در این مطلب، ویدئو Excel 2010 Statistics 82: 1 Tail Right t توزیع آزمون فرضیه میانگین P-value مقدار بحرانی با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:13:56
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,939
به ویدیوی شماره 82 آمار اکسل 2010 خوش آمدید
2
00:00:02,939 –> 00:00:05,609
اگر میخواهید این
3
00:00:05,609 –> 00:00:07,200
کسب و کار workbook را برای حضور در فایل دوم فصل 9 دانلود
4
00:00:07,200 –> 00:00:10,080
کنید، روی لینک زیر ویدیو کلیک کنید
5
00:00:10,080 –> 00:00:10,620
6
00:00:10,620 –> 00:00:14,240
هی تا کنون در فصل 9 ما در حال انجام
7
00:00:14,240 –> 00:00:16,770
آزمایش فرضیهها بودهایم که سیگما شناخته شده است
8
00:00:16,770 –> 00:00:19,279
و ما اکنون از توزیع Z استفاده
9
00:00:19,279 –> 00:00:22,289
می کنیم، می خواهیم ببینیم چه اتفاقی می افتد وقتی
10
00:00:22,289 –> 00:00:24,300
سیگما شناخته نشده باشد، می خواهیم از
11
00:00:24,300 –> 00:00:27,720
توزیع T استفاده کنیم در اینجا اولین
12
00:00:27,720 –> 00:00:33,620
مثال ما در آزمایش فرضیه HT هستیم.
13
00:00:33,620 –> 00:00:37,170
14
00:00:37,170 –> 00:00:41,040
15
00:00:41,040 –> 00:00:42,750
دستگاه تولید فیوز
16
00:00:42,750 –> 00:00:45,840
نصب شده است دستگاه قدیمی 250
17
00:00:45,840 –> 00:00:48,329
فیوز در ساعت تولید می کند. سازنده می خواهد
18
00:00:48,329 –> 00:00:50,430
تعیین کند که آیا دستگاه جدید بیش
19
00:00:50,430 –> 00:00:55,170
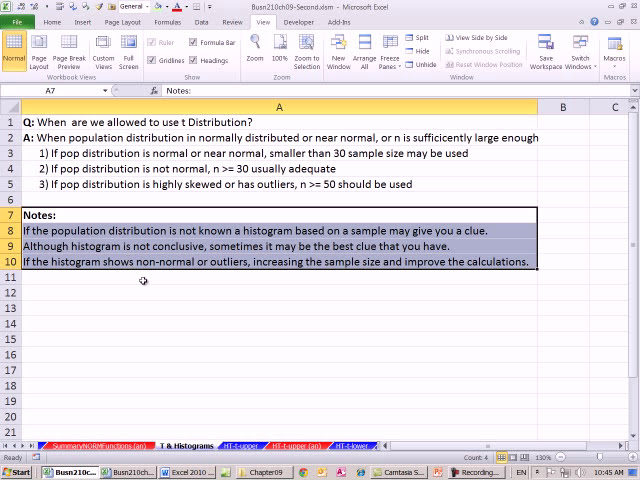
از 250 فیوز در ساعت می سازد یا نه در اصل
20
00:00:55,170 –> 00:00:57,030
آیا دستگاه به درستی کار می کند
21
00:00:57,030 –> 00:00:59,609
و سپس دستگاه قدیمی در ماه گذشته
22
00:00:59,609 –> 00:01:02,670
یا نمونه تصادفی. تعداد فیوزهای ساخته شده
23
00:01:02,670 –> 00:01:10,890
در هر ساعت که در واقع به ازای هر ساعت است، بنابراین ما
24
00:01:10,890 –> 00:01:13,439
به نرخ ساعتی نگاه می کنیم
25
00:01:13,439 –> 00:01:15,450
که در نقطه صفر یک سطح
26
00:01:15,450 –> 00:01:17,280
اهمیت گرفته شده است، آیا می توانیم نتیجه بگیریم که
27
00:01:17,280 –> 00:01:19,710
ماشین جدید بیش از 250 فیوز در ساعت تولید می کند
28
00:01:19,710 –> 00:01:24,030
اکنون ما باید برای توزیع T در نظر بگیریم که
29
00:01:24,030 –> 00:01:28,140
آیا واقعاً می توانیم
30
00:01:28,140 –> 00:01:30,270
از آن توزیع در
31
00:01:30,270 –> 00:01:32,720
اینجا در هیستوگرام T
32
00:01:32,720 –> 00:01:35,430
33
00:01:35,430 –> 00:01:37,680
استفاده کنیم یا خیر.
34
00:01:37,680 –> 00:01:40,650
توزیع T هنگامی که
35
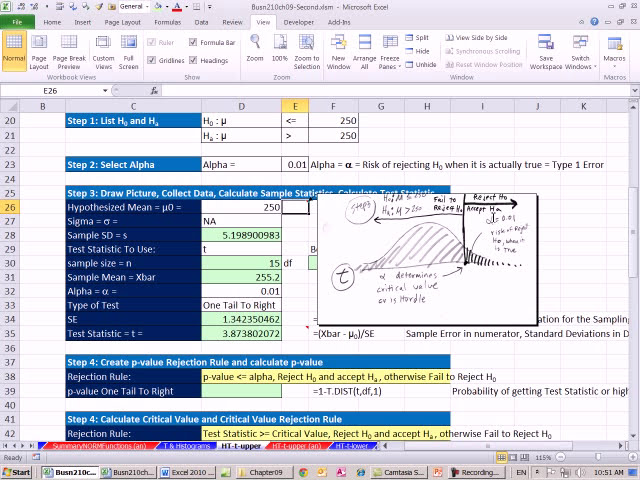
00:01:40,650 –> 00:01:42,200
توزیع جمعیت به طور معمول فقط
36
00:01:42,200 –> 00:01:45,570
توزیع شده است یا تقریباً نرمال یا n به
37
00:01:45,570 –> 00:01:48,240
اندازه کافی بزرگ است، بنابراین اگر
38
00:01:48,240 –> 00:01:52,740
توزیع نرمال است، می
39
00:01:52,740 –> 00:01:55,590
توانید از اندازه های نمونه کوچکتر از 30 استفاده کنید اگر
40
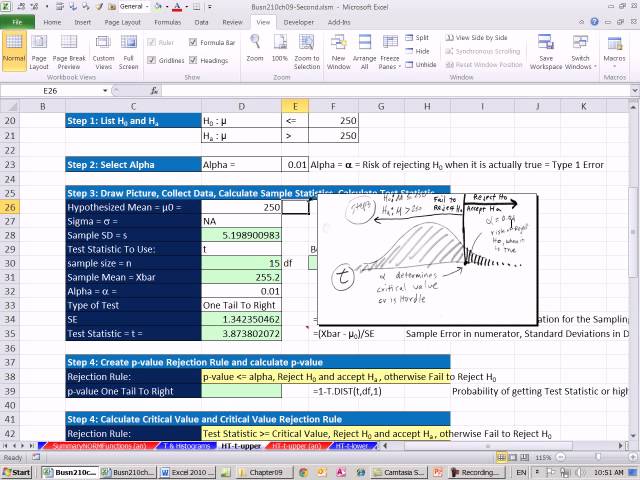
00:01:55,590 –> 00:01:59,219
n بزرگتر از 30 نرمال نیست.
41
00:01:59,219 –> 00:02:02,340
در صورتی استفاده می شود که
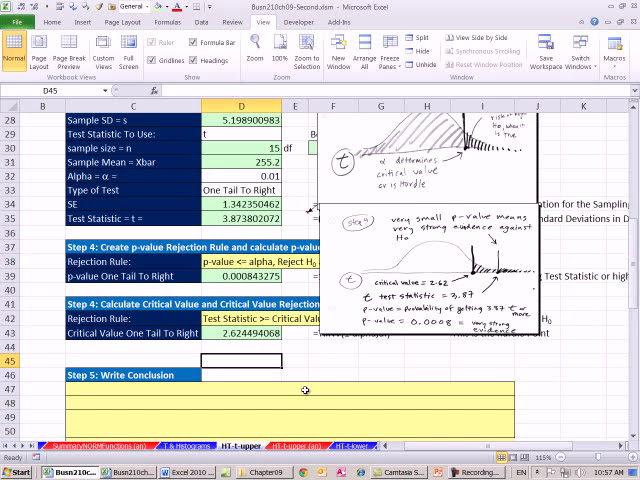
42
00:02:02,340 –> 00:02:05,340
در ابتدا زمانی که توزیع های T ایجاد شد، n برابر با 50 با
43
00:02:05,340 –> 00:02:07,290
د، بر
44
00:02:07,290 –> 00:02:09,899
ین فرض استوار بود که تو
45
00:02:09,899 –> 00:02:12,300
یع جمعیت در ناحیه به طور معمول تو
46
00:02:12,300 –> 00:02:13,680
یع شده است، اما در
47
00:02:13,680 –> 00:02:16,620
ول سال ها تحقیقات انجام شده است تا نش
48
00:02:16,620 –> 00:02:22,590
ن دهد تا زمانی که n به اندازه کافی بزرگ باشد، پی
49
00:02:22,590 –> 00:02:23,969
بینی ها انجام شده است. شما از
50
00:02:23,969 –> 00:02:26,760
توزیع t بسیار خوب است
51
00:02:26,760 –> 00:02:30,689
اکنون می توانید یک هیستوگرام روی نمونه خود اجرا کنید
52
00:02:30,689 –> 00:02:34,049
که کاملاً قطعی
53
00:02:34,049 –> 00:02:36,959
نیست، اما گاهی اوقات زمانی که y شما اطلاعاتی
54
00:02:36,959 –> 00:02:39,590
در مورد جمعیت ندارید، ممکن است تنها
55
00:02:39,590 –> 00:02:42,659
سرنخی باشد که اکنون دارید، بیایید به اینجا برویم،
56
00:02:42,659 –> 00:02:48,599
این برای فیوزها
57
00:02:48,599 –> 00:02:51,510
است، نمونه ما دقیقاً در اینجا کجاست
58
00:02:51,510 –> 00:02:52,709
و من در واقع یک هیستوگرام کوچک
59
00:02:52,709 –> 00:02:54,919
درست کردم و به نظر می رسد
60
00:02:54,919 –> 00:02:57,480
به طور معمول توزیع شده است و من
61
00:02:57,480 –> 00:03:02,069
در حال حاضر هیچ نقطه پرت نمی بینم برای این مثال در اینجا
62
00:03:02,069 –> 00:03:04,470
فیوزها سازنده مدت طولانی است که این کار را انجام می دهد
63
00:03:04,470 –> 00:03:05,790
و آنها می دانند که
64
00:03:05,790 –> 00:03:08,189
توزیع برای این نوع موقعیت ها
65
00:03:08,189 –> 00:03:11,459
به طور معمول توزیع شده است، بنابراین چون
66
00:03:11,459 –> 00:03:14,010
این یک ماشین جدید است، هیچ داده ای وجود ندارد. در مورد
67
00:03:14,010 –> 00:03:15,750
اینکه انحراف
68
00:03:15,750 –> 00:03:18,060
استاندارد جمعیت چیست، انحراف استاندارد جمعیت
69
00:03:18,060 –> 00:03:19,889
برای موقعیتهای تولیدی مانند این
70
00:03:19,889 –> 00:03:23,699
معمولاً به طور معمول توزیع میشود،
71
00:03:23,699 –> 00:03:27,900
بنابراین ما اکنون از T خود استفاده میکنیم، درست
72
00:03:27,900 –> 00:03:30,030
مانند قبل از تنظیم فرضیه
73
00:03:30,030 –> 00:03:32,099
آزمایش، فکر کردن به
74
00:03:32,099 –> 00:03:33,359
آنچه نقطه نظر چیزی است که شما در نظر می گیرید
75
00:03:33,359 –> 00:03:35,849
و هدف چیست، بنابراین
76
00:03:35,849 –> 00:03:37,260
نقطه نظر در اینجا به وضوح این است که
77
00:03:37,260 –> 00:03:38,909
سازنده می خواهد ببیند آیا دستگاه جدید
78
00:03:38,909 –> 00:03:41,849
مولدتر است یا خیر؟
79
00:03:41,849 –> 00:03:44,940
با در نظر گرفتن جمعیت تعداد
80
00:03:44,940 –> 00:03:47,159
فیوزهای ساخته شده در ساعت برای این دستگاه در
81
00:03:47,159 –> 00:03:50,849
آزمون فرضیه اجرای هدف ما برای ارائه
82
00:03:50,849 –> 00:03:52,530
شواهد آماری برای تعیین
83
00:03:52,530 –> 00:03:54,440
اینکه آیا دستگاه جدید بیش از 250 فیوز می سازد یا خیر،
84
00:03:54,440 –> 00:04:01,319
همانطور که در
85
00:04:01,319 –> 00:04:04,859
چهار ویدیوی گذشته انجام دادیم، نگاهی به این کردیم.
86
00:04:04,859 –> 00:04:06,530
نقطه نظر برای فهمیدن اینکه چگونه
87
00:04:06,530 –> 00:04:09,599
فرضیه را تنظیم کنیم اکنون ما به بیش از 250 مورد علاقه داریم،
88
00:04:09,599 –> 00:04:14,579
بنابراین ترفند قدیمی این است که فقط
89
00:04:14,579 –> 00:04:18,570
نماد بیشتری انجام دهید این است که نمادهای بیشتری
90
00:04:18,570 –> 00:04:19,470
به این سمت اشاره
91
00:04:19,470 –> 00:04:21,839
می کنند شما این را بنویسید تا به این معنی باشد که یک
92
00:04:21,839 –> 00:04:25,290
آزمایش در مورد دم بالایی
93
00:04:25,290 –> 00:04:27,120
نه تنها این، بلکه اگر این
94
00:04:27,120 –> 00:04:29,550
نماد را میشناسید، میتوانید آن را روی
95
00:04:29,550 –> 00:04:33,840
فرضیه جایگزین بزنید و این همان
96
00:04:33,840 –> 00:04:34,520
کاری است که
97
00:04:34,520 –> 00:04:40,440
ما انجام خواهیم داد، H sub a داریم: mu
98
00:04:40,440 –> 00:04:42,510
فرضیه جایگزین کولا به این معنی است که
99
00:04:42,510 –> 00:04:46,200
فرضیه mu این است که فضای بزرگتر از
100
00:04:46,200 –> 00:04:50,460
n و ما اکنون 250 داریم، من میخواهم به
101
00:04:50,460 –> 00:04:51,990
اینجا بیایم و قدم بزنم،
102
00:04:51,990 –> 00:04:53,760
همه متغیرهایمان را فهرست کرده و محاسبات خود را انجام میدهیم،
103
00:04:53,760 –> 00:04:59,010
بنابراین مو فرضی 250 خواهد بود، بنابراین من
104
00:04:59,010 –> 00:05:01,200
میخواهم آن را همینجا گوش کنم و
105
00:05:01,200 –> 00:05:02,640
البته همانطور که در حال صحبت بودیم. در باره
106
00:05:02,640 –> 00:05:04,500
هنگامی که عملگر مقایسه ای را بشناسید،
107
00:05:04,500 –> 00:05:07,440
در اینجا به سادگی آن را در فاصله
108
00:05:07,440 –> 00:05:14,730
کمتر از آن قرار می دهید و علامت مساوی را به آن اضافه می کنید، بنابراین
109
00:05:14,730 –> 00:05:17,280
اکنون فرضیه خود را آلفای خود تنظیم
110
00:05:17,280 –> 00:05:21,240
کرده ایم که خطر خطای
111
00:05:21,240 –> 00:05:23,670
خطای نوع 1 است.
112
00:05:23,670 –> 00:05:28,820
آلفا خطر
113
00:05:28,820 –> 00:05:32,300
رد فرضیه صفر خود را به ما می گوید، حتی
114
00:05:32,300 –> 00:05:37,020
اگر درست است، در حال حاضر بیایید
115
00:05:37,020 –> 00:05:38,700
پایین برویم و محاسباتی را انجام دهیم، من
116
00:05:38,700 –> 00:05:41,190
فقط کمی اینجا را مرور می کنم تا
117
00:05:41,190 –> 00:05:44,000
میانگین فرضی 250
118
00:05:44,000 –> 00:05:47,400
سیگما را داشته باشیم و آن را نمی دانیم. در
119
00:05:47,400 –> 00:05:49,350
دسترس نیست این یک دستگاه جدید است
120
00:05:49,350 –> 00:05:51,390
ما هیچ داده ای در مورد آن نداریم انحراف استاندارد نمونه
121
00:05:51,390 –> 00:05:56,660
ما از STD PPS استفاده
122
00:05:59,480 –> 00:06:06,210
می کند بنابراین آمار 5.19 را برای استفاده به دست می آوریم ما از این استفاده خواهیم کرد
123
00:06:06,210 –> 00:06:10,640
چرا که اندازه نمونه سیگما را نمی
124
00:06:10,640 –> 00:06:13,590
دانیم از
125
00:06:13,590 –> 00:06:15,030
تابع شمارش استفاده میکنیم، زیرا میشماریم چند
126
00:06:15,030 –> 00:06:19,200
عدد چهل عدد است که باید
127
00:06:19,200 –> 00:06:23,990
درجه آزادی و
128
00:06:23,990 –> 00:06:27,360
منهای تعداد نمونههایی را که گرفتهایم محاسبه کنیم، بنابراین
129
00:06:27,360 –> 00:06:30,840
میتوانم چهار درجه آزادی را بدست بیاورم که
130
00:06:30,840 –> 00:06:34,380
توسط T استفاده میشود یا انجام دادیم تا مشخص کنیم کدام یک
131
00:06:34,380 –> 00:06:36,630
بسیاری از توزیع های T y شما می خواهید
132
00:06:36,630 –> 00:06:40,260
از اندازه نمونه کوچکتر استفاده کنید،
133
00:06:40,260 –> 00:06:42,390
توزیع و تنوع بیشتری در توزیع T وجود دارد،
134
00:06:42,390 –> 00:06:46,260
135
00:06:46,260 –> 00:06:53,850
ما میانگین نمونه خود را درست می گیریم، بنابراین ما 255
136
00:06:53,