در این مطلب، ویدئو ساختن یک سیستم پیوند رکورد مقیاس پذیر با آپاچی اسپارک، پایتون 3 و یادگیری ماشینی با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:04,850 –> 00:00:07,979
بسیار خوب، متشکرم کریس سلام به همه، من
2
00:00:07,979 –> 00:00:09,719
نیک هستم، ادی ادی به همه سلام کنید،
3
00:00:09,719 –> 00:00:10,379
4
00:00:10,379 –> 00:00:12,360
ما از انبوه مشترک هستیم، می خواهیم
5
00:00:12,360 –> 00:00:14,580
به شما در مورد یک سیستم پیوند رکوردی
6
00:00:14,580 –> 00:00:16,440
که به صورت انبوه با استفاده از
7
00:00:16,440 –> 00:00:19,260
اسپارک پایتون 3 و
8
00:00:19,260 –> 00:00:22,970
یادگیری ماشین ساخته ایم به شما بگوییم.
9
00:00:22,970 –> 00:00:25,020
مشکل کسبوکار چیست و خیلی از
10
00:00:25,020 –> 00:00:27,869
شرکتهای دیگر من مطمئن هستم که میخواهند دید جامعی
11
00:00:27,869 –> 00:00:30,150
از مشتریان خود یا حتی
12
00:00:30,150 –> 00:00:32,610
مشتریان بالقوه داشته باشند، چرا آنها به
13
00:00:32,610 –> 00:00:35,520
خوبی میخواهند حداقل از نظر این
14
00:00:35,520 –> 00:00:37,559
پروژه که بیشتر به
15
00:00:37,559 –> 00:00:39,780
آن برای اهداف بازاریابی و بازاریابی علاقه داشتند.
16
00:00:39,780 –> 00:00:42,149
پذیره نویسی بنابراین بازاریابی اگر من
17
00:00:42,149 –> 00:00:44,399
اطلاعات بیشتری در مورد شخصی داشته باشم می توانم
18
00:00:44,399 –> 00:00:45,899
به طور مؤثرتری برای آنها بازاریابی کنم و
19
00:00:45,899 –> 00:00:49,409
محصولات را برای پذیره نویسی انبوه به
20
00:00:49,409 –> 00:00:51,839
آنها بفروشم.
21
00:00:51,839 –> 00:00:54,210
22
00:00:54,210 –> 00:00:55,889
23
00:00:55,889 –> 00:00:57,389
بیمه نامه آنها به
24
00:00:57,389 –> 00:01:00,659
طور موثرتر و سریع تر، بنابراین
25
00:01:00,659 –> 00:01:04,739
مشکل چیست و مشکل این است که
26
00:01:04,739 –> 00:01:06,750
اطلاعات انبوهی که قبلاً
27
00:01:06,750 –> 00:01:09,509
در داخل در مورد فعلی خود دارند و
28
00:01:09,509 –> 00:01:11,820
مشتریان بالقوه در
29
00:01:11,820 –> 00:01:14,219
سیستمهای مختلفی پراکنده شدهاند که تحت مالکیت یا
30
00:01:14,219 –> 00:01:16,500
توسعه تیمهای مختلف در دورههای زمانی مختلف هستند
31
00:01:16,500 –> 00:01:21,119
و هیچ کلید جهانی وجود ندارد که
32
00:01:21,119 –> 00:01:23,219
همه آنها را به هم مرتبط کند که به شما بگوید
33
00:01:23,219 –> 00:01:25,469
این اطلاعات ادی در این
34
00:01:25,469 –> 00:01:27,600
سیستم است و به هر حال اینجا هم ادی است.
35
00:01:27,600 –> 00:01:29,340
اطلاعات موجود در این 10 سیستم دیگر، بنابراین
36
00:01:29,340 –> 00:01:31,109
اکنون می توانید همه آن ها را جمع آوری کنید
37
00:01:31,109 –> 00:01:32,520
و تصویر کاملی از ادی
38
00:01:32,520 –> 00:01:36,659
داشته باشید، چنین چیزی وجود ندارد و البته ما
39
00:01:36,659 –> 00:01:39,929
نمی توانیم به سادگی یک تساوی انجام دهیم و به
40
00:01:39,929 –> 00:01:42,780
یک مشترک برابری ساده لوحانه در همه این موارد بپیوندیم،
41
00:01:42,780 –> 00:01:43,619
زیرا وجود دارد همیشه
42
00:01:43,619 –> 00:01:45,509
تغییرات و نحوه
43
00:01:45,509 –> 00:01:47,490
ثبت اطلاعات یک شخص برای آسیایی ها
44
00:01:47,490 –> 00:01:50,130
و نام و آدرس به ویژه به طوری
45
00:01:50,130 –> 00:01:51,420
که مشکل کسب و کار چیست
46
00:01:51,420 –> 00:01:55,140
چالش فنی در اینجا خوب ما
47
00:01:55,140 –> 00:01:58,310
حدود 330 میلیون رکورد در مورد
48
00:01:58,310 –> 00:02:01,979
مشتریان داریم که افراد دیگر را قبلاً
49
00:02:01,979 –> 00:02:06,030
داخلی به MassMutual هدایت می کند که این
50
00:02:06,030 –> 00:02:07,619
رکوردها پراکنده هستند در
51
00:02:07,619 –> 00:02:09,330
طیف گسترده ای از سیستم ها که
52
00:02:09,330 –> 00:02:12,900
طرحواره های متفاوتی دارند و غیره دوباره
53
00:02:12,900 –> 00:02:14,760
کلید جهانی a وجود ندارد درصد بسیار کمی
54
00:02:14,760 –> 00:02:16,170
از این سوابق ممکن است
55
00:02:16,170 –> 00:02:16,930
دارای SSN
56
00:02:16,930 –> 00:02:19,060
شماره امنیت اجتماعی آن
57
00:02:19,060 –> 00:02:21,370
افراد باشد و آشور شما می
58
00:02:21,370 –> 00:02:23,260
توانید از آن به عنوان یک شناسه جهانی برای پیوند دادن
59
00:02:23,260 –> 00:02:25,299
سوابق بین سیستم ها استفاده کنید، اما
60
00:02:25,299 –> 00:02:26,890
واقعاً درصد کمی از سوابق است
61
00:02:26,890 –> 00:02:29,680
که این اطلاعات را در دسترس دارند و همچنین ما
62
00:02:29,680 –> 00:02:31,959
زیرساخت تجزیه و تحلیل فعلی یا
63
00:02:31,959 –> 00:02:35,200
خط لوله قادر به انجام
64
00:02:35,200 –> 00:02:37,180
استخراج تفاضلی از این سیستم های منبع نیست،
65
00:02:37,180 –> 00:02:38,920
این سیستم های زنده هستند که روزانه در حال تغییر هستند،
66
00:02:38,920 –> 00:02:41,260
بنابراین ما هیچ راهی برای گفتن روزانه نداریم،
67
00:02:41,260 –> 00:02:43,359
فقط چیزهایی را
68
00:02:43,359 –> 00:02:45,730
که تغییر کرده یا متفاوت هستند به من بدهید، بنابراین اگر می
69
00:02:45,730 –> 00:02:47,319
خواهیم انجام دهیم. نوعی پیوند رکورد جهانی
70
00:02:47,319 –> 00:02:49,840
در داراییهای داده موجود انبوه Mutual
71
00:02:49,840 –> 00:02:51,909
که به این معنی است که ما باید
72
00:02:51,909 –> 00:02:53,950
همه چیز را به کار بگیریم و هر شب یک پیوند جهانی
73
00:02:53,950 –> 00:02:57,400
در کل چیز انجام دهیم، بنابراین
74
00:02:57,400 –> 00:03:01,870
این یک چالش فنی است، بنابراین برخی
75
00:03:01,870 –> 00:03:04,599
از هنرهای قبلی را خیلی سریع در پیوند رکورد پوشش خواهم داد.
76
00:03:04,599 –> 00:03:06,879
منطقه ای وجود دارد که یک
77
00:03:06,879 –> 00:03:09,879
کتابخانه پایتون به نام dedupe وجود دارد که در واقع
78
00:03:09,879 –> 00:03:12,549
یک کسب و کار یا محصول مرتبط دارد، شما می
79
00:03:12,549 –> 00:03:14,829
دانید که می توانید واقعی من هزینه می کنم
80
00:03:14,829 –> 00:03:16,090
اما کتابخانه اصلی کتابخانه منبع باز است.
81
00:03:16,090 –> 00:03:18,730
82
00:03:18,730 –> 00:03:20,409
تا آنجا که من می توانم بگویم یک کتابخانه بسیار بالغ و پیچیده است،
83
00:03:20,409 –> 00:03:24,250
اما فکر می کنم و خیلی
84
00:03:24,250 –> 00:03:25,239
عمیق به این موضوع نگاه نکردم، این در
85
00:03:25,239 –> 00:03:26,919
واقع توسط تیمی که قبل از من آمده بود، مورد تحقیق قرار گرفت.
86
00:03:26,919 –> 00:03:29,680
پردازش dduk
87
00:03:29,680 –> 00:03:32,260
محلی است، بنابراین تیمی که
88
00:03:32,260 –> 00:03:34,720
قبل از آمدن من این کتابخانه را برای این مشکل
89
00:03:34,720 –> 00:03:35,439
90
00:03:35,439 –> 00:03:37,510
ارزیابی میکردند، متوجه شدند که اساساً
91
00:03:37,510 –> 00:03:39,970
به سطحی نمیرسد که ما به
92
00:03:39,970 –> 00:03:43,750
قطعه دیگری از هنر قبلی نیاز داریم، سیستمی است که
93
00:03:43,750 –> 00:03:45,609
در خانه ساخته شده است. توده متقابل به نام
94
00:03:45,609 –> 00:03:50,019
splink or – این سیستم بر
95
00:03:50,019 –> 00:03:53,979
روی apache sparks RDD api در اواخر سال 2015 در
96
00:03:53,979 –> 00:03:58,810
اوایل سال 2016 ساخته شد و یکسری
97
00:03:58,810 –> 00:04:00,340
مشکلات داشت و اجرای آن خیلی طول کشید
98
00:04:00,340 –> 00:04:03,549
، خیلی پایدار نبود.
99
00:04:03,549 –> 00:04:05,709
مردم
100
00:04:05,709 –> 00:04:07,329
از کیفیت پیوند راضی نبودند،
101
00:04:07,329 –> 00:04:11,079
اما ساختن سیستم به عنوان
102
00:04:11,079 –> 00:04:13,180
نوعی آزمایش موفق ثابت کرد که بله،
103
00:04:13,180 –> 00:04:15,609
ما میتوانیم نوعی پیوند رکورد جهانی را
104
00:04:15,609 –> 00:04:19,089
در مقیاس انجام دهیم، اما فقط اکنون
105
00:04:19,089 –> 00:04:20,858
باید از آن درس بگیریم و ب
106
00:04:20,858 –> 00:04:22,830
چیزی را بسازید که برای تولید آمادهتر بود،
107
00:04:22,830 –> 00:04:25,930
بنابراین Spliter 3 در یک
108
00:04:25,930 –> 00:04:28,660
سیستم کاملاً جدید وارد میشود که ما
109
00:04:28,660 –> 00:04:32,740
MassMutual را ساختیم و
110
00:04:32,740 –> 00:04:35,680
از همان ابتدا Sparks frame data API را هدف قرار دادیم و هدف این
111
00:04:35,680 –> 00:04:38,140
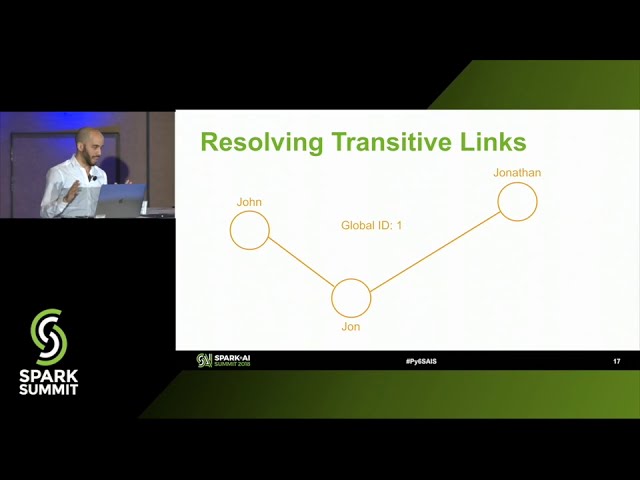
بود که یک سیستم پیوندی رکورد آماده تولید بسازیم
112
00:04:38,140 –> 00:04:39,790
و از همه
113
00:04:39,790 –> 00:04:42,130
درسها استفاده کنیم. که ما از ساخت کلینکر یاد گرفتیم
114
00:04:42,130 –> 00:04:45,880
– بنابراین قبل از اینکه به
115
00:04:45,880 –> 00:04:49,060
جزئیات نحوه ساخت Slinker 3 و
116
00:04:49,060 –> 00:04:51,220
آنچه انجام می دهد بپردازم، اجازه دهید در مورد
117
00:04:51,220 –> 00:04:53,620
پیوند رکورد به طور انتزاعی صحبت کنیم
118
00:04:53,620 –> 00:04:55,120
که انجام پیوند رکورد به چه معناست مراحل اساسی چیست،
119
00:04:55,120 –> 00:04:58,030
بنابراین ابتدا شروع می کنیم با
120
00:04:58,030 –> 00:05:00,640
این منابع داده های متنوع و درهم و برهم که
121
00:05:00,640 –> 00:05:03,130
همگی می توانند حاوی بیت های مختلفی از
122
00:05:03,130 –> 00:05:05,200
اطلاعات مشتری، طرحواره ها
123
00:05:05,200 –> 00:05:07,240
و ساختارهای مختلف باشند و ما می خواهیم همه آنها را
124
00:05:07,240 –> 00:05:08,590
در یک مکان جمع کنیم و به نوعی
125
00:05:08,590 –> 00:05:11,110
ساختار را استاندارد کنیم تا
126
00:05:11,110 –> 00:05:12,940
همه چیز در قالب یکسان
127
00:05:12,940 –> 00:05:16,510
باشد تا بتوانیم یک بار با آن کار کنیم. ما
128
00:05:16,510 –> 00:05:20,080
داریم که میخواهیم یک جفت آدم بسازیم
129
00:05:20,080 –> 00:05:22,870
که بعد برویم و بیایم و ارزیابی کنیم که بگوییم
130
00:05:22,870 –> 00:05:25,240
این دو نفر یک نفر هستند، این دو نفر
131
00:05:25,240 –> 00:05:27,250
چطور؟ e و غیره بنابراین
132
00:05:27,250 –> 00:05:28,780
ما به روشی برای ایجاد جفت
133
00:05:28,780 –> 00:05:30,700
افراد برای ارزیابی نیاز داریم و هر جفت برای هر
134
00:05:30,700 –> 00:05:32,770
جفت از افرادی که ارزیابی می کنیم، می خواهیم
135
00:05:32,770 –> 00:05:35,320
به آنها یک امتیاز اختصاص دهیم و بگوییم بله شما
136
00:05:35,320 –> 00:05:37,600
همتا هستید یا نه شما همتا نیستید بله ما
137
00:05:37,600 –> 00:05:39,400
فکر کنید که شما همان فرد هستید یا
138
00:05:39,400 –> 00:05:42,550
به همان شخص مراجعه می کنید یا نه، و
139
00:05:42,550 –> 00:05:45,280
وقتی همه چیز را به دست آوردیم، مرحله نهایی
140
00:05:45,280 –> 00:05:48,520
حل کردن پیوندهای متعدی است، بنابراین من بعداً در
141
00:05:48,520 –> 00:05:49,930
مورد این موضوع بیشتر صحبت خواهم کرد، اما اساساً اگر
142
00:05:49,930 –> 00:05:52,090
ضبط a به رکورد B مرتبط شود و
143
00:05:52,090 –> 00:05:54,910
رکورد B به رکورد C پیوند خورده است، اما
144
00:05:54,910 –> 00:05:57,010
هیچ پیوند مستقیمی از A به C وجود ندارد، ما
145
00:05:57,010 –> 00:05:58,960
هنوز می خواهیم بدانیم که B و
146
00:05:58,960 –> 00:06:01,419
C احتمالاً یک فرد هستند، بنابراین ما
147
00:06:01,419 –> 00:06:03,430
به روشی برای شناسایی این
148
00:06:03,430 –> 00:06:05,500
پیوندهای گذرا و در نظر گرفتن کل گروه به عنوان یک
149
00:06:05,500 –> 00:06:08,560
کل نیاز داریم. و گفتن اینکه شما یک نفر هستید، بنابراین
150
00:06:08,560 –> 00:06:11,440
این کل نوع طراحی
151
00:06:11,440 –> 00:06:14,200
انتزاعی پیوند رکورد است، بنابراین بیایید
152
00:06:14,200 –> 00:06:18,060
در هر مرحله به هر کدام نگاه کنیم، ابتدا
153
00:06:18,060 –> 00:06:19,930
دادههای دریافتی را استاندارد میکنیم.
154
00:06:19,930 –> 00:06:20,980
155
00:06:20,980 –> 00:06:22,690
156
00:06:22,690 –> 00:06:24,400
یک بحث کاملا جداگانه در مورد هو شما
157
00:06:24,400 –> 00:06:27,190
باید منابع مختلفی را
158
00:06:27,190 –> 00:06:28,540
که در حال مصرف آنها هستید مدیریت کنید و
159
00:06:28,540 –> 00:06:30,310
تغییرات مورد نیاز برای استانداردسازی
160
00:06:30,310 –> 00:06:31,330
را ردیابی کنید، من فکر می کنم که می تواند بحث جالبی باشد،
161
00:06:31,330 –> 00:06:33,310
اما من فقط یک
162
00:06:33,310 –> 00:06:35,500
مثال کوتاه در اینجا می زنم تصور کنید یک
163
00:06:35,500 –> 00:06:37,330
مجموعه داده دارید که در آن نام کامل
164
00:06:37,330 –> 00:06:39,730
به عنوان یک ستون نشان
165
00:06:39,730 –> 00:06:41,530
داده می شود و داده دیگری می گوید که نام
166
00:06:41,530 –> 00:06:43,690
به دو نام و نام خانوادگی تقسیم شده است یا
167
00:06:43,690 –> 00:06:46,030
فایل فشرده در یک مجموعه داده فقط زیپ است، اما
168
00:06:46,030 –> 00:06:47,980
در مجموعه داده دیگر، زیپ به اضافه
169
00:06:47,980 –> 00:06:51,640
چهار است، بنابراین ما می خواهیم آن ها را به داخل بکشیم. یک
170
00:06:51,640 –> 00:06:53,470
جدول واحد و سپس ساختار را استاندارد کنید
171
00:06:53,470 –> 00:06:54,850
تا فیلدها یکسان باشند
172
00:06:54,850 –> 00:06:57,700
که دادههای داخل فیلدها از نظر معنایی
173
00:06:57,700 –> 00:07:00,840
معنی یکسانی داشته باشند، بنابراین مرحله یک
174
00:07:00,840 –> 00:07:04,000
مرحله دوم تولید جفتها است، بنابراین
175
00:07:04,000 –> 00:07:05,830
ما همه رکوردهای خود را در یک مکان
176
00:07:05,830 –> 00:07:07,960
آوردهایم و اکنون طرحواره یکسانی دارند.
177
00:07:07,960 –> 00:07:10,210
برای ارزیابی باید جفت رکورد تولید کنیم
178
00:07:10,210 –> 00:07:13,060
و ممکن است فکر کنید خوب است، این یک
179
00:07:13,060 –> 00:07:14,770
جمله ساده است که فقط تمام رکوردهای خود را بردارید
180
00:07:14,770 –> 00:07:17,230
و همه جفت های ممکن را درست ایجاد
181
00:07:17,230 –> 00:07:19,780
کنید، مشکل زمانی است که شما
182
00:07:19,780 –> 00:07:21,490
سیصد و یکمین رکورد دارید. سی میلیون رکورد
183
00:07:21,490 –> 00:07:24,100
که ساده لوحانه همه جفتهای ممکن را
184
00:07:24,100 –> 00:07:26,050
برای ارزیابی
185
00:07:26,050 –> 00:07:29,200
تولید میکند به این معنی است که شما 10 تا 16 جفت را تولید میکنید و این
186
00:07:29,200 –> 00:07:32,320
برای من خیلی زیاد است که هر سیستمی بتواند
187
00:07:32,320 –> 00:07:34,210
حتی جرقه را به طور موثر ارزیابی کند،
188
00:07:34,210 –> 00:07:37,540
بنابراین آنچه ما نیاز داریم
189
00:07:37,540 –> 00:07:41,080
نوعی اکتشافی است. یک میانبر را فریب دهید
190
00:07:41,080 –> 00:07:43,390
تا سریعاً این 10
191
00:07:43,390 –> 00:07:45,430
جفت را به 16 جفت تولید شده کاهش دهید تا به چیزی بسیار
192
00:07:45,430 –> 00:07:47,950
معقول تر بدون از دست دادن تعداد زیادی از
193
00:07:47,950 –> 00:07:50,950
مسابقات واقعی، همانطور که ما این کار را در Slinker 3 انجام می دهیم،
194
00:07:50,950 –> 00:07:53,290
که جدید نیست، بلکه
195
00:07:53,290 –> 00:07:55,260
آن را از جای دیگری گرفته ایم. مطمئن شوید که
196
00:07:55,260 –> 00:07:57,220
افراد دیگر
197
00:07:57,220 –> 00:08:00,250
ایدههای مشابهی را با استخراج یک کلید مسدودکننده از
198
00:08:00,250 –> 00:08:03,490
هر رکورد اجرا کردهاند و کاری که ما انجام میدهیم این است
199
00:08:03,490 –> 00:08:05,650
که جفتها را فقط برای رکوردهایی ایجاد میکنیم که
200
00:08:05,650 –> 00:08:07,710
کلید مسدودکننده مشابهی دارند.
201
00:08:07,710 –> 00:08:09,750
202
00:08:09,750 –> 00:08:13,690
203
00:08:13,690 –> 00:08:17,710
خیابان و برای اهداف این
204
00:08:17,710 –> 00:08:19,720
مثال، کلید مسدود کردن من
205
00:08:19,720 –> 00:08:21,490
حرف اول نام،
206
00:08:21,490 –> 00:08:23,470
حرف اول نام خانوادگی و کد پستی است،
207
00:08:23,470 –> 00:08:26,950
بنابراین کلید مسدود کننده در این
208
00:08:26,950 –> 00:08:28,630
حالت اضافه می شود. کلید مسدودکننده را از هر رکورد ct کنید،
209
00:08:28,630 –> 00:08:32,289
به عنوان مثال، اگر من
210
00:08:32,289 –> 00:08:34,630
رکورد دیگری مانند جانسون ری در
211
00:08:34,630 –> 00:08:36,760
همان کد پستی
212
00:08:36,760 –> 00:08:38,950
داشته باشم، این شخص همان کلید مسدودکننده را دارد، بنابراین من جان
213
00:08:38,950 –> 00:08:40,720
رابرتز و جاناتان رایت را با هم جفت کنم و
214
00:08:40,720 –> 00:08:42,370
در واقع ارزیابی دقیق تری انجام دهم
215
00:08:42,370 –> 00:08:44,620
تا ببینم آیا یا نه، ما فکر می کنیم که
216
00:08:44,620 –> 00:08:45,880
آنها همان فرد هستند یا نه،
217
00:08:45,880 –> 00:08:48,010
اما اگر من رکورد دیگری مانند فرانک
218
00:08:48,010 –> 00:08:51,130
سیناترا در 0 7 یا هر چیز دیگری داشته باشم، واضح است
219
00:08:51,130 –> 00:08:52,120
که آن شخص
220
00:08:52,120 –> 00:08:53,620
همان کلید مسدود کننده را دریافت نمی کند، بنابراین من
221
00:08:53,620 –> 00:08:55,660
حتی یک جفت برای ارزیابی در
222
00:08:55,660 –> 00:08:59,170
اول ایجاد نمی کنم. در حال حاضر برای افرادی که بیشتر
223
00:08:59,170 –> 00:09:01,569
علم دادهگرا هستند در میان جمعیت قرار دهید،
224
00:09:01,569 –> 00:09:03,939
میتوانید مسدود کردن را بهعنوان یک
225
00:09:03,939 –> 00:09:06,160
مدل بسیار خام یا مانند یک
226
00:09:06,160 –> 00:09:08,079
مدل پیش پردازش تقریباً برای
227
00:09:08,079 –> 00:09:10,360
پیشبینی مواردی که میخواهیم
228
00:09:10,360 –> 00:09:13,180
نرخ فراخوان مدل نزدیک به 1.0 باشد، در نظر بگیرید.
229
00:09:13,180 –> 00:09:15,670
تا آنجا که ممکن است، اما ما به
230
00:09:15,670 –> 00:09:17,620
دقت مدل اهمیتی نمی
231
00:09:17,620 –> 00:09:19,360
دهیم، اگر نکات مثبت کاذب زیادی
232
00:09:19,360 –> 00:09:22,300
در آن وجود داشته باشد، اشکالی ندارد، اما مهمتر از همه، ما می خواهیم
233
00:09:22,300 –> 00:09:25,749
این مدل خام که مانع
234
00:09:25,749 –> 00:09:28,779
از آن می شود فضای جستجو را به شدت کاهش دهد. و
235
00:09:28,779 –> 00:09:30,759
در مورد splinter 3 کلید مسدود کننده ای
236
00:09:30,759 –> 00:09:31,990
که در نهایت از آن استفاده کردیم بسیار
237
00:09:31,990 –> 00:09:33,129
شبیه به چیزی است که من به شما نشان
238
00:09:33,129 –> 00:09:35,199
دادم.
239
00:09:35,199 –> 00:09:37,660
240
00:09:37,660 –> 00:09:40,089
هشتمین یا
241
00:09:40,089 –> 00:09:42,850
به عبارت دقیق تر از 300 تا 30
242
00:09:42,850 –> 00:09:44,170
میلیون رکورد،
243
00:09:44,170 –> 00:09:47,829
ما حدود 680 میلیون جفت برای
244
00:09:47,829 –> 00:09:51,809
ارزیابی دقیق به دست آوردیم، بنابراین
245
00:09:51,809 –> 00:09:53,769
جفت ها تولید می شوند و چیز عالی
246
00:09:53,769 –> 00:09:56,350
در مورد کار با جرقه این است
247
00:09:56,350 –> 00:09:58,059
که آنچه را که در اینجا توضیح دادم، تکنیک های مسدود کردن را پیاده سازی می کنیم.
248
00:09:58,059 –> 00:10:00,339
249
00:10:00,339 –> 00:10:03,790
ایجاد جفت
250
00:10:03,790 –> 00:10:06,490
در API قاب داده بسیار ساده و ظریف است، بنابراین اگر
251
00:10:06,490 –> 00:10:08,980
من یک UDF داشته باشم که از
252
00:10:08,980 –> 00:10:11,319
قبل منطق استخراج یک کلید مسدود کننده از یک
253
00:10:11,319 –> 00:10:14,050
رکورد داده شده را دارد و من قبلاً یک
254
00:10:14,050 –> 00:10:16,540
قاب داده از افراد دارم، به سادگی می گویم افراد
255
00:10:16,540 –> 00:10:18,550
با ستون نقطه می کنند. و سپس من می توانم ضمیمه کنم
256
00:10:18,550 –> 00:10:20,860
و شما آنها را
257
00:10:20,860 –> 00:10:22,779
با افرادی که کلید مسدود کننده
258
00:10:22,779 –> 00:10:25,899
را به انتهای آن وصل کرده اند برای
259
00:10:25,899 –> 00:10:28,329
ایجاد جفت هایی که این
260
00:10:28,329 –> 00:10:30,939
فریم داده از افراد مسدود شده را انتخاب می کنم و به سادگی به آنها ملحق می شوم، به فریم داده اصلی من فراخوانی کنید.
261
00:10:30,939 –> 00:10:33,429
آن را روی کلید مسدود کننده ای که من همین
262
00:10:33,429 –> 00:10:36,519
الان استخراج کردم، خودش را نشان می دهد و سپس من
263
00:10:36,519 –> 00:10:38,259
مقداری در اینجا در عبارت Where فقط
264
00:10:38,259 –> 00:10:40,269
برای حذف جفت های تکراری
265
00:10:40,269 –> 00:10:42,939
دارم، به طوری که اگر جفت B داشتم، یک جفت B را نیز ایجاد نکنم همین.
266
00:10:42,939 –> 00:10:45,720
اما همین است و
267
00:10:45,720 –> 00:10:48,189
شاید برای برخی از شما خیلی
268
00:10:48,189 –> 00:10:50,350
جالب نیست، اما برای
269
00:10:50,350 –> 00:10:53,259
من وقتی این را فهمیدم
270
00:10:53,259 –> 00:10:55,509
واقعاً نمیدانم راضی هستم،
271
00:10:55,509 –> 00:10:58,509
شما خوشحال میشوید زیرا به نظر
272
00:10:58,509 –> 00:11:00,790
واقعاً شیک بود، یک روش بسیار زیبا برای
273
00:11:00,790 –> 00:11:03,199
گرفتن عکس منطق یک روش بسیار
274
00:11:03,199 –> 00:11:05,540
تمیز برای ثبت آنچه در کد فکر میکردم
275
00:11:05,540 –> 00:11:07,339
است و فکر میکنم این بخشی از
276
00:11:07,339 –> 00:11:09,290
زیبایی کار با یک
277
00:11:09,290 –> 00:11:13,369
API به سبک اعلانی مانند API قاب داده است،
278
00:11:13,369 –> 00:11:16,189
بنابراین تولید جفتها، ما
279
00:11:16,189 –> 00:11:17,899
تولید همه جفتهای ممکن افراد را به پایان رساندهایم.
280
00:11:17,899 –> 00:11:19,429
ما میخواهیم ارزیابی کنیم و
281
00:11:19,429 –> 00:11:23,149
حالا میخواهیم شناسایی کنیم که کدام جفت
282
00:11:23,149 –> 00:11:26,509
به یک شخص اشاره دارد یا نه، پس
283
00:11:26,509 –> 00:11:28,819
چگونه میتوانیم یک
284
00:11:28,819 –> 00:11:31,009
مدل رگرسیون لجستیک داشته باشیم که
285
00:11:31,009 –> 00:11:34,459
ارزیابی ما این مدل را در
286
00:11:34,459 –> 00:11:36,379
زیر مجموعه بسیار کوچکی از رکوردهایی که انجام میدهیم انجام میدهد.
287
00:11:36,379 –> 00:11:38,029
در MassMutual که دارای
288
00:11:38,029 –> 00:11:40,309
شماره تامین اجتماعی هستند و بنابراین ما از
289
00:11:40,309 –> 00:11:43,429
SSN به عنوان برچسب استفاده می کنیم که برچسب
290
00:11:43,429 –> 00:11:45,499
واقعی چه کسی واقعاً همان شخص است و
291
00:11:45,499 –> 00:11:49,489
چه کسی نیست و فقط یک مرور سریع
292
00:11:49,489 –> 00:11:53,600
از ویژگی های مدل ما
293
00:11:53,600 –> 00:11:55,939
شباهت آوایی را با هم مقایسه می کنیم. نام و
294
00:11:55,939 –> 00:11:57,949
شهر را با فاصله
295
00:11:57,949 –> 00:11:59,899
رشته نام و آدرس در شهر مقایسه می
296
00:11:59,899 –> 00:12:02,209
کنیم و همچنین مطابقت دقیق روی حالت
297
00:12:02,209 –> 00:12:04,009
و zip انجام می دهیم اکنون جزئیات
298
00:12:04,009 –> 00:12:05,209
ویژگی هایی که باید استخراج شوند
299
00:12:05,209 –> 00:12:06,980
مهم نیستند فقط می خواهم به شما مهربان نشان دهم
300
00:12:06,980 –> 00:12:08,989
از ساختار نحوه برخورد ما با
301
00:12:08,989 –> 00:12:10,879
مشکل و این هیجان انگیز یا
302
00:12:10,879 –> 00:12:12,110
بدیع نیست، فکر نمی کنم حتی بهترین
303
00:12:12,110 –> 00:12:13,759
راه برای انجام این کار باشد، اما این چیزی است که ما
304
00:12:13,759 –> 00:12:18,739
کم و بیش داریم و یک فریاد سریع به یک
305
00:12:18,739 –> 00:12:21,139
کتابخانه بسیار مفید پایتون که ما داریم ما
306
00:12:21,139 –> 00:12:24,019
برای دسترسی به
307
00:12:24,019 –> 00:12:25,850
الگوریتمهای رمزگذاری آوایی مانند متا تلفن یا
308
00:12:25,850 –> 00:12:28,249
صدا Dex و الگوریتمهای فاصله رشتهای
309
00:12:28,249 –> 00:12:30,949
مانند جری وینکلر و لونشتاین استفاده میکنیم.
310
00:12:30,949 –> 00:12:33,529
311
00:12:33,529 –> 00:12:36,339
312
00:12:36,339 –> 00:12:38,929
e فقط یک مثال است فقط
313
00:12:38,929 –> 00:12:41,360
برای نشان دادن برخی از دادههای نمونه که
314
00:12:41,360 –> 00:12:43,249
جان جونز و جاناتان جونز را
315
00:12:43,249 –> 00:12:45,079
تقریباً با همان آدرس میشناسید، ما
316
00:12:45,079 –> 00:12:47,629
آنها را به عنوان تطابق علامتگذاری میکنیم، اما جان جونز و جان
317
00:12:47,629 –> 00:12:49,069
جونز با آدرس خیابان
318
00:12:49,069 –> 00:12:50,209
متفاوتی میگوییم نه، نه. فکر کنید
319
00:12:50,209 –> 00:12:50,959
آنها یک فرد هستند
320
00:12:50,959 –> 00:12:53,119
و البته جان جونز و جانت
321
00:12:53,119 –> 00:12:54,499
جکسون قطعاً یک شخص نیستند،
322
00:12:54,499 –> 00:12:55,999
حتی اگر ممکن است
323
00:12:55,999 –> 00:13:00,199
با هم مسدود شده باشند، بنابراین ما همه رکوردها را
324
00:13:00,199 –> 00:13:01,999
به صورت یکپارچه به دست آورده ایم و
325
00:13:01,999 –> 00:13:04,579
دو جفت ساخته شده است. ما هر
326
00:13:04,579 –> 00:13:06,230
جفت را ارزیابی کردیم و گفتیم شما همان فرد
327
00:13:06,230 –> 00:13:08,119
هستید نه شما همان فرد نیستید، مرحله آخر
328
00:13:08,119 –> 00:13:10,039
حل کردن پیوندهای انتقالی است،
329
00:13:10,039 –> 00:13:12,559
بنابراین من به طور خلاصه این را معرفی کردم،
330
00:13:12,559 –> 00:13:15,589
بگذارید خلاصه کنیم تصور کنید من سه رکورد دارم که
331
00:13:15,589 –> 00:13:17,330
آنها
332
00:13:17,330 –> 00:13:19,850
به این روش پیوند داده شده اند. اما اگر من به هر لینک
333
00:13:19,850 –> 00:13:21,680
به صورت مجزا نگاه کنم و بگویم که
334
00:13:21,680 –> 00:13:24,050
ID جهانی خود را به شما میدهم،
335
00:13:24,050 –> 00:13:26,030
واقعاً مشکل را حل نمیکنم که این است که
336
00:13:26,030 –> 00:13:28,340
میخواهم یک دید جهانی از همه کسانی که
337
00:13:28,340 –> 00:13:30,710
با هم مرتبط شدهاند داشته باشند، میخواهم همه آنها را
338
00:13:30,710 –> 00:13:32,840
دریافت یک شناسه واحد بنابراین اگر این سه افراد
339
00:13:32,840 –> 00:13:34,820
با هم مرتبط شدند من می خواهم همه
340
00:13:34,820 –> 00:13:36,710
آنها یک شناسه داشته باشند زیرا اساساً می خواهم
341
00:13:36,710 –> 00:13:39,560
آنها را به عنوان یک شخص شناسایی کنم بنابراین
342
00:13:39,560 –> 00:13:40,820
آنچه واقعاً می خواهم این است که به جای داشتن یک
343
00:13:40,820 –> 00:13:43,670
شناسه گروهی یک شناسه جهانی و یک شناسه جهانی
344
00:13:43,670 –> 00:13:46,580
بنویسم آنچه واقعاً می خواهم. آیا همه
345
00:13:46,580 –> 00:13:48,920
آنها به عنوان جان
346
00:13:48,920 –> 00:13:53,660
یا جاناتان شناخته می شوند یکی دیگر از چیزهای عالی در مورد
347
00:13:53,660 –> 00:13:55,370
کار با اسپارک آپاچی
348
00:13:55,370 –> 00:13:57,290
دسترسی به چند کتابخانه شگفت انگیز است و
349
00:13:57,290 –> 00:13:59,420
بنابراین حل این مشکل در
350
00:13:59,420 –> 00:14:01,370
واقع با بسته ای
351
00:14:01,370 –> 00:14:03,260
به نام فریم های نمودار که به اعتقاد من دیو
352
00:14:03,260 –> 00:14:06,290
ریک است، بسیار ساده است. موضوعی که توضیح دادم منبع باز است و
353
00:14:06,290 –> 00:14:08,420
فکر می کنم قبلاً
354
00:14:08,420 –> 00:14:10,100
در زمینه الگوریتم های گراف کاملاً شناخته شده و به خوبی حل شده است و
355
00:14:10,100 –> 00:14:14,660
356
00:14:14,660 –> 00:14:16,280
الگوریتم مربوطه اجزای متصل نامیده می شود.
357
00:14:16,280 –> 00:14:18,200
358
00:14:18,200 –> 00:14:20,360
359
00:14:20,360 –> 00:14:22,430
یک
360
00:14:22,430 –> 00:14:24,800
جزء متصل هستند، بنابراین اگر من فقط در دو فریم داده تغذیه کنم،
361
00:14:24,800 –> 00:14:26,390
یک قاب داده از رئوس
362
00:14:26,390 –> 00:14:28,940
که هر یک را نشان می دهد، یک فریم داده دیگر
363
00:14:28,940 –> 00:14:31,280
از یال ها را نشان می دهد که نشان دهنده پیوندهایی است
364
00:14:31,280 –> 00:14:32,930
که می گوییم. بله این دو نفر همسان هستند که
365
00:14:32,930 –> 00:14:35,540
من به آنها غذا می دهم و من فقط
366
00:14:35,540 –> 00:14:38,960
کامپوننت های متصل را صدا می زنم و voila
367
00:14:38,960 –> 00:14:41,660
نتایج را دارم و یک فریم داده
368
00:14:41,660 –> 00:14:44,420
دارم که با یک شخص به من برمی گردد و سپس
369
00:14:44,420 –> 00:14:49,280
شناسه جهانی آنها زیبا است بنابراین وقتی
370
00:14:49,280 –> 00:14:53,180
splinter را راه اندازی کردیم 3 ما
371
00:14:53,180 –> 00:14:55,280
بلافاصله توانستیم زمان
372
00:14:55,280 –> 00:14:57,530
اجرای این کار پیوند سراسری را از بیش از 8
373
00:14:57,530 –> 00:14:59,390
ساعت با سیستم قبلی به حدود
374
00:14:59,390 –> 00:15:03,320
یک ساعت و نیم کاهش
375
00:15:03,320 –> 00:15:06,380
دهیم
376
00:15:06,380 –> 00:15:08,390
377
00:15:08,390 –> 00:15:12,050
. خواندن بسیار آسانتر
378
00:15:12,050 –> 00:15:14,330
و به نظر من حفظ و نگهداری آن تا حد
379
00:15:14,330 –> 00:15:16,850
زیادی به لطف
380
00:15:16,850 –> 00:15:19,100
API قاب داده و این سبک توصیفی
381
00:15:19,100 –> 00:15:23,350
نوشتن تحولات اصلی و
382
00:15:23,350 –> 00:15:25,850
در نهایت به سادگی کمتر شبیه
383
00:15:25,850 –> 00:15:27,680
وزن کمتر کد،
384
00:15:27,680 –> 00:15:29,420
چیزهای کمتری دور گردن ما آویزان شد،
385
00:15:29,420 –> 00:15:31,399
زیرا ما اکنون از زمان راهاندازی میتوان از این
386
00:15:31,399 –> 00:15:37,040
اکوسیستمهای اسپارک و پایتون استفاده
387
00:15:37,040 –> 00:15:40,279
کرد و اخیراً
388
00:15:40,279 –> 00:15:42,500
ادی رهبری برخی از آزمایشها با
389
00:15:42,500 –> 00:15:44,360
شبکههای ع