در این مطلب، ویدئو آزمون فرضیه نسبت جمعیت – EXCEL با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:13:20
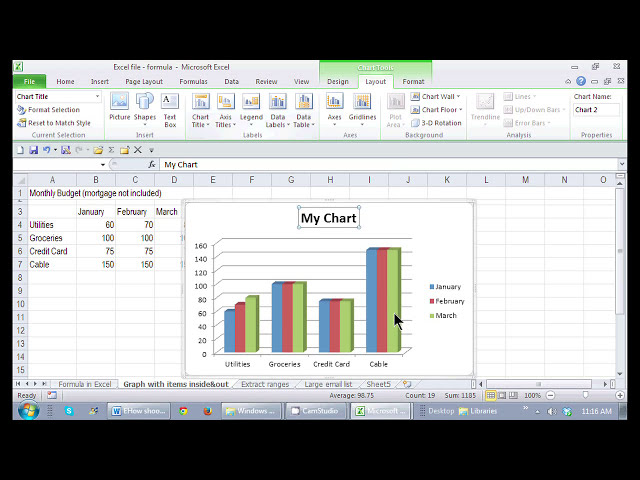
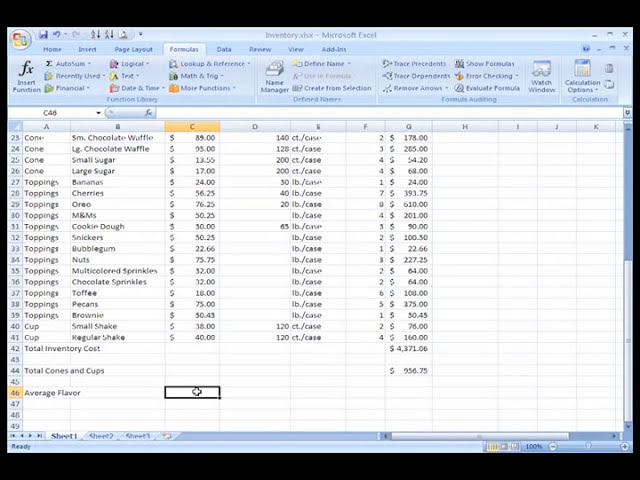
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:04,530 –> 00:00:07,649
در این ویدیو ما به استفاده از
2
00:00:07,649 –> 00:00:10,620
مایکروسافت اکسل برای آزمایش فرضیه
3
00:00:10,620 –> 00:00:13,320
با مقدار p نگاه می کنیم، اینجا اطلاعات ما
4
00:00:13,320 –> 00:00:15,990
در اینجا است و اولین چیزی که همیشه
5
00:00:15,990 –> 00:00:17,610
باید بررسی کنیم این است که آیا این چیز درست است،
6
00:00:17,610 –> 00:00:19,320
می گوید درست است اما ما آن را قرار می دهیم
7
00:00:19,320 –> 00:00:21,390
اطلاعات را در مایکروسافت اکسل
8
00:00:21,390 –> 00:00:23,580
نشان می دهد که درست است، بنابراین در اینجا
9
00:00:23,580 –> 00:00:26,490
سند ما است، آبی ها کادرهایی هستند که
10
00:00:26,490 –> 00:00:28,500
مقادیر را در آنها وارد می کنیم و کادرهای قرمز
11
00:00:28,500 –> 00:00:30,570
جعبه های محاسباتی هستند، بنابراین بیایید
12
00:00:30,570 –> 00:00:34,470
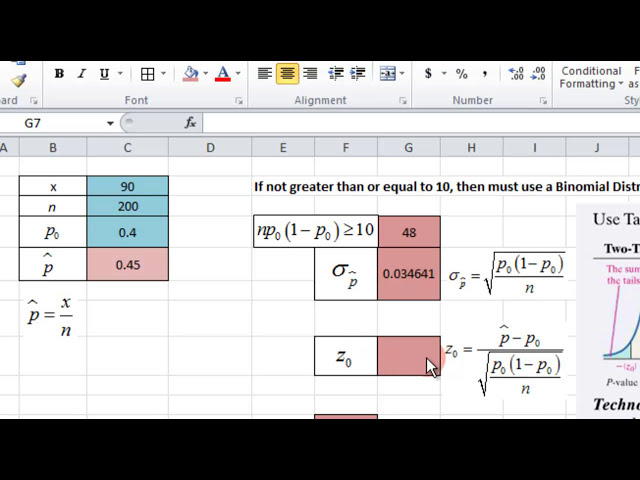
X و P را دریافت کنیم نه X ما نود و
13
00:00:34,470 –> 00:00:36,750
دویست است. و سپس P ما این مقدار
14
00:00:36,750 –> 00:00:40,350
نیست در اینجا نقطه چهار است، بنابراین نود
15
00:00:40,350 –> 00:00:48,120
و دویست و نقطه چهار، پس ما به
16
00:00:48,120 –> 00:00:50,610
تخمین نقطه یا کلاه P نیاز داریم که
17
00:00:50,610 –> 00:00:52,980
فقط مقدار x تقسیم بر مقدار پایانی
18
00:00:52,980 –> 00:00:55,379
است، بنابراین من می خواهم آن را a
19
00:00:55,379 –> 00:00:57,410
محاسبه به گونهای که همیشه بهروزرسانی میشود،
20
00:00:57,410 –> 00:01:00,329
پس معادلهای که باید
21
00:01:00,329 –> 00:01:02,430
برآورده کنیم بزرگتر از ده است،
22
00:01:02,430 –> 00:01:04,170
دلیل آن این است که در این صورت
23
00:01:04,170 –> 00:01:06,869
میتوانیم از یک توزیع نرمال با
24
00:01:06,869 –> 00:01:09,119
مقادیر خود در اینجا برای بقیه آن استفاده کنیم تا ما را به دست
25
00:01:09,119 –> 00:01:11,280
آوریم. مقدار p اگر نه پس باید از b استفاده کنیم
26
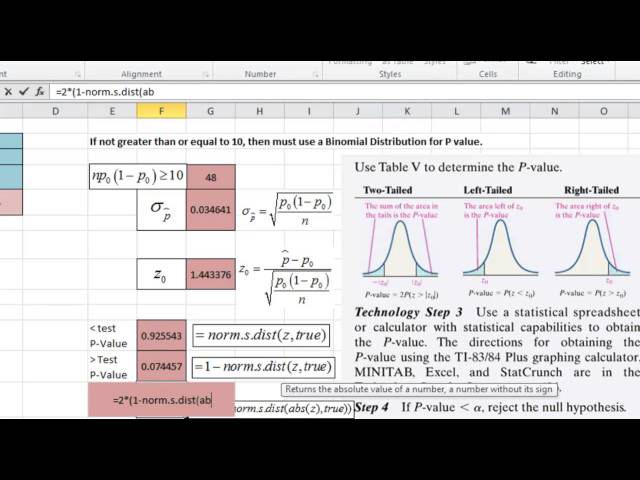
00:01:11,280 –> 00:01:13,530
توزیع غیر اسمی برای کوچکتر از
27
00:01:13,530 –> 00:01:16,830
آن، بنابراین ما این را برابر می کنیم، n
28
00:01:16,830 –> 00:01:19,680
برابر بادام زمینی داریم، بنابراین n باید یک
29
00:01:19,680 –> 00:01:23,040
نماد زمانی در اینجا قرار دهیم بادام زمینی، نماد زمانی دیگر،
30
00:01:23,040 –> 00:01:26,040
پرانتز باز یک منهای P هیچ و
31
00:01:26,040 –> 00:01:29,490
سپس پرانتزهای من را 48 به پایان برسانیم و این
32
00:01:29,490 –> 00:01:30,780
بزرگتر یا مساوی است. به ده، بنابراین ما می
33
00:01:30,780 –> 00:01:33,869
توانیم این مسیر را در اینجا ادامه دهیم و سپس به
34
00:01:33,869 –> 00:01:35,759
انحراف استاندارد نیاز داریم که
35
00:01:35,759 –> 00:01:38,100
این معادله در اینجا خواهد
36
00:01:38,100 –> 00:01:39,930
37
00:01:39,930 –> 00:01:43,650
38
00:01:43,650 –> 00:01:45,869
39
00:01:45,869 –> 00:01:47,220
بود. دوباره بر عدد تقسیم
40
00:01:47,220 –> 00:01:53,030
میشویم، بنابراین ما به جذر
41
00:01:53,030 –> 00:01:56,790
P naught ضربدر اول نیاز داریم تا یک منهای P را ببینیم
42
00:01:56,790 –> 00:01:58,560
که تمام آن عدد است و از آنجایی که
43
00:01:58,560 –> 00:02:00,420
ضرب است، میتوانم آن را به یک
44
00:02:00,420 –> 00:02:03,299
آیتم تقسیم بر مقدار پایانی تبدیل کنم
45
00:02:03,299 –> 00:02:06,149
و سپس عدد را ببندم. پرانتز برای
46
00:02:06,149 –> 00:02:08,699
ریشه مربع وارد می شود، بنابراین انحراف معیار ما وجود دارد،
47
00:02:08,699 –> 00:02:12,989
اکنون ما
48
00:02:12,989 –> 00:02:15,870
آمار آزمون Z را محاسبه می کنیم و
49
00:02:15,870 –> 00:02:17,640
سپس چیزی که قرار است باشد،
50
00:02:17,640 –> 00:02:18,470
P کلاه
51
00:02:18,470 –> 00:02:22,010
– بادام زمینی / آن انحراف استاندارد خواهد بود. به
52
00:02:22,010 –> 00:02:23,510
همین دلیل است که من آن را ایجاد کردم تا
53
00:02:23,510 –> 00:02:26,150
بتوانیم این کار را تکه تکه انجام دهیم، بنابراین
54
00:02:26,150 –> 00:02:29,020
این را در پرانتز برابر با
55
00:02:29,020 –> 00:02:34,600
تخمین نقطه کلاه P در نظر می گیریم – بادام زمینی
56
00:02:34,600 –> 00:02:37,820
تقسیم بر انحراف استاندارد
57
00:02:37,820 –> 00:02:41,330
و آمار Z ما از Z هیچ 1
58
00:02:41,330 –> 00:02:44,810
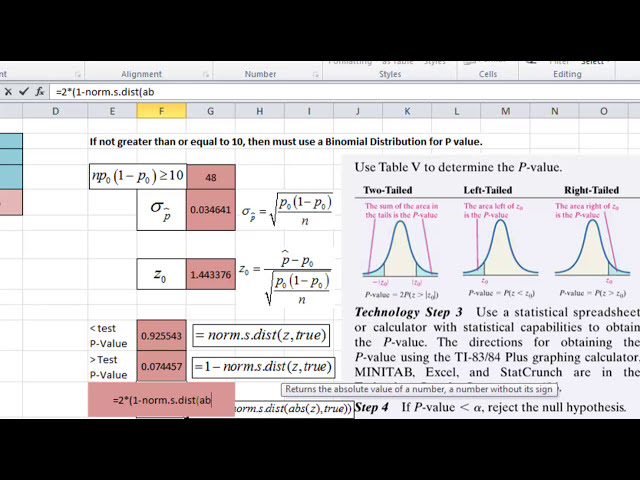
امتیاز است. 4 4 3 3 7 6 اکنون آنچه ما
59
00:02:44,810 –> 00:02:48,230
در اینجا به آن علاقه مندیم این است که چه نوع
60
00:02:48,230 –> 00:02:50,690
آزمونی را به خوبی
61
00:02:50,690 –> 00:02:53,630
62
00:02:53,630 –> 00:02:55,310
63
00:02:55,310 –> 00:02:57,410
انجام می دهیم. در اینجا یک
64
00:02:57,410 –> 00:02:58,970
تست بزرگتر از تست انجام می دهیم که یک
65
00:02:58,970 –> 00:03:00,200
تست دم دست راست است، به
66
00:03:00,200 –> 00:03:02,030
این معنی که
67
00:03:02,030 –> 00:03:04,730
اگر دم کمتری دارید، این ناحیه را در اینجا پیدا می کنیم
68
00:03:04,730 –> 00:03:07,400
– کمتر از دم سمت چپ است،
69
00:03:07,400 –> 00:03:11,510
بنابراین می خواهید این ناحیه در اینجا مطابقت داشته باشد. به
70
00:03:11,510 –> 00:03:13,700
آن مقدار z و سپس اگر یک
71
00:03:13,700 –> 00:03:16,760
تست دو طرفه دارید، میخواهید هر دو ناحیه خوب باشد،
72
00:03:16,760 –> 00:03:19,490
بنابراین اساساً یک نقطه داریم 4 4
73
00:03:19,490 –> 00:03:21,560
3 3 7 6، میخواهیم ناحیهای را که
74
00:03:21,560 –> 00:03:24,650
در سمت راست آن Z است، کاملاً درست
75
00:03:24,650 –> 00:03:27,500
پیدا کنیم. ما در اینجا بزرگتر از 1 هستیم،
76
00:03:27,500 –> 00:03:29,120
بنابراین من می خواهم آزمون t وسط را
77
00:03:29,120 –> 00:03:30,590
بزرگتر از اول انجام دهم به دلیل اینکه مقدار آن
78
00:03:30,590 –> 00:03:33,320
بیشتر از مقدار بود، اکنون فرمولی
79
00:03:33,320 –> 00:03:36,590
در اکسل داریم که آن ناحیه را به ما برمی گرداند که به
80
00:03:36,590 –> 00:03:40,100
آن نقطه هنجار s dot dist می گویند
81
00:03:40,100 –> 00:03:44,480
و سپس مقدار Z شما کاما true است، اما
82
00:03:44,480 –> 00:03:47,090
به یاد داشته باشید که نسبتی را
83
00:03:47,090 –> 00:03:49,340
که همیشه در سمت چپ مقدار Z است برمی گرداند.
84
00:03:49,340 –> 00:03:52,489
بنابراین، اگر این کار را انجام دهیم، همیشه
85
00:03:52,489 –> 00:03:54,410
ارزش را از اینجا به
86
00:03:54,410 –> 00:03:56,299
چپ میگیریم و نمیخواهم که اینجا
87
00:03:56,299 –> 00:03:58,340
به سمت راست میخواهم، بنابراین 1
88
00:03:58,340 –> 00:04:00,650
منهای مقدار سمت چپ خواهد بود، به
89
00:04:00,650 –> 00:04:02,540
همین دلیل است که وقتی شما به سمت راست یک
90
00:04:02,540 –> 00:04:07,459
مقدار نیاز-نیاز برابر است با 1 منهای نقطه عادی
91
00:04:07,459 –> 00:04:11,239
فاصله نقطه و سپس مقدار z در
92
00:04:11,239 –> 00:04:12,920
آنجا قرار می گیرد و مقدار z
93
00:04:12,920 –> 00:04:16,459
همیشه در اینجا کاما و سپس true قرار می گیرد و سپس اینتر
94
00:04:16,459 –> 00:04:21,200
را فشار دهید تا این
95
00:04:21,200 –> 00:04:24,050
مقدار سمت راست آمار z
96
00:04:24,050 –> 00:04:27,770
را به ما می دهد و آن نقطه مقدار p یا
97
00:04:27,770 –> 00:04:31,999
نقطه صفر ما هفت چهار چهار پنج هفت خواهد بود
98
00:04:31,999 –> 00:04:34,909
و اگر به مقدار خود در اینجا نگاه کنیم
99
00:04:34,909 –> 00:04:41,809
مقادیر p 0.075 و اکنون به دلیل اینکه در حال
100
00:04:41,809 –> 00:04:46,099
آزمایش 0.01 a هستیم.
101
00:04:46,099 –> 00:04:51,039
در اینجا سطح معنیداری وجود دارد و p-value کمتر از
102
00:04:51,039 –> 00:04:57,799
مقدار معنیداری نیست که t را رد نمیکنیم
103
00:04:57,799 –> 00:05:00,110
او فرضیه صفر را به این دلیل که مقدار p
104
00:05:00,110 –> 00:05:02,869
بزرگتر است اگر از این
105
00:05:02,869 –> 00:05:06,499
مقدار کمتر باشد، بنابراین مانند نقطه صفر صفر یا
106
00:05:06,499 –> 00:05:08,809
چیزی شبیه به صفر، فرضیه صفر را رد می کنیم،
107
00:05:08,809 –> 00:05:12,169
اما چون بزرگتر از
108
00:05:12,169 –> 00:05:15,649
آن مقدار است، فرض صفر را رد نمی کنیم
109
00:05:15,649 –> 00:05:16,909
و این همان چیزی است که
110
00:05:16,909 –> 00:05:18,919
بیانیه در اینجا می گوید، زیرا اگر مقادیر p شما
111
00:05:18,919 –> 00:05:21,110
آخرین فرضیه صفر را رد کرد، اگر
112
00:05:21,110 –> 00:05:22,699
بیشتر بود، فرضیه صفر را رد نکنید،
113
00:05:22,699 –> 00:05:25,369
بنابراین در مورد ما، فرضیه صفر را رد نمی کنیم، در صورتی که
114
00:05:25,369 –> 00:05:28,819
115
00:05:28,819 –> 00:05:31,339
این دو
116
00:05:31,339 –> 00:05:33,499
مقدار را تکمیل کنم. ما میخواهیم مقدار دیگری
117
00:05:33,499 –> 00:05:36,229
برای Z انجام دهیم، به عنوان مثال اگر مقدار Z ما
118
00:05:36,229 –> 00:05:40,069
کمتر از یک تست دنباله چپ بود
119
00:05:40,069 –> 00:05:42,289
، تنها کاری که باید انجام دهم این است که
120
00:05:42,289 –> 00:05:46,699
معادلها را قرار دهم و سپس هنجارگرا را وارد کنیم و سپس مقدار Z خود
121
00:05:46,699 –> 00:05:50,269
را در کاما و true قرار دهیم، زیرا این کار
122
00:05:50,269 –> 00:05:52,459
ادامه دارد. برای پیدا کردن ناحیه سمت چپ،
123
00:05:52,459 –> 00:05:53,689
مطمئناً این احتمالاً یک
124
00:05:53,689 –> 00:05:55,669
مقدار Z منفی و سپس راست خواهد بود و سپس
125
00:05:55,669 –> 00:05:57,589
ما می دانیم که از این یکی استفاده کنیم
126
00:05:57,589 –> 00:05:59,809
زیرا کمتر از آن است، ما آن
127
00:05:59,809 –> 00:06:02,649
سمت راست را که در سمت چپ است که 92 را نشان می دهد نادیده می گیریم.
128
00:06:02,649 –> 00:06:05,989
٪ به سمت چپ در اینجا در حالی که 7 درصدی
129
00:06:05,989 –> 00:06:07,789
که میدانید هفت نقطه پنج این است که یک
130
00:06:07,789 –> 00:06:12,549
خوب مساوی است، باید هر دو ناحیه را
131
00:06:12,549 –> 00:06:15,199
بدست آوریم که باید مراقب مقدار Z
132
00:06:15,199 –> 00:06:16,969
باشیم، اگرچه نمیدانیم که آیا این مقادیر
133
00:06:16,969 –> 00:06:19,099
Z مثبت یا منفی هستند، این باعث
134
00:06:19,099 –> 00:06:20,749
میشود جمع کردن هر دو ناحیه کمی چالش برانگیز
135
00:06:20,749 –> 00:06:23,929
است، بنابراین ما این کار را انجام می دهیم این است
136
00:06:23,929 –> 00:06:25,459
که اطمینان حاصل کنیم که مقدار Z
137
00:06:25,459 –> 00:06:27,979
همیشه مثبت است و بنابراین ما در اینجا می خواهیم
138
00:06:27,979 –> 00:06:29,659
ناحیه سمت راست این ناحیه را پیدا
139
00:06:29,659 –> 00:06:31,489
کنیم. مقدار Z را
140
00:06:31,489 –> 00:06:33,229
با قرار دادن مقادیر مطلق روی آن وادار به مثبت شدن
141
00:06:33,229 –> 00:06:35,089
می کنیم و سپ