10:04,210 –> 00:10:09,600
آموزش didi است، بنابراین بیایید شروع کنیم، بنابراین
278
00:10:09,600 –> 00:10:12,790
در اینجا برای بارگیری هر فایلی در یک RDD،
279
00:10:12,790 –> 00:10:14,920
فرض کنید که من یک فایل متنی را بارگیری می کنم، باید
280
00:10:14,920 –> 00:10:17,470
از s استفاده کنید اگر یک زمینه جرقه ای است، یک
281
00:10:17,470 –> 00:10:19,870
فایل متنی C نقطه و شما باید آن را ارائه
282
00:10:19,870 –> 00:10:21,730
کنید. مسیر دادههایی که
283
00:10:21,730 –> 00:10:24,250
میخواهید بارگذاری کنید، بنابراین یکی از مواردی که باید در نظر داشته باشید این است که
284
00:10:24,250 –> 00:10:26,589
در مسیر پیشفرضی که ID میگیرد
285
00:10:26,589 –> 00:10:28,300
یا نوتبوک Jupiter،
286
00:10:28,300 –> 00:10:31,180
مسیر HDFS است، بنابراین برای استفاده از
287
00:10:31,180 –> 00:10:32,770
سیستم فایل محلی باید فایل را ذکر کنید.
288
00:10:32,770 –> 00:10:36,100
کولون و اسلش دوبل رو به جلو در حال حاضر
289
00:10:36,100 –> 00:10:39,279
یک بار s ما دادههای فراوانی در داخل دادهها
290
00:10:39,279 –> 00:10:41,560
آماده هستند تا نگاهی به آن بیندازیم.
291
00:10:41,560 –> 00:10:44,650
292
00:10:44,650 –> 00:10:46,060
293
00:10:46,060 –> 00:10:47,830
294
00:10:47,830 –> 00:10:50,320
295
00:10:50,320 –> 00:10:53,410
نمونه داده های گرفته شده در
296
00:10:53,410 –> 00:10:55,779
اینجا مربوط به بلاک چین است، همانطور که می بینید
297
00:10:55,779 –> 00:10:58,350
ما در اینجا یک عنصر دو سه چهار و پنج
298
00:10:58,350 –> 00:11:02,560
داریم.
299
00:11:02,560 –> 00:11:04,570
300
00:11:04,570 –> 00:11:07,180
301
00:11:07,180 –> 00:11:10,000
و در
302
00:11:10,000 –> 00:11:12,550
تابع من این عجیب بودن را منتقل می کنم،
303
00:11:12,550 –> 00:11:13,810
بنابراین همانطور که در اینجا می بینید،
304
00:11:13,810 –> 00:11:15,730
یک افزودنی ایجاد می کنم که یک
305
00:11:15,730 –> 00:11:17,950
عجیب و غریب جدید است و از تابع نقشه استفاده می کنم یا
306
00:11:17,950 –> 00:11:19,660
بهتر بگویم تبدیل و
307
00:11:19,660 –> 00:11:21,670
انتقال تابعی را که
308
00:11:21,670 –> 00:11:25,150
ایجاد کردم برای پایین آوردن و تقسیم کردن آن، بنابراین
309
00:11:25,150 –> 00:11:27,520
اگر به خروجی آگهی خود نگاهی بیندازیم،
310
00:11:27,520 –> 00:11:29,730
311
00:11:30,040 –> 00:11:32,200
بنابراین می توانید اینجا را ببینید که همه کلمات
312
00:11:32,200 –> 00:11:34,210
با حروف کوچک هستند و همه آنها
313
00:11:34,210 –> 00:11:36,210
با کمک یک نوار فاصله از هم جدا شده اند،
314
00:11:36,210 –> 00:11:39,460
اکنون تغییر دیگری وجود دارد که
315
00:11:39,460 –> 00:11:41,350
به عنوان نقشه مسطح برای دادن شناخته می شود شما یک
316
00:11:41,350 –> 00:11:43,600
flat و خروجی دارید و من همان
317
00:11:43,600 –> 00:11:45,790
تابعی را که قبلا ایجاد کردم را منتقل می کنم، بنابراین
318
00:11:45,790 –> 00:11:47,620
اجازه دهید به خروجی این یکی نگاهی بیندازیم،
319
00:11:47,620 –> 00:11:49,540
بنابراین همانطور که می توانید
320
00:11:49,540 –> 00:11:51,520
در اینجا ببینید، ما پنج عنصر اول را دریافت کردیم که همان عنصر
321
00:11:51,520 –> 00:11:54,490
ما هستند.
322
00:11:54,490 –> 00:11:57,280
تراکنشهای کنتراست و
323
00:11:57,280 –> 00:11:59,290
رکوردهای پیشین را به اینجا رساندم، بنابراین فقط یک چیز را در
324
00:11:59,290 –> 00:12:00,760
نظر داشته باشید این است که نقشه مسطح یک
325
00:12:00,760 –> 00:12:02,470
تبدیل است که در آن به عنوان سهام،
326
00:12:02,470 –> 00:12:05,620
عمل اکنون انجام میشود، زیرا میبینید که
327
00:12:05,620 –> 00:12:07,870
محتویات دادههای نمونه حاوی کلمات توقف است،
328
00:12:07,870 –> 00:12:10,060
بنابراین اگر بخواهم حذف تمام
329
00:12:10,060 –> 00:12:12,970
توقفی که باید انجام دهم این است که شروع کنم و
330
00:12:12,970 –> 00:12:14,680
لیستی از کلمات توقف ایجاد کنم که
331
00:12:14,680 –> 00:12:16,690
در اینجا ذکر کردهام، همانطور که میبینید ما یک
332
00:12:16,690 –> 00:12:19,870
333
00:12:19,870 –> 00:12:22,720
کلمه توقف داریم و اکنون اینها همه کلمات توقف نیستند، بنابراین من فقط آن را انتخاب کردم. تعدادی
334
00:12:22,720 –> 00:12:24,190
از آنها فقط برای اینکه به شما نشان
335
00:12:24,190 –> 00:12:26,440
دهیم خروجی دقیقاً چه خواهد بود و اکنون ما در
336
00:12:26,440 –> 00:12:28,690
اینجا از تبدیل فیلتر و
337
00:12:28,690 –> 00:12:30,910
با کمک تابع لامبدا استفاده می کنیم که در آن
338
00:12:30,910 –> 00:12:33,460
X را به عنوان X به عنوان کلمات naught و stop مشخص
339
00:12:33,460 –> 00:12:35,620
کرده ایم و یک عجیب و غریب دیگر ایجاد کرده ایم
340
00:12:35,620 –> 00:12:37,510
که III اضافه شد که
341
00:12:37,510 –> 00:12:40,030
ورودی را از RDD نیز پس بیایید جلو برویم و
342
00:12:40,030 –> 00:12:43,360
ببینیم که آیا و و حذف شده اند یا
343
00:12:43,360 –> 00:12:45,370
نه، بنابراین اگر به خروجی نگاه کنید، می توانید
344
00:12:45,370 –> 00:12:48,340
سوابق تراکنش های قراردادی آنها را
345
00:12:48,340 –> 00:12:50,320
346
00:12:50,320 –> 00:12:53,230
347
00:12:53,230 –> 00:12:55,810
ببینید. من
348
00:12:55,810 –> 00:12:57,700
میخواهم دادهها را بر اساس
349
00:12:57,700 –> 00:13:00,070
سه کاراکتر اول هر عنصر گروهبندی
350
00:13:00,070 –> 00:13:02,200
کنم، بنابراین از برش پی استفاده میکنم
351
00:13:02,200 –> 00:13:04,450
و دوباره از تابع لامبدا استفاده میکنم، بنابراین اجازه دهید
352
00:13:04,450 –> 00:13:06,910
نگاهی به خروجی بیندازیم تا بتوانید ببینید که
353
00:13:06,910 –> 00:13:09,910
EDG داریم و لبهها بنابراین سه
354
00:13:09,910 –> 00:13:12,790
حرف اول هر دو کلمه مشابه هستند،
355
00:13:12,790 –> 00:13:14,560
میتوانیم آن را با استفاده از دو حرف اول پیدا کنیم،
356
00:13:14,560 –> 00:13:17,650
همچنین اجازه دهید آن را به دو تغییر دهم
357
00:13:17,650 –> 00:13:20,440
تا بتوانید ببینید که ما GU و GU ID هستیم
358
00:13:20,440 –> 00:13:23,020
که راهنما است اکنون این
359
00:13:23,020 –> 00:13:25,450
تغییرات اساسی هستند و اقدامات انجام می شود اما
360
00:13:25,450 –> 00:13:27,910
فرض کنید من می خواهم در اینجا مجموع
361
00:13:27,910 –> 00:13:29,860
هزار عدد یا حرف
362
00:13:29,860 –> 00:13:32,200
اول را در اینجا بیابم 10000 عدد تنها کاری که باید
363
00:13:32,200 –> 00:13:34,780
انجام دهم این است که عجیب و غریب دیگری را مقداردهی اولیه کنم که
364
00:13:34,780 –> 00:13:37,300
عجیب بودن زیرخط نوب است و ما از
365
00:13:37,300 –> 00:13:39,820
نقطه AC به صورت موازی استفاده می کنیم و محدوده ای که
366
00:13:39,820 –> 00:13:42,460
داده ایم این است. 1 تا 10.00 0 و ما از
367
00:13:42,460 –> 00:13:45,280
عمل کاهش در اینجا برای دیدن خروجی استفاده
368
00:13:45,280 –> 00:13:48,010
می کنیم. می توانید در اینجا مشاهده کنید. ما مجموع
369
00:13:48,010 –> 00:13:50,740
اعداد از 1 تا 10000 را داریم، اکنون
370
00:13:50,740 –> 00:13:53,830
این همه مربوط به شناسه ما بود. موضوع بعدی
371
00:13:53,830 –> 00:13:56,020
که در لیست داریم پخش و
372
00:13:56,020 –> 00:13:58,300
انباشته ها است. بدانید که در SPARC ما
373
00:13:58,300 –> 00:13:59,950
پردازش موازی را از طریق
374
00:13:59,950 –> 00:14:02,080
متغیرهای مشترک انجام میدهیم یا زمانی که درایور
375
00:14:02,080 –> 00:14:04,210
وظیفهای را ارسال میکند، در صورتی که مجری موجود
376
00:14:04,210 –> 00:14:05,890
در خوشه باشد، یک کپی از متغیر مشترک
377
00:14:05,890 –> 00:14:07,750
نیز به هر
378
00:14:07,750 –> 00:14:09,520
گره خوشه ارسال میشود که دسترسی بالا و تحمل خطا را حفظ میکند.
379
00:14:09,520 –> 00:14:11,920
اکنون
380
00:14:11,920 –> 00:14:13,660
این کار به منظور انجام وظیفه انجام می شود که
381
00:14:13,660 –> 00:14:16,300
یک جرقه آپاچی قرار است متغیرهای مشترک را تایپ کند
382
00:14:16,300 –> 00:14:18,220
که یکی از آنها
383
00:14:18,220 –> 00:14:19,630
پخش می شود و دیگری
384
00:14:19,630 –> 00:14:20,350
انباشته
385
00:14:20,350 –> 00:14:22,810
کننده است. اکنون متغیرهای پخش برای
386
00:14:22,810 –> 00:14:25,030
ذخیره کپی داده ها در تمام گره های یک
387
00:14:25,030 –> 00:14:27,010
خوشه استفاده می شوند، در حالی که Accu major
388
00:14:27,010 –> 00:14:29,080
متغیری است که برای
389
00:14:29,080 –> 00:14:31,150
جمعآوری اطلاعات دریافتی استفاده میشود. ما در
390
00:14:31,150 –> 00:14:32,850
391
00:14:32,850 –> 00:14:35,380
حال حاضر در حال حرکت به موضوع بعدی خود هستیم
392
00:14:35,380 –> 00:14:37,870
که یک پیکربندی جرقه است. سهمیه
393
00:14:37,870 –> 00:14:39,940
کلاس پیکربندی spark مجموعه ای
394
00:14:39,940 –> 00:14:42,070
از پیکربندی ها و پارامترهایی را ارائه می دهد
395
00:14:42,070 –> 00:14:43,600
که برای اجرای یک
396
00:14:43,600 –> 00:14:45,790
برنامه spark در سیستم محلی یا هر
397
00:14:45,790 –> 00:14:47,620
خوشه ای مورد نیاز است، اکنون وقتی از
398
00:14:47,620 –> 00:14:49,660
شی پیکربندی spark برای تنظیم مقادیر
399
00:14:49,660 –> 00:14:52,090
روی این پارامترها استفاده می کنید، اکن