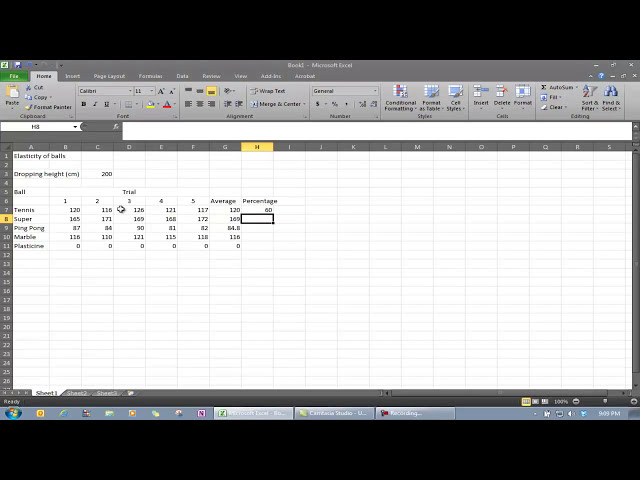
در این مطلب، ویدئو آماده سازی مجموعه داده های برآورد و اعتبار سنجی با اکسل با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:12:18
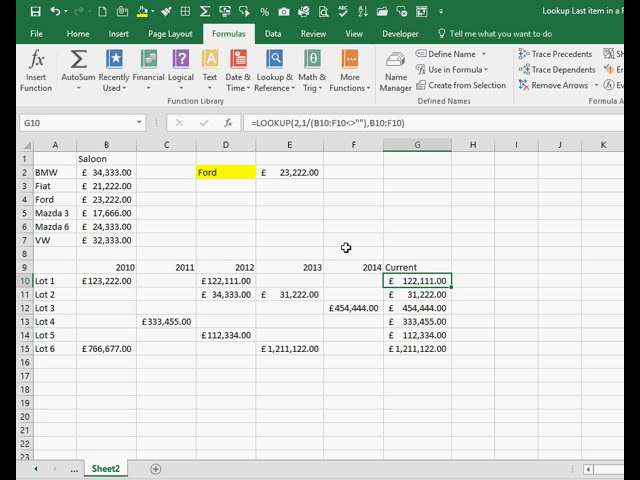
تصاویر این ویدئو:
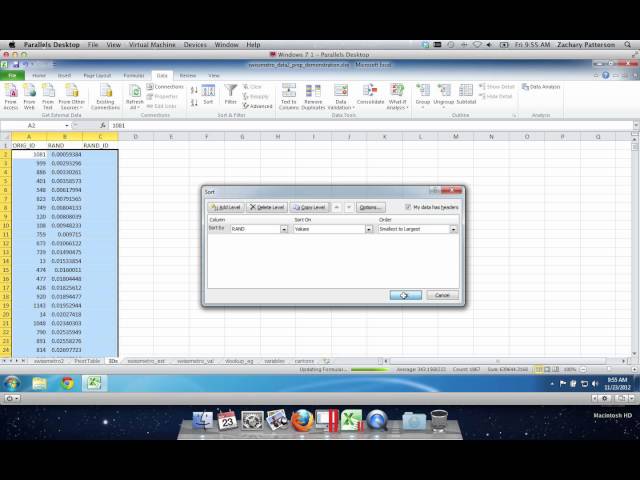
قسمتی از زیرنویس این فیلم:
00:00:03,199 –> 00:00:04,480
بسیار خوب،
2
00:00:04,480 –> 00:00:07,040
کاری که ما در این ویدئو انجام می دهیم این است که به
3
00:00:07,040 –> 00:00:08,240
طور تصادفی
4
00:00:08,240 –> 00:00:11,440
کل مجموعه داده های خود را به یک
5
00:00:11,440 –> 00:00:13,360
مجموعه داده تخمینی با
6
00:00:13,360 –> 00:00:16,640
80 داده و یک مجموعه داده اعتبارسنجی
7
00:00:16,640 –> 00:00:17,680
با
8
00:00:17,680 –> 00:00:20,320
20 داده
9
00:00:23,359 –> 00:00:25,760
برای شروع تقسیم کنیم، می خواهیم ستونی به نام rand ایجاد کنیم.
10
00:00:25,760 –> 00:00:27,519
id و این شناسه
11
00:00:27,519 –> 00:00:28,320
جدیدی است
12
00:00:28,320 –> 00:00:31,039
که میخواهیم ایجاد کنیم و
13
00:00:31,039 –> 00:00:32,159
14
00:00:32,159 –> 00:00:33,920
با تولید این شناسه تصادفی به ما این
15
00:00:33,920 –> 00:00:35,760
امکان را میدهد که بهطور
16
00:00:35,760 –> 00:00:38,719
تصادفی تخمین خود را از
17
00:00:38,719 –> 00:00:40,000
مجموعه دادههای اعتبار سنجی خود جدا کنیم
18
00:00:40,000 –> 00:00:41,760
به یاد داشته باشید که تخمین مجموعه
19
00:00:41,760 –> 00:00:43,440
داده 80
20
00:00:43,440 –> 00:00:46,480
مورد از مشاهدات کل مجموعه داده ما را دارد
21
00:00:46,480 –> 00:00:46,800
22
00:00:46,800 –> 00:00:50,480
و مجموعه داده اعتبارسنجی 20 مشاهده خواهد داشت
23
00:00:51,120 –> 00:00:52,879
پس از ایجاد این ستون، می
24
00:00:52,879 –> 00:00:54,480
خواهیم از جدول محوری استفاده کنیم، جدول
25
00:00:54,480 –> 00:00:57,840
محوری که قرار است از آن استفاده کنیم
26
00:00:57,840 –> 00:00:59,440
و قرار خواهیم داد. شناسه
27
00:00:59,440 –> 00:01:01,600
در برچسبهای ردیف،
28
00:01:01,600 –> 00:01:03,920
لیستی از
29
00:01:03,920 –> 00:01:07,520
شناسههای منحصربهفرد در مجموعه داده را به ما میدهد، همانطور که
30
00:01:07,520 –> 00:01:10,880
در مجموعه دادههای اصلی به خاطر میآورید که هر فرد به
31
00:01:10,880 –> 00:01:12,960
۹ کار انتخابی پاسخ داده است و در
32
00:01:12,960 –> 00:01:14,159
نتیجه ۹ مشاهده وجود دارد
33
00:01:14,159 –> 00:01:18,479
که میخواهیم انجام دهیم. فقط
34
00:01:18,479 –> 00:01:19,119
لیستی
35
00:01:19,119 –> 00:01:22,560
از شناسه های منحصر به فرد دریافت کنید زیرا w
36
00:01:22,560 –> 00:01:23,920
وقتی
37
00:01:23,920 –> 00:01:26,479
مجموعه دادههای خود را بین
38
00:01:26,479 –> 00:01:28,000
هشتاد و بیست درصد جدا میکنیم
39
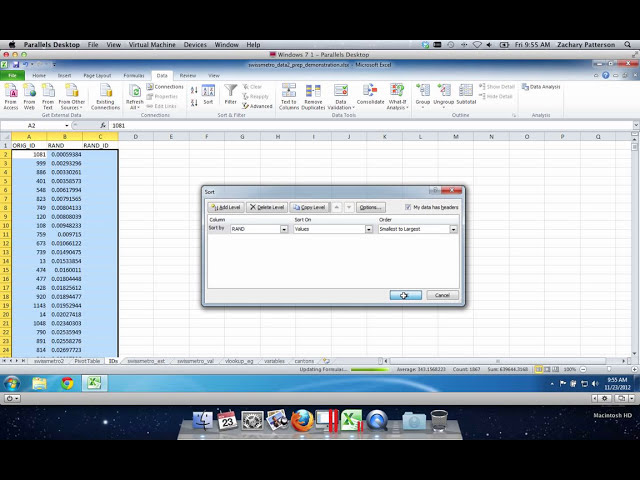
00:01:28,000 –> 00:01:28,400
،
40
00:01:28,400 –> 00:01:30,560
حذف میکنیم، نمیخواهیم هشتاد درصد افراد را حذف کنیم
41
00:01:30,560 –> 00:01:32,159
نه فقط هشتاد
42
00:01:32,159 –> 00:01:35,200
درصد سؤالها، بنابراین در اینجا فهرستی
43
00:01:35,200 –> 00:01:38,000
از شناسههای منحصربهفرد داریم. از بین افراد موجود در
44
00:01:38,000 –> 00:01:39,280
مجموعه داده،
45
00:01:39,280 –> 00:01:42,159
بنابراین ما این را انتخاب می کنیم، خواهید دید
46
00:01:42,159 –> 00:01:45,600
که از 1 تا 1185 می رود.
47
00:01:45,600 –> 00:01:49,600
ما آن را کپی می کنیم به جدول جدیدی
48
00:01:49,600 –> 00:01:52,720
که من آن را id نامیده ام و در جدول اصلی
49
00:01:52,720 –> 00:01:55,600
ستون id ما می خواهیم
50
00:01:55,600 –> 00:01:59,040
شناسه های منحصر به فرد را بچسبانیم، اکنون کاری که می خواهیم
51
00:01:59,040 –> 00:01:59,439
انجام دهیم این
52
00:01:59,439 –> 00:02:02,719
است که برای هر یک از شناسه های اصلی منحصر به فرد،
53
00:02:02,719 –> 00:02:04,960
یک
54
00:02:04,960 –> 00:02:07,119
عدد تصادفی را به آن مرتبط می
55
00:02:07,119 –> 00:02:08,720
کنیم و سپس می توانیم از آن تصادفی استفاده کنیم.
56
00:02:08,720 –> 00:02:11,120
عدد برای
57
00:02:11,120 –> 00:02:13,840
تقسیم شناسهها بین آنهایی که
58
00:02:13,840 –> 00:02:15,360
باید در مجموعه دادههای تخمینی باشند
59
00:02:15,360 –> 00:02:16,560
و آنهایی که باید
60
00:02:16,560 –> 00:02:19,599
در مجموعه دادههای اعتبارسنجی باشند تا این کار را
61
00:02:19,599 –> 00:02:21,440
انجام دهیم، از تابعی به نام
62
00:02:21,440 –> 00:02:22,959
rand
63
00:02:22,959 –> 00:02:26,239
در اکسل استفاده میکنیم و کاری که رند انجام میدهد این است که
64
00:02:26,239 –> 00:02:27,440
65
00:02:27,440 –> 00:02:31,360
یک عدد تولید میکند. عددی بین صفر و یک،
66
00:02:31,360 –> 00:02:33,280
یک عدد تصادفی بین صفر و یک است
67
00:02:33,280 –> 00:02:35,200
که میخواهیم استفاده کنیم این در یک دقیقه است،
68
00:02:35,200 –> 00:02:36,800
بنابراین ابتدا باید برای
69
00:02:36,800 –> 00:02:39,280
هر یک از شناسه های اصلی
70
00:02:39,280 –> 00:02:41,840
یک عدد تصادفی اختصاص دهیم، بنابراین قبلاً
71
00:02:41,840 –> 00:02:42,560
این را ایجاد
72
00:02:42,560 –> 00:02:44,080
کرده ایم، قبلاً در این تابع قرار داده ایم و
73
00:02:44,080 –> 00:02:45,920
اکنون اگر اکنون
74
00:02:45,920 –> 00:02:48,000
به سلولی نزدیک شویم که شماره تصادفی در
75
00:02:48,000 –> 00:02:49,440
آن وجود دارد. از پایین
76
00:02:49,440 –> 00:02:52,640
سمت راست وقتی مکان نما از یک
77
00:02:52,640 –> 00:02:53,040
78
00:02:53,040 –> 00:02:56,640
ضربدر سفید به یک ضربدر سیاه تغییر می کند، می
79
00:02:56,640 –> 00:02:59,760
توانیم دوبار کلیک کنیم اگر اکنون دوبار کلیک
80
00:02:59,760 –> 00:03:02,640
کنیم، تمام ستون ستون رند را پر می کند،
81
00:03:02,640 –> 00:03:03,120
82
00:03:03,120 –> 00:03:05,760
بنابراین اکنون خواهید دید که
83
00:03:05,760 –> 00:03:08,159
ما اعداد داریم. با هر یک
84
00:03:08,159 –> 00:03:10,159
از شناسه های اصلی ما مرتبط است و اینکه این
85
00:03:10,159 –> 00:03:13,120
اعداد همگی بین صفر و یک هستند
86
00:03:13,120 –> 00:03:15,200
و همه آنها متفاوت هستند، یک چیز
87
00:03:15,200 –> 00:03:16,560
که کمی مشکل
88
00:03:16,560 –> 00:03:19,920
است این است که هر بار که می خواهید
89
00:03:19,920 –> 00:03:22,879
کاری در برگه انجام دهید بگویید که باید
90
00:03:22,879 –> 00:03:24,799
یک عدد اضافه کنید. در
91
00:03:24,799 –> 00:03:26,560
اینجا خواهید دید که ستون تصادفی
92
00:03:26,560 –> 00:03:28,640
تغییر می کند، بنابراین هر زمان که شما کاری را در برگه انجام می دهید
93
00:03:28,640 –> 00:03:29,440
،
94
00:03:29,440 –> 00:03:32,959
اعداد تصادفی جدید ایجاد می شوند،
95
00:03:32,959 –> 00:03:34,720
بنابراین کاری که ما باید بعد از
96
00:03:34,720 –> 00:03:36,480
تولید اعداد تصادفی خود انجام دهیم این است که باید
97
00:03:36,480 –> 00:03:39,440
این ستون را انتخاب کنیم،
98
00:03:40,080 –> 00:03:47,840
آن را کپی کنیم
99
00:03:56,560 –> 00:03:59,680
و به بالا برگردیم. و سپس ما میخواهیم خاص
100
00:03:59,680 –> 00:04:00,400
را بچسبانیم،
101
00:04:00,400 –> 00:04:03,840
بنابراین این اعدادی که
102
00:04:03,840 –> 00:04:04,879
اکنون در ستون تصادفی ظاهر
103
00:04:04,879 –> 00:04:06,720
میشوند فقط اعداد هستند، آنها دیگر یک تابع نیستند،
104
00:04:06,720 –> 00:04:08,000
105
00:04:08,000 –> 00:04:10,480
بنابراین اگر کار دیگری در این برگه انجام دهیم، تغییر نخواهند کرد،
106
00:04:10,480 –> 00:04:12,959
107
00:04:12,959 –> 00:04:16,160
بنابراین اکنون آنچه میخواهیم انجام دهیم این است که
108
00:04:16,160 –> 00:04:17,759
109
00:04:17,759 –> 00:04:20,959
میخواهیم این جدول را
110
00:04:20,959 –> 00:04:24,479
بر اساس اعداد تولید شده بهطور تصادفی مرتب کنیم،
111
00:04:24,479 –> 00:04:26,080
این اولین کاری است که میخواهیم انجام دهیم،
112
00:04:26,080 –> 00:04:28,639
بنابراین باید کپی کنیم، باید کپی کنیم،
113
00:04:28,639 –> 00:04:30,240
باید ستون
114
00:04:30,240 –> 00:04:33,280
یا جدولی را که میخواهیم مرتب
115
00:04:33,280 –> 00:04:36,240
کنیم، به دادهها میرویم.
116
00:04:36,240 –> 00:04:39,280
ما قصد داریم مرتب کنیم و می خواهیم بر اساس این عدد تصادفی مرتب
117
00:04:39,280 –> 00:04:41,199
کنیم و می توانیم این کار را از کوچکترین
118
00:04:41,199 –> 00:04:42,880
یا بزرگترین به کوچکترین انجام دهیم اما کوچکترین
119
00:04:42,880 –> 00:04:44,880
بزرگترین به صورت پیش فرض است بنابراین این کار آسانتر است
120
00:04:44,880 –> 00:04:46,960
بنابراین اکنون خواهید دید که هر یک از
121
00:04:46,960 –> 00:04:48,800
اعداد
122
00:04:48,800 –> 00:04:50,800
قبلی مرتب شده است یا بهتر است بگوییم جدول قبلی
123
00:04:50,800 –> 00:04:52,880
با شناسه اصلی مرتب شده است و
124
00:04:52,880 –> 00:04:56,000
اکنون بر اساس شناسه تصادفی مرتب شده است
125
00:04:56,000 –> 00:04:58,560
و در نتیجه شناسه های اصلی
126
00:04:58,560 –> 00:05:01,840
127
00:05:03,199 –> 00:05:04,560
128
00:05:04,560 –> 00:05:06,479
ما به صورت تصادفی هستند.
129
00:05:06,479 –> 00:05:08,080
شناسه تصادفی را
130
00:05:08,080 –> 00:05:10,080
با شناسه اصلی تماس بگیرید و این
131
00:05:10,080 –> 00:05:11,759
دوباره است تقریباً ساده است
132
00:05:11,759 –> 00:05:14,960
که ما فقط میخواهیم
133
00:05:14,960 –> 00:05:18,720
یک شناسه منحصر به فرد داشته باشیم که
134
00:05:18,720 –> 00:05:22,000
برای هر یک از
135
00:05:22,000 –> 00:05:25,360
شناسههای جدول یک عدد افزایش مییابد، اکنون میتوانیم این کار را انجام دهیم
136
00:05:25,360 –> 00:05:27,280
و با دست یکی یکی که
137
00:05:27,280 –> 00:05:28,400
زمان بسیار زیادی طول میکشد
138
00:05:28,400 –> 00:05:30,160
، ترفند کوچک دیگری که میتوانیم انجام دهیم این است.
139
00:05:30,160 –> 00:05:33,039
اگر هم یکی و هم دو را انتخاب کنیم و
140
00:05:33,039 –> 00:05:36,560
141
00:05:36,560 –> 00:05:39,199
وقتی مکان نما
142
00:05:39,199 –>