در این مطلب، ویدئو آموزش ریشه یابی و واژه سازی | پردازش زبان طبیعی (NLP) با پایتون | ادورکا با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:12:44
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,810 –> 00:00:10,259
[موسیقی]
2
00:00:10,259 –> 00:00:13,120
سلام به همه، این شانون افرایم در
3
00:00:13,120 –> 00:00:15,250
Eureka است و در جلسه امروز ما
4
00:00:15,250 –> 00:00:17,740
در مورد stemming و lamenting صحبت خواهیم کرد،
5
00:00:17,740 –> 00:00:20,290
بنابراین قبل از شروع جلسه، اجازه دهید
6
00:00:20,290 –> 00:00:23,200
نگاهی به دستور کار امروز بیندازیم
7
00:00:23,200 –> 00:00:25,270
تا با تعریف
8
00:00:25,270 –> 00:00:27,669
پردازش زبان طبیعی شروع کنیم و سپس حرکت کنیم. در ادامه
9
00:00:27,669 –> 00:00:29,860
و نگاهی به مؤلفه های NLP در
10
00:00:29,860 –> 00:00:32,950
ادامه خواهیم دید که چه چیزی استمینگ است و
11
00:00:32,950 –> 00:00:36,129
چه محدودیتی در حال حرکت است،
12
00:00:36,129 –> 00:00:37,809
همچنین نگاهی به برخی از
13
00:00:37,809 –> 00:00:40,239
کاربردهای stemming و lame’
14
00:00:40,239 –> 00:00:42,789
ation خواهیم انداخت در نهایت این جلسه را
15
00:00:42,789 –> 00:00:45,339
با تفاوت ها به پایان خواهیم رساند. بین این دو، پس
16
00:00:45,339 –> 00:00:47,679
بیایید شروع کنیم زبان انسان
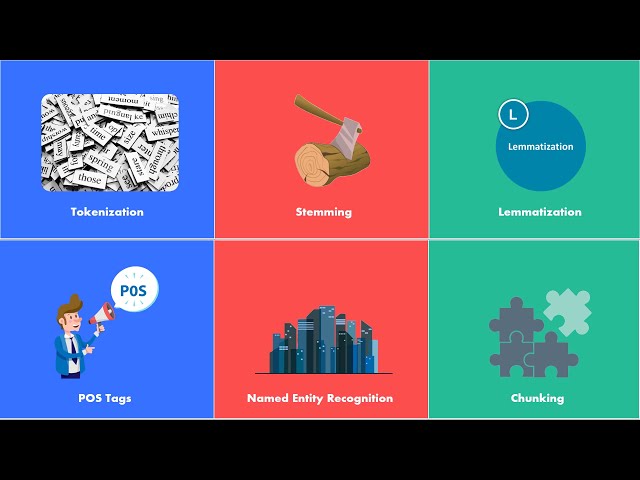
17
00:00:47,679 –> 00:00:51,039
با بیش از 6500 زبان
18
00:00:51,039 –> 00:00:53,589
در سراسر جهان یک معما است، زمانی که یک زبان حاوی کلماتی باشد
19
00:00:53,589 –> 00:00:55,809
که از کلمه دیگری مشتق شده
20
00:00:55,809 –> 00:00:58,120
اند، زیرا استفاده از آنها در تغییر گفتار،
21
00:00:58,120 –> 00:01:01,149
زبان عطف نامیده می شود، اکنون تقریباً
22
00:01:01,149 –> 00:01:03,699
همه زبان ها این ویژگی را دارند و بیشتر
23
00:01:03,699 –> 00:01:06,370
زبان ها بر اساس تخمین های صنعت، آنها به زبان عطف هستند،
24
00:01:06,370 –> 00:01:09,729
تنها 21 درصد از
25
00:01:09,729 –> 00:01:12,280
داده های موجود به صورت ساختار یافته
26
00:01:12,280 –> 00:01:15,219
وجود دارد.
27
00:01:15,219 –> 00:01:17,890
ما هنگام ارسال پیام در
28
00:01:17,890 –> 00:01:20,649
واتساپ یا اینستاگرام یا پیامرسانی من توییت میکنیم و
29
00:01:20,649 –> 00:01:23,680
در فعالیتهای مختلف دیگر
30
00:01:23,680 –> 00:01:26,619
اکثر این دادهها به صورت متنی وجود دارد
31
00:01:26,619 –> 00:01:28,960
که اکنون ماهیت آن بسیار بیساختار
32
00:01:28,960 –> 00:01:31,570
است تا بینشهای قابل توجه و
33
00:01:31,570 –> 00:01:34,780
عملی از دادههای متنی ایجاد شود.
34
00:01:34,780 –> 00:01:36,700
برای آشنایی با
35
00:01:36,700 –> 00:01:39,100
تکنیک ها و اصول متن کاوی
36
00:01:39,100 –> 00:01:41,979
و پردازش زبان طبیعی، پس بیایید
37
00:01:41,979 –> 00:01:44,350
این اصطلاحات را درک کنیم، پس بیایید
38
00:01:44,350 –> 00:01:47,350
با ex mining شروع کنیم متن کاوی یا
39
00:01:47,350 –> 00:01:49,270
تجزیه و تحلیل متن، فرآیند استخراج
40
00:01:49,270 –> 00:01:51,490
اطلاعات معنی دار از
41
00:01:51,490 –> 00:01:54,399
متون زبان طبیعی است، همانطور که متن کاوی به فرآیند اطلاق می
42
00:01:54,399 –> 00:01:56,740
شود. استخراج اطلاعات با کیفیت بالا
43
00:01:56,740 –> 00:01:59,020
از متن در حال حاضر
44
00:01:59,020 –> 00:02:02,200
هدف کلی اساسا تبدیل متن
45
00:02:02,200 –> 00:02:05,229
به داده برای تجزیه و تحلیل از طریق استفاده
46
00:02:05,229 –> 00:02:07,509
از پردازش زبان طبیعی است. اکنون
47
00:02:07,509 –> 00:02:10,240
پردازش زبان طبیعی به روش هوش مصنوعی
48
00:02:10,240 –> 00:02:12,640
برای برقراری ارتباط با یک
49
00:02:12,640 –> 00:02:14,950
سیستم هوشمند با استفاده از یک زبان طبیعی اشاره
50
00:02:14,950 –> 00:02:17,709
دارد، بنابراین در اینجا موارد مختلف وجود دارد. مراحلی
51
00:02:17,709 –> 00:02:20,709
که در فرآیند NLP دخیل هستند، بنابراین ما نشانه گذاری
52
00:02:20,709 –> 00:02:22,650
53
00:02:22,650 –> 00:02:26,310
La را داریم mmert ization برچسبهای POS به نام entity recognition and chunking نامیده میشوند،
54
00:02:26,310 –> 00:02:29,250
بنابراین امروز
55
00:02:29,250 –> 00:02:31,980
تمرکز ما بر روی ریشهگذاری و محدود
56
00:02:31,980 –> 00:02:35,099
کردن است، اکنون درجه عطف ممکن
57
00:02:35,099 –> 00:02:38,069
است در یک زبان بیشتر یا کمتر باشد، زیرا
58
00:02:38,069 –> 00:02:39,989
تعریف عطف را
59
00:02:39,989 –> 00:02:41,940
با توجه به گرامر خواندهاید، میتوانید
60
00:02:41,940 –> 00:02:44,400
درک کنید که کلمه عطف
61
00:02:44,400 –> 00:02:46,860
دارای یک ریشه مشترک است که ریشه
62
00:02:46,860 –> 00:02:48,840
سازی و حد سازی مورد مطالعه قرار گرفته است و
63
00:02:48,840 –> 00:02:50,879
الگوریتم هایی در
64
00:02:50,879 –> 00:02:53,849
علوم کامپیوتر از دهه 1960 توسعه یافته اند در این
65
00:02:53,849 –> 00:02:55,799
ویدئو با روشی عملی با ریشه یابی و
66
00:02:55,799 –> 00:02:57,930
محدود سازی آشنا می شوید
67
00:02:57,930 –> 00:03:00,209
که پس زمینه برخی از
68
00:03:00,209 –> 00:03:02,640
الگوریتم های معروف کاربردهای ریشه یابی را پوشش می دهد. و
69
00:03:02,640 –> 00:03:05,489
محدود کردن و نحوه ایجاد و محدود کردن
70
00:03:05,489 –> 00:03:08,519
جملات و اسناد کلمات چشمی با استفاده
71
00:03:08,519 –> 00:03:11,280
از بسته NLT k Python که
72
00:03:11,280 –> 00:03:13,079
بسته کیت ابزار زبان طبیعی
73
00:03:13,079 –> 00:03:15,870
ارائه شده توسط Python برای وظایف پردازش زبان طبیعی است
74
00:03:15,870 –> 00:03:18,900
که در حال حاضر تکنیک های عادی سازی متن ما در زمینه زبان طبیعی را ریشه می دهد و محدودسازی می کند.
75
00:03:18,900 –> 00:03:21,060
76
00:03:21,060 –> 00:03:23,040
77
00:03:23,040 –> 00:03:25,440
پردازشی که برای
78
00:03:25,440 –> 00:03:28,109
تهیه کلمات متنی و اسناد استفاده می شود
79
00:03:28,109 –> 00:03:30,540
پردازش بیشتر و اینها به طور گسترده
80
00:03:30,540 –> 00:03:34,410
در سیستم های برچسب گذاری ایندکس
81
00:03:34,410 –> 00:03:36,739
نتایج جستجوی وب سئو و بازیابی اطلاعات استفاده می شوند،
82
00:03:36,739 –> 00:03:39,629
به عنوان مثال جستجوی کلمه
83
00:03:39,629 –> 00:03:42,090
miss در گوگل نیز منجر به
84
00:03:42,090 –> 00:03:45,299
از دست رفتن موارد می شود زیرا miss اساساً
85
00:03:45,299 –> 00:03:48,239
ریشه هر دو این کلمات است، بنابراین بیایید
86
00:03:48,239 –> 00:03:50,609
اکنون با stemming شروع کنیم. stemming
87
00:03:50,609 –> 00:03:53,190
فرآیند کاهش عطف در کلمات
88
00:03:53,190 –> 00:03:55,799
به اشکال ریشه آنها است، مانند نگاشت یک
89
00:03:55,799 –> 00:03:58,349
گروه از کلمات به یک ریشه، حتی
90
00:03:58,349 –> 00:04:00,510
اگر خود ریشه یک کلمه معتبر
91
00:04:00,510 –> 00:04:03,120
در زبان نباشد، اکنون ریشه های انگلیسی و
92
00:04:03,120 –> 00:04:06,269
غیر انگلیسی در
93
00:04:06,269 –> 00:04:08,489
بسته nlgj موجود است. اکنون برای زبان انگلیسی
94
00:04:08,489 –> 00:04:10,709
میتوانید بین پورتر استمر و لنکستر استمر انتخاب کنید
95
00:04:10,709 –> 00:04:11,910
96
00:04:11,910 –> 00:04:14,160
که قدیمیترین استمر استمر است که
97
00:04:14,160 –> 00:04:17,459
98
00:04:17,459 –> 00:04:20,370
در سال 1979 توسعه یافت.
99
00:04:20,370 –> 00:04:22,500
100
00:04:22,500 –> 00:04:25,169
101
00:04:25,169 –> 00:04:27,270
همراه
102
00:04:27,270 –> 00:04:29,400
با آن خواهید دید که چگونه کلمات را ریشه می دهد
103
00:04:29,400 –> 00:04:32,430
، بنابراین کد
104
00:04:32,430 –> 00:04:34,710
porter stemmer اکنون چگونه کار می کند p orter stemmer
105
00:04:34,710 –> 00:04:35,740
از Suffolk
106
00:04:35,740 –> 00:04:38,259
stripping برای تولید چادر
107
00:04:38,259 –> 00:04:40,060
استفاده می کند الگوریتم پورتر stemmer از زبان شناسی پیروی نمی کند
108
00:04:40,060 –> 00:04:42,789
بلکه مجموعه ای از پنج قانون
109
00:04:42,789 –> 00:04:45,039
برای موارد مختلف است که در
110
00:04:45,039 –> 00:04:47,889
فازها برای تولید ساقه اعمال می
111
00:04:47,889 –> 00:04:50,080
112
00:04:50,080 –> 00:04:52,449
113
00:04:52,449 –> 00:04:55,060
شود. اکنون یک
114
00:04:55,060 –> 00:04:57,520
جدول جستجو برای ریشههای واقعی کلمه نگه نمیدارد، اما از
115
00:04:57,520 –> 00:04:59,349
قوانین الگوریتمی برای تولید
116
00:04:59,349 –> 00:05:02,410
ریشهها استفاده میکند، همچنین از قوانین برای تصمیمگیری در مورد
117
00:05:02,410 –> 00:05:05,500
اینکه آیا حذف پسوند عاقلانه است یا نه،
118
00:05:05,500 –> 00:05:07,690
اکنون میتوان مجموعه قوانین خود را
119
00:05:07,690 –> 00:05:10,210
برای هر زبانی که چرا Python
120
00:05:10,210 –> 00:05:12,819
analytic دستگاههای بخار برفی را معرفی
121
00:05:12,819 –> 00:05:15,099
کرد که برای ایجاد بخاریهای غیر انگلیسی استفاده میشوند،
122
00:05:15,099 –> 00:05:18,580
بنابراین چرا اکنون از آن استفاده میکنیم porter
123
00:05:18,580 –> 00:05:20,860
stemmer به دلیل سادگی و
124
00:05:20,860 –> 00:05:23,349
سرعت آن شناخته شده است. معمولاً در
125
00:05:23,349 –> 00:05:25,900
محیطهای بازیابی اطلاعات معروف
126
00:05:25,900 –> 00:05:29,199
به محیطهای IR برای یادآوری سریع و
127
00:05:29,199 –> 00:05:31,750
واکشی جستجو مفید است پرس و
128
00:05:31,750 –> 00:05:34,300
جوهایی مانند فورواردها مانند اتصالات متصل
129
00:05:34,300 –> 00:05:36,909
اتصال یا اتصال همه این
130
00:05:36,909 –> 00:05:39,729
کلمات به معنای اتصال اکنون زبان هستند
131
00:05:39,729 –> 00:05:42,219
sistema یک الگوریتم تکراری است که
132
00:05:42,219 –> 00:05:45,070
قوانین آن به صورت خارجی ذخیره شده است. بخارشوی لنکستر
133
00:05:45,070 –> 00:05:47,830
ساده است اما به دلیل نسبت های فناوری اطلاعات، ساقه بندی سنگین است
134
00:05:47,830 –> 00:05:51,039
و / ممکن است ساقه در حال حاضر رخ دهد /
135
00:05:51,039 –> 00:05:52,780
ریشه زدن باعث می شود ساقه ها
136
00:05:52,780 –> 00:05:55,419
زبانی نباشند یا ممکن است اصلاً معنایی
137
00:05:55,419 –> 00:05:57,909
نداشته باشند، بنابراین اکنون اجازه دهید نگاهی به
138
00:05:57,909 –> 00:06:00,820
کد بخار لنکستر به عنوان مثال در
139
00:06:00,820 –> 00:06:03,909
سیستم بی ثبات کد بالا – de St
140
00:06:03,909 –> 00:06:06,370
در لنکستر stemmer که در آن از
141
00:06:06,370 –> 00:06:09,099
پورتر stemmer استفاده می شود d stable اکنون بخارشوی لنکستر
142
00:06:09,099 –> 00:06:11,409
143
00:06:11,409 –> 00:06:13,659
به دلیل تکرارها ساقه کوتاه تری نسبت به پورتر تولید می کند و
144
00:06:13,659 –> 00:06:17,229
بیش از پایه نامناسب است، بنابراین می توانید
145
00:06:17,229 –> 00:06:19,780
جملات و اسناد را با استفاده از آن استناد کنید. n
146
00:06:19,780 –> 00:06:22,719
مشتری LD از کد زیر استفاده می کنند، بنابراین همانطور
147
00:06:22,719 –> 00:06:25,000
که می بینید لکنت زبان کل
148
00:06:25,000 –> 00:06:27,




![فیلم آموزشی: 4. رشته ها [آموزش برنامه نویسی پایتون 3] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/ez2N-hcwvcQimage2.jpg)

![فیلم آموزشی: [1/14] تجزیه و تحلیل المان محدود ساختارهای سه بعدی با استفاده از پایتون | DegreeTutors.com با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/n-wC9iWg9VYimage2.jpg)