در این مطلب، ویدئو از فایل اکسل تا RDF با پیوند به DBpedia و Europeana با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:12:20
تصاویر این ویدئو:
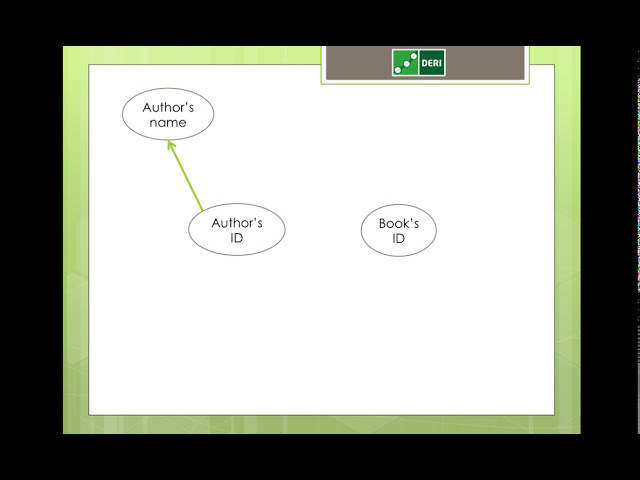
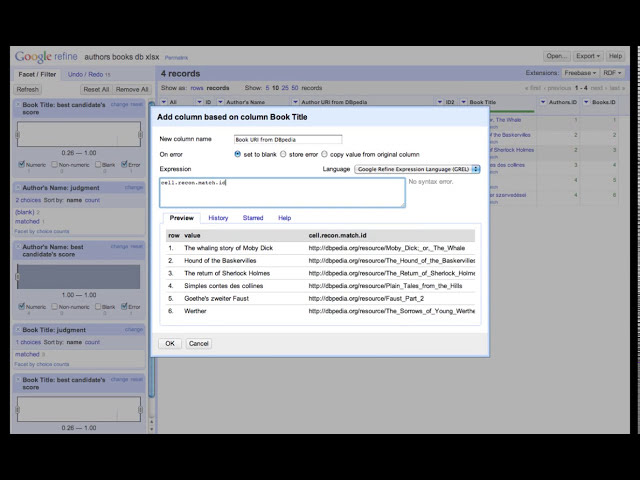
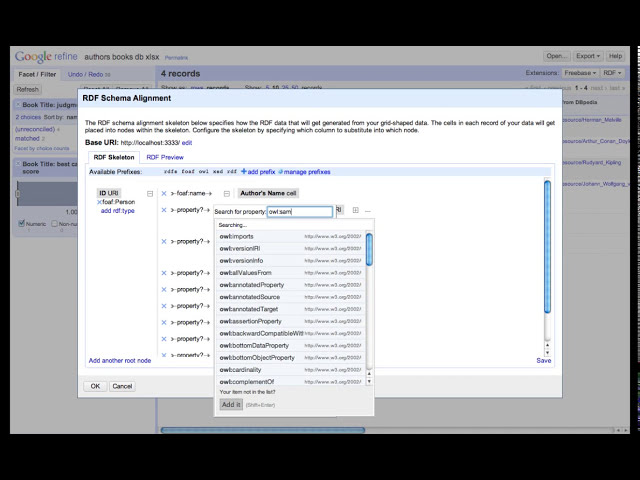
قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,820
سلام نام من آنا دوبروفسکی است در این
2
00:00:02,820 –> 00:00:05,520
آموزش به شما نشان خواهم داد که چگونه
3
00:00:05,520 –> 00:00:09,120
جداول اکسل را به rdf تبدیل کنید و همچنین به شما نشان خواهم داد
4
00:00:09,120 –> 00:00:11,460
که چگونه پیوندهایی به مجموعه داده های دیگر ایجاد کنید به
5
00:00:11,460 –> 00:00:13,590
عنوان مثال dbpedia و
6
00:00:13,590 –> 00:00:16,320
Europeana روی google
7
00:00:16,320 –> 00:00:18,390
refine و پسوند rdf به Google کار خواهند کرد.
8
00:00:18,390 –> 00:00:21,060
در مثال خود ما سه
9
00:00:21,060 –> 00:00:23,250
جدول داریم که در قسمت بیرونی
10
00:00:23,250 –> 00:00:24,869
کتابهای دوم و سومی
11
00:00:24,869 –> 00:00:26,689
روابط بین نویسندگان و کتابها را نشان میدهد،
12
00:00:26,689 –> 00:00:29,580
علاوه بر این، میتوانیم متوجه شویم که نویسندگان
13
00:00:29,580 –> 00:00:33,000
و کتابها دارای شناسههای منحصربهفرد هستند، پس حالا
14
00:00:33,000 –> 00:00:35,910
بیایید همانطور که میدانیم روی نمودار RDF تمرکز کنیم.
15
00:00:35,910 –> 00:00:38,219
شناسههای منحصربهفرد که به نام نویسنده اشاره دارد
16
00:00:38,219 –> 00:00:40,320
و همچنین جدولی داریم که دارای
17
00:00:40,320 –> 00:00:42,690
شناسههای منحصربهفرد است و به عناوین کتاب اشاره دارد.
18
00:00:42,690 –> 00:00:45,480
19
00:00:45,480 –> 00:00:47,940
20
00:00:47,940 –> 00:00:50,760
21
00:00:50,760 –> 00:00:53,430
علاوه بر این، ما همچنین
22
00:00:53,430 –> 00:00:55,260
می خواهیم برخی از اتصالات به
23
00:00:55,260 –> 00:00:57,600
منابع داده خارجی مانند timopy dia
24
00:00:57,600 –> 00:00:59,420
و Europeana را پیدا کنیم.
25
00:00:59,420 –> 00:01:01,859
اطلاعات اضافی دیگری که می
26
00:01:01,859 –> 00:01:04,438
توانید به نمودار ما اضافه کنید، رابطه است بنابراین ID
27
00:01:04,438 –> 00:01:07,560
به نام دیگران نام کتابها شناسه
28
00:01:07,560 –> 00:01:09,750
به عنوان عنوان کتاب اشاره دارد و
29
00:01:09,750 –> 00:01:13,710
نویسنده خالق کتاب است ما همچنین
30
00:01:13,710 –> 00:01:16,770
می توانیم همان رابطه را بین
31
00:01:16,770 –> 00:01:19,610
نمودار خود و پیوندهای BPD و Europeana
32
00:01:19,610 –> 00:01:23,220
ok ایجاد کنیم، بنابراین بیایید شروع کنیم، باید
33
00:01:23,220 –> 00:01:25,500
Google را در ابتدا اصلاح کند. شما فقط می
34
00:01:25,500 –> 00:01:27,210
توانید آن را مستقیماً از وب سایت و
35
00:01:27,210 –> 00:01:30,479
پسوند RDF به Google refine هنگامی
36
00:01:30,479 –> 00:01:32,520
که پسوند RDF را توسعه دادید، فقط
37
00:01:32,520 –> 00:01:34,079
باید این فایل را در دایرکتوری زیر قرار دهید
38
00:01:34,079 –> 00:01:39,770
، اکنون می توانیم تصفیه کاکائو را شروع
39
00:01:41,240 –> 00:01:43,560
کنیم اولین کاری که باید انجام دهیم این است که
40
00:01:43,560 –> 00:01:45,299
یک پروژه ایجاد کنیم. باید فایل اکسل خود را پیدا کرده
41
00:01:45,299 –> 00:01:53,970
و روی Next کلیک کنید، اکنون
42
00:01:53,970 –> 00:01:56,100
به نمای منتقل میشویم که در آن میتوانیم
43
00:01:56,100 –> 00:01:58,860
اولین پیش پردازش دادهها
44
00:01:58,860 –> 00:02:01,170
را انجام دهیم.
45
00:02:01,170 –> 00:02:02,759
46
00:02:02,759 –> 00:02:04,979
47
00:02:04,979 –> 00:02:07,290
میبینیم که آخرین ردیف در واقع تبدیل به
48
00:02:07,290 –> 00:02:11,580
هدر ما میشود که بز است، علاوه بر این، ما
49
00:02:11,580 –> 00:02:13,810
مجبور نیستیم ردیفهای خالی را شروع
50
00:02:13,810 –> 00:02:16,660
کنیم و بنابراین علامت این دو کادر را برداریم،
51
00:02:16,660 –> 00:02:18,160
میتوانیم پیشنمایش را بهروزرسانی کنیم و یک پروژه ایجاد کنیم،
52
00:02:18,160 –> 00:02:20,800
همانطور که میبینیم هنوز دو
53
00:02:20,800 –> 00:02:22,780
colu خالی داریم. mns تا بتوانیم آنها را حذف کنیم،
54
00:02:22,780 –> 00:02:25,420
بهعلاوه، نام ستونهای ما بهویژه برای
55
00:02:25,420 –> 00:02:27,030
نامها و کتابها چندان آموزنده
56
00:02:27,030 –> 00:02:29,349
نیست، به همین دلیل است که من آن را اصلاح میکنم.
57
00:02:29,349 –> 00:02:31,530
58
00:02:38,730 –> 00:02:41,760
59
00:02:41,760 –> 00:02:44,280
60
00:02:44,280 –> 00:02:47,130
خدماتی
61
00:02:47,130 –> 00:02:50,010
که به ترتیب به نقاط پایانی dbpedia و sparkle اروپایی اشاره میکنند، ابتدا
62
00:02:50,010 –> 00:02:53,700
63
00:02:53,700 –> 00:02:57,180
سرویس آشتی را بر اساس اسپارک در نقطه پایانی
64
00:02:57,180 –> 00:02:59,280
اضافه میکنیم، ابتدا tbp TSO را اضافه میکنیم که نام آن dbpedia است
65
00:02:59,280 –> 00:03:03,230
آدرس URL dbpedia dot org اسلش
66
00:03:03,230 –> 00:03:07,130
Sparkle از نوع گردشگری ترس است و ما
67
00:03:07,130 –> 00:03:10,319
انتخاب میکنیم ویژگیهای مبتنی بر
68
00:03:10,319 –> 00:03:13,470
برچسب DFS ما امتیاز یا نقطه پایانی بعدی
69
00:03:13,470 –> 00:03:14,370
یک Europeana
70
00:03:14,370 –> 00:03:17,690
با URL زیر خواهد بود، حتی اگر
71
00:03:17,690 –> 00:03:19,950
مجازی باشد، بنابراین متأسفانه
72
00:03:19,950 –> 00:03:21,510
واقعاً با این تنظیم کار نمیکند، بنابراین
73
00:03:21,510 –> 00:03:24,140
ما یک نقطه پایانی Sparkle عمومی باقی میگذاریم و
74
00:03:24,140 –> 00:03:27,110
در این مورد
75
00:03:27,110 –> 00:03:30,569
انتخاب خواهیم کرد. خواص مبتنی بر این رژیم غذایی
76
00:03:30,569 –> 00:03:34,380
برچسب DFS ما را خوب نمی کند، بنابراین اکنون
77
00:03:34,380 –> 00:03:37,049
می توانیم آشتی را شروع کنیم، ما از
78
00:03:37,049 –> 00:03:41,489
جمجمه بیرونی شروع می کنیم، از dbpedia استفاده می کنیم زیرا می دانیم
79
00:03:41,489 –> 00:03:44,010
که در مورد نویسندگان صحبت می کنیم n
80
00:03:44,010 –> 00:03:46,829
به سادگی انتخاب کنید که هر سلول را با
81
00:03:46,829 –> 00:03:50,870
یک موجودیت نویس تطبیق دهید و ما شروع به استایل کردن می
82
00:03:50,870 –> 00:03:53,459
کنیم، می گوییم که این بار یک تطابق کامل داریم،
83
00:03:53,459 –> 00:03:56,190
هر چند ضعیف باشد، همچنان می توانیم روی
84
00:03:56,190 –> 00:03:57,660
یکی از نتایج کلیک کنیم و ببینیم که
85
00:03:57,660 –> 00:04:03,000
آیا مطابقت مناسبی دارد، بنابراین از آنجایی که
86
00:04:03,000 –> 00:04:05,670
تطبیق داریم. نتایج را اکنون میتوانیم
87
00:04:05,670 –> 00:04:08,430
آنها را به یک ستون جداگانه صادر کنیم تا این کار را انجام دهیم،
88
00:04:08,430 –> 00:04:10,170
ابتدا باید یک نام منحصر به فرد برای یک ستون بگذاریم،
89
00:04:10,170 –> 00:04:12,180
در این صورت
90
00:04:12,180 –> 00:04:14,820
URI نویسنده از TVP diem خواهد بود، همچنین باید
91
00:04:14,820 –> 00:04:17,640
یک عبارت واقعی بنویسیم که
92
00:04:17,640 –> 00:04:19,168
اطلاعات تطبیق را از
93
00:04:19,168 –> 00:04:19,798
خودمان بگیریم.
94
00:04:19,798 –> 00:04:23,330
من به دنبال مطابقت میگردم ID را استخراج میکنم
95
00:04:23,330 –> 00:04:26,460
و آن را بهعنوان یک URL جداگانه مینویسم، سپس فقط
96
00:04:26,460 –> 00:04:28,710
باید روی OK کلیک کنیم، همین
97
00:04:28,710 –> 00:04:31,500
روند را برای عنوان کتاب تکرار میکنیم، این بار
98
00:04:31,500 –> 00:04:34,710
dbpedia را نیز انتخاب میکنیم، اما
99
00:04:34,710 –> 00:04:37,440
چون میدانیم در مورد کتابها صحبت کردیم، میتوانیم
100
00:04:37,440 –> 00:04:40,919
از نوع entity استفاده کنیم. کتاب این بار می
101
00:04:40,919 –> 00:04:42,419
بینیم که تطابق کاملی
102
00:04:42,419 –> 00:04:44,280
نداریم، بنابراین یا باید
103
00:04:44,280 –> 00:04:46,110
چیزی را از لیست انتخاب کنیم یا
104
00:04:46,110 –> 00:04:49,470
اگر از نتیجه راضی باشیم باید خودمان نتایج آشتی را پیدا
105
00:04:49,470 –> 00:04:51,990
کنیم.
106
00:04:51,990 –> 00:04:52,559
میتوانیم تأیید
107
00:04:52,559 –> 00:04:55,079
کنیم یا میتوانیم سعی کنیم نتیجه آشتی
108
00:04:55,079 –> 00:05:03,929
را خودمان پیدا کنیم، بنابراین باید فهرست را
109
00:05:03,929 –> 00:05:06,479
باز کنیم گاهی اوقات کافی است
110
00:05:06,479 –> 00:05:08,909
یک کلمه ک