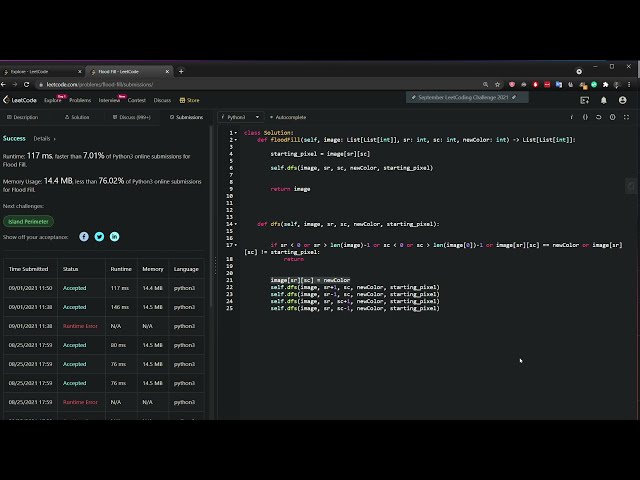
در این مطلب، ویدئو یادگیری ماشین با Qlik Sense با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:
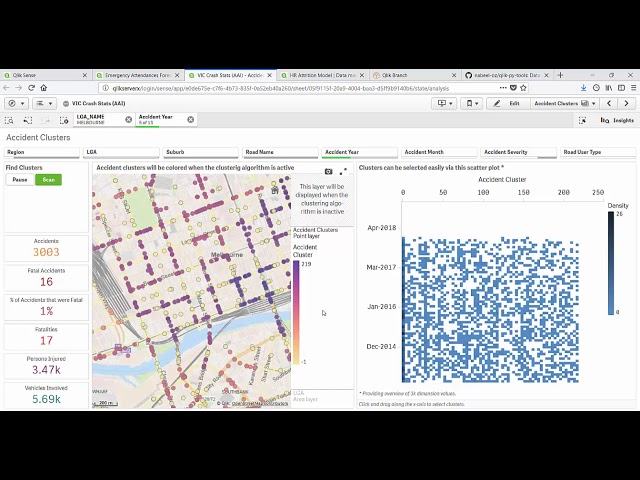


قسمتی از زیرنویس این فیلم:
00:00:04,759 –> 00:00:08,130
سلام، این نابیلا خاموش است از کلیک
2
00:00:08,130 –> 00:00:10,500
استرالیا در این ویدیو،
3
00:00:10,500 –> 00:00:12,809
من برخی از قابلیت های هیجان انگیزی را نشان خواهم داد
4
00:00:12,809 –> 00:00:14,309
که
5
00:00:14,309 –> 00:00:17,760
با استفاده از ادغام ما با کلیک روی دکمه ها، توانسته ام آنها را به کلیک برسانم.
6
00:00:17,760 –> 00:00:20,039
7
00:00:20,039 –> 00:00:21,810
8
00:00:21,810 –> 00:00:24,600
یعنی او می تواند شروع به استفاده از
9
00:00:24,600 –> 00:00:26,699
تجزیه و تحلیل پیش بینی کننده و
10
00:00:26,699 –> 00:00:28,980
الگوریتم های یادگیری ماشینی پیشرفته به عنوان بخشی از
11
00:00:28,980 –> 00:00:31,769
برنامه های کلیکی شما کند.
12
00:00:31,769 –> 00:00:32,930
در اینجا به سه مثال از
13
00:00:32,930 –> 00:00:35,670
پیش بینی خوشه بندی و
14
00:00:35,670 –> 00:00:38,790
یادگیری ماشینی تحت نظارت برنامه ها می روم که به شما نشان
15
00:00:38,790 –> 00:00:41,040
خواهم داد از یک برنامه افزودنی سمت سرور
16
00:00:41,040 –> 00:00:44,340
که من دارم استفاده کنید. ساخته شده در Python که یک
17
00:00:44,340 –> 00:00:46,289
پروژه باز در دسترس است و روی شاخه و github کلیک کنید،
18
00:00:46,289 –> 00:00:50,399
بنابراین اجازه دهید با اولین
19
00:00:50,399 –> 00:00:53,730
مثال خود در اینجا شروع کنیم.
20
00:00:53,730 –> 00:00:55,980
21
00:00:55,980 –> 00:00:59,460
22
00:00:59,460 –> 00:01:01,469
23
00:01:01,469 –> 00:01:05,129
من میخواهم یک
24
00:01:05,129 –> 00:01:08,369
سری زمانی متمرکز برای این کار اضافه کنم،
25
00:01:08,369 –> 00:01:11,130
به حالت ویرایش میروم و اندازهگیری جدیدی به
26
00:01:11,130 –> 00:01:14,790
این نمودار اضافه میکنم که با تایپ نام شروع میکنم.
27
00:01:14,790 –> 00:01:17,400
پسوند سمت سرور من در این مقیاس
28
00:01:17,400 –> 00:01:20,880
در این مورد با ابزارهایی که این
29
00:01:20,880 –> 00:01:23,240
لیستی از چندین قابلیت در دسترس
30
00:01:23,240 –> 00:01:26,460
من را به من می دهد که از الگوریتم
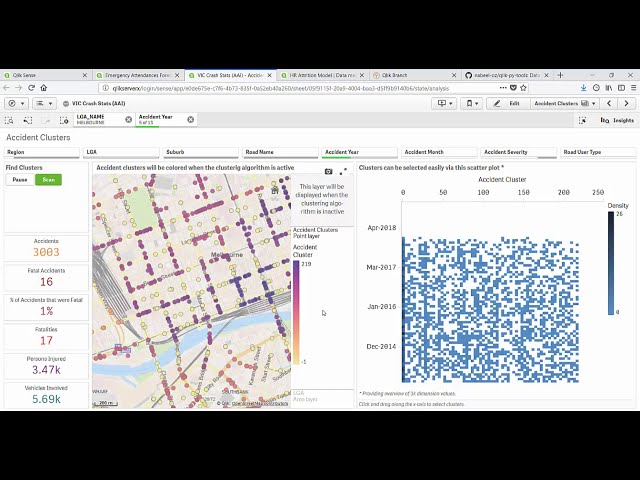
31
00:01:26,460 –> 00:01:29,430
های کتابخانه های پایتون استفاده می کند همه اینها
32
00:01:29,430 –> 00:01:31,829
توابع قابل استفاده مجدد هستند که من با استفاده
33
00:01:31,829 –> 00:01:35,159
از کتابخانه های باز شناخته شده برای آنها ساخته ام.
34
00:01:35,159 –> 00:01:36,900
پیش بینی ما از
35
00:01:36,900 –> 00:01:40,350
تابعی به نام سود استفاده می کنیم که از
36
00:01:40,350 –> 00:01:42,780
کتابخانه سودی که
37
00:01:42,780 –> 00:01:46,009
توسط تیم علم داده فیس بوک
38
00:01:46,009 –> 00:01:48,930
39
00:01:48,930 –> 00:01:51,149
40
00:01:51,149 –> 00:01:53,490
در دسترس است استفاده می کند.
41
00:01:53,490 –> 00:01:55,890
روز بعد تاریخ است در این مورد
42
00:01:55,890 –> 00:01:58,460
معیار شروع ماه است که ما میخواهیم روی آن تمرکز کنیم و
43
00:01:58,460 –> 00:02:01,890
در نهایت هر استدلال اضافی در این
44
00:02:01,890 –> 00:02:04,259
مورد، اکنون که این
45
00:02:04,259 –> 00:02:07,920
دادهها یک فرکانس ماهانه دارند سود میدهیم و بنابراین
46
00:02:07,920 –> 00:02:10,770
ما متمرکز شدهایم این بهترین خط مناسب است
47
00:02:10,770 –> 00:02:13,380
اما چگونه میتوانید این کار را بهبود ببخشید،
48
00:02:13,380 –> 00:02:16,320
ما میتوانیم این کار را به سادگی با
49
00:02:16,320 –> 00:02:18,690
تنظیم پاس پارامترها به تابع خود انجام
50
00:02:18,690 –> 00:02:21,630
دهیم، به عنوان مثال،
51
00:02:21,630 –> 00:02:24,120
میتوانیم گزارشی از مقادیر را در اینجا بگیریم، همانطور که
52
00:02:24,120 –> 00:02:27,510
اغلب در پیشبینیها انجام میشود. ting و می بینیم
53
00:02:27,510 –> 00:02:31,200
که تمرکز ما بهبود یافته است، اکنون
54
00:02:31,200 –> 00:02:33,090
به برگه بعدی خود می روم که در آنجا
55
00:02:33,090 –> 00:02:34,860
عباراتی را برای حد بالا و پایین
56
00:02:34,860 –> 00:02:38,400
به پیش بینی اضافه کرده ام و اکنون
57
00:02:38,400 –> 00:02:40,710
با این سه عبارت می توانید
58
00:02:40,710 –> 00:02:43,440
شروع به استفاده از قدرت سریع کنید زیرا
59
00:02:43,440 –> 00:02:46,230
این برنامه اکنون می تواند به ما برای هر یک
60
00:02:46,230 –> 00:02:48,450
از بیمارستان های موجود در این مجموعه داده متمرکز شود و
61
00:02:48,450 –> 00:02:50,610
می بینید که ما در حال دریافت
62
00:02:50,610 –> 00:02:55,070
نتایج خوبی برای روندهای بسیار متفاوت هستیم و
63
00:02:55,070 –> 00:02:57,630
این قابلیت ها را می توان در
64
00:02:57,630 –> 00:03:00,360
مجموعه های مختلف داده
65
00:03:00,360 –> 00:03:02,940
استفاده کرد. آمار تصادفات جاده ای
66
00:03:02,940 –> 00:03:06,810
از ویکتوریا دوباره
67
00:03:06,810 –> 00:03:09,210
توابع را از سود اعمال کرده ایم و می
68
00:03:09,210 –> 00:03:10,680
بینیم که نتایج خوبی به دست می
69
00:03:10,680 –> 00:03:13,290
آوریم زیرا الگوریتم ما توانسته است
70
00:03:13,290 –> 00:03:15,780
سری زمانی را به اجزای روند
71
00:03:15,780 –> 00:03:19,410
و فصلی تقسیم کند، می توانیم ببینیم
72
00:03:19,410 –> 00:03:21,570
که روند کاملاً صاف است اما
73
00:03:21,570 –> 00:03:25,560
از سال 2016 به بعد نزولی جزئی
74
00:03:25,560 –> 00:03:29,370
داشته است، همچنین میتوانید ببینید که جمعه
75
00:03:29,370 –> 00:03:31,380
بدترین روزی است که باید از
76
00:03:31,380 –> 00:03:34,170
نظر تعداد تصادفات باشد.
77
00:03:34,170 –> 00:03:35,670
تأثیر
78
00:03:35,670 –> 00:03:39,960
تعطیلات بر سریهای زمانی اکنون
79
00:03:39,960 –> 00:03:42,270
اغلب میتوانید چندین تکنیک علم داده
80
00:03:42,270 –> 00:03:44,040
را روی یک مجموعه داده اعمال کنید تا بینش مفیدی به دست آورید،
81
00:03:44,040 –> 00:03:46,920
در این مورد دادهها
82
00:03:46,920 –> 00:03:49,080
برای یادگیری ماشینی بدون نظارت کاملاً مناسب هستند،
83
00:03:49,080 –> 00:03:53,210
بهویژه
84
00:03:53,210 –> 00:03:55,410
خوشهبندی به ما کمک میکند الگوها را
85
00:03:55,410 –> 00:03:57,450
بر اساس شباهت تشخیص دهیم. از
86
00:03:57,450 –> 00:04:00,450
ابعاد و اندازههای مختلف در دادهها در اینجا
87
00:04:00,450 –> 00:04:02,370
میتوانیم به مکانهای تصادف نگاه
88
00:04:02,370 –> 00:04:05,760
کنیم و سعی کنیم خوشههایی از تصادفات را پیدا کنیم، بنابراین
89
00:04:05,760 –> 00:04:07,860
ابتدا از کلیک برای پرسیدن چند
90
00:04:07,860 –> 00:04:09,900
سؤال استفاده میکنیم و در مورد آنچه که
91
00:04:09,900 –> 00:04:13,080
واقعاً به آن علاقهمندیم توضیح میدهیم. میخواهم به
92
00:04:13,080 –> 00:04:15,240
ملبورن که در اینجا نشان داده شده است نگاه کنم. در
93
00:04:15,240 –> 00:04:17,220
تیرهترین رنگ، زیرا بیشترین
94
00:04:17,220 –> 00:04:21,180
تعداد تصادفات را دارد که ما اکنون
95
00:04:21,180 –> 00:04:24,630
به تصادفات فردی اختصاص دادهایم، اجازه دهید
96
00:04:24,630 –> 00:04:27,160
این را به دادههای جدیدتر محدود کنیم،
97
00:04:27,160 –> 00:04:30,020
حالا وقتی دکمه اسکن را فشار میدهم،
98
00:04:30,020 –> 00:04:31,670
درخواستی به یک الگوریتم خوشهبندی
99
00:04:31,670 –> 00:04:34,940
در پایتون ارسال میکنم. الگوها را در این
100
00:04:34,940 –> 00:04:38,750
مجموعه داده پیدا کنید و به آنجا برویم الگوریتم ما
101
00:04:38,750 –> 00:04:42,290
219 خوشه را در محدوده
102
00:04:42,290 –> 00:04:44,870
انتخاب هایمان پیدا کرده و روی رنگ آمیزی هر
103
00:04:44,870 –> 00:04:48,350
خوشه با توجه به آن کلیک می کنیم. برچسب آن اکنون در
104
00:04:48,350 –> 00:04:49,700
این مرحله داده ها هنوز کمی
105
00:04:49,700 –> 00:04:52,610
زیاد است، بنابراین کمی عمیق تر بروید، بگذارید
106
00:04:52,610 –> 00:04:56,570
بگوییم با تمرکز بر تصادفات دوچرخه،
107
00:04:56,570 –> 00:04:58,639
ممکن است متوجه نقاط زرد زیادی روی نقشه ما شوید،
108
00:04:58,639 –> 00:05:01,130
این نقاط پرت هستند
109
00:05:01,130 –> 00:05:03,280
که به هیچ خوشه ای علامت گذاری نشده اند و برچسب
110
00:05:03,280 –> 00:05:07,970
-1 با استفاده از نمودار پراکندگی استاندارد در اینجا
111
00:05:07,970 –> 00:05:10,250
من می توانم این موارد پرت را از
112
00:05:10,250 –> 00:05:12,800
داده ها حذف کنم و آیا ما به خوشه های
113
00:05:12,800 –> 00:05:16,850
تصادفات دوچرخه در ملبورن
114
00:05:16,850 –> 00:05:18,560
کلیک راست می کنیم، می توانید به پرسیدن سوال بعدی ادامه دهید
115
00:05:18,560 –> 00:05:21,380
در این مورد که من بر اساس جدول زمانی در پراکندگی دیدم ادامه دهید.
116
00:05:21,380 –> 00:05:23,600
طرحی که
117
00:05:23,600 –> 00:05:25,490
به نظر می رسد یک خوشه چندین
118
00:05:25,490 –> 00:05:29,570
تصادف در خطاهای اخیر با
119
00:05:29,570 –> 00:05:33,290
انتخاب خوشه داشته است. من متوجه شدم که در
120
00:05:33,290 –> 00:05:36,979
تقاطع لونزدیل و
121
00:05:36,979 –> 00:05:40,550
خیابان الیزابت است، این یک بینش عملی هوشمندانه
122
00:05:40,550 –> 00:05:43,390
است که پیامدهای دنیای واقعی دارد
123
00:05:43,390 –> 00:05:46,039
که با قدرت لرزه های تعاملی امکان پذیر شده است.
124
00:05:46,039 –> 00:05:48,530
تجربه انجمنی و
125
00:05:48,530 –> 00:05:54,530
الگوریتم های تجزیه و تحلیل پیشرفته اکنون اجازه دهید
126
00:05:54,530 –> 00:05:56,720
به نمونه نهایی خود برویم که در مورد
127
00:05:56,720 –> 00:05:59,210
یادگیری ماشینی نظارت شده است در این
128
00:05:59,210 –> 00:06:01,130
مثال یک پیش بینی ایجاد خواهیم کرد. مدل e
129
00:06:01,130 –> 00:06:03,890
با استفاده از دادههای تاریخی و سپس استفاده از آن برای
130
00:06:03,890 –> 00:06:06,800
انجام پیشبینیها، ما از
131
00:06:06,800 –> 00:06:09,080
دادههای نیروی کار استفاده میکنیم که در آن میخواهیم
132
00:06:09,080 –> 00:06:11,030
کارکنانی را که در معرض خطر ترک
133
00:06:11,030 –> 00:06:14,930
سازمان هستند
134
00:06:14,930 –> 00:06:16,610
135
00:06:16,610 –> 00:06:19,039
پیشبینی کنیم. عنصری
136
00:06:19,039 –> 00:06:21,200
که تعیین می کند مدل شما چقدر خوب
137
00:06:21,200 –> 00:06:23,090
کار می کند مجموعه داده های آموزشی و آزمایشی است
138
00:06:23,090 –> 00:06:26,990
که هدف در اینجا ستون ساییدگی است
139
00:06:26,990 –> 00:06:29,990
که کارکنانی را که
140
00:06:29,990 –> 00:06:33,830
در گذشته شرکت را ترک کرده اند در کنار هدف
141
00:06:33,830 –> 00:06:35,659
مشخص می
142
00:06:35,659 –> 00:06:38,940
کند.
143
00:06:38,940 –> 00:06:40,590
ستونها ویژگیهایی نامیده میشوند که
144
00:06:40,590 –> 00:06:44,100
به این ویژگیها نگاه میکنند،
145
00:06:44,100 –> 00:06:46,410
مانند – یک کارمند باید
146
00:06:46,410 –> 00:06:50,010
مسافت نرخ روزانه را از خانه طی کند، این
147
00:06:50,010 –> 00:06:52,740
فیلدهایی هستند که میتوانید به طور کلی پیدا
148
00:06:52,740 –> 00:06:56,640
کنید.
149
00:06:56,640 –> 00:06:58,980
150
00:06:58,980 –> 00:07:02,250
که
151
00:07:02,250 –> 00:07:04,650
در این مورد به ما کمک میکند
152
00:07:04,650 –> 00:07:08,010
تا اکنون یک مدل پیشبینی بسازیم تا
153
00:07:08,010 –> 00:07