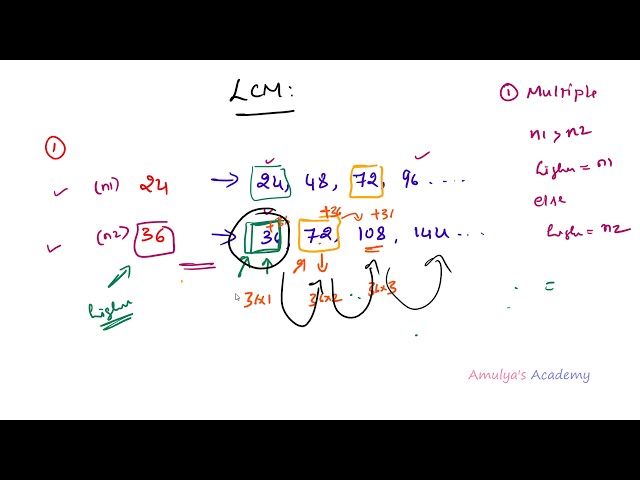
در این مطلب، ویدئو AdaBoost w / Python (آموزش 01) با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:05,250 –> 00:00:12,790
این یک نسخه از پیش ساخته شده
برنامه است، بنابراین اگر ما آن را اجرا کنیم
2
00:00:12,790 –> 00:00:24,010
و این داده های آموزشی است که استفاده خواهیم کرد
و این ستون x1 است و
3
00:00:24,010 –> 00:00:38,200
این ستون x2 است و این
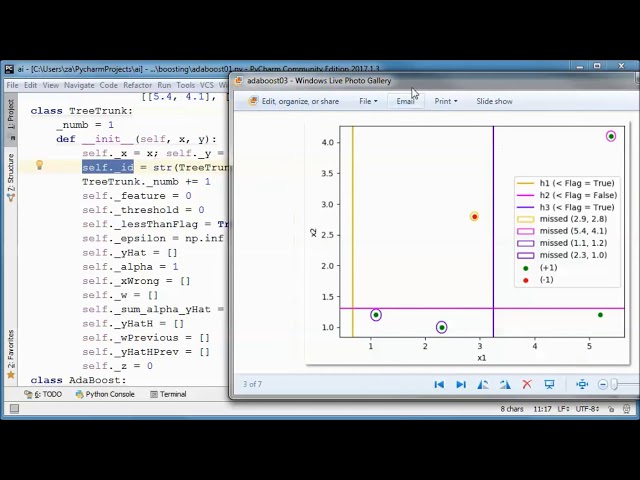
برچسب است و +1 در نشان داده می شود. سبز بنابراین
4
00:00:38,200 –> 00:00:51,760
آن آیتم های داده و
-1 به رنگ قرمز نشان داده می شود و پس از
5
00:00:51,760 –> 00:00:56,209
3
6
00:01:00,070 –> 00:01:13,689
دور به این طبقه بندی کننده کلی می رسیم
که به درستی تمام
7
00:01:13,689 –> 00:01:24,640
داده های آموزشی را طبقه بندی می کند و از
مجموع طبقه بندی کننده های ضعیف وزنی تشکیل شده است بنابراین
8
00:01:24,640 –> 00:01:38,229
h1 h2 و h3 و آنها با
alpha1 alpha2 و alpha3 وزن میکنیم و
9
00:01:38,229 –> 00:01:42,750
علامت آن جمع را میگیریم
10
00:01:45,630 –> 00:01:58,680
و این h1 است و از آنجایی که پرچم
واقعی است دادههای این سمت به
11
00:01:58,680 –> 00:02:10,489
عنوان -1 و از این طرف به عنوان +1
طبقهبندی میشود، بنابراین این آیتم داده اشتباه طبقهبندی شده است و
12
00:02:10,489 –> 00:02:21,959
این h2 و از آنجایی که پرچم نادرست است داده
های این سمت به عنوان +1 و
13
00:02:21,959 –> 00:02:30,870
از این طرف به عنوان -1
طبقه بندی می شود و این آیتم داده اشتباه طبقه بندی شده است
14
00:02:30,870 –> 00:02:41,340
و این h3 است و داده های این سمت
به عنوان -1 و به این سمت به عنوان +1 طبقه بندی می شود
15
00:02:41,340 –> 00:02:52,260
و آن 2 آیتم داده به
اشتباه طبقه بندی شده بودند و در ادامه سعی می کنیم
16
00:02:52,260 –> 00:02:57,540
چند مورد از داده ها را طبقه بندی کنیم بنابراین
ممکن است یکی در اینجا
17
00:02:57,540 –> 00:03:04,160
2 و 2 و دیگری در اینجا 4 و 1 باشد
18
00:03:10,860 –> 00:03:18,300
و این به عنوان -1
19
00:03:20,110 –> 00:03:30,660
طبقه بندی شد و به عنوان +1 طبقه بندی شد و
من در مورد فرمول
20
00:03:30,660 –> 00:03:44,260
هایی که در اینجا در هنگام نوشتن و
آزمایش کد استفاده شده است صحبت خواهم کرد. ایجاد یک
21
00:03:44,260 –> 00:03:47,280
فایل پایتون جدید
22
00:03:53,500 –> 00:04:03,100
و این دادههای آموزشی
خواهد بود که از آن استفاده خواهیم کرد، بنابراین این ستون x1 و
23
00:04:03,100 –> 00:04:14,260
این ستون x2 است و این
برچسب یا +1 یا -1 است و
24
00:04:14,260 –> 00:04:27,130
xArray شامل ویژگیها و
yArray برچسبها خواهد بود. و این کلاس
25
00:04:27,130 –> 00:04:41,260
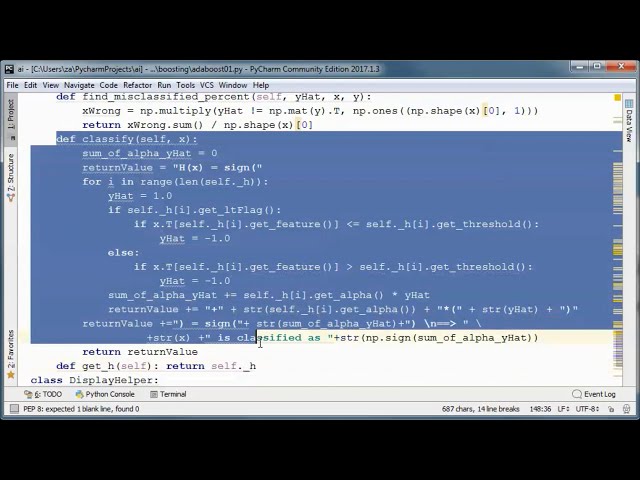
منطق AdaBoost را خواهد داشت و بیایید ادامه دهیم
و numpy را وارد کنیم زیرا
26
00:04:41,260 –> 00:04:53,980
باید از آن در اینجا استفاده کنیم بنابراین
xArray و yArray را به عنوان ماتریس به این سازنده ارسال
27
00:04:53,980 –> 00:05:05,130
می کنیم و طبقه بندی کننده کلی از طبقه بندی
کننده های TreeTrunk
28
00:05:05,130 –> 00:05:08,130
29
00:05:11,140 –> 00:05:23,280
تشکیل می شود که نشان داده می شوند. توسط این کلاس
و ما یک کلاس DisplayHelper
30
00:05:25,689 –> 00:05:36,099
خواهیم داشت و h یک آرایه از طبقهبندیکنندههای TreeTrunk خواهد بود،
حالا قبل از اینکه
31
00:05:36,099 –> 00:05:42,789
با کد ادامه دهیم، اجازه دهید یک مقدمه سریع انجام دهیم
، بنابراین تقویت
32
00:05:42,789 –> 00:05:50,649
چندین طبقهبندی ضعیف وزنی و تخصصی
را به یک طبقهبندی قوی و با
33
00:05:50,649 –> 00:05:56,499
سرعت ترکیب میکند. منظور ما این است که هر کدام از
آن دستهبندیکنندههای ضعیف در
34
00:05:56,499 –> 00:06:02,229
قسمتهای مختلف فضا خوب هستند و
بوستینگ دچار
35
00:06:02,229 –> 00:06:07,479
اضافهبرازش نمیشود و دستهبندی باینری انجام میدهد
و
36
00:06:07,479 –> 00:06:15,999
۱+ یا -۱ را تولید میکند و این فرمول
طبقهبندیکننده کلی است، بنابراین حروف کوچک h
37
00:06:15,999 –> 00:06:21,729
در اینجا نشان دهنده طبقه بندی کننده ضعیف است و
آلفا وزن هر یک از
38
00:06:21,729 –> 00:06:27,519
طبقه بندی کننده های ضعیف است و
جمع آنها را می گیریم و سپس
39
00:06:27,519 –> 00:06:33,669
علامت آن جمع را می گیریم و
هدف ما این است که همه
40
00:06:33,669 –> 00:06:40,479
طبقه بندی کننده های ضعیف و
وزن متناظر آنها را پیدا کنیم. همان
41
00:06:40,479 –> 00:06:49,029
وزن w برای هر آیتم داده و N در
اینجا تعداد آیتم های داده است و در هر
42
00:06:49,029 –> 00:06:56,709
دور مجموع اوزان باید برابر با
1 شود و ما میزان خطای
43
00:06:56,709 –> 00:07:03,789
هر طبقه بندی کننده را محاسبه می کنیم بنابراین اپسیلون برابر است
با مجموع وزن های اقلام داده ای
44
00:07:03,789 –> 00:07:09,669
که به اشتباه طبقه بندی شده اند و سپس
طبقه بندی کننده با کمترین اپسیلون را انتخاب می
45
00:07:09,669 –> 00:07:17,139
کنیم و با استفاده از این فرمول برای آن طبقه بندی کننده آلفا را محاسبه می
کنیم و سپس
46
00:07:17,139 –> 00:07:25,639
وزن های w را مجدداً بر اساس
این فرمول محاسبه می کنیم. d
47
00:07:25,639 –> 00:07:34,370
Z در اینجا برابر با این فرمول است و
اگر طبقهبندیکننده کلی
48
00:07:34,370 –> 00:07:44,860
همه موارد داده را
به درستی طبقهبندی کند با موفقیت خاتمه میدهیم و در هر
49
00:07:44,860 –> 00:07:54,060
طبقهبندیکننده TreeTrunk باید شناسه
50
00:07:54,070 –> 00:08:02,470
و ویژگی را پیگیری کنیم، به عنوان مثال برای این
طبقهبندی کننده برای h1، ویژگی
51
00:08:02,470 –> 00:08:11,460
x1 است. در دور 1، ما h1 داریم و
ویژگی X1 است و این آستانه
52
00:08:11,460 –> 00:08:23,920
در اینجا است، بنابراین ما
آستانه و کمتر از پرچم را نیز دنبال می کنیم، بنابراین
53
00:08:23,920 –> 00:08:31,090
از آنجایی که در اینجا کمتر از پرچم درست
است نسبت به داده های داده در این سمت از
54
00:08:31,090 –> 00:08:38,440
مرز تصمیم. به عنوان -1 طبقه بندی می شود
و در کنار آن به عنوان +1 اگر
55
00:08:38,440 –> 00:08:47,350
علامت کمتر از غلط بود، عکس آن را
خواهیم داشت و همچنین
56
00:08:47,350 –> 00:08:55,740
اپسیلون نرخ خطا را دنبال می کنیم، بنابراین به این
صورت اپسیلون را محاسبه می کنیم
57
00:08:58,070 –> 00:09:07,330
و برای h1 اپسیلون آن 0.2 است
58
00:09:08,930 –> 00:09:16,850
و این yhat برای این طبقهبندیکننده،
بنابراین فقط این دادههای 2.9
59
00:09:16,850 –> 00:09:24,170
و 2.8 به اشتباه طبقهبندی شدند، بنابراین
برای y 1- برای yhat از h(x
60
00:09:24,170 –> 00:09:29,160
) +1 است
61
00:09:29,680 –> 00:09:35,949
و ما آلفا را پیگیری میکنیم، بنابراین در اینجا
این عددی است که برای آلفا پیدا کردیم و
62
00:09:35,949 –> 00:09:45,660
آن را محاسبه میکنیم. با توجه به این فرمول
63
00:09:45,660 –> 00:09:52,800
و xWrong بنابراین از شما در
این اقلام دادهای را دارند که اشتباه طبقهبندی شده است، بنابراین
64
00:09:52,800 –> 00:10:06,810
فقط این مورد XWrong د